






Mydata=read.csv('第3章习题2.csv')
# 数据标准化
data=Mydata[,1:100]
data_std <- scale(data)
# 应用PCA
pca_result <- prcomp(data_std, center = TRUE, scale. = TRUE)
# 提取前3个主成分
principal_components <- pca_result$x[, 1:3]
# 输出主成分的特征向量
loadings <- pca_result$rotation[, 1:3]
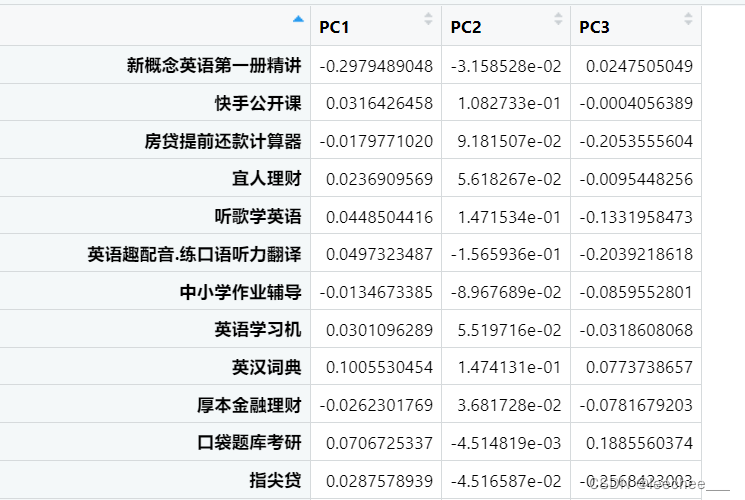
loadings结果展示,也就是特征向量,可以将x变成对应因子的值














 108
108











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









