







表 索引 语句 索引 事务 主从
show process list—>临时表(group by order by )
表(常用 or 不常用 定长 or 变长 节约 tinyint 0-255岁)
索引:
+独立索引,只能使用一个
+ 多列索引,><和like之后的and
+ 场景索引:复合索引 (cate_id,price)
+覆盖索引(using index,走索引,不用回行查找)
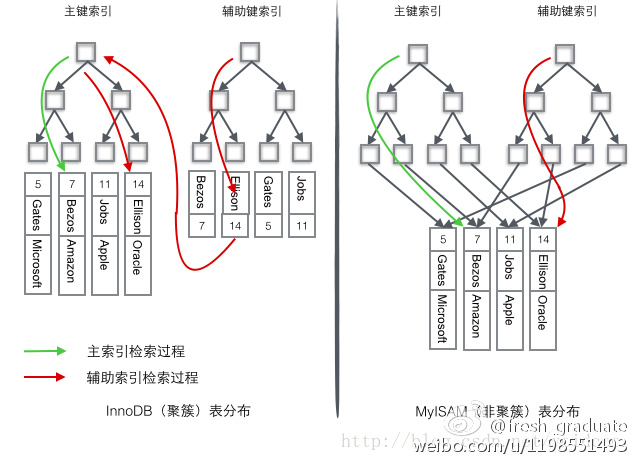
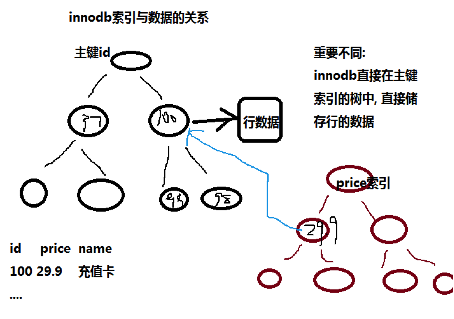
+聚族 or 非聚族:既存储了主键值,又存储了行数据,这种结构称为”聚簇索引”
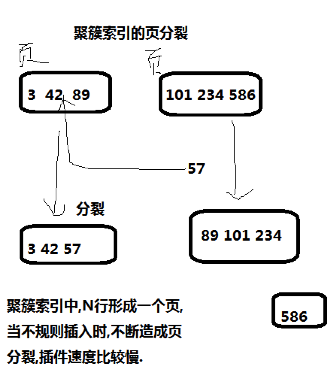
myisam 依赖行号 innodb 数据行放入主键,不连续会产生索引页的分裂
+理想索引:区分度 和 长度
select count(distinct left(word,6))/count(*) from dict;
+延迟关联:select a.* from it_area as a inner join (select id from it_area where name like '%东山%') as t on a.id=t.id
+排序:覆盖索引取出来就是有序的 or 取出来后形成临时表再通过filesort排序 =>争取取出来就是有序的
比如: goods商品表, (cat_id,shop_price)组成联合索引,
where cat_id=N order by shop_price ,可以利用索引来排序,
select goods_id,cat_id,shop_price from goods order by shop_price;
// using where,按照shop_price索引取出的结果,本身就是有序的.
select goods_id,cat_id,shop_price from goods order by click_count;
// using filesort 用到了文件排序,即取出的结果再次排序
+重复索引, 去掉.
+冗余索引: x m xm mx
+索引碎片与维护 alter table xxx engine innodb optimize table 表名 ,也可以修复.
sql语句:等待 + 执行(查 取)
优化:explain
--type列: 是指查询的方式, 非常重要,是分析”查数据过程”的重要依据
all: 意味着从表的第1行,往后,逐行做全表扫描.,运气不好扫描到最后一行.
index: 比all性能稍好一点,(2种情况可能出现:索引覆盖但是又必须全索引扫描 or 是利用索引来进行排序,但取出所有的节点)
range: 意思是查询时,能根据索引做范围的扫描
ref 意思是指 通过索引列,可以直接引用到某些数据行
eq_ref 是指,通过索引列,直接引用某1行数据,常见于连接查询中
const, system, null 这3个分别指查询优化到常量级别, 甚至不需要查找时间.
--extra:
using index: 是指用到了索引覆盖,效率非常高
using where 是指光靠索引定位不了,还得where判断一下
using temporary 是指用上了临时表, group by 与order by 不同列时,或group by ,order by 别的表的列.
using filesort : 文件排序(文件可能在磁盘,也可能在内存), (
select sum(shop_price) from goods group by cat_id(这句话,用到了临时表和文件排序)
--语法:
in(先外后内)==>join(先内后外)
from子查询(内层返回要尽量少,因为有了临时表)
count 别用where
min/max mysql内部已优化
group by 用于分组而不是筛选
union+all,不要去重
limit:limit offset,N, 取offset+N行,返回放弃前offset行,返回N行.
优化办法:
从业务上去解决:不允许翻过100页
or
不用offset,用条件查询.
mysql> select id,name from lx_com limit 5000000,10;
mysql> select id,name from lx_com where id>5000000 limit 10;
问题: 2次的结果不一致
原因: 数据被物理删除过,有空洞.
解决:一般来说,大网站的数据都是不物理删除的,只做逻辑删除 ,比如 is_delete=1
非要物理删除,还要用offset精确查询,还不限制用户分页,怎么办?
分析: 优化思路是 不查,少查,查索引,少取. 这种技巧就是延迟索引.
mysql> select id,name from lx_com inner join (select id from lx_com limit 5000000,10) as tmp using(id);
事务和隔离性:
原子性: 是指某几句sql的影响,要么都发生,要么都不发生.
一致性: 事务前后的数据,保持业务上的合理一致.
隔离性:其他事务,看不到此事务的任何效果.
持久性: 事务一旦发生,不能取消. 只能通过补偿性事务,来抵消效果.
read uncommitted: 读未提交的事务内容,显然不符原子性, 称为”脏读”.
read commited: 读不到另一个进行事务的操作,但是,可以读到另一个结束事务的操作影响.
repeatable read: 可重复读,即在一个事务过程中,所有信息都来自事务开始那一瞬间的信息,
serializeable 串行化 ,隔离的级别最高事务必须编号,事务相互等待的等待长
主从:
步骤:binlog relay-log grant changemaster starslave
状态:
show master status ; 查看master的状态, 尤其是当前的日志及位置
show slave stattus; 查看slave的状态.
reset slave ; 重置slave状态.
start slave ; 启动slave 状态(开始监听msater的变化)
stop slave; 暂停slave状态;
多主:offset increment ==> redis incrby
原则:最左前缀—>顺序 abc= a or ab or abc
匹配类型:全值 最左前缀 列前缀 范围值 精确匹配某一列并范围匹配另外一列 只访问索引的查询,同时,支持order by排序
如果不是按照索引最左列开始查找,无法使用索引
不能跳过索引中的列
某个列进行范围查询,右边的列无法使用索引
如果查询中只有索引包含的列,那么就可以使用索引直接在引擎读取数据行,引擎不用再返回数据行给mysql服务器了
--索引扫描排序
只有当索引的列顺序和order by子句顺完全一致,且所有列的排序方向一致时,才行。索引排序也需要满足最左排序。
如果多张表关联,那么只能用到第一张表的索引。
有一种例外情况,就是覆盖索引,如果有一个常量在where子句,那么可以和order by合并成覆盖索引。
--无法覆盖索引的情况有,不在索引中的列,无法组合成索引的最左前缀,排序方向不一致,有范围查询导致后面索引用不上
















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









