







文章目录
课程文档:https://github.com/InternLM/Tutorial/tree/camp2
第一课录播:https://www.bilibili.com/video/BV1Vx421X72D
InternLM2 技术报告:arxiv.org/pdf/2403.17297.pdf
为啥已经有些 AI 基础还要再来学下这门课呢?主要考虑是重新走走整条链路,把推的太前的知识巩固巩固,另外也是受到茴香豆项目的影响——白牛大佬在知乎的帖子里有课程链接。于是自然而然就报名了。
闲话少说,以下是笔记。视频课信息量不算大,技术报告是真复杂, 很多内容我也没来得及消化,日后看需要再看要不要往下挖吧。
课程笔记
第一节视频课定位扫盲。业内已经熟知的内容就不记录了,放一些个人觉得有意思或有一定启发性的内容。
InternLM2 在数据处理上的进步
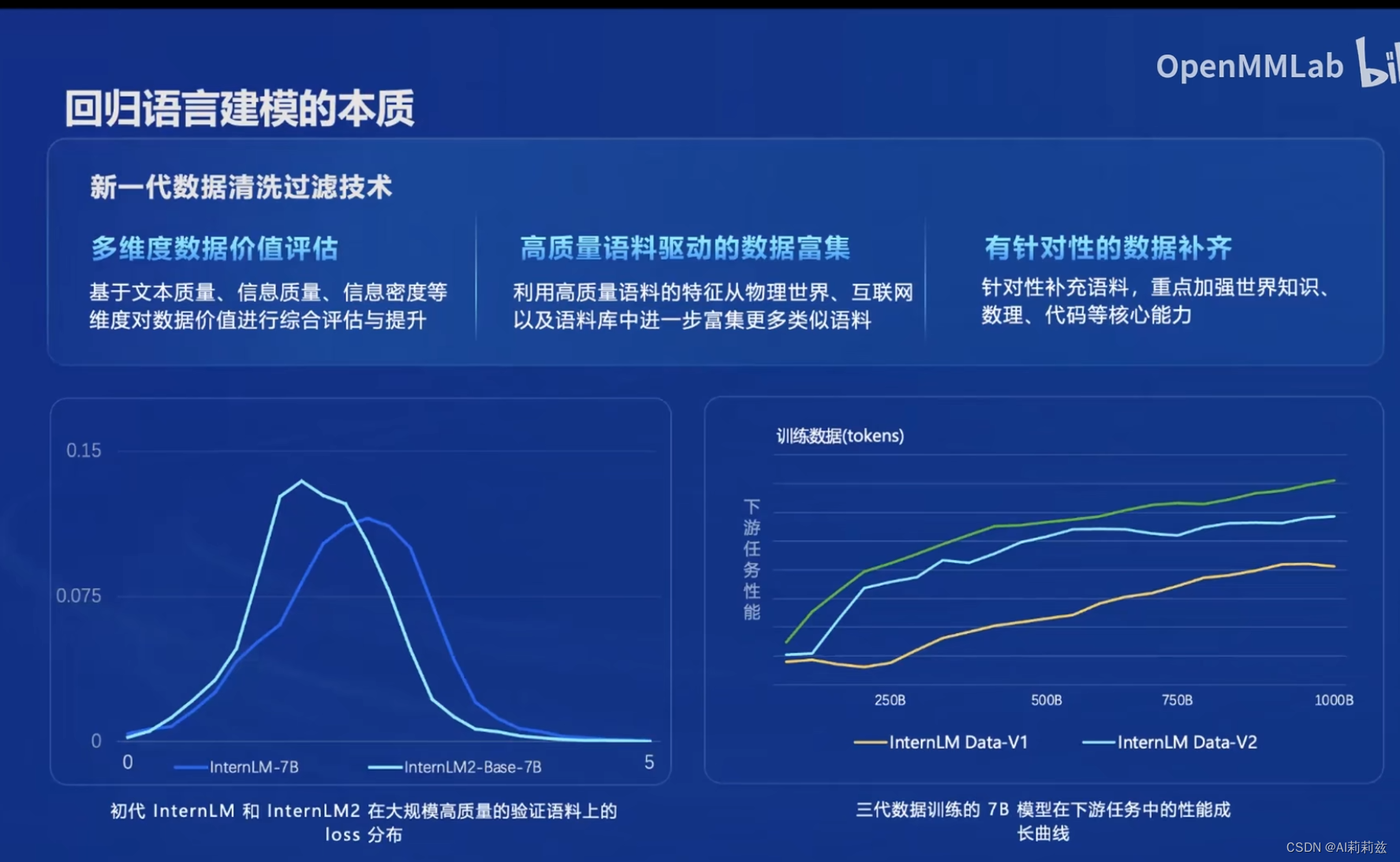
预训练质量高低或是能力水平,基本由预训练数据决定。InternLM2 总结了三个方面的处理思路:
- 对原始语料库做多角度评估:文本质量、信息质量、信息密度应该对应了三类评估数据质量的 metrics,细节不知道是否在 tech report 中有所披露
- 基于已有高质量语料寻找相似语料:在“高质量数据”上 scaling up
- 针对性增强:目前公认大模型的推理能力来自这三个方面,对应的榜单通常是 MMLU、GSM8K/MATH、HumanEval/MBPP
下左图对比两代 7B 模型,可以看到 2 代分布明显左移,侧面意味着训练层面 2 代在更多高质量语料上接受了训练;右侧表明最新一代(V3)上,下游任务性能随训练数据量增长平稳单调提升,亦即 V3 数据对下游任务只有增益而无明显副作用。两张图合起来表明 V3 数据处理方法的有效性。
(这里提个小意见,两张图理解上不是很直观,下右还丢了一个图例,不太严谨哈。)
2.0 版本的主要 features

- 超长上下文按照现在的观点并不惊艳了,技术路径也越发明确,不过在去年底今年初还算得上很 sexy
- 推理能力提升,估计主要来自数据质量提升、补充更多思维链数据以及代码、数学数据的比例提升
- 指令性数据应该经过了校准,输入输出的相关度或针对性得到增强
- function call/agent,现在也挺火
- 再强调下数学、代码和推理?代码解释指的应该是类似 PoT 能力,让模型用代码解决一些有挑战性的问题
这里是 chat wrapper 加了类似 code interpreter 的功能?
从模型到应用
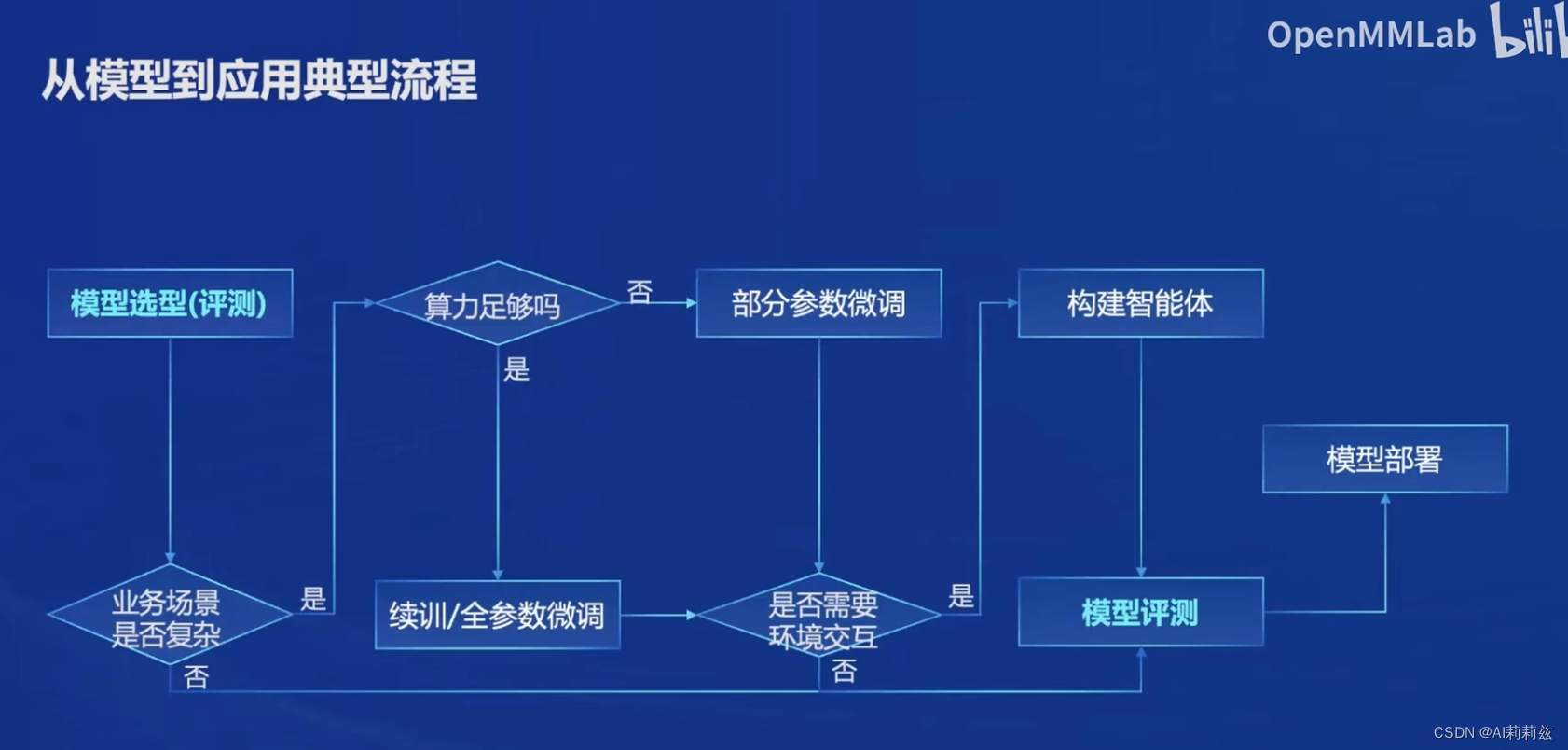
- 第一步在垂域上可能没有大家想得那么简单。比如法律大模型,目前的通用基座在遇到具体问题的时候胡说八道或不精确太正常了。只能用自己的业务数据去测,算法不能完全不懂业务。
- 图上是作为一次性流程描述的,但实际做的时候肯定是循环迭代。

连上这张图就懂了,浦语针对性地提供了解决方案。但恕我直言,这些东西目前开源社区相对还是比较丰富的,更多基于实际场景上的调优 know how 才是最值钱的,当然可能也就没人愿意公开去聊了。

万卷1.0 目前在业内还是挺大的,对没能力自己收集数据的团队很有帮助;万卷CC 是对 CC 的精选吧。两者的定位或特性差异没讲很清楚,有点可惜。
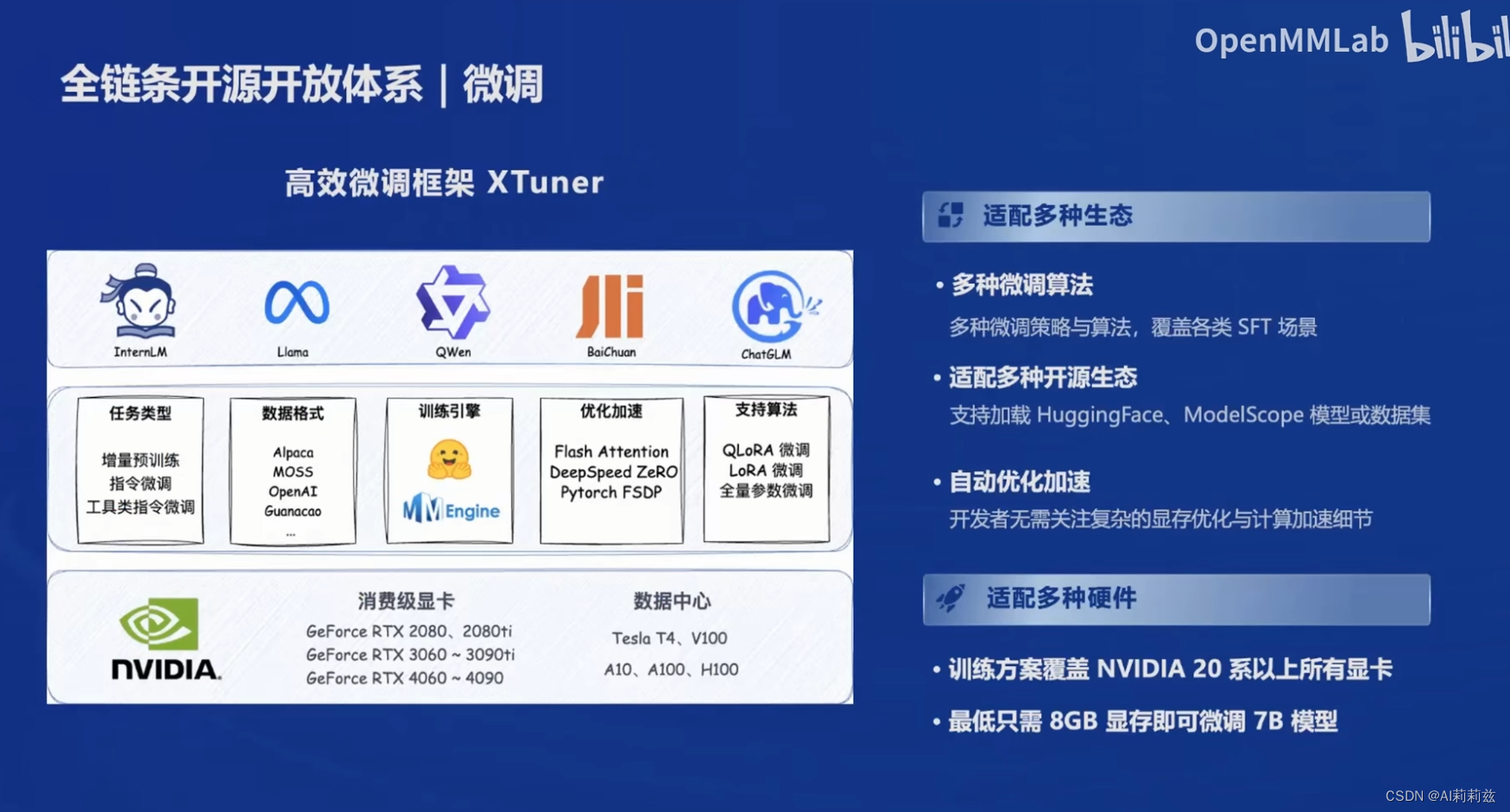
这图别的没啥,就是想暗搓搓问下为啥课程的某位讲师不用 xtuner 而是用了老外做的 axolotl/蝾螈 hhhhhh(开玩笑,跟讲师请教过,说就是随手用来做实验的,没考虑很多)
评测
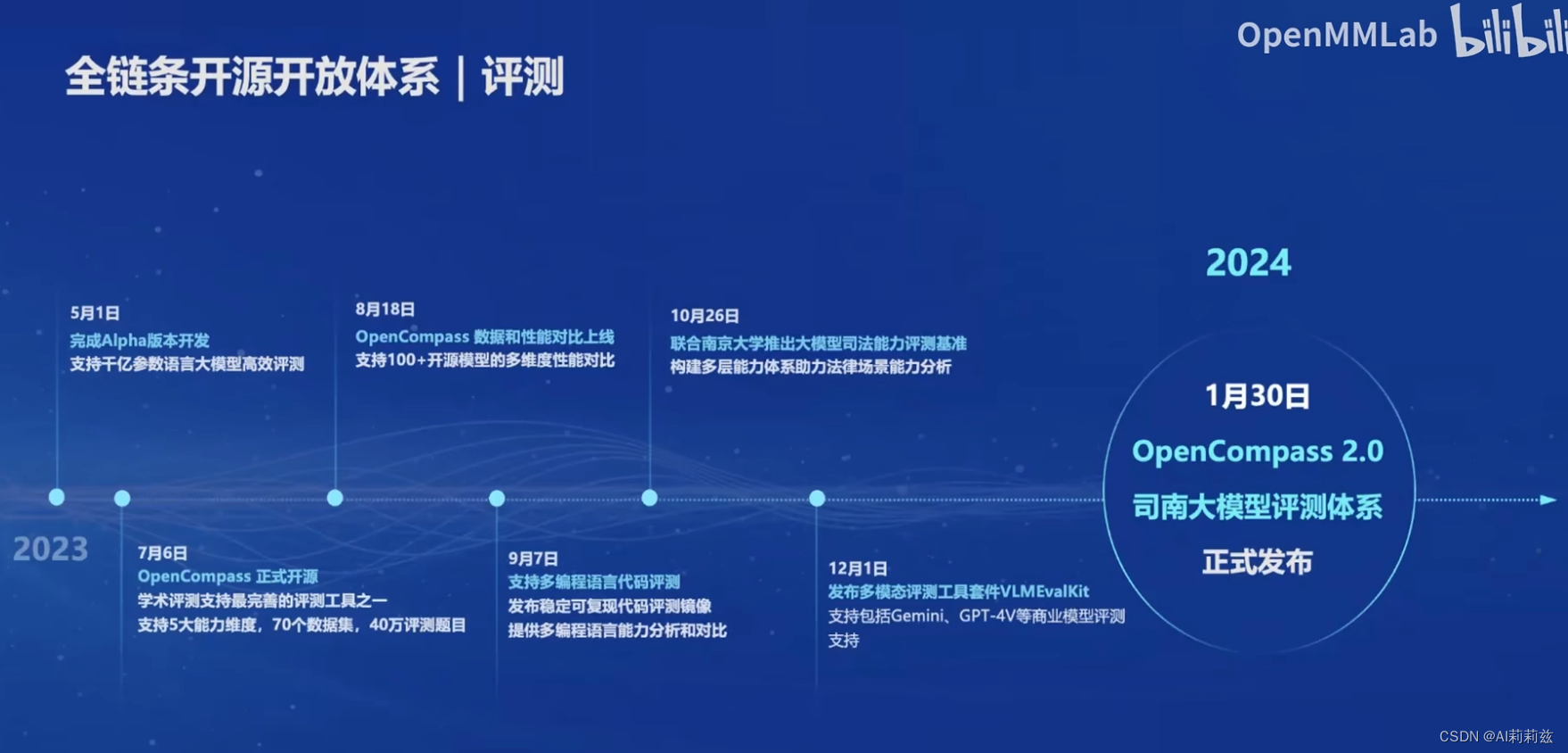
OpenCompass 贡献也挺大的,在中文生态的模型评测上提供了一些标准化的实现和相对可靠的结果。
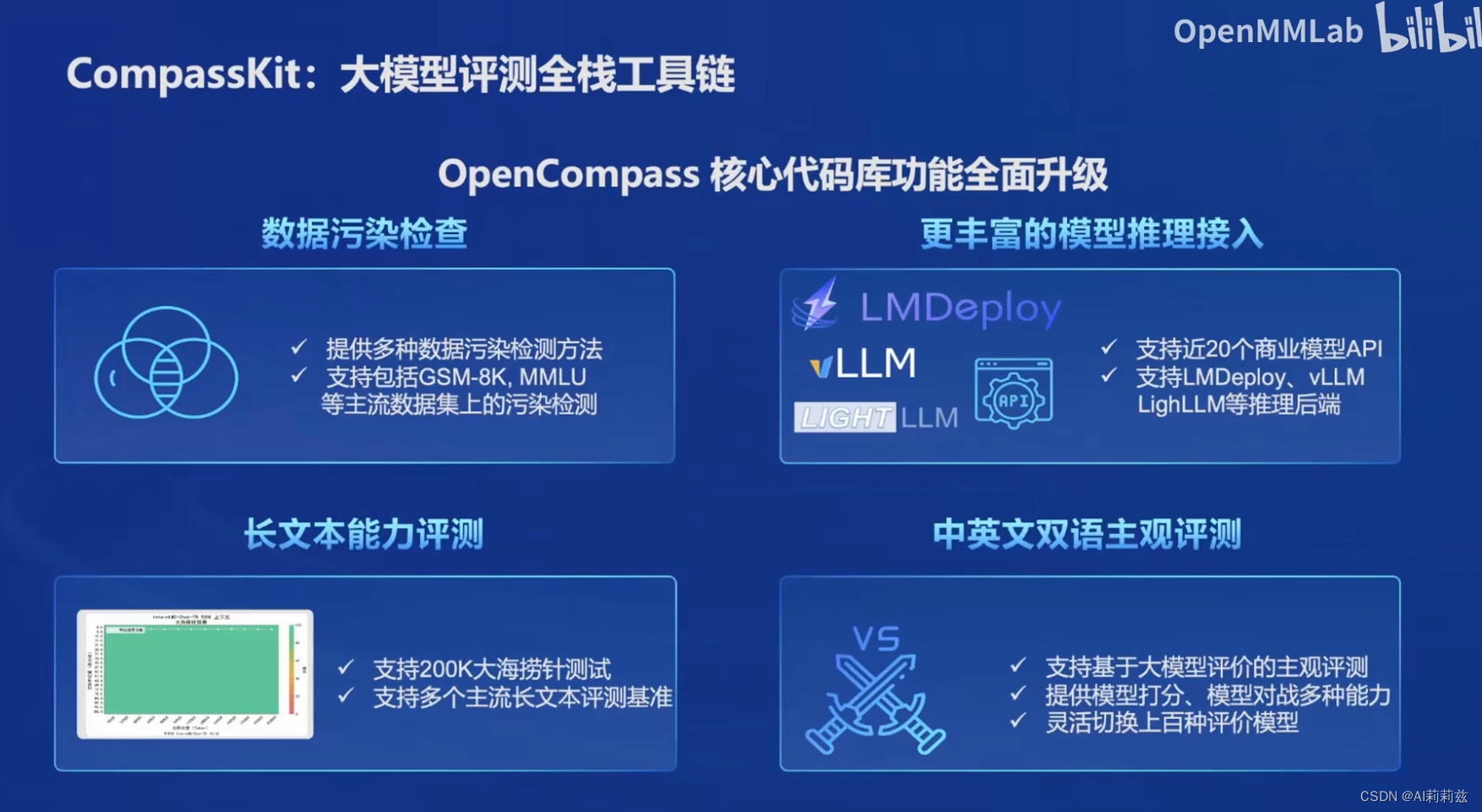

居然有这么大规模的评测,改天瞅瞅去。
而且有些没发布过自家大模型的企业的logo也在里面,狠狠的好奇了。
另外前几天阿里的魔搭终于启动了一个中文的 Chatbot Arena 评测项目,值得期待下。
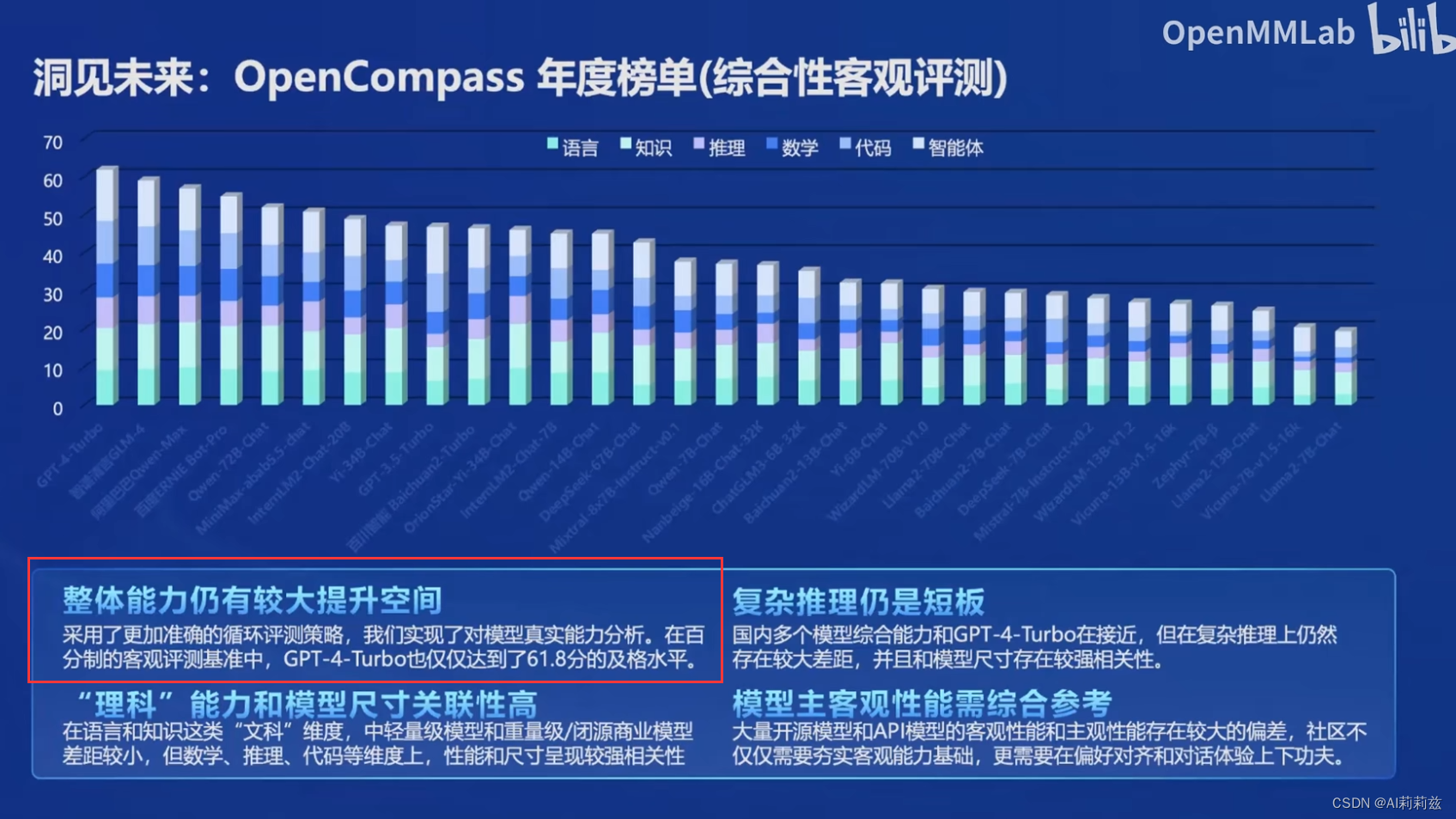
选择题也确实会有这样问题,基于统计概率的模型有时仍然不太能区分选项和选项标号的关系。
部署、Agent 工具确实没了解和体验过,后面可能需要去学习下相关代码了。
InternLM2 技术报告 阅读笔记
英文水平有限,借助沉浸式翻译节省了部分理解时间。
我记得 InternLM2 模型其实出得比较早,技术报告相对晚了不少,CodeQwen、llama3 也类似。
摘要和介绍部分,2代主要强调了几个方面:
- 长上下文的扩展:4k->32K by 训练,200k by 外推;额外 32K 指令数据提高长文本处理
- 数据质量;预训练、代码数据的准备
- COOL RLHF,一种在线RL策略
Infra
不是搞这块的看得似懂非懂
训练框架:InternEvo
做了多个方面的优化工作。他们有专门的 infra 团队,这块的实力确实不容小觑。
模型架构
follow llama 架构但融合相关算子,模型通用但计算上效率更高;GQA 保证长上下文场景下的推理效率
预训练
戏肉来了。
数据
通用文本、编程相关、长文本
文本
-
标准化为 JSON 格式,固定处理步骤包括
- 规则过滤
- 去重
- 安全
- 质量
-
数据源:分成三种类型,网页、书籍、技术文献
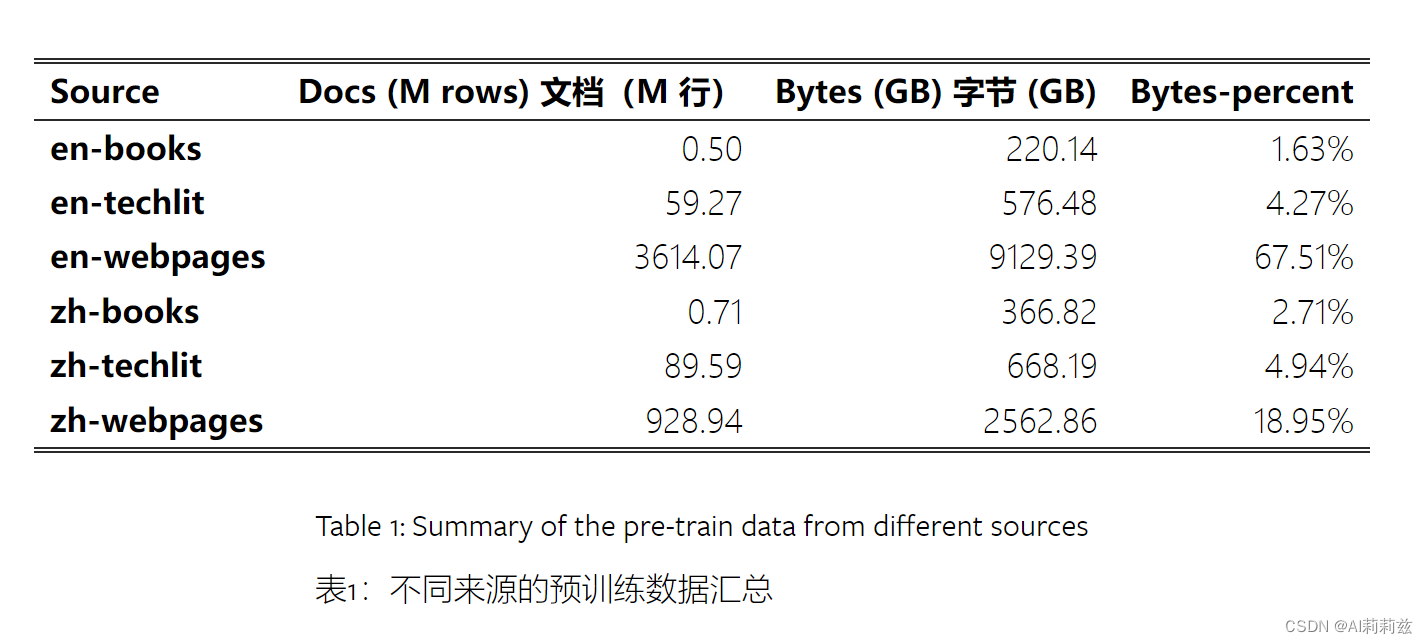
- 网络数据量比较大,总计占到86%
-
处理管道
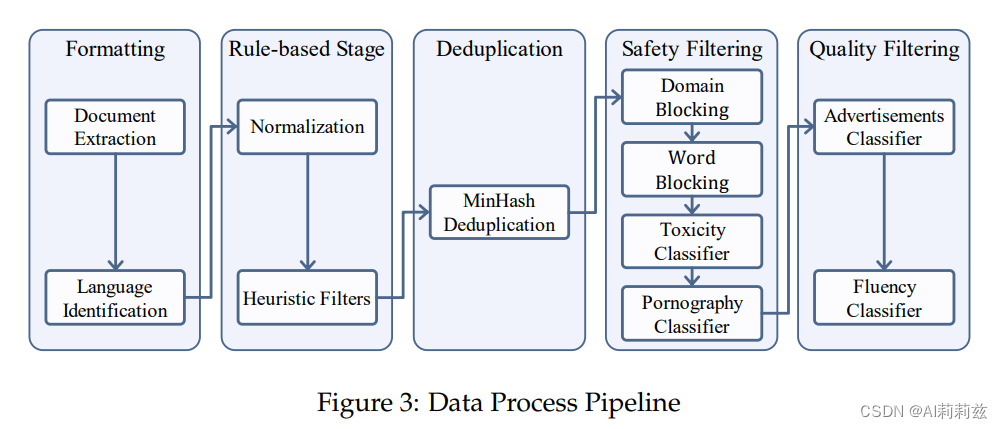
- 格式化:提取、语言检测和分类、标识符、存储
- 规则过滤:去掉解析错误、格式错误和非自然语言;基于启发式文本,重点关注分隔符和换行、异常字符频率、标点分布。这块挺耗人力的,不知道啥时候能有一些生产级的开源
- 去重:MiniHash,标准操作
- 安全过滤:从 GPT-4o 来看国产大模型遥遥领先(bushi)。域名、词汇、分类器,13M 域名+36K 词表黑名单,分词也做了精细考虑;用 Kaggle 数据微调一个“毒性分类器”,用 Perspective API 标注涩情分类数据产生“涩情分类器”,这两个分类器用来做二次过滤
-质量过滤: 过滤网页数据中的广告和缺乏连贯性的内容,分别人工标注得到两个分类器,同样方法过滤
代码
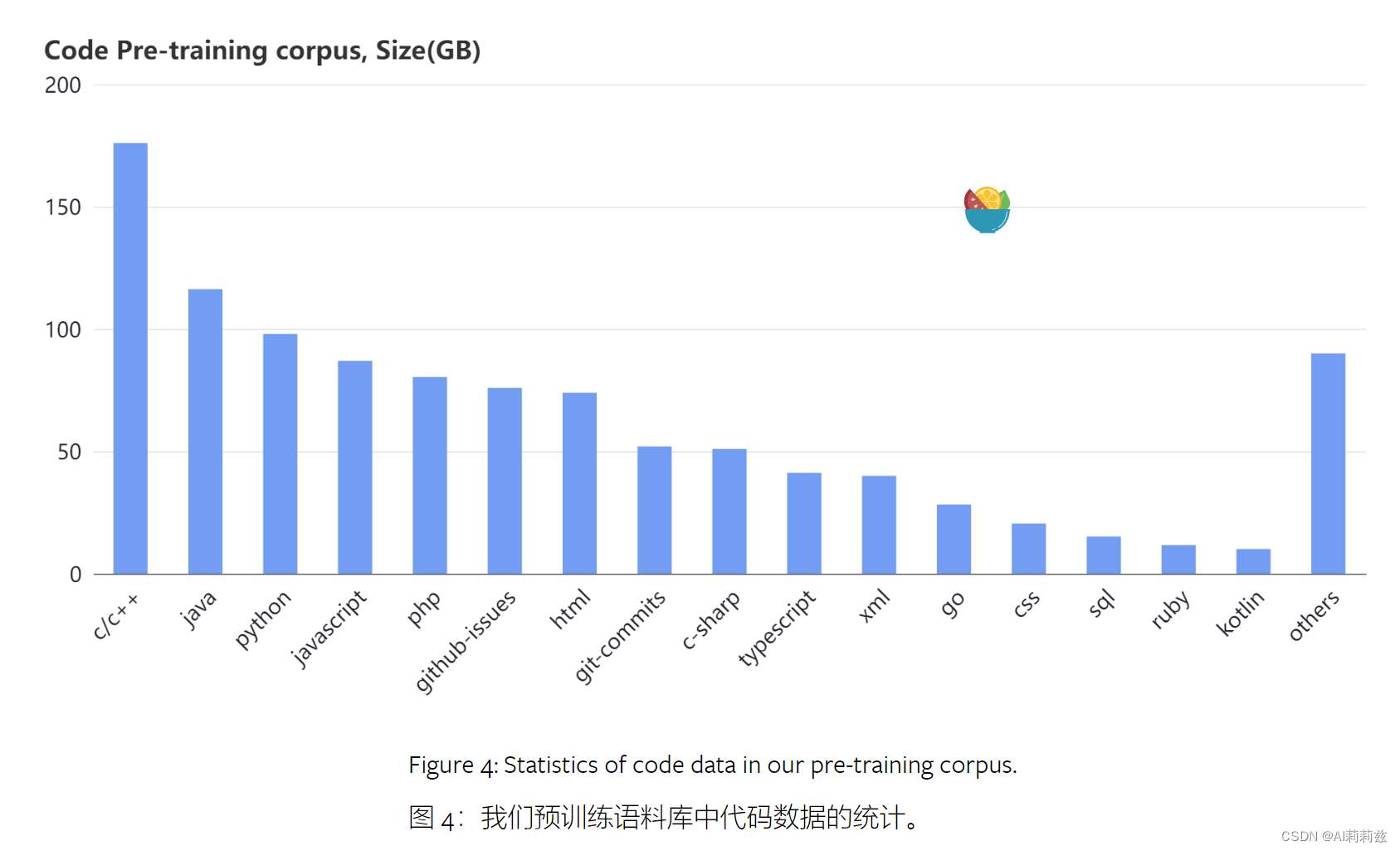
- 数据来源:包括 GitHub、公共数据集、代码相关网站。我好奇 GitHub 数据做了哪些处理,StarCoder 项目很小心地根据 license 排除了大量仓库且开放了检测和删除申请,就这还整天被人找。做闭源模型的厂家反而很少听说因此受到责难。
- 格式清理:所有数据均转换为 markdown 格式——这个操作很有价值。
- 去重:tokenizer 很关键,方法跟处理自然语言类似。去重粒度保持在文件级别
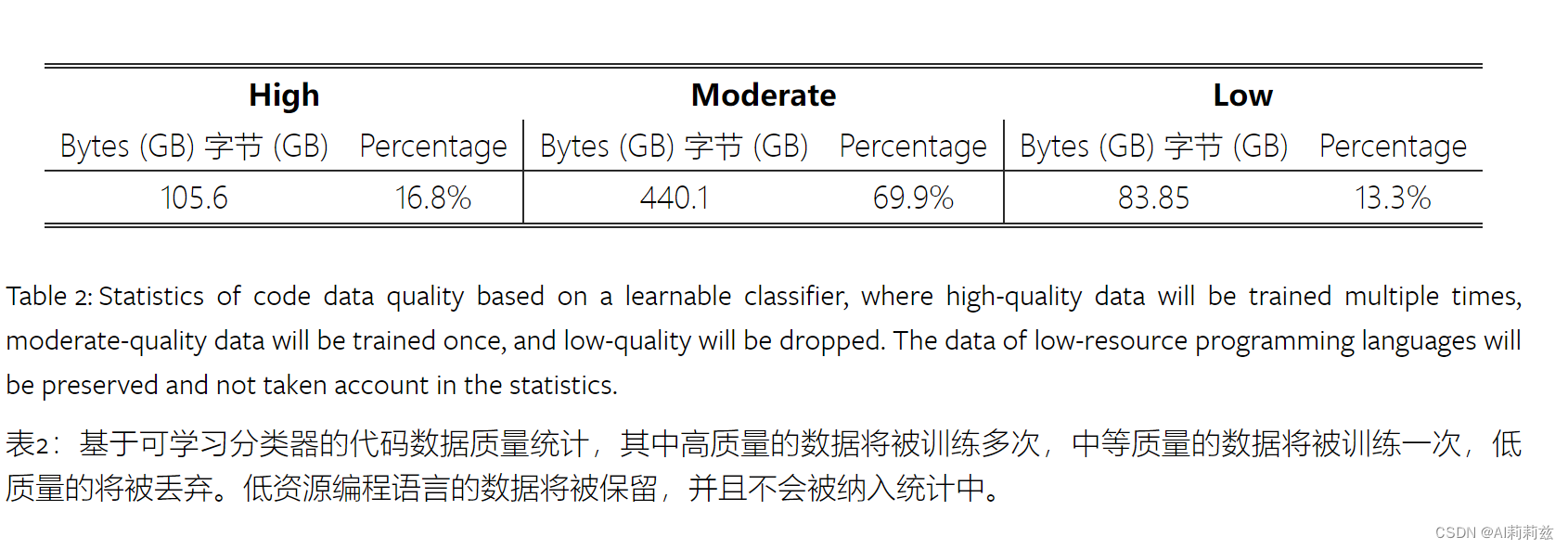
- 质量过滤:同样引入人类标注员但并不容易做。采用混合的多级过滤,基于规则和模型,模型评分与人类标注一致性比较差且跟语言相关,所以最后只用了一致性较高的模型作为过滤器。在构建质量模型过程中,采用了迭代式策略,即得到初版模型后做出预测,人工标注员只检查其输出“置信度”较大的样本。
- 依赖排序:DeepSeekCoder 也做了类似工作(拓扑排序),把 repository 重新组织成从前到后的顺序依赖关系。
长上下文
- 过滤管道:>32K 的文本;识别删除异常数据;困惑度过滤。所选数据都来自标准预训练语料。参考了同组织的 Longwanjuan
- 统计过滤:词汇,语言特征,过滤掉无意义的数据而不是选择高质量数据,对长文本更有效因为其统计特征一致性更充分
- 困惑度过滤器:确保两个片段是顺承关系,做法是估计 S1(靠前文档)、S2的条件概率 P(S2|S1),如果两者强关联,则P应该高于P(S2),否则S1是无关上文。常见错误包括 HTML 解析失败,社交媒体段落、原始数据带有复杂 layout 的情况。
- 阈值选择:两个教训,针对每个任务(domain)指定阈值,例如对长代码、教科书、论文、小说,都需要设定不同的阈值;使用校验集,仅关注边界case
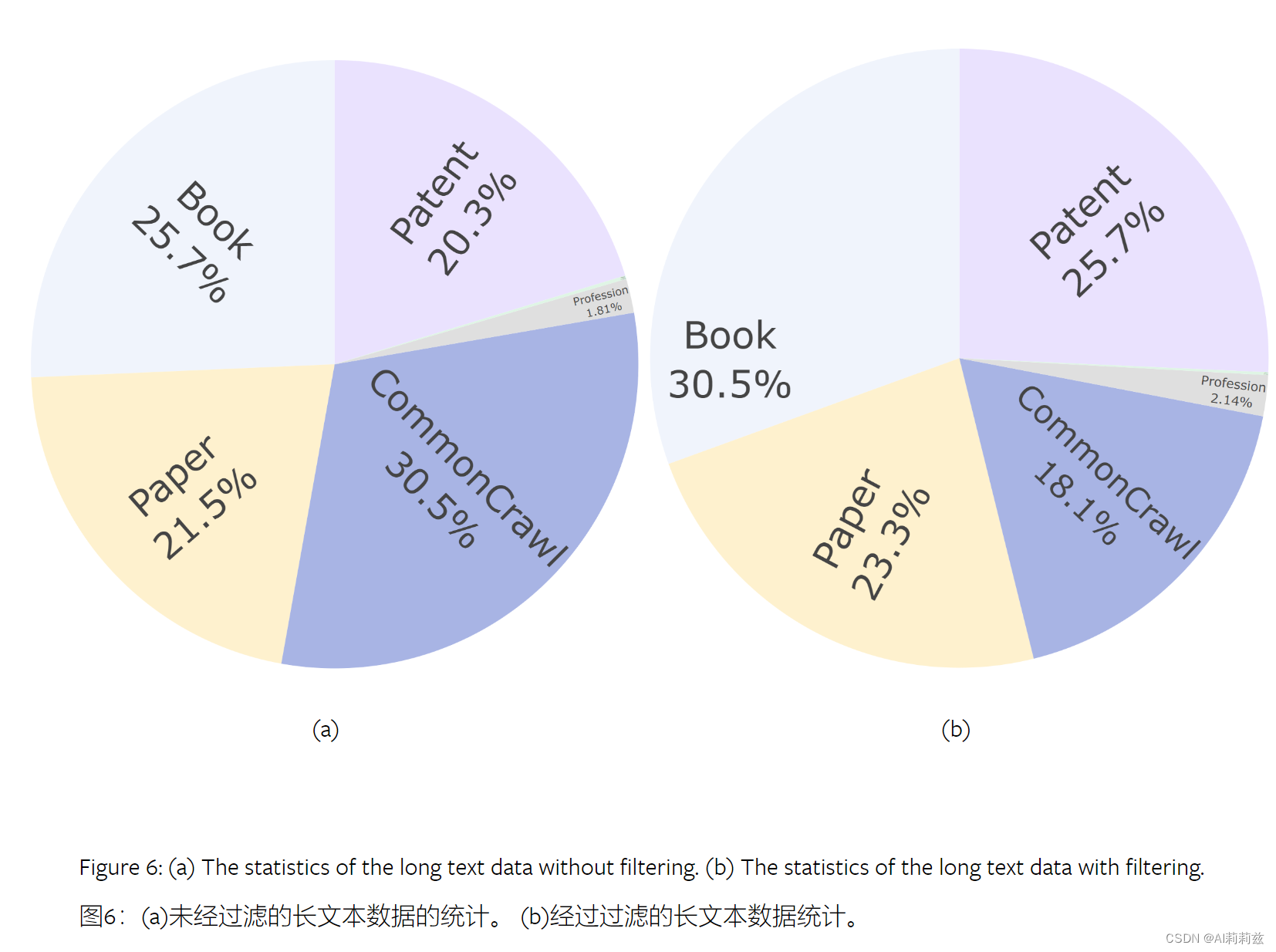
网页、专利减少,图书、文献基本保留(这里没看懂,看不出专利被大幅过滤啊……)
预训练设置
Tokenization
复用GPT-4的方法,参考cl100k词表,使用前60Ktoken+32K中文token+147备用token,最终使其达到256的整数倍以提升效率。
预训练超参数

预训练阶段
三个阶段:(1)<=4k->(2)50%的<=32k->(3)特定能力增强
每个阶段都混合中英文和代码
- 4K阶段:涵盖90%的steps,超过的部分强制截断
- 长上下文阶段:50%的数据仍然是<=4k的,占总steps数的9%,RoPE base 从50K提升到1M,该阶段训练速度下降40%
- 专项提升:在 huggingface 检索得到 24B tokens,经过污染测试。该阶段 lr 和 bz 设置都比较小
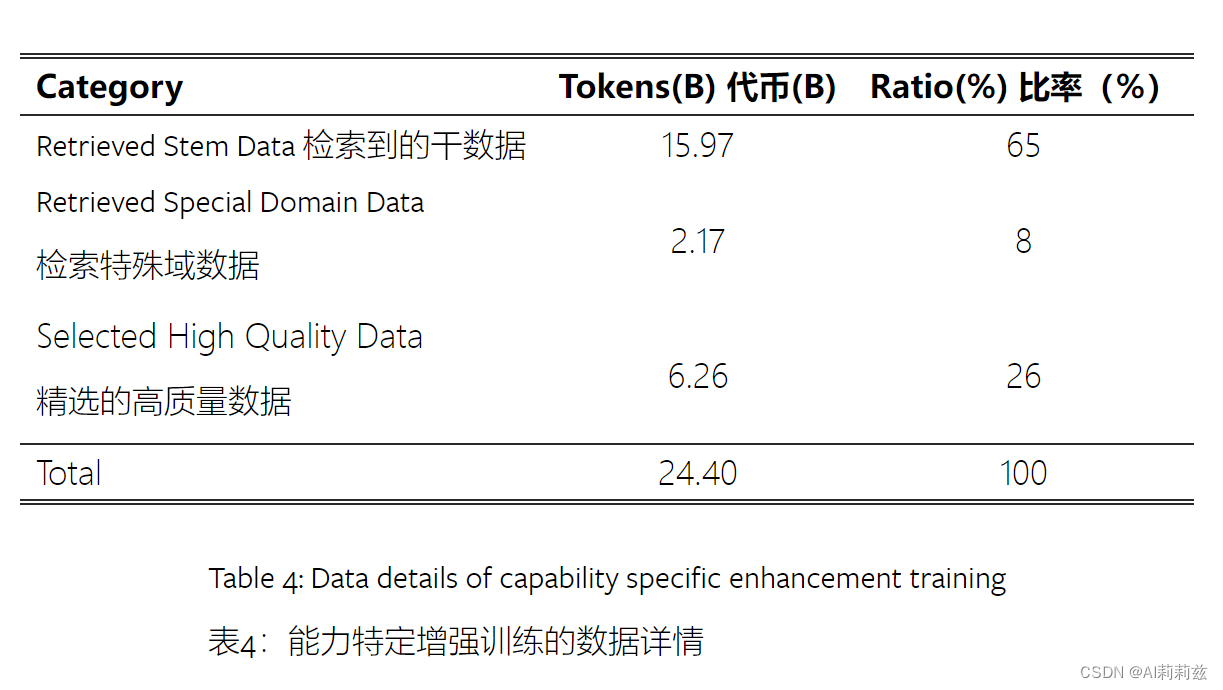
Alignment
- 千万级 SFT 数据。我其实挺好奇如何保证这部分内容的质量,以及如何有效减少因为微调数据分布差异而产生幻觉的倾向
- COOL RL 算法,看起来有点像用不同的 system prompt 使对于不同任务的偏好融合到同一个奖励模型中。下面的内容由于知识水平和实践经验所限没有读得很明白,所以会有胡乱记的情况出现。
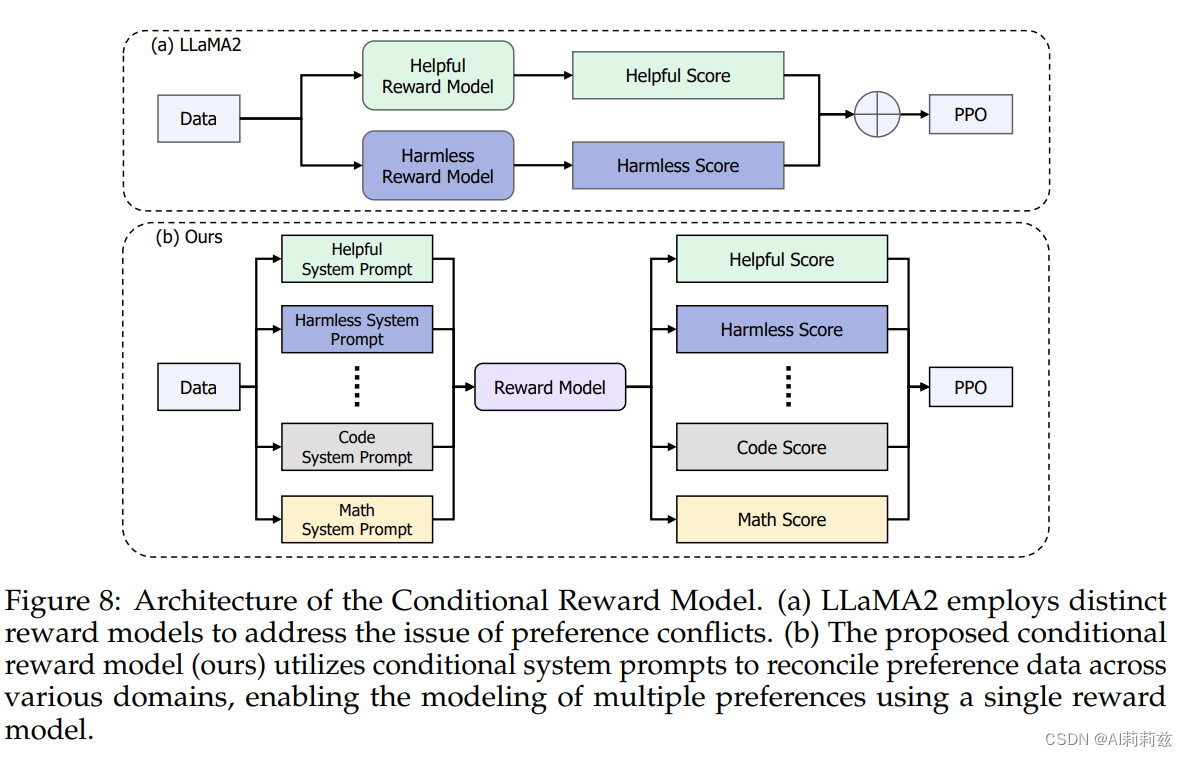
COOL RL
- 数据构成:二值化偏好数据达到了240万条
- 损失函数:将原始排名损失修改为带有焦点的排名公式
- 训练细节:复刻 InstructGPT 基本方法
- Online RLHF:两种不同路径,以减少 RL 阶段模型容易走捷径的倾向
- 快速路径:比较早期和后期 PPO 模型生成的结果,识别出特定模式的偏好对,将其调整后重新加入训练过程
- 慢速路径:使用模型各个阶段的生成结果产生比较对,人工标注放在回路中
- PPO 训练:略
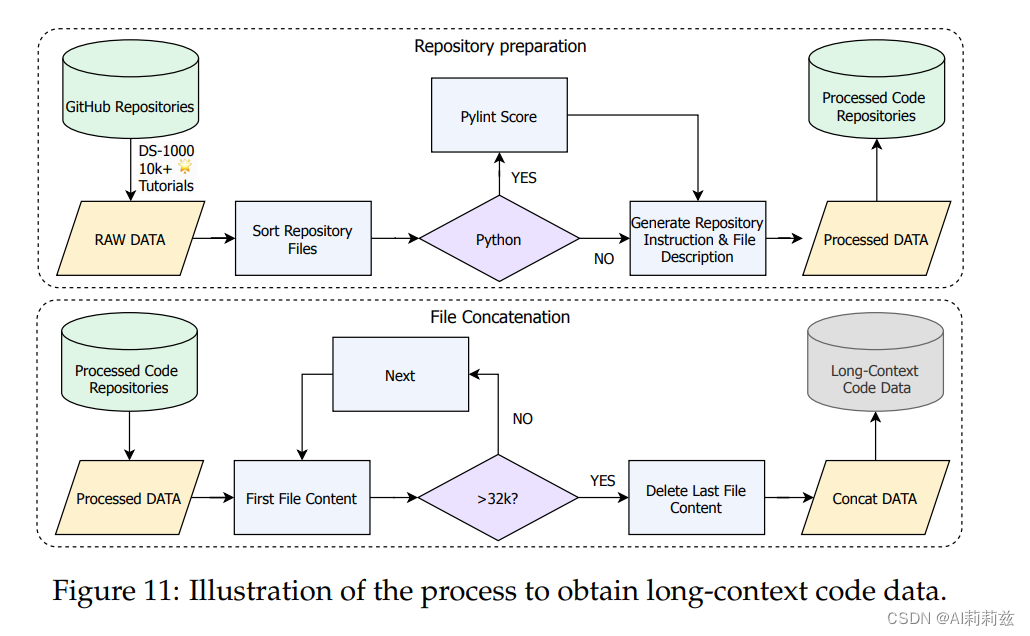
长上下文微调
数据主要由书籍和 GitHub 仓库中的特定样本组成;数据分析能力来自 DS-1000 使用的代码库例如 Pandas、Sklearn等,并且搜索了高星仓库中包含对这些代码库的引用的集合……细节如下图
工具调用
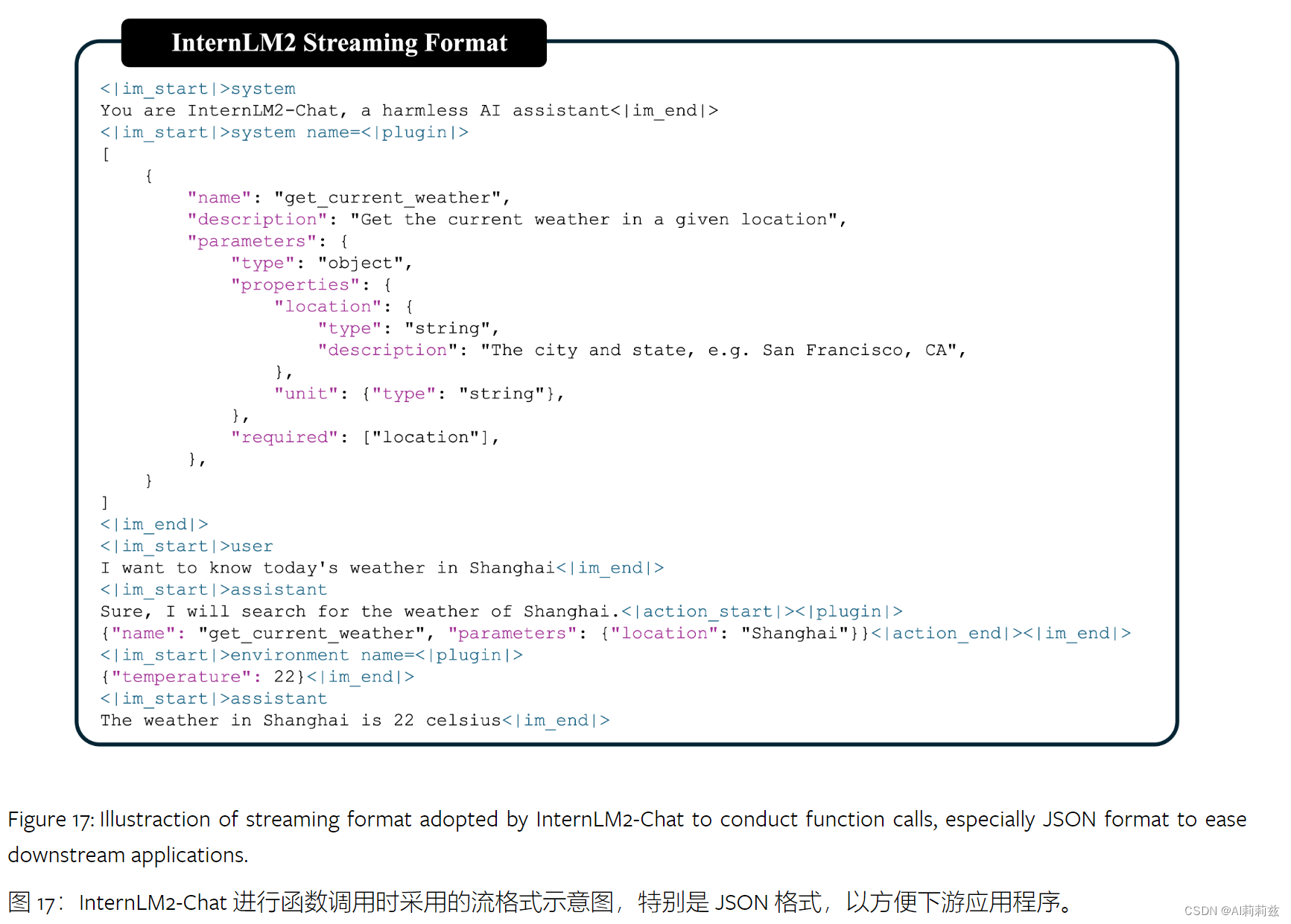
- 修改 ChatML 格式引入环境角色实现,并且定义两个特殊的关键词支持代码解释器和外部插件
- 代码解释器的数据构造参考 InternLM-Math
评估和分析
分出来两大类:下游任务指标和对齐效果。评估库主要使用 OpenCompass
下游性能
几个要点:
- Cool RL 对考试结果影响不大
- InternLM2在推理、数学、代码上表现优秀
- 强化训练的提升显著
- 长上下文评测明显强于同级别模型
对齐
接近 SoTA,不过专门测指令遵循的 IFEval 上国产模型表现都不算好,Mistral 以及后面的 llama3 在这方面都非常强,看来需要研究下 IFEval 到底在测什么了。
污染检查
通过构造相似的新数据集并计算在其上的 loss 差异,计算基座对 GSM8K 的过拟合程度,发现 Qwen 有比较严重的刷题倾向,Baichuan13B、InternLM-SFT 其次。这点我还挺意外的, RSFT、MetaMath 都是阿里的工作而且被广泛认可,为啥 Qwen 好像体现出更好的能力来。
附录
有些内容值得摘录下:
- 包含工具调用的一个交互示例
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









