







1. Motivation of
inception: To make deeper and wider CNN comes with two drawbacks: limitation of examples and increasing computational resources. ==> need to move from fully connected to sparsely connected architectures.
2. Solutions:
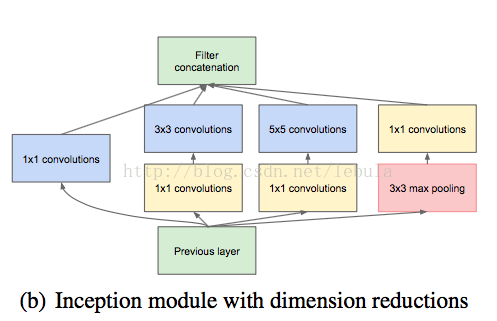
i. use 1 x 1 convolutions before 3 x3 and 5 x 5 ==> reduce redundant infor and reduce dim ( 'keep the network sparse at most places and compress the signals only whenever they have to be aggregated')
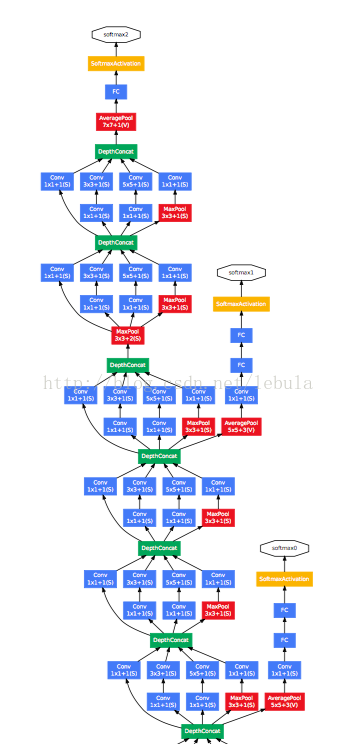
ii. introduce loss functions at hidden layers during training process
a. the model will converge faster (overthrown latter?)
b. loss of final layer: loss of auxiliary classifiers = 1: 0.3















 638
638

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









