









 本文详细介绍了浮点数在计算机中的表示方法,包括阶码的概念、尾数的规格化以及浮点数的范围和精度。通过偏移量127的选择确保了指数的表示范围,使得32位浮点数可以表示从-3.40E+38到+3.40E+38的数值。此外,还阐述了float和double类型的指数位和尾数位对范围及精度的影响,float精度约为6-7位有效数字,double精度为15-16位。
本文详细介绍了浮点数在计算机中的表示方法,包括阶码的概念、尾数的规格化以及浮点数的范围和精度。通过偏移量127的选择确保了指数的表示范围,使得32位浮点数可以表示从-3.40E+38到+3.40E+38的数值。此外,还阐述了float和double类型的指数位和尾数位对范围及精度的影响,float精度约为6-7位有效数字,double精度为15-16位。
首先要 知道 浮点数 补码 原码 反码。
定义:
浮点数的阶码一般使用移码来表示,并不牵扯到规格化。
规格化特指尾数的规格化。尾数可能是补码或者原码。
浮点数表示方法:
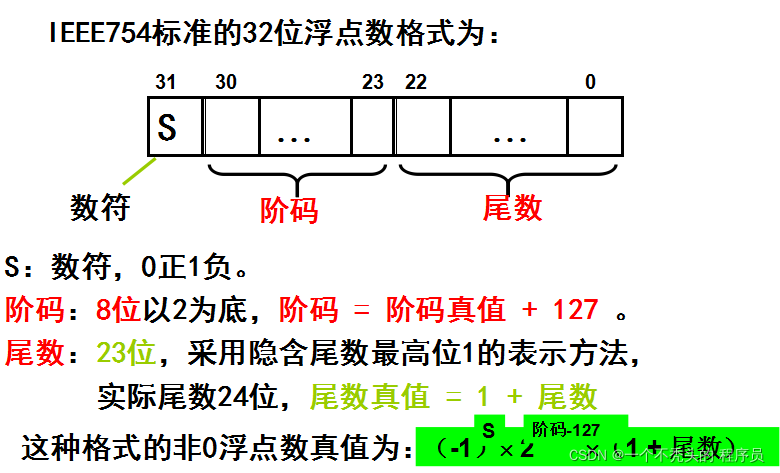
关于阶码:在机器中表示一个浮点数时需要给出指数,这个指数用整数形式表示,这个整数叫做阶码,阶码指明了小数点在数据中的位置。对于任意一个二进制数N,可用N=S×2^P表示,其中S为尾数,P为阶码,2为阶码的底,P、S都用二进制数表示,S表示N的全部有效数字,P指明小数点的位置。当阶码为固定值时,数的这种表示法称为定点表示,这样的数称为“定点数”;当阶码为可变时,数的这种表示法称为浮点表示,这样的数称为“浮点数”。为什么要定义使用阶码? 因为浮点数的定义导致的,也是浮点数的表示需求产生的。浮点数是属于有理数中某特定子集的数的数字表示,在计算机中用以近似表示任意某个实数。具体的说,这个实数由一个整数或定点数(即尾数)乘以某个基数(计算机中通常是2)的整数次幂得到,这种表示方法类似于基数为10的科学记数法。
为什么偏移量设置为127?
当阶码E 为全0且尾数M 也为全0时,表示的真值x 为零,结合符号位S 为0或1,有正零和负零之分。当阶码E 为全1且尾数M 为全0时,表示的真值x 为无穷大,结合符号位S
为0或1,也有+∞和-∞之分。这样在32位浮点数表示中,要除去E 用全0和全1(255)10表示零和无穷大的特殊情况,指数的偏移值不选128(10000000),而选127(01111111)。对于规格化浮点数,E 的范围变为1到254,真正的指数值e
则为-126到+127。因此32位浮点数表示的绝对值的范围是10-38~10^38
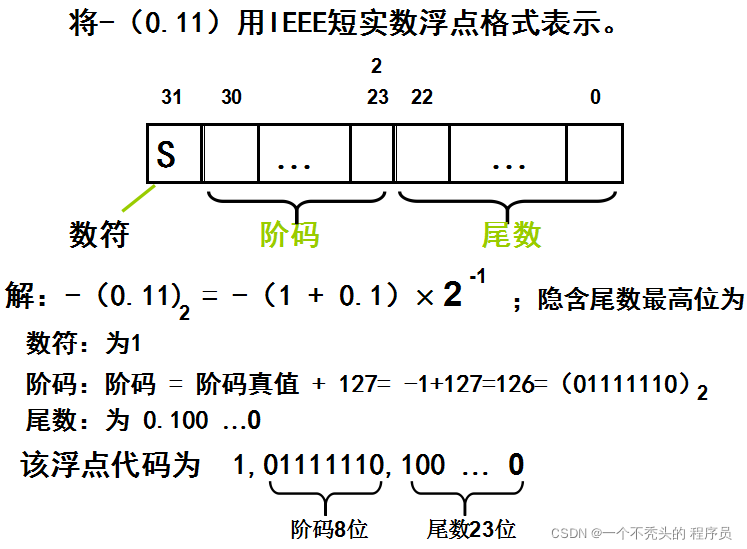

这样我们就知道了,其实我们的浮点数是这样表示在计算机当当中的,那么浮点数的范围呢?
float与double的范围和精度
1.范围
float和double的范围是由指数的位数来决定的。 float的指数位有8位,而double的指数位有11位,分布如下:
-
float:
1bit(符号位) 8bits(指数位) 23bits(尾数位) -
double:
1bit(符号位) 11bits(指数位) 52bits(尾数位)
于是,float的指数范围为-126到+127,而double的指数范围为-1022~+1023,并且指数位是按补码的形式来划分的。
之所以是上面的范围:上面黑体字部分已经解释了,为了比较方便,我们将指数加偏移量改为正值,由于隐匿一位偏移导致偏移量整体-1
其中负指数决定了浮点数所能表达的绝对值最小的非零数;而正指数决定了浮点数所能表达的绝对值最大的数,也即决定了浮点数的取值范围。
float的范围为-2^127 ~ +2^127,也即-3.40E+38 ~ +3.40E+38;double的范围为-2^1023 ~ +2^1023,也即-1.79E+308 ~ +1.79E+308。
2.精度
float和double的精度是由尾数的位数来决定的。浮点数在内存中是按科学计数法来存储的,其整数部分始终是一个隐含着的“1”,由于它是不变的,故不能对精度造成影响。
float:2^23 = 8388608,一共七位,这意味着最多能有7位有效数字,但绝对能保证的为6位,也即float的精度为6~7位有效数字;
double:2^52 = 4503599627370496,一共16位,同理,double的精度为15~16位。这样IEE754就算基本弄清了。

















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









