






判别分析实战-R语言mlr、Python-sklearn、K-折交叉验证
主要内容
-
理解线性判别分析和二次判别分析
-
建立线性判别分类器,对葡萄酒数据集进行预测
什么是判别分析
判别分析(Discriminant analysis)是一种统计分析方法,旨在通过将一组对象(例如观察数据)分类到已知类别的组中,来发现不同组之间的差异。
判别分析有两种主要形式:线性判别分析(LDA)和二次判别分析(QDA)。LDA假设每个类别的协方差矩阵相同,并寻找最优的判别方向来最大化类别之间的距离。QDA假设每个类别的协方差矩阵都不同,并寻找最优的判别方向来最大化类别之间的距离,同时也考虑了每个类别的协方差矩阵。
线性判别分析(LDA)
当我们有一个由 n n n 个样本和 p p p 个特征组成的数据集时,LDA的目标是找到一个线性变换,将数据从 p p p 维空间映射到 k k k 维空间( k < p k<p k<p),使得在新的空间中,同一类别内的数据点尽可能相似,不同类别之间的数据点尽可能分离。
线性判别分析的数学原理
我们以二分类问题为例:假设数据集是 D = { ( x i , y i } i = 1 m , y i ∈ { 0 , 1 } D=\{(x_i,y_i\}_{i=1}^m,y_i\in\{0,1\} D={(xi,yi}i=1m,yi∈{0,1},设 μ i \mu_i μi为第 i i i类样本的均值向量; X i X_i Xi为第 i i i类样本的集合; Σ i \Sigma_i Σi为第 i i i类样本的协方差矩阵, i = 0 , 1 i=0,1 i=0,1.
将样本数据投影至直线 y = w T x y=w^Tx y=wTx上,则两类样本中心在直线上的投影分别为 w T μ 0 , w T μ 1 w^T\mu_0,w^T\mu_1 wTμ0,wTμ1,两类样本在直线上的协方差分别为 w T Σ 0 w , w T Σ 1 w w^T\Sigma_0w,w^T\Sigma_1w wTΣ0w,wTΣ1w.
-
同类样本点的投影点尽量接近,也就是同类样本点投影后的协方差 w T Σ 0 w , w T Σ 1 w w^T\Sigma_0w,w^T\Sigma_1w wTΣ0w,wTΣ1w尽可能小
-
异类样本的投影点尽可能远离,也就是不同类样本点的类中心之间的距离 ∥ w T μ 0 − w T μ 1 ∥ 2 2 \|w^T\mu_0-w^T\mu_1\|_2^2 ∥wTμ0−wTμ1∥22尽可能大
目标函数
J
(
w
)
=
max
w
∥
w
T
μ
0
−
w
T
μ
1
∥
2
w
T
Σ
0
w
+
w
T
Σ
1
w
J(w)=\max_{w} \dfrac{\|w^T\mu_0-w^T\mu_1\|^2}{w^T\Sigma_0w+w^T\Sigma_1w}
J(w)=wmaxwTΣ0w+wTΣ1w∥wTμ0−wTμ1∥2
将上面的公式化简,得到:
J
(
w
)
=
max
w
w
T
(
μ
0
−
μ
1
)
(
μ
0
−
μ
1
)
T
w
w
T
(
Σ
0
+
Σ
1
)
w
J(w)=\max_{w}\dfrac{w^T(\mu_0-\mu_1)(\mu_0-\mu_1)^Tw}{w^T(\Sigma_0+\Sigma_1)w}
J(w)=wmaxwT(Σ0+Σ1)wwT(μ0−μ1)(μ0−μ1)Tw
我们记 S b = ( μ 0 − μ 1 ) ( μ 0 − μ 1 ) T , S w = Σ 0 + Σ 1 S_b=(\mu_0-\mu_1)(\mu_0-\mu_1)^T,S_w=\Sigma_0+\Sigma_1 Sb=(μ0−μ1)(μ0−μ1)T,Sw=Σ0+Σ1,我们最终可以目标函数为 J ( w ) = max w w T S b w w T S w w J(w)=\max_{w}\dfrac{w^TS_bw}{w^TS_ww} J(w)=wmaxwTSwwwTSbw
拉格朗日乘子法求解
由于求解的 w w w是一个方向向量,与模长无关,我们可以令 w T S w w = 1 w^TS_ww=1 wTSww=1,于是目标函数变为: min − w T S b w , w T S w w = 1 \min -w^TS_bw , w^TS_ww=1 min−wTSbw,wTSww=1
- 写出对偶拉格朗日函数: max λ min w − w T S b w + λ ( w T S w w − 1 ) \max_\lambda \min_{w} -w^TS_bw+\lambda(w^TS_ww-1) λmaxwmin−wTSbw+λ(wTSww−1)
我们令
F
(
w
)
=
−
w
T
S
b
w
+
λ
(
w
T
S
w
w
−
1
)
F(w)=-w^TS_bw+\lambda(w^TS_ww-1)
F(w)=−wTSbw+λ(wTSww−1),欲求
min
F
(
w
)
\min F(w)
minF(w),需要求解
∇
w
F
(
w
)
=
−
2
S
b
w
+
2
λ
S
w
w
=
0
\nabla_wF(w)=-2S_bw+2\lambda S_ww=0
∇wF(w)=−2Sbw+2λSww=0,即
S
b
w
=
λ
S
w
w
S_bw=\lambda S_w w
Sbw=λSww,注意
S
b
w
=
(
μ
0
−
μ
1
)
(
μ
0
−
μ
1
)
T
w
S_bw=(\mu_0-\mu_1)(\mu_0-\mu_1)^Tw
Sbw=(μ0−μ1)(μ0−μ1)Tw中的
(
μ
0
−
μ
1
)
T
w
(\mu_0-\mu_1)^Tw
(μ0−μ1)Tw是一个实数,方向恒为
μ
0
−
μ
1
\mu_0-\mu_1
μ0−μ1,因此我们可以不妨设
S
b
w
=
λ
(
μ
0
−
μ
1
)
S_bw=\lambda(\mu_0-\mu_1)
Sbw=λ(μ0−μ1),最终得到:
λ
(
μ
0
−
μ
1
)
=
λ
S
w
w
\lambda(\mu_0-\mu_1)=\lambda S_ww
λ(μ0−μ1)=λSww,求解得到:
w
=
S
w
−
1
(
μ
0
−
μ
1
)
w=S_w^{-1}(\mu_0-\mu_1)
w=Sw−1(μ0−μ1)
当
S
w
S_w
Sw矩阵不可逆时,我们通常使用奇异值分解:
S
w
=
U
Σ
V
T
S_w=U\Sigma V^T
Sw=UΣVT
二次判别分析(QDA)
QDA(Quadratic Discriminant Analysis)是一种有监督的机器学习算法,用于分类问题。它是 LDA(Linear Discriminant Analysis,线性判别分析)的一种扩展形式,与 LDA 类似,QDA 也是一种基于贝叶斯决策理论的分类器。与 LDA 不同的是,QDA 假设每个类别的协方差矩阵不相同,因此在分类时使用的决策边界是二次曲线。
构建线性和二次判别模型
加载和研究葡萄酒数据集
library(mlr)
library(tidyverse)
加载HDclassif程序包内置的葡萄酒数据,将其转换为tibble:
library(HDclassif)
data(wine,package = "HDclassif")
wineTib <- as_tibble(wine)
手动添加变量名称:
names(wineTib) <- c("Class","Alco","Malic","Ash","Alk","Mag","Phe","Flav","Non_flav","Proan","Col","Hue","OD","Prol")
wineTib$Class <- as.factor(wineTib$Class)
检查有无缺失值:
colSums(is.na(wineTib))
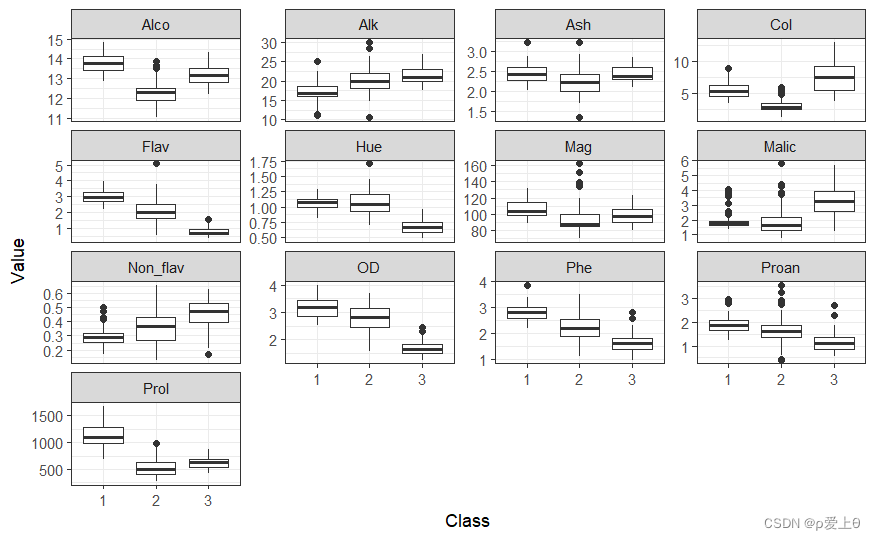
绘制数据图
wineUntidy <- gather(wineTib,"Variable","Value",-Class)
ggplot(wineUntidy,aes(Class,Value))+
facet_wrap(~ Variable,scales = "free_y")+
geom_boxplot()+
theme_bw()
训练模型
wineTask <- makeClassifTask(data = wineTib,target = "Class")
lda <- makeLearner("classif.lda")
ldaModel <-train(lda,wineTask)
使用getLearnerModel()函数提取模型信息,并使用predict()函数获取每个样本的DF值。
ldaModeldata<- getLearnerModel(ldaModel)
ldaPreds <-predict(ldaModeldata)$x
head(ldaPreds)
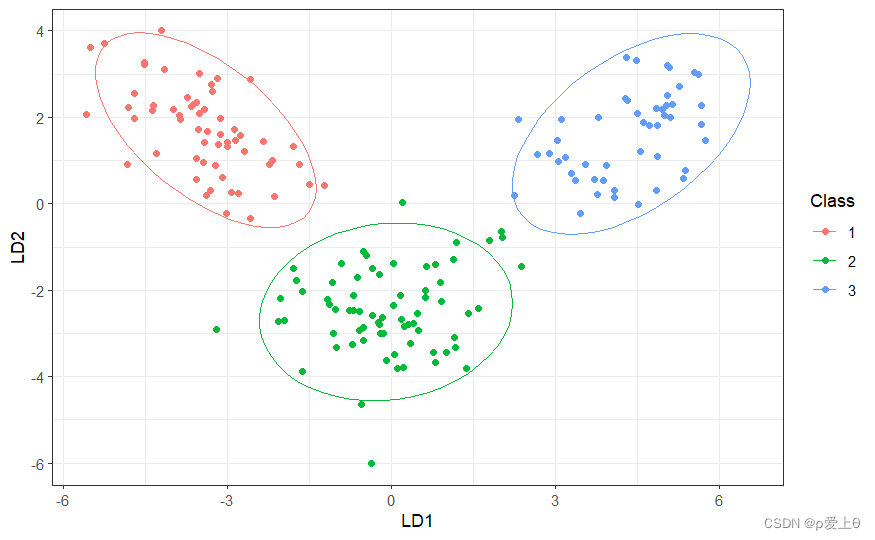
可视化建模
为了可视化算法学习到的两个DF如何很好地将三个葡萄园的数据分开,可以对他们进行对比绘制。
wineTib %>%
mutate(LD1 = ldaPreds[,1],
LD2 = ldaPreds[,2])%>%
ggplot(aes(LD1,LD2,col = Class))+
geom_point()+
stat_ellipse()+ #在每个类别的周围绘制95%的置信度椭圆
theme_bw()
构建QDA模型
qda <- makeLearner("classif.qda")
qdaModel <- train(qda,task = wineTask)
交叉验证LDA和QDA模型
kFold <- makeResampleDesc(method = "RepCV",folds = 10,reps = 2,stratify = TRUE)
ldaCV <- resample(learner = lda,task = wineTask,resampling = kFold,measures = list(acc,mmce))
qdaCV <- resample(learner = qda,task = wineTask,resampling = kFold,measures = list(acc,mmce))
ldaCV$aggr
qdaCV$aggr
LDA 模型平均对约为98.6%的样本进行了正确分类,QDA模型平均对约为99.4%的样本进行了正确分类。
输出混淆矩阵:
calculateConfusionMatrix(ldaCV$pred,relative = TRUE)
calculateConfusionMatrix(qdaCV$pred,relative = TRUE)
对未知数据进行预测
newdata <- tibble(Alco=13,Malic=2,Ash=2.2,Alk=19,Mag=100,Phe=2.3,Flav=2.5,Non_flav=0.35,Proan=1.7,Col=4,Hue=1.1,OD=3,Prol=750)
lda_pre<-predict(ldaModel,newdata = newdata)$data #输出为2
qda_pre<-predict(qdaModel,newdata = newdata)$data #输出为1
将数据导出为csv方便后续使用:
#write_csv(wineTib,"葡萄酒数据集.csv")
LDA和QDA算法的优缺点
1.优点
- 可以将高维特征空间的数据压缩到易于管理的低维空间
- 可用于分类或者其他分类算法的预处理(降维)技术
- QDA可以学习到类别之间弯曲的决策边界
2.缺点
- 只能处理连续预测变量
- 假设数据特征服从正态分布,如果数据不服从正态分布,LDA和QDA模型的表现较差
- QDA容易过拟合
复习KNN调参练习
从LDA模型中提取判别分数,并将这些类别分数用作KNN模型的自变量,在整个过程使用交叉验证,并同时调整超参数k
# 创建任务
new<-wineTib %>%
mutate(LD1=ldaPreds[, 1], LD2=ldaPreds[, 2])
newData<-new[,c(1,15,16)]
newTask <- makeClassifTask(data = newData,target = "Class")
# 创建学习器
knn <- makeLearner("classif.knn",par.vals = list("k"=5)) #初始化一个学习器,超参数定义为5
knnModel <- train(learner = knn,task = newTask)
# 调整超参数k
knnParamSpace <- makeParamSet(makeDiscreteLearnerParam("k",values = 1:10))
gridsearch <- makeTuneControlGrid() #使用网格搜索
cvForTuning <- makeResampleDesc(method = "RepCV",folds=10,reps=20)
tunedK <- tuneParams(learner = knn,task = newTask,resampling = cvForTuning,measures = list(mmce),par.set = knnParamSpace,control = gridsearch)
knnTuningData <- generateHyperParsEffectData(tunedK)
plotHyperParsEffect(knnTuningData,x="k",y="mmce.test.mean",plot.type = "line")+
theme_bw()
将数据写入csv文件,便于Python导入:
write_csv(newData,"三分类数据集.csv")
下面使用Python中的KNN算法以及网格搜索参数调优
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split,GridSearchCV
import pandas as pd
data = pd.read_csv("三分类数据集.csv")
data_shuffle = data.sample(frac=1,random_state=42) #将数据按照行进行打乱
y= data_shuffle["Class"]
x = data_shuffle.drop("Class",axis=1,inplace=False)
X_train,X_test,y_train,y_test = train_test_split(x.values,y.values,test_size=0.2,random_state=42)
knn = KNeighborsClassifier()
knn.fit(X_train,y_train)
y_pre = knn.predict(X_test)
pre_true_df = pd.DataFrame()
pre_true_df["true"] = y_test
pre_true_df["predict"] = y_pre
pre_true_df ##这里准确率已经百分百了
虽然上面的模型在测试集已经达到百分之百了,但是我们的数据集规模太小了,我们还是要学习一下如何在Python中进行参数调优吧(网格搜索)
k_range = list(range(1, 10))
param_grid = dict(n_neighbors=k_range)
grid = GridSearchCV(knn, param_grid, cv=10, scoring='accuracy')
grid.fit(x, y)
print("Best score: {:.2f}%".format(grid.best_score_*100))
print("Best parameters: {}".format(grid.best_params_))
现在调用Python中的LDA算法和QDA算法对葡萄酒数据进行分类:
import pandas as pd
wine = pd.read_csv("葡萄酒数据集.csv")
y = wine["Class"]
x = wine.drop("Class",axis=1,inplace=False)
X= x.values
Y = y.values
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis,QuadraticDiscriminantAnalysis
from sklearn.metrics import accuracy_score
# 创建LDA模型对象
lda = LinearDiscriminantAnalysis()
# 训练LDA模型
lda.fit(X_train, y_train)
# 创建QDA模型对象
qda = QuadraticDiscriminantAnalysis()
# 训练QDA模型
qda.fit(X_train, y_train)
# 进行k-折交叉验证
from sklearn.model_selection import KFold
k=10
acc_lda = []
acc_qda=[]
# 初始化KFold对象
kf = KFold(n_splits=k, shuffle=True, random_state=42)
for train_index,test_index in kf.split(X):
X_train,X_test = X[train_index],X[test_index]
Y_train,Y_test = Y[train_index],Y[test_index]
# 创建模型
lda = LinearDiscriminantAnalysis()
qda = QuadraticDiscriminantAnalysis()
# 训练模型
lda.fit(X_train,Y_train)
qda.fit(X_train,Y_train)
# 预测
y_pre_lda = lda.predict(X_test)
y_pre_qda = qda.predict(X_test)
# 评估
acc_lda.append(accuracy_score(y_pre_lda,Y_test))
acc_qda.append(accuracy_score(y_pre_qda,Y_test))
print(acc_lda)
print(acc_qda)















 788
788











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











