







想下载点离线音乐在车里听歌了,发现各大因为app都要会员,于是朋友发给我一个网站。可是进去发现需要一个一个下载,嫌麻烦,于是····开工
from selenium import webdriver
import requests
from bs4 import BeautifulSoup
import os
options = webdriver.ChromeOptions()
options.add_argument('--headless')
# 给请求指定一个请求头来模拟chrome浏览器
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36',
'cookie':'__51uvsct__JZKGLNhr7gNTmF1z=1; __51vcke__JZKGLNhr7gNTmF1z=dbcc8135-b908-58b9-ab0f-f09772cc8ef9; __51vuft__JZKGLNhr7gNTmF1z=1673170099915; __vtins__JZKGLNhr7gNTmF1z=%7B%22sid%22%3A%20%2250340dc9-526b-5b41-8642-2fa520c011a5%22%2C%20%22vd%22%3A%2030%2C%20%22stt%22%3A%204104371%2C%20%22dr%22%3A%20616811%2C%20%22expires%22%3A%201673176004282%2C%20%22ct%22%3A%201673174204282%7D'
}
server = 'https://www.gequbao.com'
# 凤凰传奇地址
singer = 'https://www.gequbao.com/s/%E8%B4%B9%E7%8E%89%E6%B8%85'
# 获取歌曲内容
def get_contents(song,song_title,singer_name):
# print(song)
save_url = 'G:/python/songs/{}'.format(singer_name)
save_lrc_path = 'G:/python/songs/{}/{}.lrc'.format(singer_name,song_title)
res = requests.get(url=song, headers=headers)
res.encoding = 'utf-8'
html = res.text
soup = BeautifulSoup(html, 'html.parser')
# 获取歌曲的下载链接
driver = webdriver.Chrome(options=options)
driver.get(song)
song_elem = driver.find_element_by_id("btn-download-mp3")
lrc_elem = driver.find_element_by_id("btn-download-lrc")
download_url = song_elem.get_attribute('href')
lrc_url = lrc_elem.get_attribute('href')
# 读取MP3资源
req = requests.get(download_url, stream=True)
# 文件夹不存在,则创建文件夹
folder = os.path.exists(save_url)
if not folder:
os.makedirs(save_url)
# 文件存储地址
full_title = song_title + '.mp3'
file_path = os.path.join(save_url, full_title)
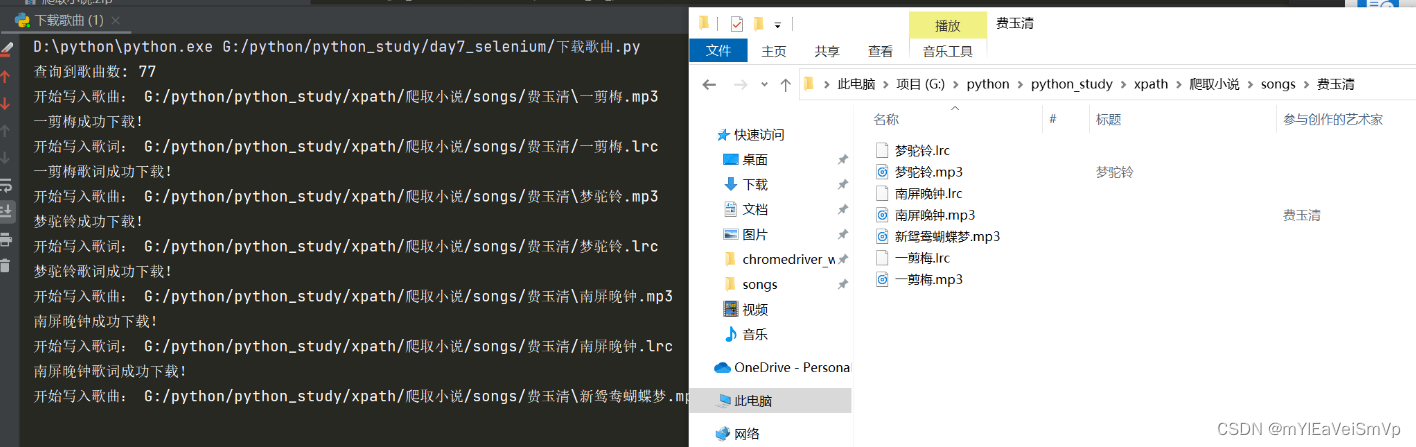
print('开始写入歌曲:', file_path)
# 打开本地文件夹路径file_path,以二进制流方式写入,保存到本地
with open(file_path, 'wb') as fd:
for chunk in req.iter_content():
fd.write(chunk)
print(song_title + '成功下载!')
# 下载歌词
print('开始写入歌词:', save_lrc_path)
r = requests.get(lrc_url).content
with open(save_lrc_path, 'wb') as fd:
fd.write(r)
fd.close()
print(song_title + '歌词成功下载!')
# 主方法
def main():
res = requests.get(singer, headers=headers)
res.encoding = 'utf-8'
html = res.text
# 使用自带的html.parser解析
soup = BeautifulSoup(html, 'html.parser')
# 获取歌曲的列表
songs = soup.find('div', class_='card-text').find_all(class_='text-primary')
singer_name = soup.find('input', id='s-input-line')['value']
print('查询到歌曲数: %d ' % len(songs))
for each in songs:
try:
song = server + each.get('href')
song_title = each.get_text().strip()
get_contents(song,song_title,singer_name)
except Exception as e:
print(e)
if __name__ == '__main__':
main()运行之后需要输入要下载的歌手搜索结果页
下载速度有点慢,而且访问太频繁系统会返回443,但是满足我的需求了,所以也没继续优化,瞎玩呗

















 1142
1142











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











