




这里写目录标题
- `----- 一、文档问答Agent项目 -------`
- 01 大模型语言基础
- ==1.1 llm概念类==
- ==1.2 分词==
- ==1.3 激活函数==
- ==1.4 注意力机制==
- ==1.5 词向量-word2vec==
- ==1.9 NLP三大特征抽取器CNN-RNN-CF==
- ==1.10 常用参数更新方法-梯度下降==
- ==1.11 layer_normalization==
- 1.12 相似度函数篇
- 1.13 FAQ
- 02 大语言模型架构
- 04 分布式训练
- 4.1 FAQ
- 4.2 大模型训练过程
- 4.3 影响大模型训练的大模型参数-模型表达能力、训练效率与性能、过拟合与泛化能力、计算资源需求、存储资源需求、可解释性与透明度
- 4.4 大模型参数调优
- 4.5 LLMs 训练时 有哪些有用的建议
- 05 大模型微调
- 1. 如何计算大模型所需参数
- 2. 为什么SFT之后感觉LLM傻了
- 3. SFT 指令微调数据 如何构建
- 4. 领域模型Continue PreTrain 数据选取
- 5. 领域数据训练后,通用能力往往会有所下降,如何缓解模型遗忘通用能力?
- 6. 领域模型Continue PreTrain ,如何 让模型在预训练过程中就学习到更多的知识
- 7. 进行SFT操作的时候,基座模型选用Chat还是Base
- 8. 领域模型微调 领域评测集 构建
- 9. 领域模型词表扩增是不是有必要的
- 10. 如何训练自己的大模型
- 11. 训练中文大模型有啥经验?
- 12 指令微调的好处
- 14 预训练和微调哪个阶段注入知识的
- 15 多轮对话任务如何微调模型
- 17 微调后的模型出现能力劣化,灾难性遗忘是怎么回事
- 18 大模型LLM进行SFT操作的时候在学习什么
- 19 预训练和SFT操作有什么不同
- 20 样本量规模增大,训练出现OOM错
- 22. 大模型LLM进行SFT 如何对样本进行优化?
- 23. 微调大模型的一些建议
- 24.微调大模型时,如果 batch size 设置太小 会出现什么问题
- 25.微调大模型时,如果 batch size 设置太大 会出现什么问题
- 26. 微调大模型时, batch size 如何设置问题
- 27 大模型训练loss突刺原因和解决办法
- 06 推理
- 07 强化学习
- 08 大模型评估
- 09 应用
- `--------------项目--------------`
- 01 RAG
- 02 项目-智能客服
- 1. 架构
- 03 FAQ
- 04 多模态
----- 一、文档问答Agent项目 -------
学习方向
链接: link
- 论文偏于网络结构优化,难以吸引面试官眼球
- 大模型从0到1的经验非常珍贵:
- 大模型预训练经验,7B全量的微调起步的8张40GB的A100,65B的全量微调起步得上百张了
- 这个过程中会考虑选型、部署、微调、处理幻觉风控问题- 大模型评测非常重要,但是存在缺陷
- 相关经验扎实,基本不问八股,但是学校及项目比较好想转型,会考虑潜质问题
01 简历描述
| 项目 | Value |
|---|---|
| 文档问答Agent系统 | 招商银行AI赛道训练营-个人参赛、 |
| 【比赛背景】 | 以大模型为中心构建一个Agent,对文档数据进行解析和理解,回答用户的相关问题,完成文档问答需求 |
| 【模型选择】 | 大语言模型:Qwen1.5-14B-Chat; |
| 嵌入模型-文本转向量:bge-large-zh-v1.5; | |
| Reranker 模型:BGE-reranker-large | |
| 【方案流程】 | 1. 普通模块:用户提问→文档筛选→意图识别→检索模块(BM25、HyDE)→公共模块(重排序→LLM→输出) |
| 2. 核心模块:导入文档→文档处理→嵌入模块→Fasis模块→检索模块(BM25、HyDE)→公共模块(重排序→LLM→输出) | |
| 【模型微调】 | 1. 问题需求:针对去除千分位分隔符和保留小数点后两位这两个指令需求,大模型遵守的并不好 |
| 2. 数据集构建:使用step模型的api生成带有指令的有/无千分位分隔符的文本对和有/无小数点后保留两位的文本对(200) | |
| 3. 方法:使用Llama-Factory 框架进行AdaLoRA微调,占用40G显存,训练3个epoch |
1 大语言模型的选择
- 考虑到比赛会涉及到 Agent 的构建,LLM 的选择要优先选择具备 Function Call 或 ReAct 能力的模型
- Llama3-8B-Instruct 模型,是对于中文 Byte 的 token 和语料都训练不足
- Qwen1.5-14B-Chat 版本,因为它具备同参数量下较强的通用能力之外,还支持 ReAct 调用,除此之外 1.5 版本的滑动窗口机制对推理的加速效果有很大的提升
- 囿于服务器没有 root 权限、以及英伟达驱动版本过低的问题,舍弃了 vLLM 和 TGI 推理加速框架,选择了 ModelScope 的 SWIFT 框架进行本
地的部署
02 Llama3-8B-Instruct
1. Llama 3 仍旧使用Decoder-only的 Transformer 架构
1. 特点
- LLaMA 3和LLaMA 2基本没有区别,同样使用了Transformer的Decoder-only架构(由编码器(Encoder)和解码器(Decoder)两个部分构成),加入RMSNorm预归一化,使用 SwiGLU 激活函数和旋转位置嵌入,使用了改进的注意力机制GQA,增加了上下文长度
2. decoder结构
- 采用前置的RMSNorm作为层归一化方法(Layer Norm之上的改进)
- 为了提高模型性能,采用SwiGLU作为激活函数
- SwiGLU激活函数的主要思想是引入一个门控机制,用于控制输入信号在激活函数中的传递方式。它由两个部分组成:GLU(Gated Linear Unit)和Swish函数
- GLU部分接受输入信号并执行门控操作,其目的是对输入信号进行筛选和选择性放大。它由一个sigmoid激活函数作为门控器,将输入信号转换为范围在0和1之间的值。这个值可以被解释为对输入信号的重要性或影响程度。然后,GLU将输入信号与门控值相乘,以便选择性地放大或抑制输入。
- Swish部分是一个非线性函数,类似于ReLU(Rectified Linear Unit),它将输入信号进行非线性变换。Swish函数定义为 x * sigmoid(x)。Swish函数的特点是在输入为正数时逐渐趋向于线性变换,而在输入为负数时则具有非线性的抑制效果
- SwiGLU激活函数的主要思想是引入一个门控机制,用于控制输入信号在激活函数中的传递方式。它由两个部分组成:GLU(Gated Linear Unit)和Swish函数
- 为了更好地建模长序列数据,采用RoPE作为位置编码
- 旋转编码 RoPE 可以有效地保持位置信息的相对关系,即相邻位置的编码之间有一定的相似性,而远离位置的编码之间有一定的差异性
- 旋转编码 RoPE 可以通过旋转矩阵来实现位置编码的外推,即可以通过旋转矩阵来生成超过预训练长度的位置编码。这样可以提高模型的泛化能力和鲁棒性
- 旋转编码 RoPE 可以与线性注意力机制兼容,即不需要额外的计算或参数来实现相对位置编码。这样可以降低模型的计算复杂度和内存消耗
- 为了平衡性能和准确度,采用了分组查询注意力机制(GQA)
- 首先将输入的token序列通过词嵌入(word embedding)矩阵转化为词向量序列。然后,词向量序列作为隐藏层状态依次通过 个解码器层,并在最后使用RMSNorm进行归一化。归一化后的隐藏层状态将作为最后的输出
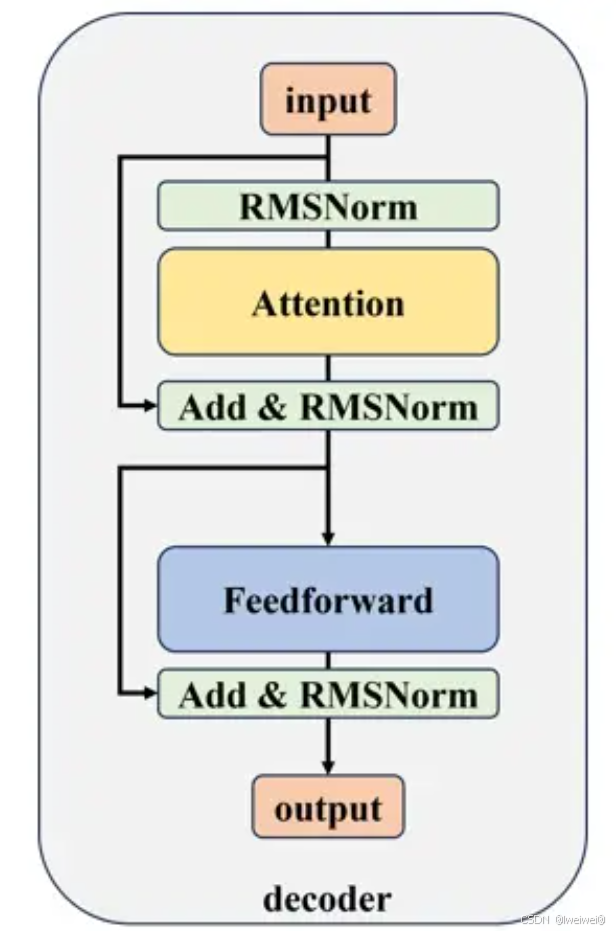
- 首先将输入的token序列通过词嵌入(word embedding)矩阵转化为词向量序列。然后,词向量序列作为隐藏层状态依次通过 个解码器层,并在最后使用RMSNorm进行归一化。归一化后的隐藏层状态将作为最后的输出
2. Llama 3 训练
- 在预训练阶段:通过为下游基准测试制定一系列扩展法则(scaling laws),使得在训练之前就能预测出模型在关键任务上的性能,进而选择最佳的数据组合
- Meta结合了三种并行策略:数据并行、模型并行和流水并行
- 为了最大限度地延长GPU的正常运行时间,Meta开发了一个先进的训练堆栈,可以自动检测、处理和维护错误。另外还大大提高了硬件可靠性和无声数据损坏的检测机制,并开发了新的可扩展存储系统,减少了检查点和回滚的开销
- 在微调阶段,Meta对模型的微调方法进行了重大创新,结合了有监督微调(Supervised Fine-Tuning, SFT)、拒绝采样、近似策略优化(Proximal Policy Optimization, PPO)和直接策略优化(Direct Policy Optimization, DPO)。
使用Normalization的目的、方法
1. 解决问题
- 当我们使用梯度下降法做优化时,随着网络深度的增加,输入数据的特征分布会不断发生变化,为了保证数据特征分布的稳定性,会加入Normalization。
- 从而可以使用更大的学习率,从而加速模型的收敛速度。同时,Normalization也有一定的抗过拟合作用,使训练过程更加平稳。
- 具体地,Normalization的主要作用就是把每层特征输入到激活函数之前,对它们进行normalization****,使其转换为均值为0,方差为1的数据,从而可以避免数据落在激活函数的饱和区,以减少梯度消失的问题。
2.实现方法
- LayerNorm & BatchNorm,BN(BatchNorm)和LN(LayerNorm)是两种最常用的Normalization的方法,它们都是将输入特征转换为均值为0,方差为1的数据
- 只不过,BN是对一个batch-size样本内的每个特征做归一化,LN是对每个样本的所有特征做归一化。以一个二维矩阵为例,它的行数代表batch_size,列数代表fea_nums。BN就是竖着进行归一化,LN则是横着进行归一化。
- BN抹平了不同特征之间的大小关系,而保留了不同样本之间的大小关系
- LN抹平了不同样本之间的大小关系,而保留了不同特征之间的大小关系
ReACT框架
其核心思想是将推理和行动结合起来,形成一个智能、自主的智能体结构,并拥有与外部环境交互的能力
Function Call
-
Function Calling 是一个允许大型语言模型(如 GPT)在生成文本的过程中调用外部函数或服务的功能。
-
Function Calling允许我们以 JSON 格式向 LLM 模型描述函数,并使用模型的固有推理能力来决定在生成响应之前是否调用该函数。模型本身不执行函数,而是生成包含函数名称和执行函数所需的参数的 JSON
-
函数调用机制的主要步骤:
- 一、用户输入:用户通过自然语言向模型提出问题或请求。这些问题或请求可能需要调用外部函数来获取答案或执行某些操作。
- 二、模型解析:模型接收到用户输入后,会解析并理解输入内容。模型会根据其训练数据和算法判断是否需要调用函数,并确定要调用的函数及其参数。
- 三、生成函数调用:如果模型确定需要调用函数,它会生成一个包含函数调用所需参数的结构化输出。这通常是一个JSON对象,其中包含函数名、参数列表等信息。这JSON对象是以字符串形式存在的,需要在实际调用函数之前进行解析。
- 四、函数调用执行:在您的代码中,您需要解析这个字符串化的JSON对象,将其转换为有效的数据结构(如字典或对象),并使用这些参数调用相应的函数。这个过程是在您的代码环境中完成的,而不是在模型内部。模型只是提供了调用函数所需的参数和信息。
- 五、处理函数结果:函数调用执行完成后,您需要将函数的结果返回给模型。这通常通过将结果附加到模型中再次调用模型来实现。模型会接收并处理这些结果,然后生成一个自然语言回复给用户,总结或解释函数调用的结果。
03. 大语言模型:Qwen1.5-14B-Chat
- Qwen1.5是一个典型decoder-only的transformers大模型结构,主要包括文本输入层、embedding层、decoder层、输出层及损失函数
- 输入层:
- Tokenizer:将输入的文本序列转换为字或词标记的序列
- Input_ids:将Tokenizer生成的词标记ID化。
- Embedding层:
- 将每个ID映射到一个固定维度的向量,生成一个向量序列作为模型的初始输入表示
- Decoder层:堆叠一堆重复的Layers,每个内部相似
- Self-Attention机制:多头自注意力机制,通俗理解每个头表示隐形的特征,针对NLP特征可以是动名词,主谓宾等,针对推荐系统可以是item标签、item类型等
- Feed-Forward Network (MLP):多层DNN神经网络感知机,用于交叉特征信息
- Residual Connection:残差连接网络,在深度学习中经常用到的技巧,在神经网络的层与层之间添加一个直接的连接,允许输入信号无损地传递到较深的层。这样设计的目的是为了缓解梯度消失和梯度爆炸问题,同时促进梯度在深层网络中的流畅传播,使得训练更高效,模型更容易学习复杂的特征
- Normalization层(如RMSNorm):标准化,这里使用RMSNorm(均方根标准化)代替LayerNorm(层标准化),具有加速训练和改善模型的泛化能力的效果,在实际的推荐系统工作中经常用到BatchNorm(批量标准化),在神经元激活函数前,加上一个BN层,使得每个批次的神经元输出遵循标准正态分布,解决深度传播过程中随数据分布产生的协变量偏移问题。
- Rotary Position Embedding(RoPE):旋转位置编码,LLaMA也在用,可以更好的学习词之间的位置信息
优点:
- 上下文size:统统调整为32K,不用再改来改去了
- 代码合并进transformers:纯开源!不用再使用trust_remote_code了,要求transformers>=4.37.0
- 全尺寸通吃:这个太狠了,不管你有什么样的硬件条件,贫穷还是富有,Qwen都爱你
- 所有模型均支持system prompt:更好的支持工具调用、RAG(检索增强文本生成)、角色扮演、AI Agent等
04. 嵌入模型-文本转向量:bge-large-zh-v1.5(RAG之微调垂域BGE)
- bge-large-zh是一个针对中文文本的预训练模型,其核心功能是将文本转换为高维向量表示。这些向量捕捉了文本中的语义信息,使得语义上相似的文本在向量空间中的距离更近。这种表示方法为后续的相似性搜索和聚类提供了便利
1. BGE-M3 模型的原理-基于BERT
结构
- Tokenization
- 将输入文本转成 token 序列
- BERT 还会插入两个特殊的 token:[CLS] token 表示开始,[SEP] token 表示一个句子的结束。
- Embedding:使用 embedding matrix 将每个 token 转换为一个向量,详见 BERT 论文;
- Encoding:这些向量通过多层 encoder,每层由 self-attention 和 feed-forward 神经网络组成会根据所有其他 token 提供的上下文细化每个 token 的表示。
- Output:输出一系列最终的 embedding vectors。
最终生成的 dense embedding 能够捕捉单个单词的含义及其在句子中的相互关系
- BERT特点
- 基于 transformer 的预训练(pretrain)语言模型 BERT 的出现,彻底颠覆了传统的信息检索范式
- BERT 是双向(前向+后向)transformer,
- 可以理解为在预训练时,每个句子正向读一遍,反向再读一遍
- 能更好地捕获句子的上下文语义(contextual semantics)
- 最终输出是一个 dense vector,本质上是对语义的压缩
基于 BERT dense embedding 的文档检索
- 有了 dense embedding 之后,针对给定文本输入检索文档就很简单了,只需要再加一个最近邻之类的算法就行
- 下面是两个句子的相似度判断,原理跟文档检索是一样的
2. BGE-M3(BERT-based learned sparse embedding)是如何工作的
M3 = Multi-Functionality、Multi-Linguisticity、Multi-Granularity
BGE-M3 通过更精细的方法来捕捉每个 token 的重要性,
- Token importance estimation:BERT 在分类/相似性比较时仅关注第一个 token([CLS]), BGE-M3 则扩大到关注序列中的每个 token Hi;
- 线性变换:在 encoder 的输出层上又增加一个线性层,计算每个 token 的 importance weights Wlex
- 激活函数
- Wlex 和 Hi 的乘积经过 Rectified Linear Unit (ReLU) 激活函数,得到每个 token 的术语权重 Wt
- ReLU 的结果是非负的,有助于 embedding 的稀疏性
- learned sparse embedding:以上输出的是一个 sparse embedding,其中每个 token 都有一个相关的 weights,表明在整个输入文本上下文中的重要性
补:MTEB指标包含些啥
- Retrival :是信息检索领域中用于评估排名质量的一种指标。NDCG@k 是 NDCG 的一个变种,其中 “@k” 表示考虑排名的前 k 个文档
- Re-Ranking:MAP(Mean Average Precision,计算一组文档重排的指标。其衡量的是,是否能够根据query,正确的区分正样本和负样本
- STS (Semantic Textual Similarity):语义文本相似度,其数据形式是一对文本,标签是其是否相关。该类任务的关键指标采用的是Spearman秩相关性系数,文本对的标签有两类,相关是1,不相关是0。当采用该指标时,需同时计算很多对文本对。
补:C-MTEB则是专门针对中文文本向量的评测基准
- 智源的 BGE-reranker-large
- 无论使用何种嵌入模型,重新排序都显示出更高的命中率和MRR,这表明重新排序的显著影响;
- 目前,最好的重新排名模型是Cohere[1],但它是一种付费服务。开源bge-reranker-large模型具有与Cohere类似的功能;
嵌入模型和重新排序模型的组合也会产生影响,因此开发人员可能需要在实际过程中尝试不同的组合。
05 Reranker 模型:BGE-reranker-large
为什么要Reranker 模型
- 经过第一步使用cosin余弦相似度从密集向量数据库 + keyword search(稀疏向量召回)初步召回top K相似度的文本,按理来说就可以让LLM根据用户的query + 召回的context生成最终答案了
- 实际召回的context中包含北京的文本不一定排在前面,可能在中间甚至后面,给最后一个LLM输入的context会很大,直接导致LLM需要处理很长的文本,推理效率低不说,还容易出错,核心问题还是在于:初步召回的context还是有进一步压缩提炼的空间
- 用cosin求两个向量的相似度,本质是看两个向量的距离。比如“北京”、“上海”、“深圳”这些都是中国的一线大城市,这3个词的embedding的cosin会很近,所以使用cosin召回的时候也可能把“上海”、“深圳”这些不是正确答案的sentence召回,所以要用tf-idf这类稀疏向量补充召回部分向量,整个过程称为 hybrid search。经过hybird search后,召回的context变多,给最后一步的LLM生成最终答案带来了麻烦,所以需要进一步从context中继续提炼,优中选优
- 比如初步召回20条,需要通过rerank选择更接近的3~5条,这个过程就是rerank
- cosin计算的是两个向量的距离,只考虑语义相似,不考虑字面符号是否一致;而稀疏检索tf-idf只考虑字面的符号, 不考虑语义,怎么整合这两种retrieve的优势,摒弃其劣势了?这就需要用到传统NLP常见的手段了:classifier
reranker模型原理
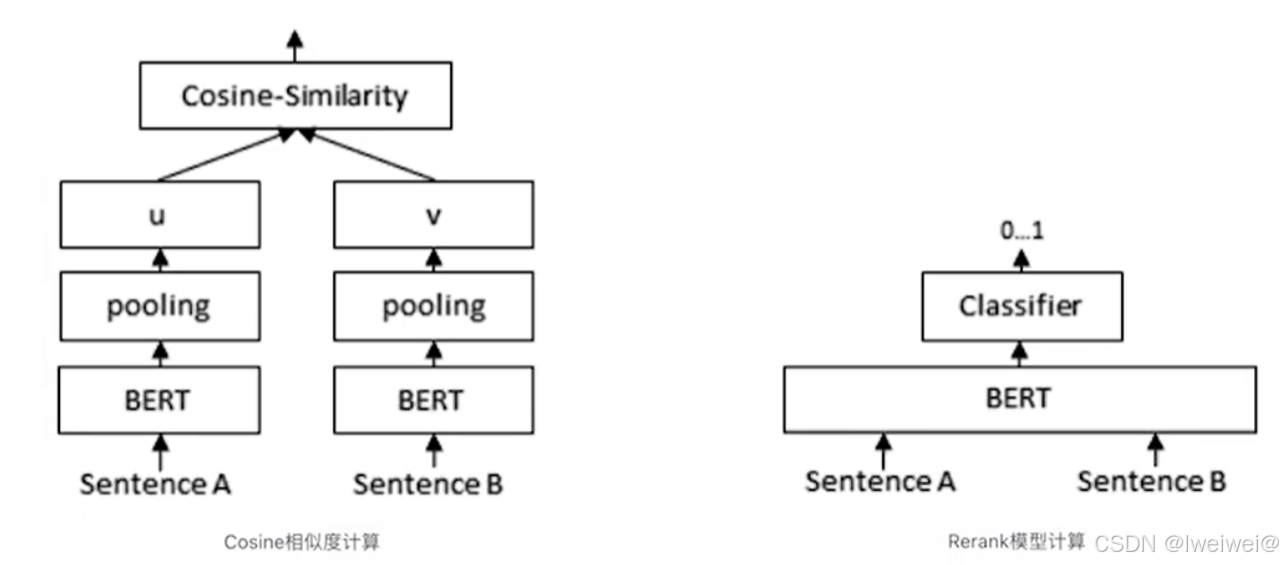
- 如上图右边所示:两个sentence先进入同一个bert
- lm_head用一个二分类来判断这两个sentence是否匹配!右边这种classifier判断是否匹配比左边这种cosin判断是否相似更准确,原因又是啥了?两个sentence首尾拼接进入bert后:
- 先要计算attention计算token之间的相似度,再进入FFN生成非线性特征,更利于lm_head的分类
- 两个sentence的特征能两两组合交互生成新的维度特征,捕捉复杂的细节关系
- cosin相似度的计算是基于整个sentence的embedding,但这种embeeding涉及到pooling,这个过程会有一定的信息丢失,造成精度下降
- cosin是没有参数可调节的,但classifier可以通过调节参数,让模型的目标函数主动适配特定的任务和数据分布。具体到这里,可以让模型生成的答案主动适配query;可以简单理解为answer对query的1v1 有针对性的VIP服务
- 当然,既然classifier的准确性提高了,为啥不从一开始就用这种classifier来召回生成context了?还用cosin计算相似度干嘛了?这里就是计算量的问题了!
- cosin的计算量远比classifier小,并且可以事先离线计算embedding存入向量数据库,所以适合第一步从大量数据中初步召回数十条;classifier精准度高,但计算量大,适合从初步召回的数十条context中进一步精选出几条包含或最接正确答案的context
06 检索模块(BM25、HyDE)
1. 信息检索的技术发展大致可分为三个阶段:
- 基于统计信息的关键字匹配(statistical keyword matching)
- 是一种 sparse embedding —— embedding 向量的大部分字段都是 0;
- 基于深度学习模型的上下文和语义理解,
- 属于 dense embedding —— embedding 向量的大部分字段都非零;
- 所谓的“学习型”表示,组合上面两种的优点,称为 learned sparse embedding
- 既有深度学习模型的上下文和语义理解能力;
- 又具备稀疏表示的可解释性(interpretability of sparse representations)和低计算复杂度
2. 基于统计信息和关键词匹配TF-IDF、BM25
- 原理:分析语料库的词频和分布(term frequency and distribution), 作为评估文档的相关性(document relevance)的基础
- BM25 基于 TF-IDF(Term Frequency-Inverse Document Frequency)的思想,但对其进行了改进以考虑文档的长度等因素
- TF-IDF 的改进: BM25 通过对文档中的每个词项引入饱和函数(saturation function)和文档长度因子,改进了 TF-IDF 的计算。
- 饱和函数: 在 BM25 中,对于词项的出现次数(TF),引入了一个饱和函数来调整其权重。这是为了防止某个词项在文档中出现次数过多导致权重过大。
- 文档长度因子: BM25 考虑了文档的长度,引入了文档长度因子,使得文档长度对权重的影响不是线性的。这样可以更好地适应不同长度的文档。

3. 基于深度学习和上下文语义:Word2Vec、BERT
- Word2Vec
- 首次尝试使用高维向量来表示单词,能分辨它们细微的语义差别;
- 标志着向机器学习驱动的信息检索的转变
- BERT
- 基于 transformer 的预训练(pretrain)语言模型 BERT 的出现,彻底颠覆了传统的信息检索范式
- BERT 是双向(前向+后向)transformer,
- 可以理解为在预训练时,每个句子正向读一遍,反向再读一遍
- 能更好地捕获句子的上下文语义(contextual semantics)
- 最终输出是一个 dense vector,本质上是对语义的压缩
- BERT 严重依赖预训练数据集的领域知识(domain-specific knowledge), 预训练过程使 BERT 偏向于预训练数据的特征, 因此在领域外(Out-Of-Domain),例如没有见过的文本片段,表现就不行了
- 解决方式之一是fine-tune(精调/微调),但成本相对较高, 因为准备高质量数据集的成本是很高的
- (Google AI研究院提出的一种预训练模型,多个Transformer Encoder一层一层地堆叠起来),用了Transformer的encoder侧的网络,encoder中的Self-attention机制在编码一个token的时候同时利用了其上下文的token,其中‘同时利用上下文’即为双向的体现
- 最大的特点是抛弃了传统的RNN和CNN,通过Attention机制将任意位置的两个单词的距离转换成1
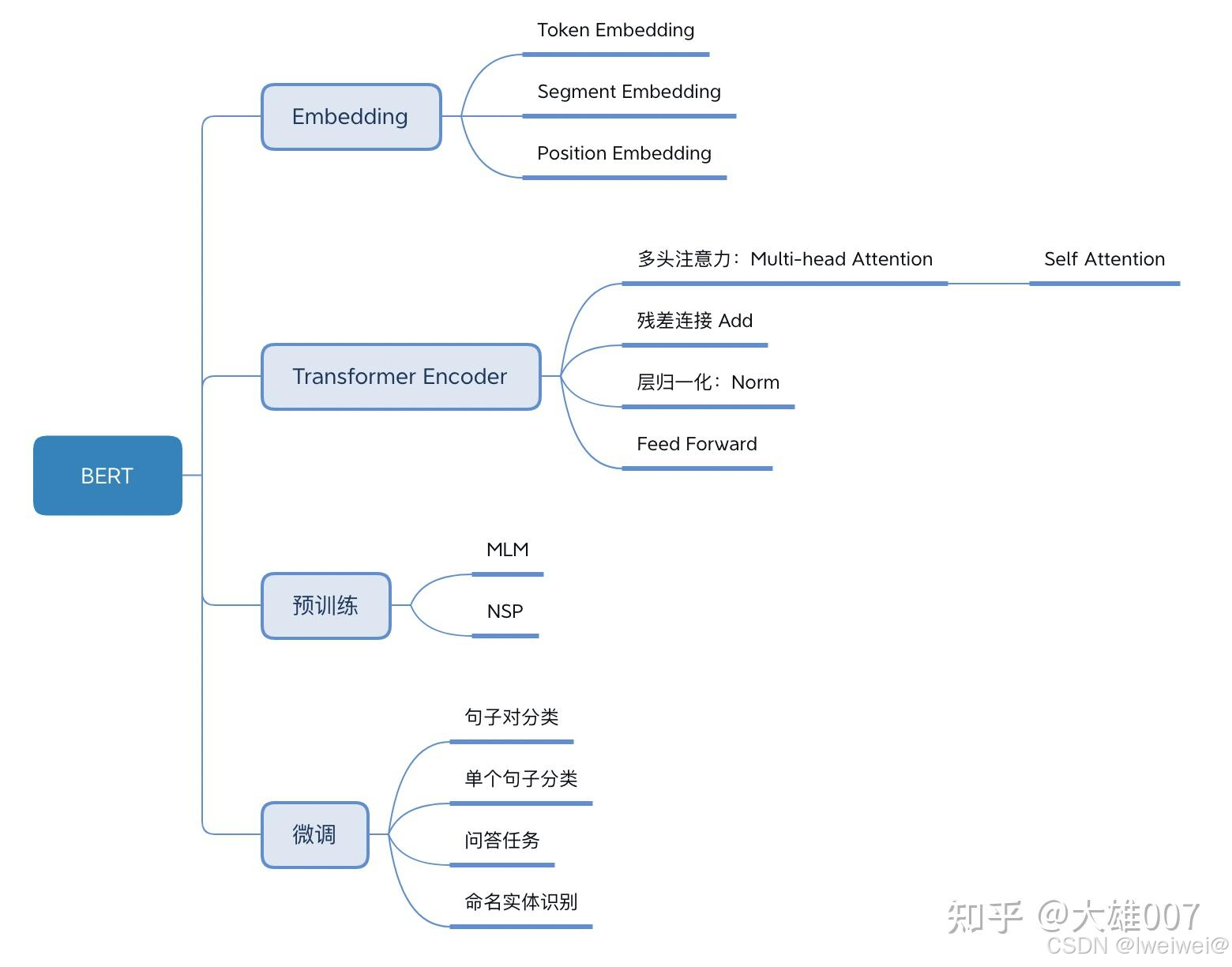
4. 学习型:组合前两种的优点
- 原理:传统 sparse vector 与上下文化信息的融合
- 先通过 BERT 等深度学习模型生成 dense embedding
- 再引入额外的步骤对以上 dense embedding 进行稀疏化,得到一个 sparse embedding
- 与传统 sparse embedding 的区别
- 引入了 Token Importance Estimation;
- 既保留了关键词搜索能力,又利用上下文信息,丰富了 embedding 的稀疏表示;
- 能够辨别相邻或相关的 token 的重要性,即使这些 token 在文本中没有明确出现。
- 优点
- 将稀疏表示与学习上下文结合,同时具备精确匹配和语义理解两大能力,在领域外场景有很强的泛化能力
- 与 dense embedding 相比更简洁,只保留了最核心的文本信息
- 固有的稀疏性使向量相似性搜索所需的计算资源极少
- 术语匹配特性还增强了可解释性,能够更精确地洞察底层的检索过程,提高了系统的透明度。
HyDE
- HyDE(全称Hypothetical Document Embeddings)是RAG中的一种技术,它基于一个假设:相较于直接查询,通过大语言模型 (LLM) 生成的答案在嵌入空间中可能更为接近。HyDE 首先响应查询生成一个假设性文档(答案),然后将其嵌入,从而提高搜索的效果
- 比如:
- 原始query: 美日半导体协议是由哪两部门签署的?
- 加上回答后的query: 美日半导体协议是由哪两部门签署的?美日半导体协议是由美国商务部和日本经济产业省签署的。
- 加上回答后的query使用BM25算法可以找回正确文本,且排名第一位,而Embedding算法仍无法召回。
07 用Llama-Factory 框架进行AdaLoRA微调
- LLaMA-Factory项目的目标是整合主流的各种高效训练微调技术,适配市场主流开源模型,形成一个功能丰富,适配性好的训练框架。项目提供了多个高层次抽象的调用接口,包含多阶段训练,推理测试,benchmark评测,API Server等,使开发者开箱即用
- 以Meta-Llama-3-8B-Instruct 模型 和 Linux + RTX 4090 24GB环境,LoRA+sft训练阶段为例子,帮助开发者迅速浏览和实践本项目会涉及到的常见若干个功能,包括:
- 原始模型直接推理
- 自定义数据集构建
- 基于LoRA的sft指令微调
- 动态合并LoRA的推理
- 批量预测和训练效果评估
- LoRA模型合并导出
- 一站式webui board的使用
- API Server的启动与调用
- 大模型主流评测 benchmark
08 Faiss
- 如何一次搜索一批的特征,而不仅仅是一个特征?
- 如何返回更相似度最近的一批特征,而不只是一个特征?(好吧,Deepvac类也支持)
- 如何让特征库使用的内存空间更小?(你看,上面都需要把特征库拆分到多个cuda设备上了)
- 搜索速度方面如何更快?
- 这就是Faiss库存在的意义。Faiss:Facebook AI Similarity Search。
创建并使用Faiss索引
- 在开始使用Faiss之前,我们首先需要创建一些向量数据。假设我们有一个由n个向量组成的矩阵,每个向量的维度为d
- 创建向量数据:使用Numpy创建一个随机的向量矩阵
- 创建索引:在Faiss中,索引是向量搜索的核心。我们以平面索引为例,它是最简单的一种索引类型,基于L2距离进行相似性计算
- 向索引添加数据:创建索引后,我们需要将向量数据添加到索引中
- 进行搜索:现在我们可以使用Faiss进行向量搜索了。假设有一个查询向量,我们想找到与其最相似的前k个向量
08 基于langchain RAG问答应用实战
- 软件资源
- CUDA 11.7
- Python 3.10
- pytorch 1.13.1+cu117
- langchain
- 环境搭建
-
下载代码
-
构建环境
$ conda create -n py310_chat python=3.10 # 创建新环境
$ source activate py310_chat # 激活环境 -
安装依赖
$ pip install datasets langchain sentence_transformers tqdm chromadb
langchain_wenxin
-
RAG问答应用实战
- 数据构建
- 藜麦数据(https://baike.baidu.com/item/藜麦/5843874)保存到 藜.txt 文件中
- 本地数据加载
- 文档分割:文档分割,借助langchain的字符分割器,这里采用固定字符长度分割chunk_size=128
- 向量化&数据入库:接下来对分割后的数据进行embedding,并写入数据库。这里选用m3e-base作为embedding模型,向量数据库选用Chroma
from langchain.embeddings import HuggingFaceBgeEmbeddings from langchain.vectorstores import Chroma # embedding model: m3e-base model_name = "moka-ai/m3e-base" model_kwargs = {'device': 'cpu'} encode_kwargs = {'normalize_embeddings': True} embedding = HuggingFaceBgeEmbeddings( model_name=model_name, model_kwargs=model_kwargs, encode_kwargs=encode_kwargs, query_instruction="为文本生成向量表示用于文本检索" ) # load data to Chroma db db = Chroma.from_documents(documents, embedding) # similarity search db.similarity_search("藜一般在几月播种?") - Prompt设计
- 数据构建
template = '''
【任务描述】
请根据用户输入的上下文回答问题,并遵守回答要求。
【背景知识】
{{context}}
【回答要求】
- 你需要严格根据背景知识的内容回答,禁止根据常识和已知信息回答问题。
- 对于不知道的信息,直接回答“未找到相关答案”
-
RetrievalqaChain构建:这里采用ConversationalRetrievalChain,ConversationalRetrievalQA chain 是建立在 RetrievalQAChain
之上,提供历史聊天记录组件。如下面定义了memory来追踪聊天记录,在流程上,先将历史问题和当前输入问题融合为一个新的独立问题,然后再进行检索,获取问题相关知识,最后将获取的知识和生成的新问题注入Prompt让大模型生成回答。from langchain import LLMChain from langchain_wenxin.llms import Wenxin from langchain.prompts import PromptTemplate from langchain.memory import ConversationBufferMemory from langchain.chains import ConversationalRetrievalChain from langchain.prompts.chat import ChatPromptTemplate, SystemMessagePromptTemplate, HumanMessagePromptTemplate # LLM选型 llm = Wenxin(model="ernie-bot", baidu_api_key="baidu_api_key", baidu_secret_key="baidu_secret_key") retriever = db.as_retriever() memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True) qa = ConversationalRetrievalChain.from_llm(llm, retriever, memory=memory) qa({"question": "藜怎么防治虫害?"}) >>> {'question': '藜怎么防治虫害?', 'chat_history': [HumanMessage(content='藜怎么防治虫害?'), AIMessage(content='藜麦常见虫害有象甲虫、金针虫、蝼蛄、黄条跳甲、横纹菜蝽、萹蓄齿 胫叶甲、潜叶蝇、蚜虫、夜蛾等。防治方法:可每亩用3%的辛硫磷颗粒剂2-2.5千克于耕地前均 匀撒施,随耕地翻入土中。也可以每亩用40%的辛硫磷乳油250毫升,加水1-2千克,拌细土20- 25千克配成毒土,撒施地面翻入土中,防治地下害虫。')], 'answer': '藜麦常见虫害有象甲虫、金针虫、蝼蛄、黄条跳甲、横纹菜蝽、萹蓄齿胫叶甲、 潜叶蝇、蚜虫、夜蛾等。防治方法:可每亩用3%的辛硫磷颗粒剂2-2.5千克于耕地前均匀撒施, 随耕地翻入土中。也可以每亩用40%的辛硫磷乳油250毫升,加水1-2千克,拌细土20-25千克配 成毒土,撒施地面翻入土中,防治地下害虫。'}
基于LLM+向量库的文档对话 优化面
痛点1:文档切分粒度不好把控,既担心噪声太多又担心语义信息丢失
问题2:如何让LLM回答出全面的粗粒度(跨段落)知识?:
- 基于LLM的文档对话架构分为两部分,先检索,后推理。重心在检索(推荐系统),推理交给LLM整合即可。
- 而检索部分要满足三点 ①尽可能提高召回率,②尽可能减少无关信息;③速度快。
- 将所有的文本组织成二级索引,第一级索引是 [关键信息],第二级是 [原始文本],二者一一映射。
- 检索部分只对关键信息做embedding,参与相似度计算,把召回结果映射的 原始文本 交给LLM
- 如何构建关键信息?
- 语义切分方法1:利用NLP的篇章分析(discourse parsing)工具,提取出段落之间的主要关系,譬如上述极端情况2展示的段落之间就有从属关系。把所有包含主从关系的段落合并成一段。 这样对文章切分完之后
保证每一段在说同一件事情. - 语义切分方法2:除了discourse parsing的工具外,还可以写一个简单算法利用BERT等模型来实现语义分割。BERT等模型在预训练的时候采用了NSP(next sentence prediction)的训练任务,因此BERT完全可以判断两个句子(段落)是否具有语义衔接关系。这里我们可以设置相似度阈值t,从前往后依次判断相邻两个段落的相似度分数是否大于t,如果大于则合并,否则断开。当然算法为了效率,可以采用二分法并行判定,模型也不用很大,笔者用BERT-base-Chinese在中文场景中就取得了不错的效果。
- 语义切分方法1:利用NLP的篇章分析(discourse parsing)工具,提取出段落之间的主要关系,譬如上述极端情况2展示的段落之间就有从属关系。把所有包含主从关系的段落合并成一段。 这样对文章切分完之后
- 语义段的切分及段落(句子)关键信息抽取
- 如果向量检索效率很高,获取语义段之后完全可以按照真实段落及句号切分,以缓解细粒度知识点检索时大语块噪声多的场景。当然,关键信息抽取笔者还有其他思路。
- 方法1:利用 NLP 中的成分句法分析(constituency parsing)工具和命名实体识别(NER)工具提取
• 成分句法分析(constituency parsing)工具:可以提取核心部分(名词短语、动词短语……);
• 命名实体识别(NER)工具:可以提取重要实体(货币名、人名、企业名……)。 - 方法2:可以用语义角色标注(Semantic Role Labeling)来分析句子的谓词论元结构,提取“谁对谁做了什么”的信息作为关键信息
- 方法3:直接法。其实NLP的研究中本来就有关键词提取工作(Keyphrase Extraction)。也有一个成熟工具可以使用。一个工具是 HanLP ,中文效果好,但是付费,免费版调用次数有限。还有一个开源工具是KeyBERT,英文效果好,但是中文效果差
- 方法4:垂直领域建议的方法。以上两个方法在垂直领域都有准确度低的缺陷,垂直领域可以仿照ChatLaw的做法,即:训练一个生成关键词的模型。ChatLaw就是训练了一个KeyLLM
- 方法1:利用 NLP 中的成分句法分析(constituency parsing)工具和命名实体识别(NER)工具提取
- 如果向量检索效率很高,获取语义段之后完全可以按照真实段落及句号切分,以缓解细粒度知识点检索时大语块噪声多的场景。当然,关键信息抽取笔者还有其他思路。
痛点3:langchain 内置 问答分句效果不佳问题
• 文档加工:
• 一种是使用更好的文档拆分的方式(如项目中已经集成的达摩院的语义识别的模型及进行拆分);
• 一种是改进填充的方式,判断中心句上下文的句子是否和中心句相关,仅添加相关度高的句子;
• 另一种是文本分段后,对每段分别及进行总结,基于总结内容语义及进行匹配;
如何 尽可能召回与query相关的Document 问题
- 问题描述:如何通过得到query相关性高的context,即与query相关的Document尽可能多的能被召回;
- 解决方法:
- 将本地知识切分成Document的时候,需要考虑Document的长度、Document embedding质量和被召回Document数量这三者之间的相互影响。在文本切分算法还没那么智能的情况下,本地知识的内容最好是已经结构化比较好了,各个段落之间语义关联没那么强。Document较短的情况下,得到的
- Document embedding的质量可能会高一些,通过Faiss得到的Document与query相关度会高一些。
- 使用Faiss做搜索,前提条件是有高质量的文本向量化工具。因此最好是能基于本地知识对文本向量化工具进行Finetune。另外也可以考虑将ES搜索结果与Faiss结果相结合。
痛点5:如何让LLM基于query和context得到高质量的response
• 问题描述:
- 一些开源的embedding模型本身效果一般,尤其是当text chunk很大的时候,强行变成一个简单的vector是很
难准确表示的,开源的模型在效果上确实不如openai Embeddings; - 多语言问题,paper的内容是英文的,用户的query和生成的内容都是中文的,这里有个语言之间的对齐问
题,尤其是可以用中文的query embedding来从英文的text chunking embedding中找到更加相似的top-k是个
具有挑战的问题
• 解决方法: - 用更小的text chunk配合更大的topk来提升表现,毕竟smaller text chunk用embedding表示起来noise更小,
更大的topk可以组合更丰富的context来生成质量更高的回答; - 多语言的问题,可以找一些更加适合多语言的embedding模型
01 大模型语言基础
1.1 llm概念类
1. Prefix LM(前缀语言模型)和Causal LM(因果语言模型)对比
| 项目 | Value |
|---|---|
| Prefix LMv | 前缀语言模型是一种生成模型,它在生成每个词时都可以考虑之前的上下文信息。在生成时,前缀语言模型会根据给定的前缀(即部分文本序列)预测下一个可能的词。这种模型可以用于文本生成、机器翻译等任务 |
| Causal LM | 因果语言模型是一种自回归模型,它只能根据之前的文本生成后续的文本,而不能根据后续的文本生成之前的文本。在训练时,因果语言模型的目标是预测下一个词的概率,给定之前的所有词作为上下文。这种模型可以用于文本生成、语言建模等任务 |
Prefix LM(前缀语言模型)
- Prefix LM其实是Encoder-Decoder模型的变体
- 在标准的Encoder-Decoder模型中,Encoder和Decoder各自使用一个独立的Transformer
- 而在Prefix LM,Encoder和Decoder则共享了同一个Transformer结构,在Transformer内部通过Attention Mask机制来实现
与标准Encoder-Decoder类似,Prefix LM在Encoder部分采用Auto Encoding (AE-自编码)模式,即前缀序列中任意两个token都相互可见,而Decoder部分采用Auto Regressive (AR-自回归)模式,即待生成的token可以看到Encoder侧所有token(包括上下文)和Decoder侧已经生成的token,但不能看未来尚未产生的token
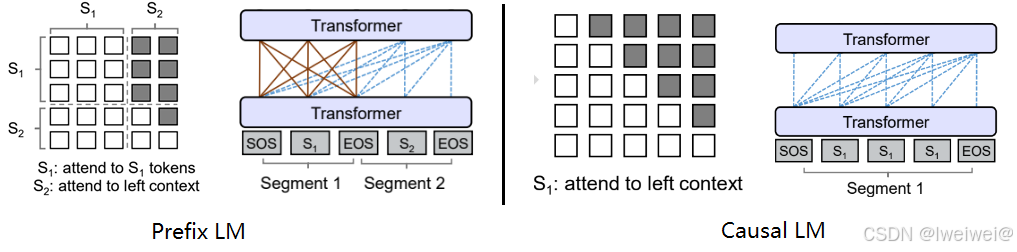
Causal LM
- Causal LM是因果语言模型,目前流行地大多数模型都是这种结构,别无他因,因为GPT系列模型内部结构就是它,还有开源界的LLaMa也是
- Causal LM只涉及到Encoder-Decoder中的Decoder部分,采用Auto Regressive模式,直白地说,就是根据历史的token来预测下一个token,也是在Attention Mask这里做的手脚
自回归模型(英语:Autoregressive model,简称AR模型),是统计上一种处理时间序列的方法,用同一变数例如x的之前各期,亦即x1至xt-1来预测本期xt的表现,并假设它们为一线性关系
2. 大模型LLM的训练目标-最大似然估计
- 训练过程:使用的数据通常是大量的文本语料库。训练目标是最大化模型生成训练数据中观察到的文本序列的概率
- 具体来说,对于每个文本序列,模型根据前面的上下文生成下一个词的条件概率分布,并通过最大化生成的词序列的概率来优化模型参数
- 为了最大化似然函数,可以使用梯度下降等优化算法来更新模型参数,使得模型生成的文本序列的概率逐步提高。在训练过程中,通常会使用批量训练(batch training)的方法,通过每次处理一小批数据样本来进行参数更新
梯度下降(Gradient Descent)是一种优化算法,用于寻找最小化损失函数(或成本函数)的参数值。在机器学习和深度学习的背景下,损失函数衡量了模型预测值与真实值之间的差异,而梯度下降则是用于更新模型的参数(例如权重和偏置),以最小化这个差异
l连接:深度学习之详解常见梯度算法(概念、公式、原理、算法实现过程
3. 涌现能力是啥原因?
- 定义
- 涌现能力(Emergent Ability)是指模型在训练过程中能够生成出令人惊喜、创造性和新颖的内容或行为。这种能力使得模型能够超出其训练数据所提供的内容,并产生出具有创造性和独特性的输出
- 产生原因
- 任务的评价指标不够平滑:因为很多任务的评价指标不够平滑,导致我们现在看到的涌现现象。如果评价指标要求很严格,要求一字不错才算对,那么Emoji_movie任务我们就会看到涌现现象的出现。但是,如果我们把问题形式换成多选题,就是给出几个候选答案,让LLM选,那么随着模型不断增大,任务效果在持续稳定变好,但涌现现象消失,如上图图右所示。这说明评价指标不够平滑,起码是一部分任务看到涌现现象的原因
- 复杂任务 vs 子任务:展现出涌现现象的任务有一个共性,就是任务往往是由多个子任务构成的复杂任务。也就是说,最终任务过于复杂,如果仔细分析,可以看出它由多个子任务构成,这时候,子任务效果往往随着模型增大,符合 Scaling Law,而最终任务则体现为涌现现象
- 用 Grokking (顿悟)来解释涌现:对于某个任务T,尽管我们看到的预训练数据总量是巨大的,但是与T相关的训练数据其实数量很少。当我们推大模型规模的时候,往往会伴随着增加预训练数据的数据量操作,这样,当模型规模达到某个点的时候,与任务T相关的数据量,突然就达到了最小要求临界点,于是我们就看到了这个任务产生了Grokking现象
4. 为何现在的大模型大部分是Decoder only结构?
首先概述几种主要的架构:
- 以BERT为代表的encoder-only
- 以T5和BART为代表的encoder-decoder
- 以GPT为代表的decoder-only,
- 以UNILM9为代表的PrefixLM(相比于GPT只改了attention mask,前缀部分是双向,后面要生成的部分是单向的causal mask%)
- Encoder的低秩问题:Encoder的双向注意力会存在低秩问题,这可能会削弱模型表达能力,就生成任务而言,引入双向注意力并无实质好处。
- 更好的Zero-Shot性能、更适合于大语料自监督学习:decoder-only 模型在没有任何 tuning 数据的情况下、zero-shot 表现最好,而 encoder-decoder 则需要在一定量的标注数据上做 multitask finetuning 才能激发最佳性能。
效率问题:decoder-only支持一直复用KV-Cache,对多轮对话更友好,因为每个Token的表示之和它之前的输入有关,而encoder-decoder和PrefixLM就难以做到。
5. 补充:encoder(编码器)和decoder(解码器)
链接:【Transformer系列(1)】encoder(编码器)和decoder(解码器)
- Transformer 模型一开始是用来做 seq2seq 任务的,所以它包含 Encoder 和 Decoder 两个部分;
- 他们两者的区别主要是,Encoder 在抽取序列中某一个词的特征时能够看到整个序列中所有的信息,即上文和下文同时看到;而 Decoder 中因为有 mask 机制的存在,使得它在编码某一个词的特征时只能看到自身和它之前的文本信息
- encoder
- 定义:也就是编码器,负责将输入序列压缩成指定长度的向量,这个向量就可以看成是这个序列的语义,然后进行编码,或进行特征提取(可以看做更复杂的编码)
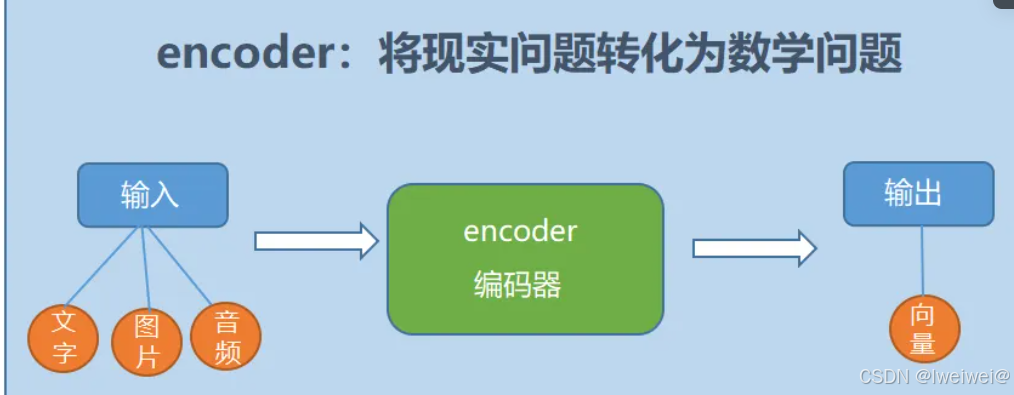
- 定义:也就是编码器,负责将输入序列压缩成指定长度的向量,这个向量就可以看成是这个序列的语义,然后进行编码,或进行特征提取(可以看做更复杂的编码)
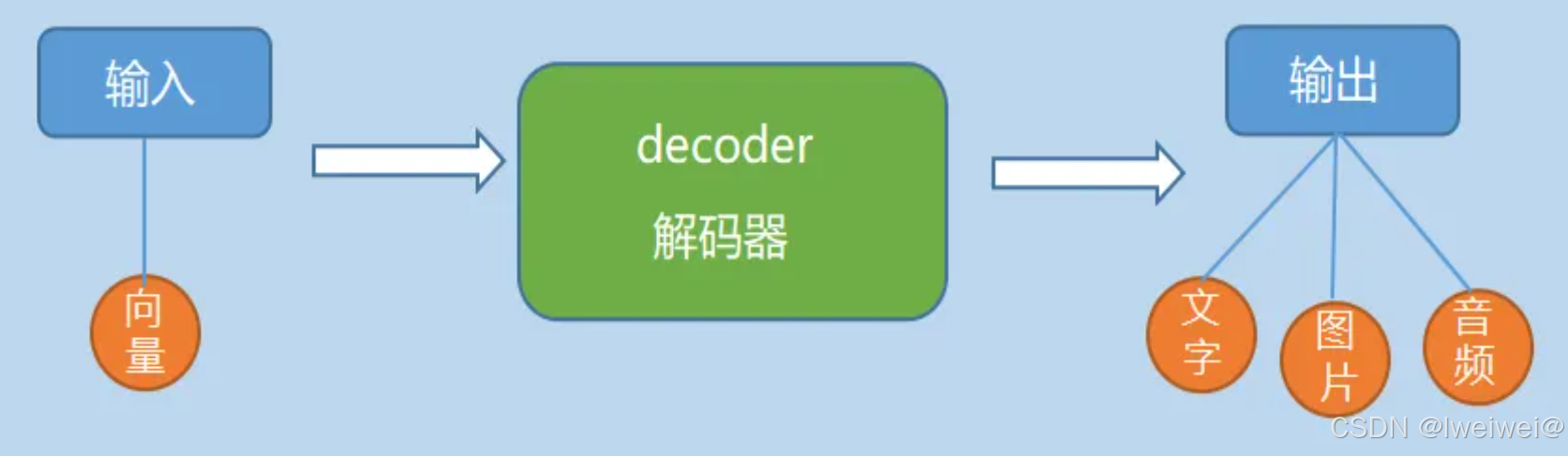
- decoder
- 也就是解码器,负责根据encoder部分输出的语义向量c来做解码工作。以翻译为例,就是生成相应的译文。
- 简单来说,就是就数学问题,并转换为现实世界的解决方案
7. LLMs复读机问题?
- 为什么会出现 LLMs 复读机问题
- 数据偏差:大型语言模型通常是通过预训练阶段使用大规模无标签数据进行训练的。如果训练数据中存在大量的重复文本或者某些特定的句子或短语出现频率较高,模型在生成文本时可能会倾向于复制这些常见的模式。
- 训练目标的限制:大型语言模型的训练通常是基于自监督学习的方法,通过预测下一个词或掩盖词来学习语言模型。这样的训练目标可能使得模型更倾向于生成与输入相似的文本,导致复读机问题的出现。
- 缺乏多样性的训练数据:虽然大型语言模型可以处理大规模的数据,但如果训练数据中缺乏多样性的语言表达和语境,模型可能无法学习到足够的多样性和创造性,导致复读机问题的出现。
- 模型结构和参数设置:大型语言模型的结构和参数设置也可能对复读机问题产生影响。例如,模型的注意力机制和生成策略可能导致模型更倾向于复制输入的文本。
- 缓解方法
- 多样性训练数据:在训练阶段,使用多样性的语料库来训练模型,避免数据偏差和重复文本的问题。这可以包括从不同领域、不同来源和不同风格的文本中获取数据。
- 引入噪声:在生成文本时,引入一些随机性或噪声,例如通过采样不同的词或短语,或者引入随机的变换操作,以增加生成文本的多样性。这可以通过在生成过程中对模型的输出进行采样或添加随机性来实现。
- 温度参数调整:温度参数是用来控制生成文本的多样性的一个参数。通过调整温度参数的值,可以控制生成文本的独创性和多样性。较高的温度值会增加随机性,从而减少复读机问题的出现。
- Beam搜索调整:在生成文本时,可以调整Beam搜索算法的参数。Beam搜索是一种常用的生成策略,它在生成过程中维护了一个候选序列的集合。通过调整Beam大小和搜索宽度,可以控制生成文本的多样性和创造性。
- 后处理和过滤:对生成的文本进行后处理和过滤,去除重复的句子或短语,以提高生成文本的质量和多样性。可以使用文本相似度计算方法或规则来检测和去除重复的文本。
- 人工干预和控制:对于关键任务或敏感场景,可以引入人工干预和控制机制,对生成的文本进行审查和筛选,确保生成结果的准确性和多样性。
- 此外,解决复读机问题还需要综合考虑数据、训练目标、模型架构和生成策略等多个因素,需要进一步的研究和实践来提高大型语言模型的生成文本多样性和创造性
8.LLMs输入句子长度理论上可以无限长吗?
- 计算资源:生成长句子需要更多的计算资源,包括内存和计算时间。由于LLMs通常是基于神经网络的模型,计算长句子可能会导致内存不足或计算时间过长的问题。
- 模型训练和推理:训练和推理长句子可能会面临一些挑战。在训练阶段,处理长句子可能会导致梯度消失或梯度爆炸的问题,影响模型的收敛性和训练效果。在推理阶段,生成长句子可能会增加模型的错误率和生成时间。
- 上下文建模:LLMs是基于上下文建模的模型,长句子的上下文可能会更加复杂和深层。模型需要能够捕捉长句子中的语义和语法结构,以生成准确和连贯的文本
10. 如何让大模型处理更长的文本?
- 分块处理:将长文本分割成较短的片段,然后逐个片段输入模型进行处理。这样可以避免长文本对模型内存和计算资源的压力。在处理分块文本时,可以使用重叠的方式,即将相邻片段的一部分重叠,以保持上下文的连贯性。
- 层次建模:通过引入层次结构,将长文本划分为更小的单元。例如,可以将文本分为段落、句子或子句等层次,然后逐层输入模型进行处理。这样可以减少每个单元的长度,提高模型处理长文本的能力。
- 部分生成:如果只需要模型生成文本的一部分,而不是整个文本,可以只输入部分文本作为上下文,然后让模型生成所需的部分。例如,输入前一部分文本,让模型生成后续的内容。
- 注意力机制:注意力机制可以帮助模型关注输入中的重要部分,可以用于处理长文本时的上下文建模。通过引入注意力机制,模型可以更好地捕捉长文本中的关键信息。
- 模型结构优化:通过优化模型结构和参数设置,可以提高模型处理长文本的能力。例如,可以增加模型的层数或参数量,以增加模型的表达能力。还可以使用更高效的模型架构,如Transformer等,以提高长文本的处理效率
11 AI大模型参数介绍中的5B、7B是何意-性能和成本的平衡?
7B、14B、405B确实指的是模型中可训练参数的数量
| 项目 | Value | Value |
|---|---|---|
| 7B(70亿参数) | 已经属于较大规模、参数包括神经网络中的权重和偏置,它们在训练过程中通过反向传播算法进行更新,以优化模型对数据的拟合能力 | 此类模型能够处理复杂的自然语言处理任务,如文本分类、情感分析、问答系统等,并表现出较高的准确率和效率 |
| 14B(140亿参数) | 例如,猎户星空发布的Orion-14B系列LLM模型,其核心模型Orion-14B-Base就拥有140亿个参数** | 并具备多模态和多任务能力,可以处理文本、图像、音频、视频等多种类型的输入和输出 |
| 405B(4050亿参数) | Llama 3.1系列中的旗舰模型 | 带来了强大的性能,如深入理解长篇文本、解决复杂数学难题、生成合成数据等能力 |
参数规模的影响 | 表达能力 | |
| 训练难度与成本 | ||
| 性能与泛化能力 | ||
| 应用场景 | 如自然语言处理中的问答系统,可能需要使用参数规模较大的模型;对实时性要求较高的任务(如在线聊天机器人),则可能需要使用参数规模较小但响应速度更快的模型 |
- AIGC大模型参数的5B、7B是指模型中可训练参数的数量。这里的“B”表示10亿(Billion),即10^9。因此,5B表示50亿个可训练参数,7B表示70亿个可训练参数。这些参数是神经网络中的权重和偏置,它们在训练过程中通过反向传播算法进行更新,以使模型能够更好地拟合训练数据。
- 随着深度学习技术的发展,模型的规模越来越大,参数数量也越来越多。这是因为更大的模型具有更强的表达能力,可以捕捉到更复杂的特征和模式。然而,这也带来了一些问题,如计算资源需求增加、训练时间延长以及过拟合风险提高等。因此,研究人员需要在模型规模和性能之间找到一个平衡点。
- 研究人员提出了许多技术,如模型压缩、知识蒸馏、迁移学习等
12 如何选择模型
- 数据集的大小:较大的数据集通常需要较大的模型来捕捉其中的特征。然而,过大的模型可能会导致过拟合问题
- 任务的复杂性:不同的任务可能需要不同规模的模型。例如,图像分类任务通常需要较大的模型来捕捉图像中的复杂特征,而文本分类任务可能只需要较小的模型
- 计算资源:较大的模型需要更多的计算资源来进行训练和推理。因此,在有限的计算资源下,可能需要选择较小的模型规模
- 性能要求:根据任务的性能要求,可以选择适当规模的模型。例如,对于一些高精度的任务,可能需要选择较大的模型来提高性能
13 大模型参数详细介绍
1. 架构参数-神经元数量、层类型、激活函数、隐藏层大小和宽度、注意力头数量
| 项目 | Value |
|---|---|
| 定义 | 模型架构参数指的是模型的基本结构和组成,这些参数决定了模型如何处理输入数据并生成输出 |
| 神经元数量 | 在神经网络中,每个神经元都是一个处理单元,负责接收输入、进行计算并产生输出。神经元的数量直接影响模型的复杂度和学习能力 |
| 层类型 | 神经网络由多个层组成,不同类型的层(如卷积层、全连接层、池化层等)具有不同的功能和特性。层类型的选择对模型的性能有重要影响 |
| 激活函数 | 激活函数用于在神经网络中引入非线性因素,使得模型能够学习复杂的非线性关系。常见的激活函数包括ReLU、Sigmoid、Tanh等 |
| 隐藏层大小和宽度 | 隐藏层是神经网络中位于输入层和输出层之间的层,其大小和宽度(即神经元数量)决定了模型能够学习到的数据内在关系的复杂程度 |
| 注意力头数量 | 在基于Transformer的大模型中,注意力头是一种并行注意力机制,用于捕捉更多的并行化关系。注意力头的数量越多,模型能够同时关注的信息就越多 |
2. 优化器参数
| 项目 | Value |
|---|---|
| 定义 | 优化器是用于调整模型权重的算法,其参数决定了优化器如何根据损失函数来更新权重 |
| 学习率 | 学习率决定了权重更新的步长,过大的学习率可能导致模型无法收敛,而过小的学习率则可能导致训练过程过于缓慢。 |
| 动量 | 动量是一种加速梯度下降的策略,它模拟了物理中的动量概念,帮助模型在相关方向上加速收敛,并抑制震荡。 |
| 其他参数 | 不同的优化器(如Adam、RMSProp等)可能还具有其他特定的参数,这些参数共同决定了优化器的行为。 |
3. 损失函数参数
| 项目 | Value |
|---|---|
| 定义 | 损失函数用于衡量模型预测与真实值之间的差距,其参数可以影响模型的训练速度和性能 |
| 权重 | 在某些损失函数中,可以对不同类型的误差赋予不同的权重,以强调某些方面的性能。 |
| 温度参数 | 在交叉熵损失等函数中,温度参数可以控制模型预测分布的平滑程度,影响模型对不确定性的处理能力 |
4. 正则化参数
| 项目 | Value |
|---|---|
| 定义 | 是一种防止模型过拟合的技术,其参数用于控制模型对训练数据的拟合程度 |
| 正则化强度 | 正则化强度决定了正则化项对损失函数的影响程度,过大的强度可能导致模型欠拟合,而过小的强度则可能无法有效防止过拟合 |
举例:
- L2正则化如何减少模型的复杂度
- 假设我们有一个简单的线性回归模型,其目标是基于输入特征预测目标变量。在训练过程中,模型会尝试学习最佳的权重参数,以便最小化训练数据的误差。然而,如果没有正则化,模型可能会过度拟合训练数据,导致在未见过的数据上表现不佳
- 除了原始的误差项(如均方误差)外,我们还添加了一个L2范数惩罚项,它是模型权重参数的平方和的平方根。这个惩罚项的作用,不仅要考虑误差的大小,还要考虑权重参数的大小,由于L2正则化项的存在,模型会倾向于选择较小的权重参数。这是因为较大的权重参数会导致L2正则化项的值增大,从而增加总损失。因此,模型会尝试在最小化误差和最小化权重参数之间找到一个平衡
- 假设我们有一个包含多个特征的数据集,并且其中一些特征是噪声或与其他特征高度相关的。在没有L2正则化的情况下,模型可能会给这些噪声或相关特征分配较大的权重,导致过拟合。但是,在引入L2正则化后,模型会倾向于将这些特征的权重减小,甚至可能将它们完全忽略,从而得到一个更简单、更鲁棒的模型。
5. 其它参数
| 项目 | Value |
|---|---|
| 批处理大小 | 在每次模型权重更新时使用的样本数量。较大的批处理大小可以减少训练时间,但也可能导致内存不足;而较小的批处理大小则可能导致训练不稳定。 |
| 训练轮次 | 整个数据集被用于训练模型的次数。过多的训练轮次可能导致过拟合,而过少的训练轮次则可能导致模型未能充分学习。 |
| 学习率调度 | 在训练过程中动态调整学习率的策略,如随着训练的进行逐渐减小学习率。 |
| 初始化策略 | 权重初始化是模型训练的第一步,不同的初始化策略会影响模型训练的稳定性和速度。 |
| 数据增强 | 一种通过变换原始数据来增加训练样本数量的技术,可以提高模型的泛化能力。 |
14. 参数规模7B、14B、405B(4050亿参数)
1.2 分词
1. 基于词典的分词算法
基于词典的分词算法,本质上就是字符串匹配。将待匹配的字符串基于一定的算法策略,和一个足够大的词典进行字符串匹配,如果匹配命中,则可以分词。根据不同的匹配策略,又分为正向最大匹配法,逆向最大匹配法,双向匹配分词,全切分路径选择等。
最大匹配法主要分为三种:
- 正向最大匹配法,从左到右对语句进行匹配,匹配的词越长越好。比如“商务处女干事”,划分为“商务处/女干事”,而不是“商务/处女/干事”。这种方式切分会有歧义问题出现,比如“结婚和尚未结婚的同事”,会被划分为“结婚/和尚/未/结婚/的/同事”。
- 逆向最大匹配法,从右到左对语句进行匹配,同样也是匹配的词越长越好。比如“他从东经过我家”,划分为“他/从/东/经过/我家”。这种方式同样也会有歧义问题,比如“他们昨日本应该回来”,会被划分为“他们/昨/日本/应该/回来”。
- 双向匹配分词,则同时采用正向最大匹配和逆向最大匹配,选择二者分词结果中词数较少者。但这种方式同样会产生歧义问题,比如“他将来上海”,会被划分为“他/将来/上海”。由此可见,词数少也不一定划分就正确。
- 全切分路径选择,将所有可能的切分结果全部列出来,从中选择最佳的切分路径。分为两种选择方法
- n最短路径方法。将所有的切分结果组成有向无环图,切词结果作为节点,词和词之间的边赋予权重,找到权重和最小的路径即为最终结果。比如可以通过词频作为权重,找到一条总词频最大的路径即可认为是最佳路径。
n元语法模型。同样采用n最短路径,只不过路径构成时会考虑词的上下文关系。一元表示考虑词的前后一个词,二元则表示考虑词的前后两个词。然后根据语料库的统计结果,找到概率最大的路径。
基于统计的分词算法
基于统计的分词算法,本质上是一个序列标注问题。将语句中的字,按照他们在词中的位置进行标注。标注主要有:B(词开始的一个字),E(词最后一个字),M(词中间的字,可能多个),S(一个字表示的词)。例如“网商银行是蚂蚁金服微贷事业部的最重要产品”,标注后结果为“BMMESBMMEBMMMESBMEBE”,对应的分词结果为“网商银行/是/蚂蚁金服/微贷事业部/的/最重要/产品”。
2. 基于统计分析方法:HMM,CRF,SVM,以及深度学习
得到序列标注结果,就可以得到分词结果了。这类算法基于机器学习或者现在火热的深度学习,主要有HMM,CRF,SVM,以及深度学习等。
- HMM,隐马尔科夫模型。隐马尔科夫模型在机器学习中应用十分广泛,它包含观测序列和隐藏序列两部分。对应到NLP中,语句是观测序列,而序列标注结果是隐藏序列。任何一个HMM都可以由一个五元组来描述:观测序列,隐藏序列,隐藏态起始概率,隐藏态之间转换概率(转移概率),隐藏态表现为观测值的概率(发射概率)。其中起始概率,转移概率和发射概率可以通过大规模语料统计来得到。从隐藏态初始状态出发,计算下一个隐藏态的概率,并依次计算后面所有的隐藏态转移概率。序列标注问题就转化为了求解概率最大的隐藏状态序列问题。jieba分词中使用HMM模型来处理未登录词问题,并利用viterbi算法来计算观测序列(语句)最可能的隐藏序列(BEMS标注序列)。
- CRF,条件随机场。也可以描述输入序列和输出序列之间关系。只不过它是基于条件概率来描述模型的。详细的这儿就不展开了。
- 深度学习。将语句作为输入,分词结果作为标注,可以进行有监督学习。训练生成模型,从而对未知语句进行预测
3. jieba分词用法及原理
1. 特点、安装、算法
-
Jieba库分词有4种模式,最常用的还是前3种- 精确模式**:就是把一段文本精确地切分成若干个中文单词,若干个中文单词之间经过组合,就精确地还原为之前的文本。其中不存在冗余单词 **。
- 全模式**:将一段文本中所有可能的词语都扫描出来,可能有一段文本它可以切分成不同的模式,或者有不同的角度来切分变成不同的词语,在全模式下,Jieba库会将各种不同的组合都挖掘出来。分词后的信息再组合起来会有冗余,不再是原来的文本 **。
- 搜索引擎模式**:** 在精确模式基础上,对发现的那些长的词语,我们会对它再次切分,进而适合搜索引擎对短词语的索引和搜索。也有冗余。
- paddle模式:利用PaddlePaddle深度学习框架,训练序列标注(双向GRU)网络模型实现分词。同时支持词性标注。paddle模式使用需安装paddlepaddle-tiny,pip install paddlepaddle-tiny==1.6.1。目前paddle模式支持jieba v0.40及以上版本。jieba v0.40以下版本,请升级jieba,pip install jieba --upgrade 。
-
安装说明- 代码对 Python 2/3 均兼容
- 全自动安装:easy_install jieba 或者 pip install jieba / pip3 install jieba
- 半自动安装:先下载 http://pypi.python.org/pypi/jieba/ ,解压后运行 python setup.py install
- 手动安装:将 jieba 目录放置于当前目录或者 site-packages 目录
- 通过 import jieba 来引用
-
算法- 基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图 (DAG)
- 采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合
- 对于未登录词,采用了基于汉字成词能力的 HMM 模型,使用了 Viterbi 算法
2. 用法
-
jieba分词用法- 分词
- jieba.cut 方法接受四个输入参数:
- 需要分词的字符串
- cut_all 参数用来控制是否采用全模式;
- HMM 参数用来控制是否使用 HMM 模型;
- use_paddle 参数用来控制是否使用paddle模式下的分词模式,paddle模式采用延迟加载方式,通过enable_paddle接口安装paddlepaddle-tiny,并且import相关代码;
- 分词
-
添加自定义词典- 开发者可以指定自己自定义的词典,以便包含 jieba 词库里没有的词。虽然 jieba 有新词识别能力,但是自行添加新词可以保证更高的正确率
- 用法: jieba.load_userdict(file_name) , file_name 为文件类对象或自定义词典的路径
- 词典格式和 dict.txt 一样,一个词占一行;每一行分三部分:词语、词频(可省略)、词性(可省略),用空格隔开,顺序不可颠倒。file_name 若为路径或二进制方式打开的文件,则文件必须为 UTF-8 编码。
- 词频省略时使用自动计算的能保证分出该词的词频。
3. 关键词提取-基于TF-IDF的关键词抽取算法
4. 原理分析
jieba分词综合了基于字符串匹配的算法和基于统计的算法,其分词步骤为
- 初始化。加载词典文件,获取每个词语和它出现的词数
- 切分短语。利用正则,将文本切分为一个个语句,之后对语句进行分词
- 构建DAG。通过字符串匹配,构建所有可能的分词情况的有向无环图,也就是DAG
- 构建节点最大路径概率,以及结束位置。计算每个汉字节点到语句结尾的所有路径中的最大概率,并记下最大概率时在DAG中对应的该汉字成词的结束位置。
- 构建切分组合。根据节点路径,得到词语切分的结果,也就是分词结果。
- HMM新词处理:对于新词,也就是dict.txt中没有的词语,通过统计方法来处理,jieba中采用了HMM隐马尔科夫模型来处理。
- 返回分词结果:通过yield将上面步骤中切分好的词语逐个返回。yield相对于list,可以节约存储空间。
5. jieba词性标注原理
jieba在分词的同时,可以进行词性标注。利用jieba.posseg模块来进行词性标注,会给出分词后每个词的词性。词性标示兼容ICTCLAS 汉语词性标注集
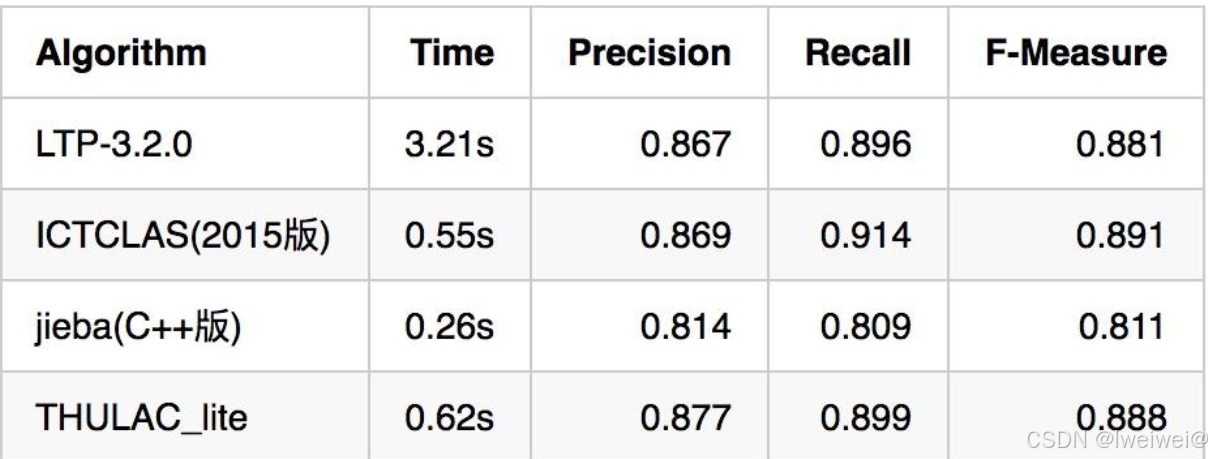
4. 分词质量-常见方法素服和准确度对比
- 评价一个分词引擎性能的指标主要有分词准确度和分词速度两方面,分词准确度直接影响后续的词性标注,句法分析,文本分析等环节。分词速度则对自然语言处理的实时性影响很大
1.3 激活函数
sigmoid和tanh、ReLU对比
| 项目 | P | N |
|---|---|---|
| sigmoid | 平滑,易于求导;取值范围是(0, 1),可直接用于求概率值的问题或者分类问题;比如 LSTM 中的门,二分类或者多标签分类问题; | 计算量大,包含幂运算,以及除法运算;sigmoid 导数的取值范围是 [0, 0.25],最大值都是小于 1 的,反向传播时又是"链式传导",经过几次相乘之后很容易就会出现梯度消失的问题;sigmoid 的输出的均值不是0(即zero-centered),这会导致当前层接收到上一层的非0均值的信号作为输入,随着网络的加深,会改变数据的原始分布; |
| Tanh的函数 | tanh 函数可以由 sigmoid 函数经过平移和拉伸得到。tanh 函数的取值范围是(-1, 1) | 它的输出范围是(-1, 1),解决了 sigmoid 函数输出的均值不是0(zero-centered)的问题;tanh 的导数取值范围是(0, 1),可以看出其在反向传播的"链式传导"过程中的梯度消失问题要比 sigmoid 函数要好一些,但是其依然存在着梯度消失问题;幂运算依然存在,计算量比较大; |
| ReLU | 当 z>0 时,ReLU 激活函数的导数恒为常数1,这就避免了 sigmoid 和 tanh 会在神经网络层数比较深的时候出现的梯度消失的问题;计算复杂度低,不再含有幂运算,只需要一个阈值就能够得到其导数;使用 ReLU 作为激活函数,模型收敛的速度比 sigmoid 和 tanh 快 |
1. FFN(Feed-Forward Network)块
是Transformer模型中的一个重要组成部分,用于对输入数据进行非线性变换。它由两个全连接层(即前馈神经网络)和一个激活函数组成。下面是FFN块的计算公式:
假设输入是一个向量 x,FFN块的计算过程如下:

2 介绍一下 GeLU 计算公式?
GeLU(Gaussian Error Linear Unit)是一种激活函数,常用于神经网络中的非线性变换。它在Transformer模型中广泛应用于FFN(Feed-Forward Network)块。下面是GeLU的计算公式:
假设输入是一个标量 x,GeLU的计算公式如下:

3 介绍一下 Swish 计算公式?
Swish是一种激活函数,它在深度学习中常用于神经网络的非线性变换。Swish函数的计算公式如下:

4 介绍一下 使用 GLU 线性门控单元的 FFN 块 计算公式?
使用GLU(Gated Linear Unit)线性门控单元的FFN(Feed-Forward Network)块是Transformer模型中常用的结构之一。它通过引入门控机制来增强模型的非线性能力。下面是使用GLU线性门控单元的FFN块的计算公式:

- 在公式(1)中,首先将输入向量 x 通过一个全连接层(线性变换)得到一个与 x 维度相同的向量,然后将该向量通过Sigmoid函数进行激活。这个Sigmoid函数的输出称为门控向量,用来控制输入向量 x 的元素是否被激活。最后,将门控向量与输入向量 x 逐元素相乘,得到最终的输出向量。
- GLU线性门控单元的特点是能够对输入向量进行选择性地激活,从而增强模型的表达能力。它在Transformer模型的编码器和解码器中广泛应用,用于对输入向量进行非线性变换和特征提取。
- 需要注意的是,GLU线性门控单元的计算复杂度较高,可能会增加模型的计算开销。因此,在实际应用中,也可以根据具体情况选择其他的非线性变换方式来代替GLU线性门控单元。
5 介绍一下 使用 GeLU 的 GLU 块 计算公式?
介绍一下 使用 GeLU 作为激活函数的 GLU 块 计算公式?
使用GeLU作为激活函数的GLU块的计算公式如下:

作用
神经网络是线性的,无法解决非线性的问题,加入激活函数就是给模型引入非线性能力
不同的激活函数,特点和作用不同:
- Sigmoid和tanh的特点是将输出限制在(0,1)和(-1,1)之间,说明Sigmoid和tanh适合做概率值的处理,例如LSTM中的各种门;而ReLU就不行,因为ReLU无最大值限制,可能会出现很大值。
- ReLU适合用于深层网络的训练,而Sigmoid和tanh则不行,因为它们会出现梯度消失。
梯度爆炸和梯度消失
模型中的梯度爆炸和梯度消失问题:
- 激活函数导致的梯度消失,像 sigmoid 和 tanh 都会导致梯度消失;
- 矩阵连乘也会导致梯度消失,这个原因导致的梯度消失无法通过更换激活函数来避免。直观的说就是在反向传播时,梯度会连乘,当梯度都小于1.0时,就会出现梯度消失;当梯度都大于1.0时,就会出现梯度爆炸。
如何解决梯度爆炸和梯度消失问题:
- 上述第一个问题只需要使用像 ReLU 这种激活函数就可以解决;
- 上述第二个问题没有能够完全解决的方法,目前有一些方法可以很大程度上进行缓解该问题,比如:对梯度做截断解决梯度爆炸问题、残差连接、normalize。由于使用了残差连接和 normalize 之后梯度消失和梯度爆炸已经极少出现了,所以目前可以认为该问题已经解决了。
1.4 注意力机制
1. 定义
- 注意力机制对不同信息的关注程度(重要程度)由权值来体现,注意力机制可以视为查询矩阵(Query)、键(key)以及加权平均值构成了多层感知机(Multilayer Perceptron, MLP)
- 注意力的思想,类似于寻址。给定Target中的某个元素Query,通过计算Query和各个Key的相似性或相关性,得到每个Key对应Value的权重系数,然后对Value进行加权求和,即得到最终的Attention数值。所以,本质上Attention机制是Source中元素的Value值进行加权求和,而Query和Key用来计算对应Value的权重系数
2. 注意力机制的计算过程
- 第一阶段,**计算 Query和不同 Key 的相关性**,即计算不同 Value 值的权重系数;
- 计算两者相似性或者相关性常用方法:点积、Cosin相似性、MLP网络
- 第二阶段,对上一阶段的输出进行归一化处理,将数值的范围映射到 0 和 1 之间
- 引入类似**SoftMax**的计算方式对第一阶段的得分就行数值转换。一方面,可以进行归一化,将原始计算分值整理成所有元素权重之和为1的概率分布;另一方面,通过SoftMax的内在机制更加突出重要元素的权重。即一般采用如下公式:
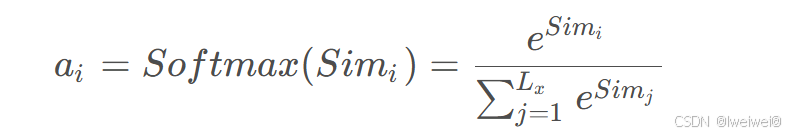
- 第三阶段,根据权重系数对Value进行加权求和,从而得到最终的注意力数值
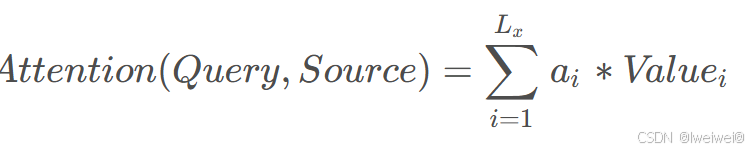
3. attention 变体
- 稀疏 attention。将稀疏偏差引入 attention 机制可以降低了复杂性;
• 线性化 attention。解开 attention 矩阵与内核特征图,然后以相反的顺序计算 attention 以实现线性复杂度;
• 原型和内存压缩。这类方法减少了查询或键值记忆对的数量,以减少注意力矩阵的大小;
• 低阶 self-Attention。这一系列工作捕获了 self-Attention 的低阶属性;
• Attention 与先验。该研究探索了用先验 attention 分布来补充或替代标准 attention;
• 改进多头机制。该系列研究探索了不同的替代多头机制。
4. Multi-query attention
1.5 词向量-word2vec
1. 词向量模型训练
- 词向量模型训练只需要有训练语料即可,语料越丰富准确率越高,属于无监督学习
# gensim是自然语言处理的一个重要Python库,它包括了Word2vec
import gensim
from gensim.models import word2vec
# 语句,由原始语句经过分词后划分为的一个个词语
sentences = [['网商银行', '体验', '好'], ['网商银行','转账','快']]
# 使用word2vec进行训练
# min_count: 词语频度,低于这个阈值的词语不做词向量
# size:每个词对应向量的维度,也就是向量长度
# workers:并行训练任务数
model = word2vec.Word2Vec(sentences, size=256, min_count=1)
# 保存词向量模型,下次只需要load就可以用了
model.save("word2vec_atec")
2. 增量训练
有时候我们语料不是很丰富,但都是针对的某个垂直场景的,比如网商银行相关的语料。此时训练词向量时,可以先基于一个已有的模型进行增量训练,这样就可以得到包含特定语料的比较准确的词向量了
3. 词向量训练算法
- 词向量可以通过使用大规模语料进行无监督学习训练得到,常用的算法有CBOW连续词袋模型和skip-gram跳字模型。二者没有本质的区别,算法框架完全相同。
- 区别在于,CBOW利用上下文来预测中心词。而skip-gram则相反,利用中心词来预测上下文。
- ,CBOW适合小规模训练语料,对其进行平滑处理。skip-gram适合大规模训练语料,可以基于滑窗随机选择上下文词语。word2vec模型训练时默认采用skip-gram
原理
- 下载语料文件、语料处理、词表制作
- 生成训练的batch label对。这是比较关键的一步,也是体现skip-gram算法的一步
- 先取出滑窗范围的一组词,如滑窗大小为5,则取出5个词。
- 位于中心的词为中心词,比如滑窗大小为5,则第三个词为中心词。其他词则称为上下文。
- 从上下文中随机取出num_skip个词,比如num_skip为2,则从4个上下文词语中取2个。通过随机选取提高了一定的泛化性
- 得到num_skip个中心词->上下文的x->y词组
- 将滑窗向右移动一个位置,继续这些步骤,直到滑窗到达文本最后
- 构造训练模型,这一步也很关键。利用nce loss将多分类问题转化为二分类问题,optimizer优化方法采用随机梯度下降。
- 开始真正的训练。这一步比较常规化。送入第四步构建的batch进行feed,跑optimizer和loss,并进行相关信息打印即可。训练结束后,即可得到调整完的词向量模型
4. Word2Vec中为什么使用负采样(negtive sample)
- 负采样是另一种用来提高Word2Vec效率的方法,它是基于这样的观察:训练一个神经网络意味着使用一个训练样本就要稍微调整一下神经网络中所有的权重,这样才能够确保预测训练样本更加精确,如果能设计一种方法每次只更新一部分权重,那么计算复杂度将大大降低
- 当通过(”fox”, “quick”)词对来训练神经网络时,回想起这个神经网络的“标签”或者是“正确的输出”是一个one-hot向量。也就是说,对于神经网络中对应于”quick”这个单词的神经元对应为1,而其他上千个的输出神经元则对应为0。
- 使用负采样,通过随机选择一个较少数目(比如说5个)的“负”样本来更新对应的权重。(在这个条件下,“负”单词就是希望神经网络输出为0的神经元对应的单词)。并且仍然为“正”单词更新对应的权重(也就是当前样本下”quick”对应的神经元仍然输出为1)。
负采样这个点引入word2vec非常巧妙,两个作用:
- 加速了模型计算
- 保证了模型训练的效果,其一 模型每次只需要更新采样的词的权重,不用更新所有的权重,那样会很慢,其二 中心词其实只跟它周围的词有关系,位置离着很远的词没有关系,也没必要同时训练更新,作者这点非常聪明。
1.9 NLP三大特征抽取器CNN-RNN-CF
- RNN已经基本完成它的历史使命,将来会逐步退出历史舞台;CNN如果改造得当,将来还是有希望有自己在NLP领域的一席之地;而Transformer明显会很快成为NLP里担当大任的最主流的特征抽取器
RNN
- 采取线性序列结构不断从前往后收集输入信息,但这种线性序列结构在反向传播的时候存在优化困难问题,因为反向传播路径太长,容易导致严重的梯度消失或梯度爆炸问题
- 后来引入了LSTM和GRU模型,通过增加中间状态信息直接向后传播,以此缓解梯度消失问题
- 又从图像领域借鉴并引入了attention机制(从这两个过程可以看到不同领域的相互技术借鉴与促进作用),叠加网络把层深作深,以及引入Encoder-Decoder框架,这些技术进展极大拓展了RNN的能力以及应用效果
CNN
- 捕获的特征其实的单词的k-gram片段信息,k的大小决定了能捕获多远距离的特征
三大抽取器比较
- 语义特征提取能力:Transformer在这方面的能力非常显著地超过RNN和CNN,RNN和CNN两者能力差不太多。
- 长距离特征捕获能力:原生CNN特征抽取器在这方面极为显著地弱于RNN和Transformer,Transformer微弱优于RNN模型(尤其在主语谓语距离小于13时),能力由强到弱排序为Transformer>RNN>>CNN; 但在比较远的距离上(主语谓语距离大于13),RNN微弱优于Transformer,所以综合看,可以认为Transformer和RNN在这方面能力差不太多,而CNN则显著弱于前两者。
- 任务综合特征抽取能力(机器翻译):Transformer综合能力要明显强于RNN和CNN,而RNN和CNN看上去表现基本相当,貌似CNN表现略好一些。
- 并行计算能力及运行效率:RNN在并行计算方面有严重缺陷,这是它本身的序列依赖特性导致的;对于CNN和Transformer来说,因为它们不存在网络中间状态不同时间步输入的依赖关系,所以可以非常方便及自由地做并行计算改造。Transformer和CNN差不多,都远远远远强于RNN。
1.10 常用参数更新方法-梯度下降
| 项目 | Value |
|---|---|
| 梯度下降 | 在一个方向上更新和调整模型的参数,来最小化损失函数。 |
| 随机梯度下降(Stochastic gradient descent,SGD) | 对每个训练样本进行参数更新,每次执行都进行一次更新,且执行速度更快。 |
| 小批量梯度下降 | 为了避免SGD和标准梯度下降中存在的问题,一个改进方法为小批量梯度下降(Mini Batch Gradient Descent),因为对每个批次中的n个训练样本,这种方法只执行一次更新 |
1.11 layer_normalization
定义
- Normalization根据标准化操作的维度不同可以分为batch Normalization和Layer Normalization,不管在哪个维度上做noramlization,本质都是为了让数据在这个维度上归一化,因为在训练过程中,上一层传递下去的值千奇百怪,什么样子的分布都有。BatchNorm就是通过对batch size这个维度归一化来让分布稳定下来。LayerNorm则是通过对Hidden size这个维度归一化来让某层的分布稳定。
- 接下来介绍两个最常用的标准化方法:Batch Normalization 和 Layer Normalization
1. Batch Norm
- BN的主要思想:
- Batch Normalization(纵向规范化:计算方式:针对单个神经元进行,利用网络训练时一个 mini-batch 的数据来计算该神经元xi的均值和方差,因而称为 Batch Normalization。
- 针对每个神经元,使数据在进入激活函数之前,沿着通道计算每个batch的均值、方差,‘强迫’数据保持均值为0,方差为1的正态分布, 避免发生梯度消失。
- 具体来说,就是把第1个样本的第1个通道,加上第2个样本第1个通道 … 加上第 N 个样本第1个通道,求平均,得到通道 1 的均值(注意是除以 N×H×W 而不是单纯除以 N,最后得到的是一个代表这个 batch 第1个通道平均值的数字,而不是一个 H×W 的矩阵)。求通道 1 的方差也是同理。对所有通道都施加一遍这个操作,就得到了所有通道的均值和方差。
- BN的使用位置: 全连接层或卷积操作之后,激活函数之前
- BN算法过程:
- 沿着通道计算每个batch的均值
- 沿着通道计算每个batch的方差做归一化
- 加入缩放和平移变量 γ \gamma γ和 β:保证每一次数据经过归一化后还保留原有学习来的特征,同时又能完成归一化操作,加速训练。 这两个参数是用来学习的参数
- BN的作用
- 允许较大的学习率;
- 减弱对初始化的强依赖性
- 保持隐藏层中数值的均值、方差不变,让数值更稳定,为后面网络提供坚实的基础;
- 有轻微的正则化作用(相当于给隐藏层加入噪声,类似Dropout)
2. Layer Normalization(横向规范化)-结构中最常用的归一化操作
它的作用是 对特征张量按照某一维度或某几个维度进行0均值,1方差的归一化 操作
y
=
x
−
E
(
x
)
V
ar
(
x
)
+
ϵ
∗
γ
+
β
\mathrm{y}=\frac{\mathrm{x}-\mathrm{E}(\mathrm{x})}{\sqrt{\mathrm{V} \operatorname{ar}(\mathrm{x})+\epsilon}} * \gamma+\beta
y=Var(x)+ϵx−E(x)∗γ+β
3. BN和LN对比
- BatchNorm是对一个batch-size样本内的每个特征做归一化,LayerNorm是对每个样本的所有特征做归一化。BN 的转换是针对单个神经元可训练的:不同神经元的输入经过再平移和再缩放后分布在不同的区间;而 LN 对于一整层的神经元训练得到同一个转换:所有的输入都在同一个区间范围内。如果不同输入特征不属于相似的类别(比如颜色和大小),那么 LN 的处理可能会降低模型的表达能力。
- BN抹杀了不同特征之间的大小关系,但是保留了不同样本间的大小关系;LN抹杀了不同样本间的大小关系,但是保留了一个样本内不同特征之间的大小关系
- 在BN和LN都能使用的场景中,BN的效果一般优于LN,原因是基于不同数据,同一特征得到的归一化特征更不容易损失信息。但是有些场景是不能使用BN的,例如batch size较小或者序列问题中可以使用LN。这也就解答了RNN 或Transformer为什么用Layer Normalization
4. Instance Norm-针对图像像素做normalization
- 最初用于图像的风格化迁移。在图像风格化中,生成结果主要依赖于某个图像实例,feature map 的各个 channel 的均值和方差会影响到最终生成图像的风格。所以对整个batch归一化不适合图像风格化中,因而对H、W做归一化。可以加速模型收敛,并且保持每个图像实例之间的独立
1.12 相似度函数篇
1. 除了cosin还有哪些算相似度的方法
常见的相似度计算方法还包括欧氏距离、曼哈顿距离、Jaccard相似度、皮尔逊相关系数等
2. 了解对比学习嘛
- 对比学习是一种无监督学习方法,通过训练模型使得相同样本的表示更接近,不同样本的表示更远离,从而学习到更好的表示。对比学习通常使用对比损失函数,例如Siamese网络、Triplet网络等,用于学习数据之间的相似性和差异性
3. 对比学习负样本是否重要?负样本构造成本过高应该怎么解决?
- 对比学习中负样本的重要性取决于具体的任务和数据。负样本可以帮助模型学习到样本之间的区分度,从而提高模型的性能和泛化能力。然而,负样本的构造成本可能会较高,特别是在一些领域和任务中。
- 为了解决负样本构造成本过高的问题,可以考虑以下方法:
- 降低负样本的构造成本:通过设计更高效的负样本生成算法或采样策略,减少负样本的构造成本。例如,可以利用数据增强技术生成合成的负样本,或者使用近似采样方法选择与正样本相似但不相同的负样本
- 确定关键负样本:根据具体任务的特点,可以重点关注一些关键的负样本,而不是对所有负样本进行详细的构造。这样可以降低构造成本,同时仍然能够有效训练模型。
- 迁移学习和预训练模型:利用预训练模型或迁移学习的方法,可以在其他领域或任务中利用已有的负样本构造成果,减少重复的负样本构造工作
1.13 FAQ
1. 什么是生成式大模型
- 生成式大模型(一般简称大模型LLMs)是指能用于创作新内容,例如文本、图片、音频以及视频的一类深度学习模型。相比普通深度学习模型,主要有两点不同:
- 模型参数量更大,参数量都在Billion级别;
- 可通过条件或上下文引导,产生生成式的内容(所谓的prompt engineer就是由此而来)
2. 大模型是怎么让生成的文本丰富而不单调的呢
- 从训练角度来看:
- 基于Transformer的模型参数量巨大,有助于模型学习到多样化的语言模式与结构;
- 各种模型微调技术的出现,例如P-Tuning、Lora,让大模型微调成本更低,也可以让模型在垂直领域
有更强的生成能力; - 在训练过程中加入一些设计好的loss,也可以更好地抑制模型生成单调内容;
- 从推理角度来看:
- 基于Transformer的模型可以通过引入各种参数与策略,例如temperature,nucleus samlper来改变每次生成的内容。
3. LLMs 复读机问题
定义
- 字符级别重复,指大模型针对一个字或一个词重复不断的生成
- 语句级别重复,大模型针对一句话重复不断的生成
- 章节级别重复,多次相同的prompt输出完全相同或十分近似的内容,没有一点创新性的内容
- 大模型针对不同的prompt也可能会生成类似的内容,且有效信息很少、信息熵偏低
为什么会出现 LLMs 复读机问题?
- 数据偏差
- 训练目标的限制
- 缺乏多样性的训练数据
- 模型结构和参数设置
- 从 induction head[1]机制的影响角度:也就是模型会倾向于从前面已经预测的word里面挑选最匹配的词
- 从信息熵的角度分析。“在模型生成采样时,我们就应该只采样那些与条件熵对应概率接近的字符”[2],但是我更理解为信息淹没;比如电商标题,作为一种语句连贯性很弱、基本是词序堆叠的文本,它的信息熵无疑是很高的,下一个词预测时,概率后验基本上很难预测出来,Softmax的分布也倾向于平稳,也就是说模型也预测不出来下一个词应该是什么。因此模型会倾向从前面的word里面挑选。无论是专业翻译大模型M2M、NLLB还是通用语言模型ChatGPT,LLAMA等, <HJIKL, HJIKLL,HJIKLL…>的TSNE二维分布基本一致;也就是你添加了LLLL后,文本语义基本没有变化
解决
- Unlikelihood Training:思路:在训练中加入对重复词的抑制来减少重复输出;
- 一般对于生成式任务,只需要在原模型基础上加入unlikelihood training进行sentence级别finetune即可,不需要通过token级别的unlikelihood和likelihood loss叠加训练。
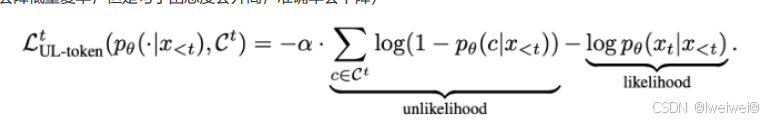
- 引入噪声:在生成文本时,引入一些随机性或噪声,例如通过采样不同的词或短语,或者引入随机的变换操作,以增加生成
文本的多样性。这可以通过在生成过程中对模型的输出进行采样或添加随机性来实现 - Repetition Penalty:思路:重复性惩罚方法通过在模型推理过程中加入重复惩罚因子,对原有softmax结果进行修正,降低重复生成的token被选中的概率
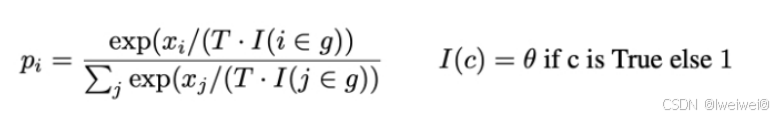
- 注:其中T代表温度,温度越高,生成的句子随机性越强,模型效果越不显著;I就代表惩罚项,c代表我们保存的一个list,一般为1-gram之前出现过的单词,theta值一般设置为1.2,1.0代表没有惩罚。 - Beam Search::Beam Search是对贪心策略一种改进。思路简单,就是稍微放宽考察的范围。在每一个时间步,不再只保留当前分数最高的1个输出,而是保留num_beams个。当num_beams=1时集束搜索(Beam Search)就退化成了贪心搜索。Beam Search虽然本质上并没有降低重复率的操作,但是该策略确实在结果上优化了部分生成结果,降低了一定的重复率。
- TopK通过对Softmax的输出结果logit中最大的K个token采样来选择输出的token,该方法存在的问题是当概率分布很极端时,即模型很确定下一个token时,容易造成生成错误。以下图为例,TopK采样会选择最大的K个token,并通过logit值对K个token进行采样,相比于贪心搜索增添了随机性,相当于同样的输入,多次经过TopK采样生成的结果大概率不会一样。
- Nucleus sampler俗称TopP采样,一种用于解决TopK采样问题的新方法,该采样方式不限制K的数目,而是通Softmax后排序token的概率,当概率大于P时停止,相当于当模型很确定下一个token时,可采样的K也会很少,减少异常错误发生的概率。以下图为例,TopP采样会不断选择logit中最大概率的token,放入一个list中,直到list中计算的总概率大于设置的TopP值,后对list中的token概率进行重新计算,最终根据计算出来的概率值对list中的token进行采样
4. 如何让大模型处理更长的文本?
- 动机:目前绝大多数大模型支持的token最大长度为2048,因为序列长度直接影响Attention的计算复杂度,
太长了会影响训练速度。 - 让大模型处理更长的文本 方法
- LongChat
- step1:将新的长度压缩到原来2048长度上,这样的好处是能复用原来的位置信息,增加长度并没有破坏position的权重。比如从2048扩展到16384,长度变为原来的8倍,那么值为10000的position_id,被压缩成10000/8=1250代码只需要改一行:
- step2:用训练Vicuna的对话语料做微调,超过16k的文本被截断。
- position等比例缩放既然有用,那后续会不会有一种新的position构造的方式,无论多长都可以归一到同样的尺度下,只要position的相对位置保持不变就可以?其实ALiBi的方法就是一个比较简单优雅的方式,可以部
分解决扩展长度的问题
- position等比例缩放既然有用,那后续会不会有一种新的position构造的方式,无论多长都可以归一到同样的尺度下,只要position的相对位置保持不变就可以?其实ALiBi的方法就是一个比较简单优雅的方式,可以部
- 商业模型比如ChatGPT和Claude到底是怎么做的?这个目前都没有公开。首先语料是不缺的,所以只能是结构上的变化。但是这两个商业模型规模都是100B这个量级的,这么大的参数,如果只增加序列长度而不做其
他优化的话,很难训练起来。目前有证据的方法如下:- 稀疏化,GPT3的论文中曾提到有这方面的尝试。
- Google的周彦祺在一次分享中透露GPT-4用了MoE的技术(猜测是100B16E),所以应该有类似的方法
来保证在序列变长的情况下,仍然能高效的训练模型。 - Multi-Query Attention。Google的PaLM,Falcon等模型都用到过,通过权重共享来提升性能。
- 真正的出路可能还是Linear Attention,将Attention的复杂度从O(N2)降低为O(N). 比如Linear Transformer和RWKV。其实关于变长序列的问题,历史上现成的解决方案就是RNN,通过信息传递来解决。Transformer的卖点就是Attention is All your Need,丢弃了RNN,RWKV敢于把RNN拿回来,还是很有勇气,非常好的一个工作。现在的Attention就有点像历史上的MLP,每个节点之间都要建立关联,而MLP之后涌现了大量新的结构,所以Transformer是起点,后续肯定会有更合理的结构来取代它
02 大语言模型架构
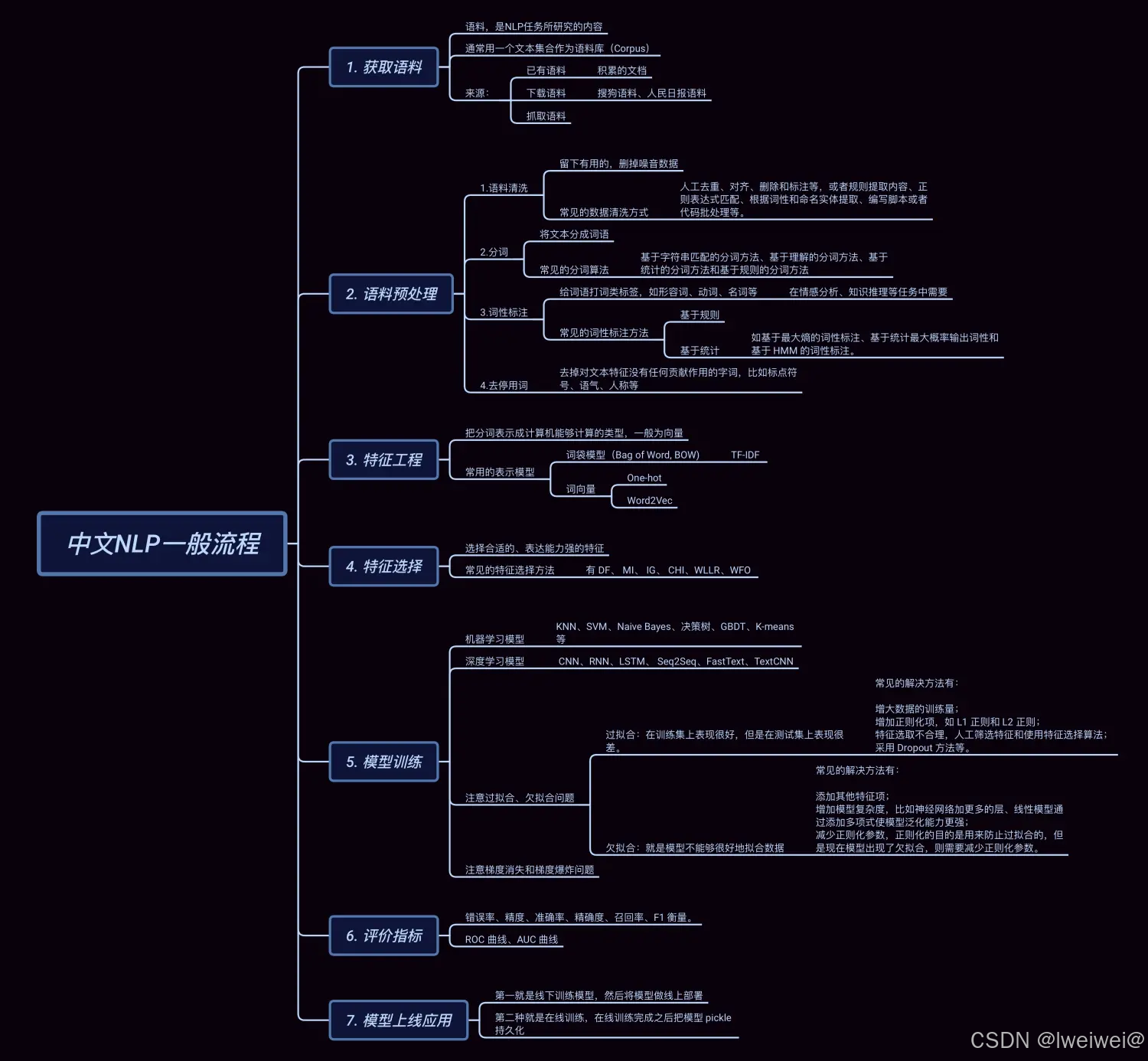
2.1 中文NLP的一般流程
- 获取预料
- 预料预处理
- 语料清洗
- 分词
- 词性标注
- 去停用词
- 特征工程
- 词袋模型:一般为IF-IDF
- 词向量:wor2Vec
- 特征选择
- 模型训练
- 评价指标
- 模型上线应用
2.2 主流的开源模型体系有哪些?
主流的开源模型体系:prefix Decoder 和 causal Decoder 和 Encoder-Decoder
目前 主流的开源模型体系 分三种:
- 第一种:prefix Decoder 系
- 特点:prefix部分的token互相能看到,causal Decoder 和 Encoder-Decoder 折中;
- 缺点:训练效率低
- 代表模型:ChatGLM、ChatGLM2、U-PaLM
- 第二种:causal Decoder 系
- 自回归语言模型,预训练和下游应用是完全一致的,严格遵守只有后面的token才能看到前面的token的规则;
- 适用任务:文本生成任务效果好
- 优点:训练效率高,zero-shot 能力更强,具有涌现能力
- 代表模型:LLaMA-7B、LLaMa 衍生物
- 第三种:Encoder-Decoder
- 在输入上采用双向注意力,对问题的编码理解更充分
- 适用任务:在偏理解的 NLP 任务上效果好
- 缺点:在长文本生成任务上效果差,训练效率低;
- 代表模型:T5、Flan-T5、BART
对比表格
| 项目 | Value | Value | Value |
|---|---|---|---|
| GPT(Generative Pre-trained Transformer)系列 | 由OpenAI发布的一系列基于Transformer架构的语言模型,包括GPT、GPT-2、GPT-3等。 | GPT模型通过在大规模无标签文本上进行预训练,然后在特定任务上进行微调,具有很强的生成能力和语言理解能力。 | 使用单向Encoder,利用了 Transformer 的编码器作为语言模型进行预训练的,之后特定的自然语言处理任务在其基础上进行微调即可 |
| BERT(Bidirectional Encoder Representations from Transformers) | 由Google发布的一种基于Transformer架构的双向预训练语言模型。 | BERT模型通过在大规模无标签文本上进行预训练,然后在下游任务上进行微调,具有强大的语言理解能力和表征能力。 | Bert是一种预训练的语言模型,适用于各种自然语言处理任务,如文本分类、命名实体识别、语义相似度计算等。如果你的任务是通用的文本处理任务,而不依赖于特定领域的知识或语言风格,Bert模型通常是一个不错的选择。Bert由一个Transformer编码器组成,更适合于NLU相关的任务。 |
| XLNet | 由CMU和Google Brain发布的一种基于Transformer架构的自回归预训练语言模型。 | XLNet模型通过自回归方式预训练,可以建模全局依赖关系,具有更好的语言建模能力和生成能力。 | |
| RoBERTa | 由Facebook发布的一种基于Transformer架构的预训练语言模型。 | RoBERTa模型在BERT的基础上进行了改进,通过更大规模的数据和更长的训练时间,取得了更好的性能。 | |
| T5(Text-to-Text Transfer Transformer) | 由Google发布的一种基于Transformer架构的多任务预训练语言模型。 | T5模型通过在大规模数据集上进行预训练,可以用于多种自然语言处理任务,如文本分类、机器翻译、问答等 | |
| LLaMA模型 | LLaMA(Large Language Model Meta AI)包含从 7B 到 65B 的参数范围, - 训练使用多达14,000亿tokens语料,具有常识推理、问答、数学推理、代码生成、语言理解等能力。LLaMA由一个Transformer解码器组成。训练预料主要为以英语为主的拉丁语系,不包含中日韩文。所以适合于英文文本生成的任务。 | ||
| ChatGLM模型 | 是一个面向对话生成的语言模型,适用于构建聊天机器人、智能客服等对话系统。如果你的应用场景需要模型能够生成连贯、流畅的对话回复,并且需要处理对话上下文、生成多轮对话等,ChatGLM模型可能是一个较好的选择。ChatGLM的架构为Prefix decoder,训练语料为中英双语,中英文比例为1:1。所以适合于中文和英文文本生成的任务 |
2.3 BERT
框架
- BERT(Bidirectional Encoder Representations from Transformers)是谷歌提出,作为一个Word2Vec的替代者,其在NLP领域的11个方向大幅刷新了精度
- 使用了双向Transformer作为算法的主要框架,之前的模型是从左向右输入一个文本序列,或者将 left-to-right 和 right-to-left 的训练结合起来,实验的结果表明,双向训练的语言模型对语境的理解会比单向的语言模型更深刻;
- 使用了Mask Language Model(MLM)和 Next Sentence Prediction(NSP) 的多任务训练目标;
- Masked LM (MLM) : 在将单词序列输入给 BERT 之前,每个序列中有 15% 的单词被 [MASK] token 替换。 然后模型尝试基于序列中其他未被 mask 的单词的上下文来预测被掩盖的原单词
- 80% 的 tokens 会被替换为 [MASK] token:是 Masked LM 中的主要部分,可以在不泄露 label 的情况下融合真双向语义信息;
- 10% 的 tokens 会称替换为随机的 token :因为需要在最后一层随机替换的这个 token 位去预测它真实的词,而模型并不知道这个 token 位是被随机替换的,就迫使模型尽量在每一个词上都学习到一个 全局语境下的表征,因而也能够让 BERT 获得更好的语境相关的词向量(这正是解决一词多义的最重要特性);
- Next Sentence Prediction (NSP) : 在 BERT 的训练过程中,模型接收成对的句子作为输入,并且预测其中第二个句子是否在原始文档中也是后续句子
- 在训练期间,50% 的输入对在原始文档中是前后关系,另外 50% 中是从语料库中随机组成的,并且是与第一句断开的。
- 在第一个句子的开头插入 [CLS] 标记,表示该特征用于分类模型,对非分类模型,该符号可以省去,在每个句子的末尾插入 [SEP] 标记,表示分句符号,用于断开输入语料中的两个句子
- Masked LM (MLM) : 在将单词序列输入给 BERT 之前,每个序列中有 15% 的单词被 [MASK] token 替换。 然后模型尝试基于序列中其他未被 mask 的单词的上下文来预测被掩盖的原单词
- BERT 只利用了 Transformer 的 encoder 部分。因为BERT 的目标是生成语言模型,所以只需要 encoder 机制
==
2.1 Transformer模型
结构
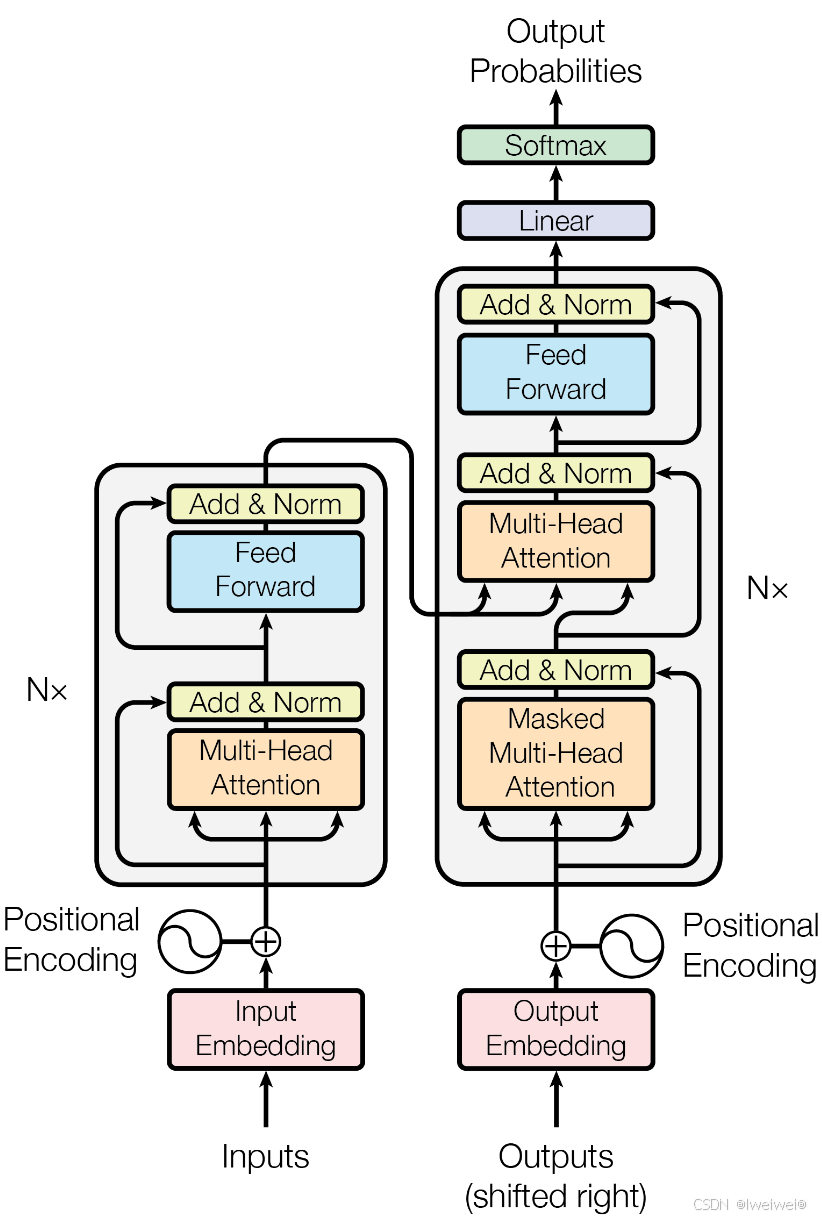
1. Encoder模块
- 经典的Transformer架构中的Encoder模块包含6个Encoder Block.
- 每个Encoder Block包含两个⼦模块, 分别是多头⾃注意⼒层, 和前馈全连接层.
- 多头⾃注意⼒层采⽤的是⼀种Scaled Dot-Product Attention的计算⽅式, 实验结果表 明, Multi-head可以在更细致的层⾯上提取不同head的特征, ⽐单⼀head提取特征的 效果更佳.
- 前馈全连接层是由两个全连接层组成, 线性变换中间增添⼀个Relu激活函数, 具体的 维度采⽤4倍关系, 即多头⾃注意⼒的d_model=512, 则层内的变换维度d_ff=2048.
2. Decoder模块
- 经典的Transformer架构中的Decoder模块包含6个Decoder Block.
- 每个Decoder Block包含3个⼦模块, 分别是多头⾃注意⼒层, Encoder-Decoder Attention 层, 和前馈全连接层.
- 多头⾃注意⼒层采⽤和Encoder模块⼀样的Scaled Dot-Product Attention的计算⽅ 式, 最⼤的 区别在于需要添加look-ahead-mask, 即遮掩"未来的信息".
- Encoder-Decoder Attention层和上⼀层多头⾃注意⼒层最主要的区别在于Q != K = V, 矩阵Q来源于上⼀层Decoder Block的输出, 同时K, V来源于Encoder端的输出.
- 前馈全连接层和Encoder中完全⼀样.
Decoder端训练和预测的输入
- 在Transformer结构中的Decoder模块的输⼊, 区分于不同的Block, 最底层的Block输⼊有其特殊的地⽅。第⼆层到第六层的输⼊⼀致, 都是上⼀层的输出和Encoder的输出。
- 最底层的Block在训练阶段, 每⼀个time step的输⼊是上⼀个time step的输⼊加上真实标 签序列向后移⼀位. 具体来看, 就是每⼀个time step的输⼊序列会越来越⻓, 不断的将之前的 输⼊融合进来.
- 最底层的Block在训练阶段, 真实的代码实现中, 采⽤的是MASK机制来模拟输⼊序列不断添 加的过程.
- 最底层的Block在预测阶段, 每⼀个time step的输⼊是从time step=0开始, ⼀直到上⼀个 time step的预测值的累积拼接张量. 具体来看, 也是随着每⼀个time step的输⼊序列会越来越长. 相⽐于训练阶段最⼤的不同是这⾥不断拼接进来的token是每⼀个time step的预测值, ⽽不是训练阶段每⼀个time step取得的groud truth值
3. Add & Norm模块
- Add & Norm模块接在每⼀个Encoder Block和Decoder Block中的每⼀个⼦层的后⾯.
- 对于每⼀个Encoder Block, ⾥⾯的两个⼦层后⾯都有Add & Norm.
- 对于每⼀个Decoder Block, ⾥⾯的三个⼦层后⾯都有Add & Norm.
- Add表示残差连接, 作⽤是为了将信息⽆损耗的传递的更深, 来增强模型的拟合能⼒.
- Norm表示LayerNorm, 层级别的数值标准化操作, 作⽤是防⽌参数过⼤过⼩导致的学习过程异常 , 模型收敛特别慢的问题.
4. 位置编码器Positional Encoding
- Transformer中采⽤三⻆函数来计算位置编码.
- 因为三⻆函数是周期性函数, 不受序列⻓度的限制, ⽽且这种计算⽅式可以对序列中不同位置的编码的重要程度同等看待
Transformer中self-attention
- self-attention是⼀种通过⾃身和⾃身进⾏关联的attention机制, 从⽽得到更好的 representation来表达⾃身
- 优点
- 从上图中可以看到, self-attention可以远距离的捕捉到语义层⾯的特征(it的指代对象是 animal).
- 应⽤传统的RNN, LSTM, 在获取⻓距离语义特征和结构特征的时候, 需要按照序列顺序依次 计算, 距离越远的联系信息的损耗越⼤, 有效提取和捕获的可能性越⼩.
- 但是应⽤self-attention时, 计算过程中会直接将句⼦中任意两个token的联系通过⼀个计算 步骤直接联系起来,
关于self-attention为什么要使⽤(Q, K, V)三元组⽽不是其他形式
- ⾸先⼀条就是从分析的⻆度看, 查询Query是⼀条独⽴的序列信息, 通过关键词Key的提示作⽤, 得到最终语义的真实值Value表达, 数学意义更充分, 完备.
- 这⾥不使用(K, V)或者(V)没有什么必须的理由, 也没有相关的论⽂来严格阐述⽐较试验的结果差异, 所以可以作为开放性问题未来去探索, 只要明确在经典self-attention实现中⽤的是三元组就好
Transformer架构并行化机制
Transformer架构中Encoder模块的并行化机制
- Encoder模块在训练阶段和测试阶段都可以实现完全相同的并行化.
- Encoder模块在Embedding层, Feed Forward层, Add & Norm层都是可以并行化的.
- Encoder模块在self-attention层, 因为各个token之间存在依赖关系, 无法独立计算, 不是真正意义上的并行化.
- Encoder模块在self-attention层, 因为采用了矩阵运算的实现方式, 可以一次性的完成所有注意力张量的计算, 也是另一种"并行化"的体现.
- Transformer架构中Decoder模块的并行化机制
Decoder模块在训练阶段可以实现并行化.
- Decoder模块在训练阶段的Embedding层, Feed Forward层, Add & Norm层都是可以并行化的.
- Decoder模块在self-attention层, 以及Encoder-Decoder Attention层, 因为各个token之间存在依赖关系, 无法独立计算, 不是真正意义上的并行化.
- Decoder模块在self-attention层, 以及Encoder-Decoder Attention层, 因为采用了矩阵运算的实现方式, 可以一次性的完成所有注意力张量的计算, 也是另一种"并行化"的体现.
- Decoder模块在预测计算不能并行化处理.
2.2 llama系列模型
2.3 chatglm系列模型
2.4 langchain
1. 定义&结构
- LangChain是用于构建大语言模型应用的工程化解决方案
- 既然是工程化的解决方案,LangChain符合一般软件的基本结构
LangChain的基本结构- Runtime(运行时):技术基座
- 内存+持久化:软件必要的部分
- 逻辑层:逻辑控制的部分
- 方案设计:软件开发前的技术设计
- 可观测:系统在线上运行时,对系统运作状态(Metrics)、问题排查(Log, Trace)的观测
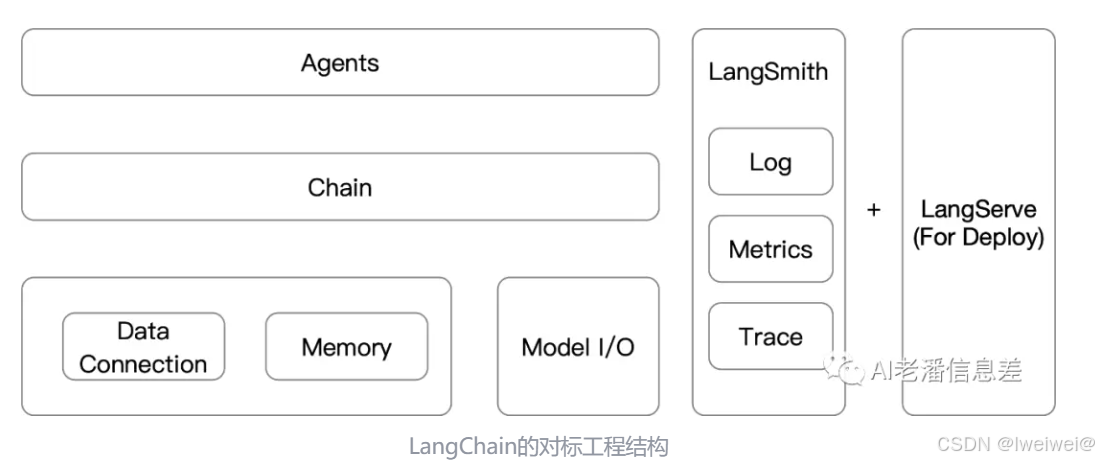
- Module I/O 对标 Runtime
- 持久化 对标 DataConnection
- Chain 对标 逻辑层
- Agents 对标 方案设计
- LangSmith 对标 可观测
1. Runtime模块 -> Model I/O
- 任何语言模型应用的核心元素是模型的输入和输出。LangChain提供了与任何语言模型进行接口交互的基本组件
- 提示 prompts:将模型输入模板化、动态选择和管理
- 语言模型 models:通过常见接口调用语言模型
- 输出解析器 output_parsers:从模型输出中提取信息
2. Memory模块
- 对话的一个重要组成部分是能够引用对话中先前介绍的信息。至少,对话系统应该能够直接访问过去消息的某些窗口
- 在收到初始用户输入之后但在执行核心逻辑之前,链将从其内存系统中读取并增加用户输入。
- 在执行核心逻辑之后但在返回答案之前,链会将当前运行的输入和输出写入内存,以便在将来的运行中引用它们。
3. 持久化 -> Data Connection
- 许多LLM应用程序需要用户特定数据,这些数据不是模型的训练集的一部分。完成这一任务的主要方法是通过检索增强生成(RAG)。在此过程中,检索外部数据,然后在生成步骤中将其传递给LLM
- RAG步骤:data connection,load,transform,embed,store,retrieve
4. 逻辑层 -> Chain
- 在简单应用中,单独使用LLM是可以的,但更复杂的应用需要将LLM进行链接 - 要么相互链接,要么与其他组件链接
- LangChain为这种"链接"应用提供了Chain接口。LangChain将链定义得非常通用,它是对组件调用的序列,可以包含其他链。基本接口很简单:
5. 技术方案 -> 智能体(Agents)
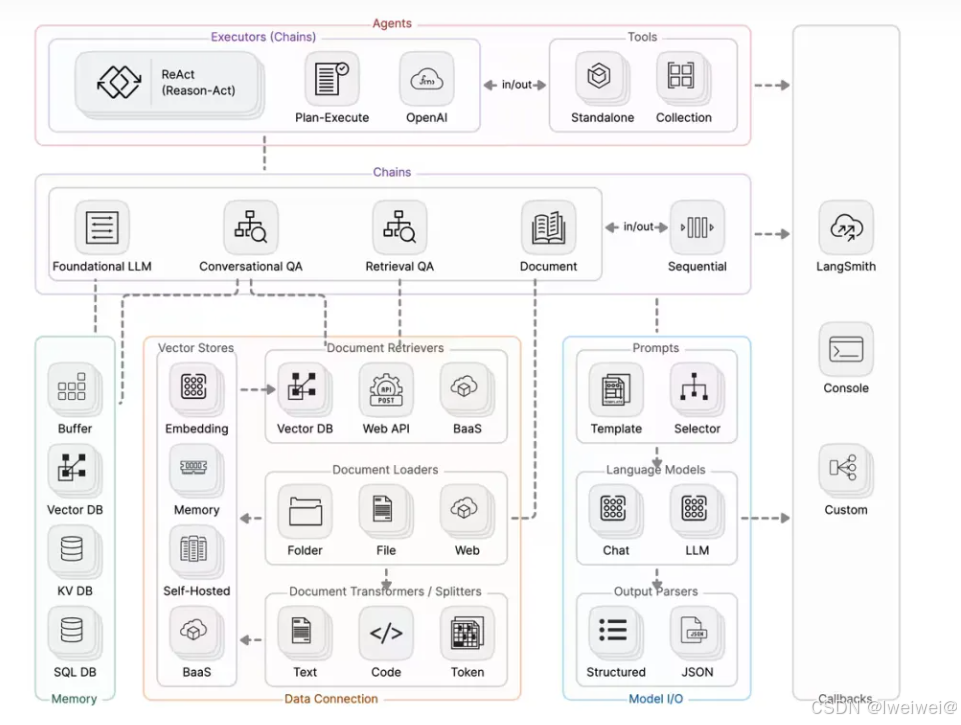
- 智能体的核心思想是使用LLM来选择要采取的一系列动作。在链式结构中,一系列动作是硬编码的(在代码中)。在代理中,使用语言模型作为推理引擎来确定要采取的动作及其顺序
- 代理 Agent
- 这是负责决定下一步采取什么动作的类。这是由语言模型和提示词驱动的。该输入可以包括以下内容:Tools: 可用工具的描述.\用户输入: 高级别的目标; 中间步骤: 之前为了实现用户的输入, 而执行的任何的(action, tool output) 输出是要执行的下一个操作或要发送给用户的最终响应(AgentActions 或 AgentFinish)。操作指定工具以及该工具的输入。不同的智能体有不同的推理提示风格、不同的编码输入方式以及不同的解析输出方式。
- 工具(Tools):工具是代理调用的函数
- 工具包(Toolkits):代理可以访问的工具集合通常比单个工具更重要
- 智能体执行器(AgentExecutor):智能体执行是智能体的运行时。这是实际调用智能体并执行其选择的动作的部分。以下是此运行时的伪代码:
6. 结构图
04 分布式训练
4.1 FAQ
1. 训练 大语言模型 存在问题?
- 计算资源需求训练大型语言模型需要大量的计算资源,包括高端 GPU、大量的内存和高速存储器。这可能限制了许多研究人员和组织的训练能力,因为这些资源通常很昂贵。
- 数据需求**:** 训练大型语言模型需要大规模的数据集,这些数据集通常需要大量的标注和清洗工作。获取高质量的数据可能是一项困难和昂贵的任务。
- 长时间训练**:** 训练大型语言模型需要大量的时间。特别是对于巨型模型,训练可能需要数周甚至数月的时间,这增加了实验的时间和成本。
- 环境影响**:** 大规模模型的训练需要大量的能源和计算资源,可能对环境造成影响。这引发了对训练模型的可持续性和能源效率的关注。
- 过拟合和泛化**:** 训练大型模型可能导致过拟合问题,特别是当训练数据集不能充分覆盖所有可能的语言情况和使用场景时。此外,对于大型模型,泛化能力可能会受到一定程度的影响。
- 认知偏差和歧视性**:** 如果训练数据集存在偏差或歧视性,大型语言模型可能会继承这些问题,并在生成文本时表现出类似的偏见。
2. 什么是 点对点通信
点对点通信(Peer-to-Peer Communication)是一种网络通信模式,其中两个或多个计算机或设备之间直接进行通信,而不需要通过中央服务器或集中式系统。在点对点通信中,每个参与者都可以充当客户端和服务器,能够直接与其他节点通信、交换信息或共享资源。
这种通信模式与传统的客户端-服务器模型不同,后者在网络中有一个中心服务器负责处理和转发所有请求和数据。而点对点通信模式中,参与者之间能够直接建立连接,相互传输信息或资源,使得网络更为分散和去中心化。
3. 什么是 集体通信
集体通信(Collective Communication)是指一组计算节点或处理单元之间进行协作、交换信息或执行通信操作的过程。这种通信形式涉及到多个节点之间的集体参与,而不仅仅是点对点的通信。它可以用于并行计算、分布式系统和群集计算等领域,以便在多个节点之间协调和管理数据的传输、处理和同步操作。
集体通信常见的操作包括广播、散射、汇总、规约和全局同步等
4. 数据并行 vs 张量并行 vs 流水线并行?
数据并行、张量并行和流水线并行是在并行计算中常见的三种策略,它们有不同的应用场景和优势:
1、数据并行(Data Parallelism):
- 概念: 数据并行是指将整个模型复制到每个处理单元上,不同处理单元处理不同的数据子集。每个处理单元独立计算,并通过同步更新模型参数来实现训练。
- 适用场景: 数据并行适用于大型模型和数据集,特别是在深度学习中。每个处理单元负责计算不同数据子集上的梯度,然后同步更新模型参数。
- 优势: 易于实现,适用于大规模数据和模型。
2、张量并行(Tensor Parallelism):
- 概念: 张量并行是指将模型分解成多个部分,每个部分在不同处理单元上进行计算。通常,这涉及到在层与层之间划分模型,并在不同的 GPU 或处理单元上执行这些部分。
- 适用场景: 张量并行适用于非常大的模型,其中单个 GPU 的内存容量无法容纳整个模型。它允许将模型的不同部分分配到不同的处理单元上,从而扩展模型的规模。
- 优势: 适用于大型模型的规模扩展,可用于解决内存限制问题。
3、流水线并行(Pipeline Parallelism):
- 概念: 流水线并行是指将模型的不同层分配到不同的处理单元上,并通过将不同层的输出传递给下一层来实现计算。每个处理单元负责一个模型层的计算。
- 适用场景: 流水线并行适用于深层次的模型,其中各层之间的计算相对独立。它可以提高模型的整体计算速度,特别是在层之间存在较大的计算延迟时。
- 优势: 适用于深层次模型,减少整体计算时间。
5. 想要训练1个LLM,如果只想用1张显卡,那么对显卡的要求是什么
显卡显存足够大,nB模型微调一般最好准备20nGB以上的显存。
- 显存大小**:** 大型语言模型需要大量的显存来存储模型参数和中间计算结果。通常,至少需要 16GB 或更多的显存来容纳这样的模型。对于较小的模型,8GB 的显存也可能足够。
- 计算能力**:** 针对大型神经网络模型,较高的计算能力通常可以加快训练速度。通常情况下,NVIDIA 的 RTX 系列或者 A系列的显卡具有较高的性能和计算能力,例如 RTX 2080 Ti、RTX 3080、RTX 3090 等。这些显卡提供了更多的 CUDA 核心和更高的计算能力,能够更快地处理大型模型。
- 带宽和速度**:** 显卡的显存带宽和速度也是一个考虑因素。较高的内存带宽可以更快地从内存读取数据,对于大型模型的训练非常重要。
- 兼容性和优化**:** 良好的软硬件兼容性以及针对深度学习训练任务的优化也是考虑的因素。确保显卡与所选深度学习框架兼容,并且可以利用框架提供的优化功能。
6. 如果有N张显存足够大的显卡,怎么加速训练?
- 数据并行化**:** 在数据并行化中,模型的多个副本在不同的 GPU 上训练相同的数据批次。每个 GPU 计算梯度,并将结果汇总到主 GPU 或进行参数更新。这种方法适用于模型过大而无法完全容纳在单个 GPU 内存中的情况。
- 模型并行化**:** 在模型并行化中,模型的不同部分分配到不同的 GPU 上。每个 GPU 负责计算其分配的部分,并将结果传递给其他 GPU。这对于大型模型,特别是具有分层结构的模型(如大型神经网络)是有益的。
- 分布式训练**:** 使用分布式框架(例如 TensorFlow 的 tf.distribute 或 PyTorch 的 torch.nn.parallel.DistributedDataParallel)来实现训练任务的分布式执行。这允许将训练任务分配到多个 GPU 或多台机器上进行加速。
- 优化批处理大小**:** 增大批处理大小可以提高 GPU 利用率,但需要注意的是,批处理大小的增加也可能导致内存不足或梯度下降不稳定。因此,需要根据模型和硬件配置进行合理的调整。
- 混合精度训练**:** 使用半精度浮点数(例如 TensorFlow 的 tf.keras.mixed_precision 或 PyTorch 的 AMP)来减少内存占用,加速训练过程。
- 模型剪枝和优化**:** 对模型进行剪枝和优化以减少模型的大小和计算负荷,有助于提高训练速度和效率。
7. 如果显卡的显存不够装下一个完整的模型呢
最直观想法,需要分层加载,把不同的层加载到不同的GPU上(accelerate的device_map)也就是常见的PP,流水线并行
8. PP推理时,是一个串行的过程,1个GPU计算,其他空闲,有没有其他方式
微批次流水线并行:
- 微批次(MicroBatch)流水线并行与朴素流水线几乎相同,但它通过将传入的小批次(minibatch)分块为微批次(microbatch),并人为创建流水线来解决 GPU 空闲问题,从而允许不同的 GPU 同时参与计算过程,可以显著提升流水线并行设备利用率,减小设备空闲状态的时间。目前业界常见的流水线并行方法 GPipe 和 PipeDream 都采用微批次流水线并行方案
9. 分布式并行及显存优化技术并行技术有哪一些,都有什么特点
分布式并行技术:
-
数据并行(Data Parallelism):
- 特点: 将数据分成多个子集,分配给不同的处理单元,每个处理单元计算不同的数据子集。处理单元之间共享模型参数,然后同步参数更新。
- 优点: 可以处理大规模数据和模型,易于实现,能够加速训练过程。
-
模型并行(Model Parallelism):
- 特点: 将模型划分成多个部分,在不同的设备上并行计算这些部分。通常用于大型模型,每个设备负责处理整个模型的不同部分。
- 优点: 可以应对模型过大,无法放入单个设备内存的情况。
-
流水线并行(Pipeline Parallelism):
- 特点: 将计算过程划分为多个阶段,不同设备同时执行不同阶段的计算。每个设备负责处理流程中的不同阶段,类似于流水线。
- 优点: 可以在一定程度上减少设备空闲时间,提高并行效率。
-
显存优化技术:
- 模型裁剪(Model Pruning):
- 特点: 去除模型中不必要的参数或结构,减小模型大小和内存占用。
- 优点: 可以降低模型的存储需求,适用于显存不足的情况。
- 模型压缩(Model Compression):
- 特点: 使用量化、剪枝等方法减小模型大小,减少显存占用。
- 优点: 降低模型存储空间,适用于显存限制的场景。
- 混合精度计算(Mixed Precision Computing):
- 特点: 使用较低精度(如半精度浮点数)进行计算,减少显存使用。
- 优点: 可以在一定程度上减少显存需求,提高计算效率。
- 模型裁剪(Model Pruning):
10. 常见的分布式训练框架哪一些,都有什么特点
| 项目 | Value | Value |
|---|---|---|
| Megatron-LM | Megatron 是由 NVIDIA 深度学习应用研究团队开发的大型 Transformer 语言模型,该模型用于研究大规模训练大型语言模型。 | Megatron 支持transformer模型的模型并行(张量、序列和管道)和多节点预训练,同时还支持 BERT、GPT 和 T5 等模型。 |
| DeepSpeed | 是微软的深度学习库,已被用于训练 Megatron-Turing NLG 530B 和 BLOOM等大型模型 | 创新体现在三个方面:训练、推理、压缩,练/推理具有数十亿或数万亿个参数的密集或稀疏模型;实现出色的系统吞吐量并有效扩展到数千个 GPU |
| FairScale | 用于高性能和大规模训练的 PyTorch 扩展 | FairScale 的愿景:可用性:用户应该能够以最小的认知代价理解和使用 FairScale API;模块化:用户应该能够将多个 FairScale API 无缝组合为训练循环的一部分;性能:airScale API 在扩展和效率方面提供了最佳性能。 |
11. 显存问题
-
大模型大概有多大,模型文件有多大?
大模型也分为不同的规格,一般模型的规格会体现在模型的名称上,例如 LLaMA2-13b,13b 就是其模型参数量的大小,意思是 130亿的参数量。大模型的文件大小与其参数量有关,通常大模型是以半精度存储的, Xb 的模型文件大概是 2X GB多一些,例如 13b 的模型文件大小大约是 27GB 左右。 -
能否用4 * v100 32G训练vicuna 65b?
一般来说推理模型需要的显存约等于模型文件大小,全参训练需要的显存约为推理所需显存的三倍到四倍,正常来说,在不量化的情况下4张 v100 显卡推理 65b 的模型都会有一些吃力,无法进行训练,需要通过 LoRA 或者****QLoRA 采用低秩分解的方式才可以训练。 -
如何评估你的显卡利用率?
- flops比值法:gpu利用率 = 实测的flops/显卡理论上的峰值flops。deepspeed实测flops 100t flops,而用的是A100卡理论峰值312t flops,可以得到GPU利用率只有 32.05%。
- throughout估计法:吞吐量 = example数量/秒/GPU * max_length;gpu利用率 = 实际吞吐量 / 文中的吞吐量(假设利用率100%),实测训练时处理样本速度为 3 example/s,一共有4卡,max length 2048,则吞吐量为 1536 token/s/gpu,根据llama论文可以得知,他们训练7B模型的吞吐量约为 3300 token/s/gpu,那么GPU利用率只有46.54%
- torch profiler分析法:利用torch profiler记录各个函数的时间,将结果在tensorboard上展示,在gpu kenel视图下,可以看到tensor core的利用率,比如30%。
-
如何查看多机训练时的网速?
iftop -i eth2 -n -P
iftop 是外置的命令,可以监控发送流量,接收流量,总流量,运行 iftop 到目前时间的总流量,流量峰值,过去 2s 10s 40s 的平均流量。 -
如何查看服务器上的多卡之间的NVLINK topo?
nvidia-smi topo -m -
如何查看服务器上显卡的具体型号?
cd /usr/local/cuda/samples/1_Utilities/deviceQuery make ./deviceQuery -
如何查看训练时的 flops?(也就是每秒的计算量)
如果基于deepspeed训练,可以通过配置文件很方便地测试。{ "flops_profiler": { "enabled": true, "profile_step": 1, "module_depth": -1, "top_modules": 1, "detailed": true, "output_file": null } } -
如何查看对 deepspeed 的环境配置是否正确?
ds_report -
TF32 格式有多长?
TF32(TensorFloat32)是 NVIDIA 在 Ampere 架构推出的时候面世的,现已成为 Tensorflow 和 Pytorch 框架中默认的32位格式。用于近似 FP32 精度下任务的专有格式,实际上约等于 FP19 也就是19位。
4.2 大模型训练过程
1. 数据收集、清洗、预处理(文本分词、词嵌入、位置编码→转化为数值张量)
| 项目 | Value |
|---|---|
| 数据收集 | 首先,需要收集大量的训练数据。这些数据通常是无标签的文本数据,如互联网上的新闻文章、博客、论坛帖子、书籍等。对于某些特定任务,还需要收集有标签的数据用于监督学习。 |
| 数据清洗 | 收集到的数据需要进行清洗,以去除噪音、无关信息以及个人隐私相关的内容。清洗后的数据将用于训练和优化模型。 |
| 数据预处理 | 预处理步骤包括文本分词(Tokenization)、词嵌入(Word Embedding)和位置编码(Positional Encoding)等。这些步骤将文本数据转换为模型可以处理的数值型张量(Tensor)。 |
数据集哪里找-数据增强
- 公开数据集:有许多公开可用的数据集可供使用,涵盖了各种领域和任务。例如,Common Crawl、Wikipedia、OpenWebText、BookCorpus等都是常用的大规模文本数据集,可以用于语言模型的训练。
- 开放数据平台:许多组织和机构提供了开放的数据平台,可以获取各种类型的数据。例如,Kaggle、UCI Machine Learning Repository、Google Dataset Search等平台都提供了丰富的数据集资源。
- 数据收集和爬取:如果没有合适的公开数据集,您可以自己进行数据收集和爬取。这可以通过爬虫技术从互联网上收集相关的文本数据。需要注意的是,在进行数据收集和爬取时,需要遵守法律法规和网站的使用条款,并确保获得数据的合法使用权。
- 数据增强:如果您已经有了一些初始的数据集,但觉得数量不够,可以考虑使用数据增强技术来扩充数据。数据增强可以通过对原始数据进行一些变换、替换、合成等操作来生成新的样本
- EDA(Easy Data Augmentation): 同义词替换、同义词随机插入、随机选择两个单词交换位置、随机删除一个单词
- 回译(Back Translation): 将文本翻译成另一种语言,然后再翻译回来。可以翻译成多种语言,从而得到多条回译样本
- Masked Language Model: 利用预训练好的BERT, Roberta等模型,对原句子进行部分掩码,然后让模型预测掩码部分,从而得到新的句子。但是,这种方法存在的一个问题是,决定要屏蔽文本的哪一部分并不简单。可以考虑使用启发式方法来确定掩码部分,否则,生成的文本可能无法保留原始句子的含义。(启发式方法:基于词性或词频等方法。基于词性选择对句子语义影响不大的介词、冠词、连词等,基于词频选择频率较高的功能词)
微调需要多少条数据
根据 Scaling Laws,随着模型大小、数据集大小和用于训练的计算浮点数的增加,模型的性能会提高。并且为了获得最佳性能,所有三个因素必须同时放大。一般来说对于给定模型的理想训练数据集 token 数量大约是模型中参数数量的20倍
有哪些大模型的训练集
以下是一些常用的大语言模型训练集的示例:
- Common Crawl:这是一个由互联网上抓取的大规模文本数据集,包含了来自各种网站的文本内容。它是一个常用的数据集,可用于语言模型的训练。
- Wikipedia:维基百科是一个包含大量结构化文本的在线百科全书。维基百科的内容丰富多样,涵盖了各种领域的知识,可以作为语言模型训练的数据集。
- OpenWebText:这是一个从互联网上抓取的开放文本数据集,类似于Common Crawl。它包含了大量的网页文本,可以作为语言模型的训练数据。
- BookCorpus:这是一个包含了大量图书文本的数据集,用于语言模型的训练。它包括了各种类型的图书,涵盖了广泛的主题和领域。
- News articles:新闻文章是另一个常用的语言模型训练集。可以通过从新闻网站、新闻API或新闻数据库中收集新闻文章来构建训练集。
- 其他领域特定数据集:根据具体任务和应用,可以使用特定领域的数据集来训练语言模型。例如,在医学领域,可以使用医学文献或医疗记录作为训练数据;在法律领域,可以使用法律文书或法律条款作为训练数据。
大模型预训练数据从哪里获取?(paper:The RefinedWeb Dataset for Falcon LLM: Outperforming Curated Corpora with Web Data, and Web Data Only)
1)获取来源
- 一类是网页数据(web data),这类数据的获取最为方便,各个数据相关的公司比如百度、谷歌等每天都会爬取大量的网页存储起来
- 比如非盈利性机构构建的CommonCrawl数据集是一个海量的、非结构化的、多语言的网页数据集
- 第二类称之为专有数据(curated high-quality corpora),为某一个领域、语言、行业的特有数据。比如对话、书籍、代码、技术报告、论文考试等数据
- 在OpenAI的GPT3,4模型以及谷歌的PaLM系列模型训练中,大量用到了专有数据,如2TB的高质量书籍数据(Books – 2TB)和社交媒体对话数据(Social media conversations)等
- 对比:网页数据好于专有数据:
- 网页数据的量级比公开数据大的多,仅用专有数据模型模型训练不到最佳效果:GPT3 论文中说自己模型参数是175B,使用了大约300B的token数量进行模型训练,但根据scaling law我们得知,训练175B的模型,想要获得最有效果数据量应该是3500B tokens,这几乎是现有最大训练数据库的两倍,是现有公开训练数据的10倍。
- 专有数据处理起来很麻烦:网页数据有固定的格式,我们可以根据html上面的标签进行处理,而专有数据因为来源很杂,格式不统一等原因,甚至需要一份数据,一种处理方式很费时间。
- 大部分专有数据其实在网页数据中也能找到:比如书籍数据,也可能在某些盗版书网站上就有网页版本的。
2)网页数据处理方法
- 很脏\很大,更多的还是需要先用启发式规则过滤下(启发式规则在高级计划与排程(APS)中是指基于直观经验或特定策略的算法,用于快速找到问题的可行解,而非最优解)
步骤:
-
URL过滤:也训练了一个根据关键词过滤URL的工具,但发现很多嘻哈文化网站、医疗网站等被过滤了,怕可能引起bias,所以设计了一套比较复杂的规则,来尽可能的减少false positive误判样本
-
文本内容提取:网页内容仅仅保留正文!URL、导航栏文本、标题、脚注、广告文本等和正文无关的信息要去除干净。使用trafilatura库用于从网页中提取正文
-
文本处理Pipeline
- 目标语言识别:将你需要的目标语言网页保留,这时候用到的模型是比较快的n-gram模型,比如fastTexts(假设下一个词的出现只与前面的N个词相关)
- 规则过滤:将有一些包含禁用词的网页,标点符号过多的行去掉。这个要非常注意,如果过滤关键词范围很大的话,模型可能会有bias,举个栗子:如果将情色相关作为关键词进行过滤,那么很多医疗相关网页也会被过滤掉
- 通过机器学习方法过滤出高质量语料库:比如将wikipedia链接到的网页(注意是链接到的,而不仅仅是wikipedia网页)作为正样本,随机采样作为负样本训练模型,将模型打分高于一定阈值的网页保留。不过这种机器学习算法也可能引入额外的bais,也要尽量少的采用。因此在情色内容过滤这块,作者仅使用URL进行过滤
- 去重(Deduplication):去除重复的段落和文档。去重有两种方案一种是绝对匹配(exact match)去重,就是完全一致的才叫重复,直接字符串匹配就好。一种是近似匹配(Approximate matches,也叫fuzzy duplicates)去重,就是将文档进行嵌入,通过哈希的方法进行去重,比如局部敏感哈希MinHash、SimHash等方法去重
-
语言识别 Language identification
- 使用fastText 语言分类器 CCNet对文档进行分类,这个模型是一个训练好的n-gram模型,根据wikipedia训练的,支持176种语言。可以按照所需比如仅将英文页面拿出来。作者进行了这一步后52%的非英文网页被过滤掉了
-
过滤 filtering
- 重复移除(Repetition removal):将文档中有太长的行,段落,或者n-gram repetitions的文章移除,这些很可能是机器生成的。
- 文档级别过滤(Document-wise filtering):如果文档的长度过长,或者某些单词在文档中的占比过高,那么这些文章也有可能是机器或者模板生成。
- 行级别过滤(Line-wise filtering):比如一些社交媒体正文中有点赞数量,导航跳转按钮之类的在正文里面的需要过滤的东西。并且如果一个文档中5%的行都被过滤了之后,那么整个文档也不要了。
3)非Web数据
- 对话数据
- OpenSubtitles: 电视和电影的英文字幕。
- Ubuntu IRC⭐️: Ubuntu IRC 数据集是从 Freenode IRC 聊天服务器上所有 Ubuntu 相关频道的公开聊天记录中派生出来的。聊天记录数据6提供了一个建模实时人类交互的机会,这种交互具有其他社交媒体模式通常不具备的自发性。
- 音视频模态转化文本数据
- The pile中有部分YouTube字幕数据,尚未发现大规模开放数据
数据清洗步骤
- 在文本提取之前,会评估每个数据源的质量,并忽略文本密度低于70%的网页。
- 由于网页文本转载现象普遍存在,使用simhash算法删除重复内容。
- 少量文字的网页通常意味着它们不包含有意义的句子。这些网页不适合用于训练语言模型。如果一个网页包含少于10个汉字,会忽略它。
- 脏话、煽动性评论和其他非法内容等敏感信息会对建设和谐、积极的社会环境产生不利影响。排除包含上述内容的网页。
- 为了最大程度地保护每个人的隐私安全,使用正则表达式匹配私人信息(如身份证号码、电话号码、QQ号码、电子邮件地址等),并从数据集中删除它们。
- 不完整的句子在模型训练中可能会出现问题。使用标点符号(如句号、感叹号、问号、省略号)来分隔提取出的文本,并删除最后一段,有时最后一段可能是不完整的。
- 由于某些网页违反了W3C标准,从这些网页提取的文本可能会乱码。为了排除语料库中的乱码内容,我们过滤掉高频乱码词汇的网页,并使用解码测试进行二次检查。
- 由于简体和繁体中都有汉字,将这些繁体汉字转换为简体汉字,以使的语料库中字符格式统一。
- 为了保证提取的文本流畅,从网页中删除那些异常符号(如表情符号、标志等)。
- 为了避免的数据集中存在过长的非中文内容,我们排除那些包含超过十个连续非中文字符的网页。
- 由于网页标识符(如HTML、层叠样式表(CSS)和Javascript)对语言模型训练没有帮助,从提取的文本中删除它们。
- 由于用空格分隔两个汉字是不必要的,删除每个句子中的所有空格,以规范化的语料库。
文本大模型训练的上界在哪?
- 目前的问题并不是数据不够了,还是训练速度太慢了
比如 CommonCrawl 有88个快照,每个快照大概能清洗出来200B的中英文高质量语料,则我们可以清洗出大约18TB tokens的高质量数据,如果加上专有数据则可以突破24TB tokens,这几乎是现有最大开源模型LLaMA-65B训练数据1.2TB tokens的20倍。
根据Scaling law,24TB高质量数据可以充分训练1300B的模型,并且所需训练量是目前训练LLaMA-65B的400倍。LLaMA-65B大概是在2000张80G显存N卡上训练了21天,大概耗费400万刀
如何突破文本训练的Scaling law(模型性能与模型规模、训练数据量和计算量之间的关系)
2. 训练数据集
1 SFT(有监督微调)的数据集格式
-
方式:对于大语言模型的训练中,SFT(Supervised Fine-Tuning)的数据集格式可以采用以下方式:
- 输入数据:输入数据是一个文本序列,通常是一个句子或者一个段落。每个样本可以是一字符串或者是一个tokenized的文本序列。
- 标签数据:标签数据是与输入数据对应的标签或类别。标签可以是单个类别,也可以是多个类别的集合。对于多分类任务,通常使用one-hot编码或整数编码来表示标签。
- 数据集划分:数据集通常需要划分为训练集、验证集和测试集。训练集用于模型的训练,验证集用于调整模型的超参数和监控模型的性能,测试集用于评估模型的最终性能。
- 数据集格式:数据集可以以文本文件(如CSV、JSON等)或数据库的形式存储。每个样本包含输入数据和对应的标签。可以使用表格形式存储数据,每一列代表一个特征或标签。
-
举例
Input,Label "This is a sentence.",1 "Another sentence.",0- 输入数据是一个句子**,标签是一个二分类的标签(1代表正例,0代表负例)**。每一行代表一个样本,第一列是输入数据,第二列是对应的标签
2 RM(奖励模型)的数据格式
- 在大语言模型训练中,RM(Reward Model,奖励模型)的数据格式可以采用以下方式:
- 输入数据:输入数据是一个文本序列,通常是一个句子或者一个段落。每个样本可以是一个字符串或者是一个tokenized的文本序列。
- 奖励数据:奖励数据是与输入数据对应的奖励或评分。奖励可以是一个实数值,表示对输入数据的评价。也可以是一个离散的标签,表示对输入数据的分类。奖励数据可以是人工标注的,也可以是通过其他方式(如人工评估、强化学习等)得到的。
- 数据集格式:数据集可以以文本文件(如CSV、JSON等)或数据库的形式存储。每个样本包含输入数据和对应的奖励数据。可以使用表格形式存储数据,每一列代表一个特征或标签。
Input,Reward "This is a sentence.",0.8 "Another sentence.",0.2- 输入数据是一个句子,奖励数据是一个实数值,表示对输入数据的评价。每一行代表一个样本,第一列是输入数据,第二列是对应的奖励数据。
3 PPO(强化学习)的数据格式
- 输入数据:输入数据是一个文本序列,通常是一个句子或者一个段落。每个样本可以是一个字符串或者是一个tokenized的文本序列。
- 奖励数据:奖励数据是与输入数据对应的奖励或评分。奖励可以是一个实数值,表示对输入数据的评价。也可以是一个离散的标签,表示对输入数据的分类。奖励数据可以是人工标注的,也可以是通过其他方式(如人工评估、模型评估等)得到的。
- 动作数据:动作数据是模型在给定输入数据下的输出动作。对于语言模型,动作通常是生成的文本序列。动作数据可以是一个字符串或者是一个tokenized的文本序列。
- 状态数据:状态数据是模型在给定输入数据和动作数据下的状态信息。对于语言模型,状态数据可以是模型的隐藏状态或其他中间表示。状态数据的具体形式可以根据具体任务和模型结构进行定义。
- 数据集格式:数据集可以以文本文件(如CSV、JSON等)或数据库的形式存储。每个样本包含输入数据、奖励数据、动作数据和状态数据。可以使用表格形式存储数据,每一列代表一个特征或标签。
nput,Reward,Action,State
"This is a sentence.",0.8,"This is a generated sentence.",[0.1, 0.2, 0.3, ...]
"Another sentence.",0.2,"Another generated sentence.",[0.4, 0.5, 0.6, ...]
输入数据是一个句子,奖励数据是一个实数值,动作数据是生成的句子,状态数据是模型的隐藏状态。每一行代表一个样本,第一列是输入数据,第二列是对应的奖励数据,第三列是生成的动作数据,第四列是状态数据
3. 预训练阶段-自监督学习、掩码语言模型(MLM)、因果语言模型(CLM)、优化算法-todo
| 项目 | Value |
|---|---|
| 自监督学习 | 模型通过从输入数据本身生成的伪标签来进行训练。常见的自监督学习任务包括掩码语言模型(Masked Language Model, MLM)和因果语言模型(Causal Language Model, CLM)。 |
| 掩码语言模型(MLM),将输入文本中的一部分词汇进行随机掩码,然后要求模型预测这些被掩码的词汇。这种方式有助于模型学习词汇与上下文之间的关系。 | |
| 因果语言模型(CLM):模型被训练来预测给定前文的下一个词。这种方式有助于模型学习文本的顺序结构和语言的生成过程。 | |
| 优化算法 | 在预训练过程中,使用优化算法(如Adam、SGD等)来更新模型的参数,以最小化损失函数(如交叉熵损失)。损失函数衡量了模型预测结果与真实目标之间的差异。 |
3. 监督微调阶段-任务特定数据、有监督学习-todo
| 项目 | Value |
|---|---|
| 任务特定数据 | 在预训练完成后,使用特定任务的标签数据对模型进行微调。这些标签数据通常包括人类生成的高质量对话、问答对等 |
| 有监督学习 | 在微调阶段,模型通过有监督学习的方式学习如何根据输入生成更准确、更相关的回复。监督学习涉及使用损失函数来衡量模型预测结果与真实标签之间的差异,并通过反向传播算法更新模型参数 |
4. 强化学习阶段-人类反馈、奖励模型、策略优化、todo
| 项目 | Value |
|---|---|
| 人类反馈 | 在强化学习阶段,模型通过人类反馈进行微调。这通常涉及收集人类评估者对模型生成的回复的评分或排序,并使用这些反馈来训练奖励模型(Reward Model)。 |
| 奖励模型 | 奖励模型用于计算模型生成回复的奖励分数。这个分数反映了回复与人类期望的匹配程度。 |
| 策略优化 | 使用强化学习算法(如PPO、DPO等)来优化模型的策略,使其能够生成更高奖励分数的回复。强化学习算法通过不断迭代更新模型参数,以最大化累积奖励。 |
5. 模型评估与部署-模型评估(准去率召回率等)、模型部署(压缩优化降低消耗)
| 项目 | Value |
|---|---|
| 模型评估 | 在训练过程中,定期对模型进行评估以监控其性能和收敛情况。评估通常涉及在验证集和测试集上进行测试,并计算相关指标(如准确率、召回率、F1分数等) |
| 模型部署 | 经过充分训练和评估后,将模型部署到实际应用场景中。部署前需要进行模型压缩和优化以提高推理速度和降低资源消耗 |
举例:二分类相关评估指标(召回率、准确率,精确率,f1,auc和roc)
- 样本集拆分:所谓正样本(positive samples)、负样本(negative samples),对于某一环境下的人脸识别应用来说,比如教室中学生的人脸识别,则教室的墙壁,窗户,身体,衣服等等便属于负样本的范畴
- 20x20 大小的人脸检测,拍摄一张 1000x1000 像素大小的车的图像,将其拆分为 20x20 大小的片段
训练集负样本继续抽样: 保留全部正样本,负样本随机抽取一定比例加入训练集数据平衡: cascade learning 以及重采样的方法 ==> 实现数据平衡
- Positive表示对样本作出的是正的判断,T表示判断正确,F表示判断错误(Negtive类似)。比如TP表示样本为正,我们模型也判断为正,FP模型判断为正,但判断错误,样本为负
1. TP:True Positive
2. FP:False Positive
3. TN:True Negtive
4. FN:False Negtive
Accuracy = (TP+TN)/(TP+FP+TN+FN)
准确率,表示在所有样本中分对(即正样本被分为正,负样本被分为负)的样本数占总样本数的比例。Precision = TP / (TP+ FP)
精确率,表示模型预测为正样本的样本中真正为正的比例。Recall = TP /(TP + FN)
召回率,表示模型准确预测为正样本的数量占所有正样本数量的比例。F1 = 2*P*R /(P+ R)
F1,是一个综合指标,是Precision和Recall的调和平均数,因为在一般情况下,Precision和Recall是两个互补关系的指标,鱼和熊掌不可兼得,顾通过F测度来综合进行评估。F1越大,分类器效果越好。Accaracy和Precision作用相差不大,都是值越大,分类器效果越好,但是有前提,前提就是样本是均衡的。如果样本严重失衡了,Accuracy不再适用,只能使用Precision
ROC,AUC- ROC,AUC优点:当数据中的正负样本分布发生变化时,ROC能够保持不变,尤其在样本不均衡的应用场景中
- TPR = TP / (TP+FN)真正率,指在所有正样本中,被准确识别为正样本的比例,公式与召回率一样。
- FPR = FP / (TN + FP)假正率,指在所有负样本中,被错误识别为正样本的比例。又叫误报率,错误接收率
- 以TPR为y轴,FPR为x轴,通过不断改变threshold的值,获取到一系列点(FPR,TPR),将这些点用平滑曲线连接起来即得到ROC曲线,
- Threshold定义为正负样本分类面的阈值,通常的二分类模型中取0.5,
- 通常取测试集上各样本的概率预测分值,即predict_prob,将所有样本的概率预测分值从高到低排序,并将这些分值依次作为threshold,然后计算对应的点(FPR,TPR),比如最大的样本预测分值为0.9时,当threshold取0.9时,所有样本分值大于等于0.9的才预测为正样本,小于0.9的预测为负样本。最后加上两个threshold值1和0,分别可对应到(0,0),(1,1)两个点,将这些点连接起来即得到ROC曲线,点越多,曲线越平滑,而ROC曲线下的面积即为AUC
- ROC特点
- (1)一个好的分类器应该ROC曲线应该尽量位于左上位置,当ROC为(0,0)和(1,1)两个点的直线时,分类器效果跟随机猜测效果一样;
- (2)ROC曲线下方的面积作为AUC,可以用AUC作为衡量分类器好坏的标准,理想的分类器AUC为1,当AUC为0.5时,效果跟随机猜测效果一致;
- (3)ROC能很好的解决正负样本分布发生变化的情况,在正负样本分布发生变化的情况下,ROC能够保持不变。
6. 参数调优-学习率、批次大小、训练轮数、正则化与过拟合
| 项目 | Value |
|---|---|
| 超参数调整 | 在训练过程中,可能需要调整多个超参数(如学习率、批次大小、训练轮数等)以获得最佳性能。超参数调整通常通过网格搜索、随机搜索或贝叶斯优化等方法进行。 |
| 正则化与过拟合 | 为了防止模型在训练过程中过拟合,可以采用正则化技术(如Dropout、L1/L2正则化等)来降低模型复杂度。同时,还可以采用早停(Early Stopping)等技术来提前终止训练过程。 |
4.3 影响大模型训练的大模型参数-模型表达能力、训练效率与性能、过拟合与泛化能力、计算资源需求、存储资源需求、可解释性与透明度
| 项目 | Value |
|---|---|
| 模型表达能力 | 参数数量的增加可以提高模型的表达能力。更多的参数意味着模型能够学习到更复杂的特征和模式,从而更准确地拟合输入数据。这对于处理高维数据(如图像、文本等)和复杂任务(如自然语言处理、图像识别等)尤为重要 |
| 训练效率与性能 | 训练时间:加速训练过程,通常需要采用高性能的硬件设备和优化算法,如GPU、TPU等加速器以及分布式训练技术 |
| 收敛速度 | |
| 过拟合与泛化能力 | 泛化能力是指模型对新数据的预测能力。大模型在训练过程中能够学习到更多的特征和规律,因此通常具有更强的泛化能力。然而,这也取决于模型的训练方式、数据质量以及参数配置等因素 |
| 计算资源需求、存储资源需求 | |
| 可解释性与透明度 | 随着参数数量的增加,深度学习模型的可解释性通常会下降。因为模型的内部工作原理变得更加复杂和难以理解,人们很难直接解释模型是如何做出决策的 |
4.4 大模型参数调优
| 项目 | Value |
|---|---|
| 参数调优的目标 | 是找到一组最优的模型参数,使得模型在验证集或测试集上的性能(如准确率、召回率、F1分数等)达到最佳 |
| 参数调优的方法 | 网格搜索(Grid Search),网格搜索是一种穷举搜索的方法,它通过定义一个超参数空间,并在该空间中进行离散的搜索;网格搜索的优点是简单易懂,容易实现,且有可能找到全局最佳超参数。然而,其缺点是计算复杂度高,搜索空间大时需要较长的时间才能完成搜索 |
| 步骤:定义超参数空间:根据模型和问题设置超参数的取值范围。创建超参数组合:将超参数空间划分成不同的子空间,并生成超参数组合。训练和评估模型:按照每个超参数组合的设定,训练模型并通过交叉验证等方法评估模型性能。选择最佳模型:根据评估结果,选择性能最佳的模型。 | |
随机搜索(Random Search),:基于随机抽样的超参数调优方法,在超参数空间中进行随机抽样来搜索最佳超参数组合,搜索空间较大时更高效地找到性能相对较好的超参数组合,也不能保证找到全局最佳超参数,通常需要进行适当次数的抽样以充分搜索超参数空间 | |
贝叶斯优化(Bayesian Optimization):基于高斯过程的优化算法,它通过建立模型对超参数进行先验估计,并通过观察来更新估计结果 | |
| 参数调优的策略 | 逐步调优:先从较宽的参数范围开始搜索,逐渐缩小范围,直到找到最优的参数组合 |
交叉验证:交叉验证将数据集分为训练集、验证集和测试集,通过多次划分和训练来评估模型在不同数据集上的表现。这有助于更准确地评估模型的泛化能力 | |
并行计算:训练过程通常非常耗时,因此可以利用并行计算技术来加速训练过程。通过并行计算,可以同时训练多个模型或同时搜索多个超参数组合,从而显著提高训练效率 | |
| 参数调优的注意事项 | 数据质量:训练数据存在噪声、异常值或不平衡等问题 |
模型选择 | |
超参数范围:范围过宽,可能会导致搜索时间过长;如果范围过窄,则可能无法找到最优解 | |
评估指标:合适的评估指标(如准确率、召回率、F1分数等) |
4.5 LLMs 训练时 有哪些有用的建议
- 于一些国产AI加速卡,目前来说,坑还比较多,如果时间不是时间非常充裕,还是尽量选择Nvidia的AI加速卡。
- 关注GPU使用效率:。要更准确地评估GPU利用率,需要关注TFLOPS和吞吐率等指标,这些监控在DeepSpeed框架中都得以整合。
- 弹性容错和自动重启机制:大模型训练不是以往那种单机训个几小时就结束的任务,往往需要训练好几周甚至好几个月,这时候你就知道能
稳定训练有多么重要。弹性容错能让你在机器故障的情况下依然继续重启训练;自动重启能让你在训练中断之后立刻重启训练。毕竟,大模型时代,节约时间就是节约钱。
05 大模型微调
1. 如何计算大模型所需参数
一般 n B的模型,最低需要 16-20 n G的显存。(cpu offload基本不开的情况下)vicuna-7B为例,官方样例配置为 4*A100 40G,测试了一下确实能占满显存。(global batch size128,max length 2048)当然训练时用了FSDP、梯度累积、梯度检查点等方式降显存。
-
模型本身需要的 RAM 大致分三个部分:模型参数、梯度、优化器参数
- 模型参数 = 参数量 * 每个参数所需内存
- 梯度=模型参数=参数量 * 每个梯度参数所需内存
- 优化器参数,对于常用的 AdamW 来说,需要储存两倍的模型参数(用来储存一阶和二阶momentum)
fp32 精度,一个参数需要 32 bits, 4 bytes;
fp16 精度,一个参数需要 16 bits, 2 bytes;
int8 精度,一个参数需要 8 bits, 1 byte。
-
CUDA kernel
- CUDA kernel 也会占据一些 RAM,大概 1.3GB 左右,查看方式如下
torch.ones((1,1)).to("cuda")print_gpu_utilization()`` ``>>> GPU memory occupied: 1343 MB
-
batch
- 首先需要计算batch中每个instance的中间变量内存。
- 等于用中间计算参数量 *每个参数所需内存 * batch size。
假设您有一个包含200个样本(数据行)的数据集,并且您选择的Batch大小为5和1,000个Epoch。
这意味着数据集将分为40个Batch,每个Batch有5个样本。每批五个样品后,模型权重将更新。这也意味着一个epoch将涉及40个Batch或40个模型更新。
有1000个Epoch,模型将暴露或传递整个数据集1,000次。在整个培训过程中,总共有40,000Batch。
-
LLaMA的架构举例:
-
模型参数
- 模型参数:对于 int8,LLaMA-6B 需要 6B *1 byte = 6GB
- 梯度:同上,6GB
- 优化器参数:int8 的 LLaMA-6B,AdamW 需要 6B* 1 bytes * 2= 12 GB
- CUDA kernel : 1.3GB
- int 8精度下 Llama-6B: 6GB+6GB+12GB+1.3GB = 25.3GB
-
batch
- hidden_size = 4096, intermediate_size =11008, num_hidden_layers = 32, context_length = 2048
- 每个实例:(4096 +11008) * 2048 *32 * 1byte = 990MB
- batch size为50
- 990MB * 50 = 48.3GB
25.3GB + 48.3GB = 73.6GB
2. 为什么SFT之后感觉LLM傻了
- SFT的重点在于激发大模型的能力,SFT的数据量一般也就是万恶之源alpaca数据集的52k量级,相比于预训练的数据还是太少了。
3. SFT 指令微调数据 如何构建
- 代表性。应该选择多个有代表性的任务;
- 数据量。每个任务实例数量不应太多(比如:数百个)否则可能会潜在地导致过拟合问题并影响模型性能;
- 不同任务数据量占比。应该平衡不同任务的比例,并且限制整个数据集的容量(通常几千或几万),防止较大的数据集压倒整个分布。
4. 领域模型Continue PreTrain 数据选取
- 技术标准文档或领域相关数据是领域模型Continue PreTrain的关键。因为领域相关的网站和资讯重要性或者知识密度不如书籍和技术标准
5. 领域数据训练后,通用能力往往会有所下降,如何缓解模型遗忘通用能力?
- 动机:仅仅使用领域数据集进行模型训练,模型很容易出现灾难性遗忘现象.
- 解决方法:通常在领域训练的过程中加入通用数据集
- 主要与领域数据量有关系,当数据量没有那么多时,一般领域数据与通用数据的比例在1:5到1:10之间是比较合适的
6. 领域模型Continue PreTrain ,如何 让模型在预训练过程中就学习到更多的知识
领域模型Continue PreTrain时可以同步加入SFT数据,即MIP,Multi-Task InstructionPreTraining。预训练过程中,可以加下游SFT的数据,可以让模型在预训练过程中就学习到更多的知识。
7. 进行SFT操作的时候,基座模型选用Chat还是Base
仅用SFT做领域模型时,资源有限就用在Chat模型基础上训练,资源充足就在Base模型上训练。(资源=数据+显卡)
资源充足时可以更好地拟合自己的数据,如果你只拥有小于10k数据,建议你选用Chat模型作为基座进行微调;如果你拥有100k的数据,建议你在Base模型上进行微调。
8. 领域模型微调 领域评测集 构建
领域评测集时必要内容,建议有两份,一份选择题形式自动评测、一份开放形式人工评测。选择题形式可以自动评测,方便模型进行初筛;开放形式人工评测比较浪费时间,可以用作精筛,并且任务形式更贴近真实场景。
9. 领域模型词表扩增是不是有必要的
领域词表扩增真实解决的问题是解码效率的问题,给模型效果带来的提升可能不会有很大
10. 如何训练自己的大模型
如果我现在做一个sota的中文GPT大模型,会分2步走:
- 基于中文文本数据在LLaMA-65B上二次预训练;
- 加CoT和instruction数据, 用FT + LoRA SFT。
- 第一阶段:扩充领域词表,比如金融领域词表,在海量领域文档数据上二次预训练LLaMA模型;
- 第二阶段:构造指令微调数据集,在第一阶段的预训练模型基础上做指令精调。还可以把指令微调数据集拼起来成文档格式放第一阶段里面增量预训练,让模型先理解下游任务信息
11. 训练中文大模型有啥经验?
扩充中文词表后,可以增量模型对中文的理解能力,效果更好
- 数据质量越高越好,而且数据集质量提升可以改善模型效果
- 数据语言分布,加了中文的效果比不加的好
- 数据规模越大且质量越高,效果越好,大量高质量的微调数据集对模型效果提升最明显。解释下:数据量在训练数据量方面,数据量的增加已被证明可以显著提高性能。值得注意的是,如此巨大的改进可能部分来自belle-3.5和我们的评估数据之间的相似分布。评估数据的类别、主题和复杂性将对评估结果产生很大影响
扩充词表后的LLaMA-7B-EXT的评估表现达到了0.762/0.824=92%的水平
12 指令微调的好处
- 对齐人类意图,能够理解自然语言对话(更有人情味)
- 经过微调(fine-tuned),定制版的GPT-3在不同应用中的提升非常明显。OpenAI表示,它可以让不同应用的准确度能直接从83%提升到95%、错误率可降低50%。解小学数学题目的正确率也能提高2-4倍。(更准)
14 预训练和微调哪个阶段注入知识的
预训练阶段注入知识的,微调是在特定任务训练,以使预训练模型的通用知识跟特定任务的要求结合,使模型在特定任务上表现更好
15 多轮对话任务如何微调模型
ChatGLM-6B 的生成对话的例子
>>> from transformers import AutoTokenizer, AutoModel
>>> tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b",
trust_remote_code=True)
>>> model = AutoModel.from_pretrained("THUDM/chatglm-6b",
trust_remote_code=True).half().cuda()
>>> model = model.eval()
>>> response, history = model.chat(tokenizer, "你好", history=[])
>>> print(f"response:{response}")
>>> print(f"history:{history}")
response:你好👋!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。
history:["你好", "你好👋!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任
何问题。"]
- response 为 ChatGLM-6B 模型的 当前反馈
- history 为 ChatGLM-6B 模型的 历史记录的保存
- 就是 ChatGLM-6B 模型简单的把上一轮对话扔进下一轮的input里,这种方法好处是简单,缺点是随着轮数的增加,history 存储的 对话会越来越多,导致 max_length 增加,从而 出现爆显问题。
解决方法:
- 对 历史对话 做一层文本摘要,取其精华去其糟粕
- 将 历史对话 做成一个 embedding
- 如果是 任务型对话,可以将 用户意图 和 槽位 作为 上一轮信息 传递给 下一轮
17 微调后的模型出现能力劣化,灾难性遗忘是怎么回事
应该是微调训练参数调整导致的,微调初始学习率不要设置太高,lr=2e-5或者更小,可以避免此问题,不要大于预训练时的学习率
18 大模型LLM进行SFT操作的时候在学习什么
- 预训练->在大量无监督数据上进行预训练,得到基础模型–>将预训练模型作为SFT和RLHF的起点。
- SFT–>在有监督的数据集上进行SFT训练,利用上下文信息等监督信号进一步优化模型–>将SFT训练后的模型作为RLHF的起点。
- RLHF–>利用人类反馈进行强化学习,优化模型以更好地适应人类意图和偏好–>将RLHF训练后的模型进行评估和验证,并进行必要的调整。
19 预训练和SFT操作有什么不同
下面使用一个具体的例子进行说明。
问题:描述计算机主板的功能
回答:计算机主板是计算机中的主要电路板。它是系统的支撑。
- 进行预训练的时候会把这句话连接起来,用前面的词来预测后面出现的词。在计算损失的时候,问句中的损失也会被计算进去。
- 进行SFT操作则会构建下面这样一条训练语料
输入:描述计算机主板的功能[BOS]计算机主板是计算机中的主要电路板。它是系统的支撑。[EOS]
标签:[......][BOS]计算机主板是计算机中的主要电路板。它是系统的支撑。[EOS]
- 其中[BOS]和[EOS]是一些特殊字符,在计算损失时,只计算答句的损失。在多轮对话中,也是一样的,所有的问句损失都会被忽略,而只计算答句的损失。
- 因此SFT的逻辑和原来的预训练过程是一致的,但是通过构造一些人工的高质量问答语料,可以高效地教会大模型问答的技巧。
20 样本量规模增大,训练出现OOM错
- 问题描述:模型训练的样本数量从10万,增大300万,训练任务直接报OOM了。
- 解决方案,对数据并行处理,具体实现参考海量数据高效训练,核心思想自定义数据集本次的
主要目标是使向量化耗时随着处理进程的增加线性下降,训练时数据的内存占用只和数据分段
大小有关,可以根据数据特点,灵活配置化。核心功能分为以下几点: - 均分完整数据集到所有进程(总的GPU卡数)
- 每个epoch训练时整体数据分片shuffle一次,在每个进程同一时间只加载单个分段大小数据集
- 重新训练时可以直接加载向量化后的数据
- 解决方案,对数据并行处理,具体实现参考海量数据高效训练,核心思想自定义数据集本次的
22. 大模型LLM进行SFT 如何对样本进行优化?
- 对于输入历史对话数据进行左截断,保留最新的对话记录。
- 去掉样本中明显的语气词,如嗯嗯,啊啊之类的。
- 去掉样本中不合适的内容,如AI直卖,就不应出现转人工的对话内容。
- 样本中扩充用户特征标签,如年龄,性别,地域,人群等
23. 微调大模型的一些建议
- 模型结构:
- 模型结构+训练目标: Causal Decoder + LM。有很好的zero-shot和few-shot能力,涌现效应
- layer normalization: 使用Pre RMS Norm
- 激活函数: 使用GeGLU或SwiGLU
- embedding层后不添加layer normalization,否则会影响LLM的性
- 位置编码: 使用ROPE或ALiBi。ROPE应用更广泛
- 去除偏置项:去除dense层和layer norm的偏置项,有助于提升稳定性
- 训练配置:
- batch: 选用很大的batch size; 动态地增加batch size的策略,GPT3逐渐从32K增加到3.2M tokens。
- 学习率调度:先warmup再衰减。学习率先线性增长,再余弦衰减到最大值的10%。最大值一般在5e-5到1e-4之间。
- 梯度裁剪:通常将梯度裁剪为1.0。
- 权重衰减: 采用AdamW优化器,权重衰减系数设置为0.1Adamw相当于Adam加了一个L2正则项
- 混合精度训练:采用bfloat16,而不是foat16来训练。
- 训练崩溃挽救:
- 选择一个好的断点,跳过训练崩溃的数据段,进行断点重训。选择一个好的断点的标准:损失标度lossscale>0;梯度的L2范数<一定值 && 波动小
24.微调大模型时,如果 batch size 设置太小 会出现什么问题
当 batch size 较小时,更新方向(即对真实梯度的近似)会具有很高的方差,导致的梯度更新主要是噪声。经过一些更新后,方差会相互抵消,总体上推动模型朝着正确的方向前进,但个别更新可能不太有用,可以一次性应用(使用更大 batch size 进行更新)。
25.微调大模型时,如果 batch size 设置太大 会出现什么问题
当 batch size 非常大时,我们从训练数据中抽样的任何两组数据都会非常相似(因为它们几乎完全匹配真实梯度)。因此,在这种情况下,增加 batch size 几乎不会改善性能,因为你无法改进真实的梯度预测。换句话说,你需要在每一步中处理更多的数据,但并不能减少整个训练过程中的步数,这表明总体训练时间几乎没有改善。但是更糟糕的是你增加了总体的 FLOPS。
26. 微调大模型时, batch size 如何设置问题

27 大模型训练loss突刺原因和解决办法
- loss spike指的是预训练过程中,尤其容易在大模型(100B以上)预训练过程中出现的loss突然暴涨的情况
- 如图所示模型训练过程中红框中突然上涨的loss尖峰 loss spike的现象会导致一系列的问题发生,譬如模型需要很长时间才能再次回到spike之前的状态(论文中称为pre-explosion),或者更严重的就是loss再也无法drop back down,即模型再也无法收敛PaLM和GLM130b之前的解决办法是找到loss spike之前最近的checkpoint,更换之后的训练样本来避免loss spike的出现。
06 推理
推理(Inference)阶段则建立在训练完成的基础上,将训练好的模型应用于新的、未见过的数据。模型利用先前学到的规律进行预测、分类或生成新内容,使得AI在实际应用中能够做出有意义的决策,例如在医疗诊断、自动驾驶和自然语言理解等领域。
6.1 LLM 的推理框架对比
| 项目 | Value |
|---|---|
| vLLM | 适用于大批量Prompt输入,并对推理速度要求高的场景; |
| Text generation inference | 依赖HuggingFace模型,并且不需要为核心模型增加多个adapter的场景; |
| CTranslate2 | 可在CPU上进行推理; |
| OpenLLM | 为核心模型添加adapter并使用HuggingFace Agents,尤其是不完全依赖PyTorch; |
| Ray Serve | 稳定的Pipeline和灵活的部署,它最适合更成熟的项目; |
| MLC LLM | 可在客户端(边缘计算)(例如,在Android或iPhone平台上)本地部署LLM; |
| DeepSpeed-MII | 使用DeepSpeed库来部署LLM; |
6.2 LLM推理常见参数:
- GreedySearch是最简单、最直接的方式,其可以保证稳定的输出,相应的
- BeamSearch可以进一步提升生成效果,但是代价更高,也是可以保证稳定的输出。
- top_p和top_k都可以用于增加模型生成结果的多样性,输出结果往往会变。
- 温度系数temperature一般用于控制随机性,temperature越大,随机性越强
temperature越小,随机性越弱。 - 重复惩罚repetition_penalty用于避免模型一直输出重复的结果,repetition_penalty越大,出现重复性可能越小,repetition_penalty越小,出现重复性可能越大。
07 强化学习
08 大模型评估
8.1 幻觉
- 幻觉有哪些不同类型?
- 内在幻觉:生成的内容与源内容相矛盾。
- 外部幻觉:生成的内容不能从源内容中得到验证,既不受源内容支持也不受其反驳。
- 为什么LLM会产生幻觉
- 源与目标的差异:当我们在存在源与目标差异的数据上训练模型时,模型产生的文本可能与原始源内容产生偏差。这种差异,有时可能是在数据收集过程中不经意间产生的,有时则是故意为之。
- 无意识的源-目标差异:这种差异的产生有多种原因。例如,数据可能是基于某种经验法则编制的,使得目标信息并不总是完全依赖源信息。举例来说,如果从两家不同的新闻网站获得相同事件的报道作为源与目标,目标报道中可能包含源报道没有的信息,从而导致二者不同。
- 有意识的源-目标差异:某些任务在本质上并不追求源与目标的严格一致,尤其是在需要多样性输出的情境下。
- 训练数据的重复性:训练过程中使用的数据,如果存在大量重复,可能导致模型在生成时过于偏好某些高频短语,这也可能引发“幻觉”。
- 数据噪声的影响:使用充斥噪声的数据进行训练,往往是导致“幻觉”出现的关键因素之一。
- 解码过程中的随机性:某些旨在增加输出多样性的解码策略,如top-k采样、top-p方法以及温度调节,有时会增加“幻觉”的产生。这往往是因为模型在选择输出词汇时引入了随机性,而没有始终选择最可能的词汇。
- 模型的参数知识偏向:有研究表明,模型在处理信息时,可能更依赖其在预训练阶段所积累的知识,而忽略了实时提供的上下文信息,从而偏离了正确的输出路径。
- 训练与实际应用中的解码差异:在常见的训练方法中,我们鼓励模型基于真实数据预测下一个词汇。但在实际应用中,模型则是根据自己先前生成的内容进行预测。这种方法上的差异,尤其在处理长文本时,可能会导致模型的输出出现“幻觉”。
- 如何度量幻觉
- 命名实体误差:命名实体(NEs)是“事实”描述的关键组成部分,我们可以利用NE匹配来计算生成文本与参考资料之间的一致性。直观上,如果一个模型生成了不在原始知识源中的NE,那它可以被视为产生了幻觉(或者说,有事实上的错误)。
- 蕴含率:该指标定义为被参考文本所蕴含的句子数量与生成输出中的总句子数量的比例。为了实现这一点,可以采用成熟的蕴含/NLI模型。
- 基于模型的评估:应对复杂的句法和语义变化。
- 利用问答系统:此方法的思路是,如果生成的文本在事实上与参考材料一致,那么对同一个问题,其答案应该与参考材料相似。具体而言,对于给定的生成文本,问题生成模型会创建一组问题-答案对。接下来,问答模型将使用原始的参考文本来回答这些问题,并计算所得答案的相似性。
- 利用信息提取系统:此方法使用信息提取模型将知识简化为关系元组,例如<主体,关系,对象>。这些模型从生成的文本中提取此类元组,并与从原始材料中提取的元组进行比较。
- 如何缓解LLM幻觉
- 利用外部知识验证正确性
- 修改解码策略
- 采样多个输出并检查其一致性
留出法、交叉验证法、自助法
- 留出法 hold-out
- 留出法直接将数据集D划分为两个互斥的部分,其中一部分作为训练集S,另一部分用作测试集T。通常训练集和测试集的比例为70%:30%。同时,训练集测试集的划分有两个注意事项:
- 尽可能保持数据分布的一致性。避免因数据划分过程引入的额外偏差而对最终结果产生影响。在分类任务中,保留类别比例的采样方法称为“分层采样”(stratified sampling)。
- 采用若干次随机划分避免单次使用留出法的不稳定性。
- 交叉验证法 cross validation
- k折交叉验证
- 交叉验证法先将数据集D划分为k个大小相似的互斥子集,每次采用k−1个子集的并集作为训练集,剩下的那个子集作为测试集。进行k次训练和测试,最终返回k个测试结果的均值。又称为“k折交叉验证”(k-fold cross validation)。
- k折交叉验证
- 留出法直接将数据集D划分为两个互斥的部分,其中一部分作为训练集S,另一部分用作测试集T。通常训练集和测试集的比例为70%:30%。同时,训练集测试集的划分有两个注意事项:
- 留一法 leave-one-out cross validation
- 留一法是k折交叉验证k=m(m为样本数)时候的特殊情况。即每次只留下一个样本做测试集,其它样本做训练集,需要训练k次,测试k次。留一法计算最繁琐,但样本利用率最高。因为计算开销较大,所以适合于小样本的情况。
- 优点:样本利用率高。
- 缺点:计算繁琐。
- 留一法是k折交叉验证k=m(m为样本数)时候的特殊情况。即每次只留下一个样本做测试集,其它样本做训练集,需要训练k次,测试k次。留一法计算最繁琐,但样本利用率最高。因为计算开销较大,所以适合于小样本的情况。
- 自助法 bootstrapping
- 自助法以自助采样为基础(有放回采样)。每次随机从D(样本数为m)中挑选一个样本,放入D′中,然后将样本放回D中,重复m次之后,得到了包含m个样本的数据集。

- 自助法以自助采样为基础(有放回采样)。每次随机从D(样本数为m)中挑选一个样本,放入D′中,然后将样本放回D中,重复m次之后,得到了包含m个样本的数据集。
8.2 评测
1. 方法-确率(accuracy)和F1得分
- 首先是“直接评估指标”这一类别。这些是在人工智能领域长期以来广泛使用的传统指标。像准确率(accuracy)和F1得分(F1 score)等指标属于这个类别。通常情况下,这种方法涉及从模型中获取单一的输出,并将其与参考值进行比较,可以通过约束条件或提取所需信息的方式来实现评估**。**
- 接下来是第二类方法,称为“间接或分解的启发式方法(indirect or decomposed heuristics)”。在这种方法中,我们利**用较小的模型(smaller models)来评估主模型(the main model)**生成的答案,这些较小的模型可以是微调过的模型或原始的分解模型(raw decompositions)。
- 第三类评估方法被称为“基于模型的评估”。在这种方法中,模型本身提供最终的评估分数或评估结果。然而,这也引入了额外的可变因素。即使模型可以获取到ground truth信息,评估指标本身也可能在评分过程中产生随机因素或不确定因素
2. 大模型评估工具有哪些
- ChatbotArena:借鉴游戏排位赛机制,让人类对模型两两评价
- SuperCLUE:中文通用大模型综合性评测基准,尝试全自动测评大模型
- C-Eval:采用 1.4 万道涵盖 52 个学科的选择题,评估模型中文能力
- FlagEval:采用“能力—任务—指标”三维评测框架
8.3 评估指标
1. 基础评估
- 用户参与度和效用指标
- 访问:访问LLM应用程序功能的用户数
- 提交提交提示词的用户数
- 响应LLM应用程序生成没有错误的响应
- 观看用户查看LLM的响应信息次数
- 点击用户点击LLM响应中的参考文档(如有参考文档的话)
- 用户交互指标
- 用户接受率:用户接受大模型响应内容的概率,例如,在对话场景中包含正面、负面或者建议的反馈)
- LLM会话数:每个用户的LLM平均会话数
- 活跃天数:每个用户使用LLM功能的活动天数
- 交互计时:编写提示词、发送再到大模型响应之间的平均时间,以及每次花费的时间
- 模型答复质量
- 提示和响应长度:提示词和响应内容的平均长度
- 编辑距离度量:用户提示之间以及LLM响应和保留内容之间的平均编辑距离测量用作提示细化和内容定制的指标
- 用户反馈和用户留存
- 用户反馈:带有有“大拇指向上、向下”的反馈数’
- 每日/每周/每月活跃用户:在特定时间段内访问LLM应用程序功能的用户数
- 性能度量指标
- 每秒请求数(并发):LLM每秒处理的请求数
- 每秒处理Token数:计算LLM响应流期间每秒输出的Tokens
- 第一次输出Token的时间:从用户提交提示词到第一次流式输出令牌的时间,以多次重复测量’
- 错误率:不同类型错误的错误概率,如401错误、429错误。
- 可靠性:成功请求占总请求(包括错误或失败请求)的百分比
- 延迟时间:从提交请求到收到响应之间的平均处理持续时间
- 成本度量指标
- GPU/CPU利用率:在请求返回错误(OpenAI 返回429错误编码,表示过多请求)之前的Token总数
- LLM呼叫成本:每次调用需要花费的成本
- 基础设施成本:存储、网络、计算资源等成本
- 运维成本:包括:运行、维护、技术支持、监控、记录、安全措施等方面的成本
2. RAI指标-道德
对于LLM来说,评价其是否存在道德、偏见、伦理等潜在风险,十分重要。RAI(Responsible AI)指标主要用于评价LLM是否是一个负责任的大模型。评价可以促进基于LLM的应用具有公平性、包容性和可靠性。
- 有害内容
- 合规性:隐私和安全\
- 幻觉:非事实\冲突基于共同世界知识的幻觉
- 其他:透明度\问责制:生成内容缺乏出处(生成内容的来源和更改可能无法追踪)\服务质量(QoS)差异
3. 文档摘要能力评估指标
| 类型 | 度量 | 描述 | 参考资料 |
|---|---|---|---|
| 基于重叠的度量 | BLEU | BLEU评分是一种基于精度的衡量标准,范围从0到1。值越接近1,预测越好。 | https://huggingface.co/spaces/evaluate-metric/bleu |
| ROUGE | ROUGE(Recall-Oriented Understudy for Gisting Evaluation)是一套用于评估自然语言处理中自动摘要和机器翻译软件的度量标准和附带的软件包。 | https://huggingface.co/spaces/evaluate-metric/rouge | |
| ROUGE-N | 测量候选文本和参考文本之间的n-gram(n个单词的连续序列)的重叠。它根据n-gram重叠计算精度,召回率和F1分数。 | https://github.com/google-research/google-research/tree/master/rouge | |
| ROUGE-L | 测量候选文本和参考文本之间的最长公共子序列(LCS)。它根据LCS的长度计算精确率、召回率和F1分数。 | https://github.com/google-research/google-research/tree/master/rouge | |
| METEOR | 一种机器翻译评估的自动度量,其基于机器生成的翻译和人类生成的参考翻译之间的单字匹配的广义概念。 | https://huggingface.co/spaces/evaluate-metric/meteor | |
| 基于语义相似性的度量 | BERTScore | 利用BERT中预先训练的上下文嵌入,并通过“余弦相似度”匹配候选句子和参考句子中的单词。 | https://huggingface.co/spaces/evaluate-metric/bertscore |
| MoverScore | 基于上下文向量和距离的文本生成评估。 | https://paperswithcode.com/paper/moverscore-text-generation-evaluating-with |
4. 问答样本评估指标
QA评估指标主要用于衡量基于LLM的应用系统在解决用户问答方面的有效性。
| 类型 | 描述 | 参考资料 |
|---|---|---|
| QAEval | 基于问答的度量,用于估计摘要的内容质量。 | https://github.com/danieldeutsch/sacrerouge/blob/master/doc/metrics/qaeval.md |
| QAFactEval | 基于QA的事实一致性评价。 | https://github.com/salesforce/QAFactEval |
| QuestEval | 一种NLG指标,用于评估两个不同的输入是否包含相同的信息。它可以处理多模式和多语言输入。 | https://github.com/ThomasScialom/QuestEval |
5. 实体识别指标
| 类型 | 描述 | 参考资料 |
|---|---|---|
| 分类度量指 | 实体级别或模型级别的分类指标(精度、召回率、准确性、F1分数等)。 | https://learn.microsoft.com/en-us/azure/ai-services/language-service/custom-named-entity-recognition/concepts/evaluation-metrics |
| 解释评估指标 | 主要思想是根据实体长度、标签一致性、实体密度、文本的长度等属性将数据划分为实体的桶,然后在每个桶上分别评估模型。 | https://github.com/neulab/InterpretEvalhttps://arxiv.org/pdf/2011.06854.pdf |
6. 文本转SQL
| 类型 | 描述 |
|---|---|
| Exact-set-match accuracy (EM) | EM根据其相应的基本事实SQL查询来评估预测中的每个子句。然而,一个限制是,存在许多不同的方式来表达SQL查询,以达到相同的目的。 |
| Execution Accuracy (EX) | EX根据执行结果评估生成的答案的正确性。 |
| VES (Valid Efficiency Score) | VES是一个用于测量效率以及所提供SQL查询的通常执行正确性的度量标准。 |
7. RAG系统评价指标
RAG(Retrieval-Augmented Generation)是一种自然语言处理(NLP)模型架构,它结合了检索和生成方法的元素。通过将信息检索技术与文本生成功能相结合来增强大语言模型的性能。评估RAG检索相关信息、结合上下文、确保流畅性、避免偏见对提高满足用户满意度至关重要。有助于识别系统问题,指导改进检索和生成模块
| 类型 | 描述 |
|---|---|
| Faithfulness | 事实一致性:根据给定的上下文测量生成的答案与事实的一致性。 |
| Answer relevance | 答案相关性:重点评估生成的答案与给定提示的相关性。 |
| Context precision | 上下文精确度:评估上下文中存在的所有与实况相关的项目是否排名更高。 |
| Context relevancy | 语境关联:测量检索到的上下文的相关性,根据问题和上下文计算。 |
| Context Recall | 上下文召回率:测量检索到的上下文与样本答案(被视为基本事实)的一致程度。 |
| Answer semantic similarity | 答案语义相似度:评估生成的答案和基础事实之间的语义相似性。 |
| Answer correctness | 答案正确性:衡量生成的答案与地面实况相比的准确性。 |
8.3 评估基准
通用大模型具有多功能性,如:聊天、实体识别(NER)、内容生成、文本摘要、情感分析、翻译、SQL生成、数据分析等。下面收集了一些对这些大模型的评估基准。
| 类型 | 描述 | 参考资料 |
|---|---|---|
| GLUE基准 | GLUE(General Language Understanding Evaluation)提供了一组标准化的各种NLP任务,以评估不同大语言模型的有效性。 | https://gluebenchmark.com/ |
| SuperGLUE基准 | 提供比起GLUE更具挑战性、多样化,更全面的任务。 | https://super.gluebenchmark.com/ |
| HellaSwag | 评估LLM完成句子的能力。 | https://rowanzellers.com/hellaswag/ |
| TruthfulQA | 评测模型的回答是否真实性。 | https://github.com/sylinrl/TruthfulQA |
| MMLU | 评估LLM可以处理大规模多任务的能力。 | https://github.com/hendrycks/test |
| ARC | AI2数据集分为两个分区:“简单”和“挑战”,其中后一个分区包含需要推理的更困难的问题。大多数问题有4个答案选择,1%的问题有3个或5个答案选择。 | https://paperswithcode.com/dataset/arc |
8.4 QAEval - 精确度\召回率F1分数
- 生成问题:从参考文本中自动生成问题,这些问题通常围绕文本中的关键信息点构建。
- 生成答案:使用问答系统来回答这些问题,生成答案。
- 评估答案:将生成的答案与人类生成的参考答案进行比较。这一步通常涉及多个子指标,如:
精确度:评估系统答案中正确信息的比例。
召回率:评估系统答案覆盖参考答案中信息的程度。
F1分数:精确度和召回率的调和平均,提供一个单一的性能度量。 - 计算指标:使用特定的算法来计算上述指标。这可能包括文本相似度度量(如BLEU, ROUGE等),也可能包括更复杂的语义相似度评估方法。
二分
对于二分类问题,每一条数据要么预测正确,表示为1;要么预测错误,表示为0(注意这里是预测结果正确与否,而不是预测结果是0还是1),而事物本身也是被分为0(负样本)和1(正样本)两类。
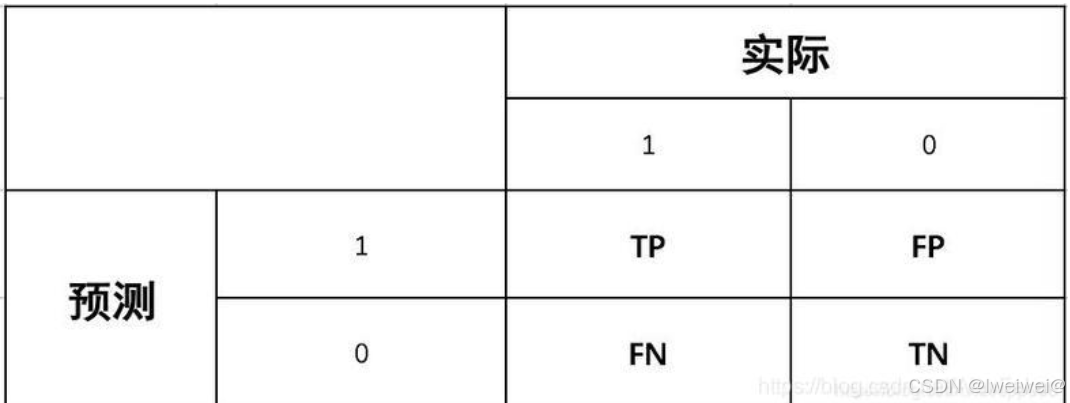
1. 精确度 (Precision)
- 精确度是指系统生成答案中正确信息的比例。
- True Positives (TP): 系统答案中正确的信息点数
- False Positives (FP): 系统答案中错误的信息点数
- Precision= TP/TP+FP
2. 召回率 (Recall)
- 召回率是指系统答案覆盖参考答案中信息的程度
- True Positives (TP): 系统答案中正确的信息点数
- False Negatives (FN): 参考答案中的信息点未被系统答案覆盖
- Recall= TP/TP+FN
3. F1分数
F1分数是精确度和召回率的调和平均,提供一个单一的性能度量
F1 Score=2× Precision×Recall /(Precision+Recall)
4. ROC_AUC
-
ROC
- ROC(receiver operating characteristic curve:接受者操作特征曲线)是一条曲线。该曲线涉及两个指标:真正率(TPR)和假正率(FPR)
- 真正率就是召回率,假正率(1-特异度)=FP/(FP+TN)
- 们以FPR为x轴,TPR为y轴画图,就得到了ROC曲线
- 针对一个模型,我们希望的是假正率(X值,自变量)一定的时候真正率(Y值,因变量)越高越好,也就是曲线“越上凸”就越好
- OC曲线的xy值都是正负样本的准确率(错误率),因此,**无论我们给的样例中正负样本的个数孰多孰少,都不会影响ROC的形状,我们可以称ROC曲线“无视样本的不平衡”,**这是ROC曲线比前几种指标更加准确合理的根本原因
-
AUC(曲线下面积)
- ROC曲线越上凸模型就越好,那有没有什么度量指标能够量化这种好呢?答案就是用曲线下方的面积,也就是曲线在0到1上的积分
- 果我们连接对角线,它的面积正好是 0.5。对角线的实际含义是:随机判断响应与不响应,正负样本覆盖率应该都是 50%,表示随机效果。 ROC 曲线越陡越好,所以理想值就是 1,一个正方形,而最差的随机判断都有 0.5,所以一般 AUC 的值是介于 0.5 到 1 之间的
8.4 评测步骤
计算 QAFactEval 的步骤
- 准备数据:
问题集:选择或创建一个包含多个问题的数据集。
参考答案:为每个问题准备一个或多个准确的参考答案,这些答案应包含正确的事实信息。
- 生成答案:
使用待评估的问答系统回答问题集中的每个问题,记录系统的答案。
- 事实提取:
从系统答案和参考答案中提取关键事实。这通常需要自然语言处理工具,如命名实体识别(NER)或关键短语提取。
- 事实匹配:
比较系统答案中的事实与参考答案中的事实。这包括检查事实的存在性(是否被提及)和准确性(是否正确无误)。
- 计算指标:
精确度 (Precision):系统答案中正确事实的比例。
召回率 (Recall):参考答案中的事实被系统答案正确覆盖的比例。
F1分数 (F1 Score):精确度和召回率的调和平均值。
09 应用
9.1 Lanfchain
l链接:langchain
9.2 国内大模型对比
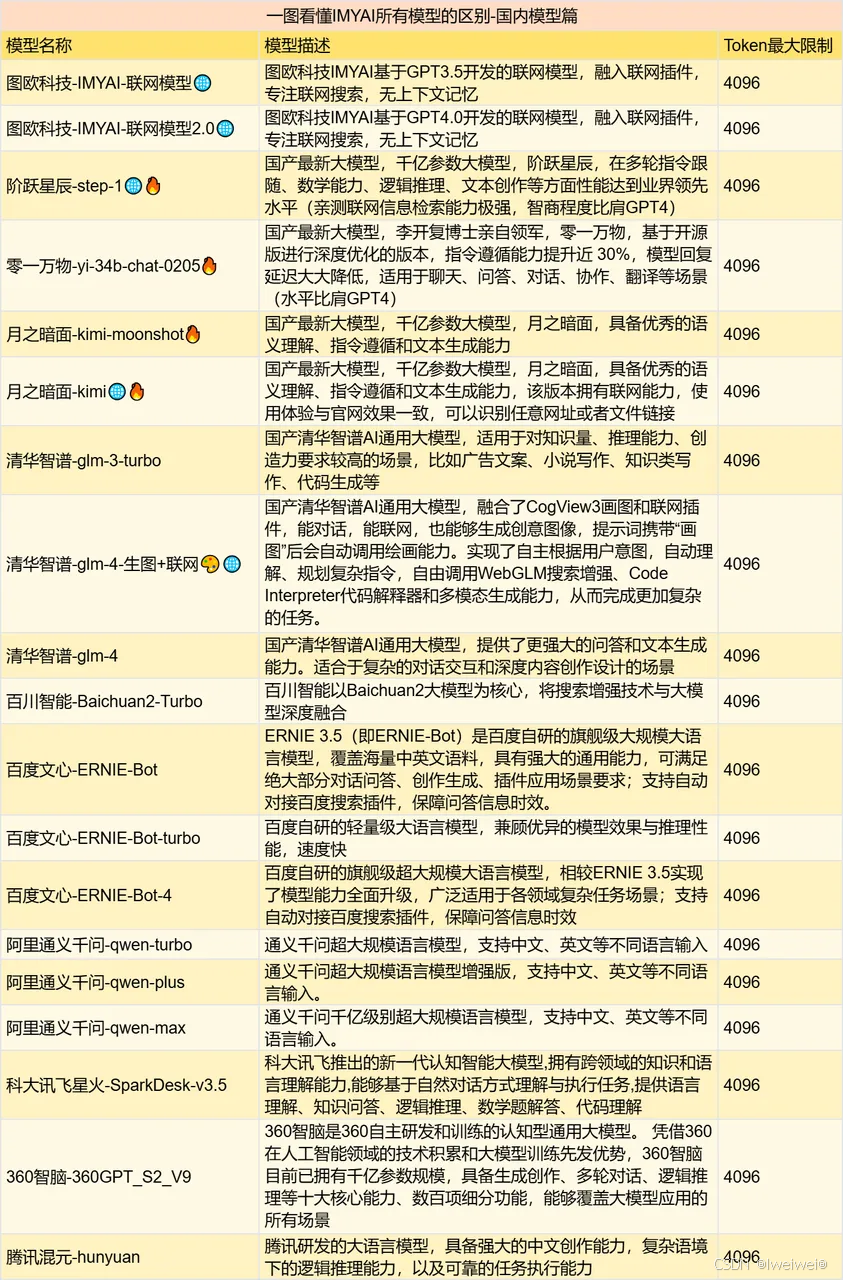
9.3 国外大模型对比
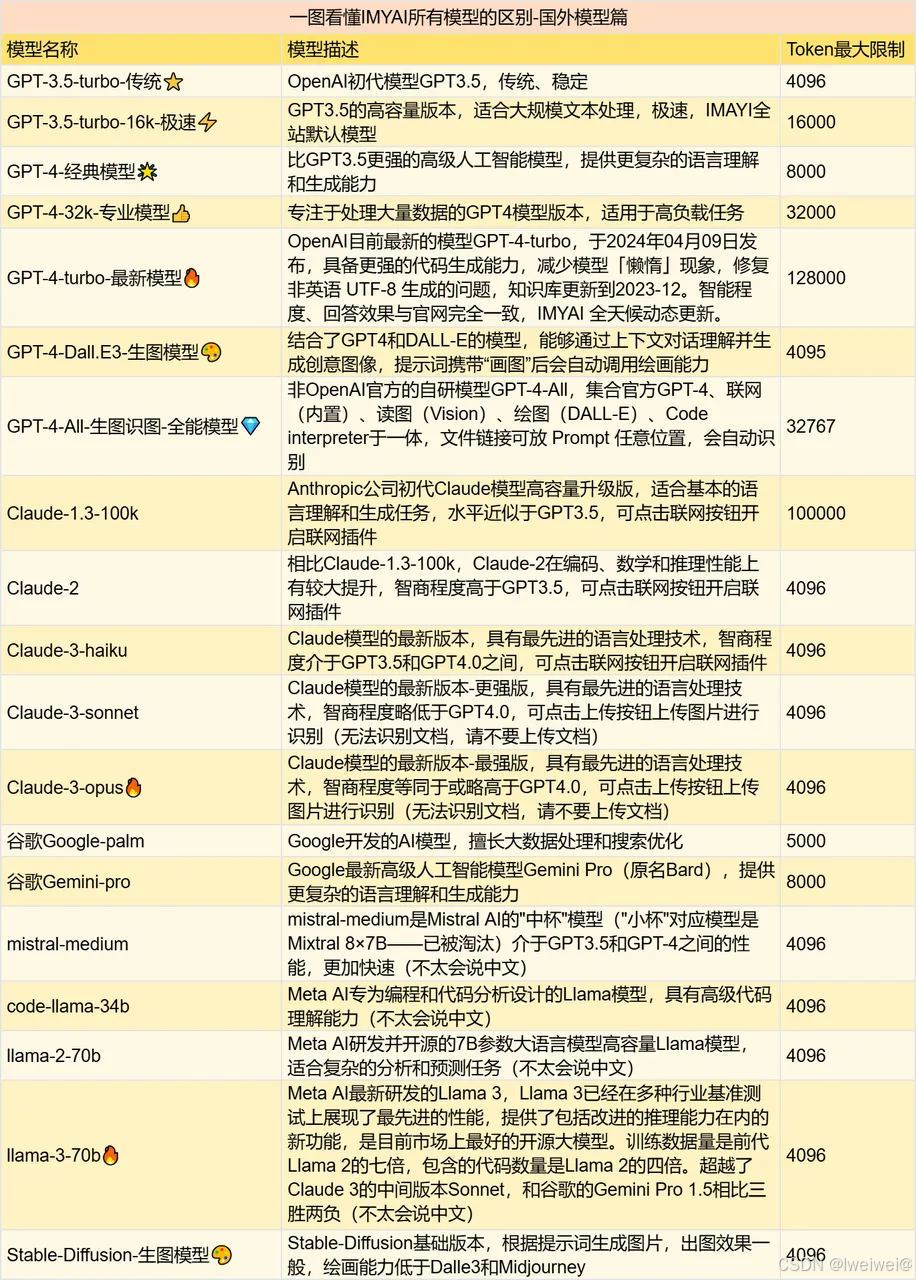
9.4 图转文字-OCR技术
- OCR技术的基本原理是利用计算机视觉和机器学习算法对图像中的文字进行识别。
- 首先,OCR系统会对图像进行预处理,包括去噪、二值化、倾斜校正等操作,以提高文字识别的准确性。然后,OCR系统会通过特征提取和分类器训练等技术,将图像中的文字转换为计算机可读的格式,如文本文件或数据库记录
- 然而,预训练OCR大模型的实现也面临一些挑战。首先,大规模无标签数据的获取和处理是一个难题。其次,预训练OCR大模型的训练需要消耗大量的计算资源和时间,成本较高。此外,由于预训练OCR大模型的参数数量庞大,如何对其进行有效的调优和微调也是一个挑战。
图像处理方法
- 2.1 图像预处理
由于纸张的厚薄、光洁度和印刷质量都会造成文字畸变,产生断笔、粘连和污点等干扰,所以在进行文字识别之前,要对带有噪声的文字图像进行处理。预处理一般包括灰度化、二值化,倾斜检测与校正,行、字切分,图像平滑,规范化等等。 - 2.1.1 灰度化
通过外设采集的图像通常为彩色图像,彩色图像会夹杂一些干扰信息,灰度化处理的主要目的就是滤除这些信息,灰度化的实质其实就是将原本由三维描述的像素点,映射为一维描述的像素点。转换的方式、工具和规则有很多,在这里不详细介绍。 - 2.1.2 二值化
经过灰度处理的彩色图像还需经过二值化处理将文字与背景进一步分离开,所谓二值化,就是将灰度值(或者彩色值)图像信号转化成只有黑(l)和白(0)的二值图像信号。二值化效果的好坏,会直接影响灰度文本图像的识别率。二值化方法大致可以分为局部阈值二值化和整体阈值二值化。 - 2.1.3 倾斜检测与校正
- 印刷体文本资料大多是由平行于页面边缘的水平(或者垂直)的文本行(或者列)组成的,即倾斜角度为零度。然而在文本页面扫描过程中,不论是手工扫描还是机器扫描,都不可避免地会出现图像倾斜现象。而倾斜的文档图像对后期的字符分割、识别和图像压缩等工作将产生很大影响。为了保证后续处理的正确性,对文本图像进行倾斜检测和校正是十分必要的。
- 文本图像的倾斜校正分为手动校正和自动校正两种。
手动校正,是指识别系统提供某种人机交互手段,实现文本图像的倾斜校正。
自动校正,是指由计算机自动分析文本图像的版面特征,估计图像的倾斜角度,并根据倾斜角度对文本图像进行校正。 - 目前,文本图像的倾斜检测方法有许多种,主要可以划分为以下五类:基于投影图的方法,基于Houhg变换的方法,基于交叉相关性的方法,基于Fourier变换的方法和基于最近邻聚类方法。
- 最简单的基于投影图的方法是将文本图像沿不同方向进行投影。当投影方向和文字行方向一致时,文字行在投影图上的峰值最大,并且投影图存在明显的峰谷,此时的投影方向就是倾斜角度。
基于Houhg变换的方法也是一种最常用的倾斜检测方法,它是利用Hough变换的特性,将图像中的前景像素映射到极坐标空间,通过统计极坐标空间各点的累加值得到文档图像的倾斜角度。
基于Fourier变换的方法是利用页面倾角对应于使Fourier空间密度最大的方向角的特性,将文档图像的所有像素点进行Fourier变换。这种方法的计算量非常大,目前很少采用。
基于最近邻聚类方法,取文本图像的某个子区域中字符连通域的中心点作为特征点,利用基线上的点的连续性,计算出对应的文本行的方向角,从而得到整个页面的倾斜角。
- 2.1.4 图像平滑
- 文本图像经过平滑处理之后,能够去掉笔划上的孤立白点和笔划外部的孤立黑点,以及笔划边缘的凹凸点,使得笔划边缘变得平滑。一种简单的平滑处理方法如下。采用NxN窗口(N一般为3,如图2-1所示是一个3X3窗口),依次在二值文字点阵中进行扫描,根据窗口中黑白像素的分布情况,使处于窗口中心的被平滑像素X。,从“0”变成“1”或者从“l”变成“0”。
该方法是按以下规则对文字轮廓边缘进行平滑的。
规则1如果满足图2-2中(a),(b),©,(d)四种情况中的任何一种,则中心点应该由“0”变成“l”。
规则2如果满足图2-2中(e),(f),(g),(h)四种情况中的任何一种,则中心点应该由“1”变成
- 文本图像经过平滑处理之后,能够去掉笔划上的孤立白点和笔划外部的孤立黑点,以及笔划边缘的凹凸点,使得笔划边缘变得平滑。一种简单的平滑处理方法如下。采用NxN窗口(N一般为3,如图2-1所示是一个3X3窗口),依次在二值文字点阵中进行扫描,根据窗口中黑白像素的分布情况,使处于窗口中心的被平滑像素X。,从“0”变成“1”或者从“l”变成“0”。
9.5 OpenAI发布的文本生成视频大模型Sora的原理解密
文本提示生成内容
空间时间补丁
视频生成过程
步骤1:视频压缩网络
步骤2:空间时间潜在补丁提取
步骤3:视频生成的Transformer模型
Sora模型生成视频的原理
首先,Sora利用一种称为“视频压缩网络”的技术,将输入的图像或视频数据转换成一个更简洁的、低维度的表达方式。这个过程类似于将不同尺寸和分辨率的图片进行“标准化”,以便于进行后续的处理和存储。这种转换并不是要摒弃原始数据的特点,而是将其转换成一种对Sora来说更易于理解和操作的形态。
然后,Sora将这些压缩过的数据进一步细分为所谓的“空间时间补丁”(Spacetime Patches),这些补丁可以被视作视觉内容的基本单元,就像我们之前提到的相册中的每一张照片都可以被拆分成包含独特景观、颜色和纹理的小块。这样,无论原始视频的长度、分辨率或风格如何,Sora都能将它们转化为一种一致的格式。
通过这种方式,Sora能够在保持原始视觉信息多样性的同时,将来自不同来源和风格的视觉数据整合成一种统一的内部表达形式。这就像你在翻阅世界名胜相册时,尽管照片各不相同,但你依然能够以相同的方式去理解和欣赏它们。
文本提示生成内容
Sora是如何根据文本提示生成内容的。这个过程主要依赖于一种称为“文本条件化的Diffusion模型”的技术。为了解释这个技术的运作原理,我们可以用一个日常生活的例子来说明:设想你手中有一本充满随意涂鸦的草图本,起初,本子上满是随机的墨迹,看起来毫无意义。但如果你按照一个特定的主题,比如“花园”,逐渐地去修改和细化这些墨迹,最终,这些杂乱的线条将逐渐演变成一幅描绘花园的美丽画面。在这个例子中,你的“特定主题”就是文本提示,而你逐步改善草图本的过程,就类似于Diffusion模型的工作机制。
具体到Sora的应用,这个过程始于一段与目标视频长度相同但内容完全是随机噪声的视频,可以将其想象成草图本上的那些无意义的墨迹。然后,Sora根据给定的文本提示(例如“一只猫坐在窗台上看日落”)开始“编辑”这段视频。在这个过程中,Sora利用了从大量视频和图片数据中学习到的知识,以决定如何逐步消除噪声,将这段噪声视频转变为接近文本描述的内容。
这个“编辑”过程是通过数百个连续的步骤逐渐完成,每一步都使得视频更接近最终的目标。这种方法的一个显著优势在于其灵活性和创新性:即使是相同的文本提示,通过不同的初始噪声状态或者在转换步骤中进行微调,也能够产生视觉上各具特色、但都与文本提示相契合的视频内容。这就像是多位艺术家根据同一主题创作出风格迥异的画作。
利用这种基于文本条件的Diffusion模型,Sora不仅能够创造出具有极高创意性的视频和图像,还能够确保所生成的内容与用户的文本提示高度吻合。无论是重现真实场景还是构建幻想世界,Sora都能够根据文本提示“绘制”出令人惊叹的视觉作品。
空间时间补丁
空间时间补丁:我们可以理解为将视频或图片分解成许多小块或“补丁”,每个小块都携带着一定的时间和空间信息。这种方法的灵感来自于处理静态图片的技术,其中图片被分割成小块以便更高效地进行分析。在视频处理的背景下,这个概念被扩展到了时间维度上,不仅涉及空间(即图片的特定区域),还包括这些区域随时间的变化。
整体步骤
步骤1:视频压缩网络
想象一下,你正在整理一间混乱的房间,你的目标是以最少的盒子来收拾所有的物品,并且保证以后能够迅速找到需要的物品。在这个过程中,你可能会把小物品放入小盒子,然后再把这些小盒子放入更大的箱子。这样,你就能够用更少、更有条理的空间来存放同样数量的物品。视频压缩网络的工作原理与此类似。它将视频内容“整理”成一个更加紧凑、高效的形式(即降低维度)。这样,Sora在处理视频时能够更加高效,也能够保留足够的信息来重建原始视频。
步骤2:空间时间潜在补丁提取
继续上面的比喻,如果你想详细记录每个盒子里放置了哪些物品,你可能会为每个盒子制作一个清单。这样,当你需要找到某个特定的物品时,只需要查阅相应的清单,就能迅速知道它存放在哪个盒子里。在Sora的处理过程中,与之类似的“清单”就是空间时间潜在补丁。通过视频压缩网络的处理,Sora将视频分割成许多小块,每个小块都包含了视频中的一小部分空间和时间信息,这就像是视频内容的详细“清单”。这样的处理使得Sora能够在后续的步骤中精确地处理视频的每一个部分。
步骤3:视频生成的Transformer模型
最后,想象你和朋友们一起玩一个特殊的拼图游戏,这个游戏的规则就是根据一个故事来拼出一幅完整的画面。你们首先将故事分成了几个部分,每个人负责一部分。接着,你们根据自己负责的那部分故事内容选择或者绘制出相应的拼图碎片。最后,你们将各自的拼图碎片拼接在一起,形成了一幅完整的图像,展现了整个故事的内容。在Sora生成视频的过程中,Transformer模型就扮演了这样的角色。它接收空间时间潜在补丁(即视频内容的“拼图片”)和文本提示(即“故事”),然后决定如何调整或组合这些拼图碎片以创造出最终的视频,从而呈现出文本提示中的故事情节。
Sora模型技术特点与创新点
Sora支持多种视频格式
Sora模型对多种视频格式的强大兼容性。比如说,不管是宽屏的1920x1080p视频、垂直的1080x1920视频,还是其他任何比例的视频,Sora都能够轻松处理。这种兼容性使得Sora能够直接为不同设备生成相应比例的内容,满足各种不同的观看需求。此外,Sora还能够先在低分辨率下快速制作内容原型,然后再以全分辨率生成最终产品,这一切都可以在同一个模型内完成。这样的特性不仅增强了内容创作的灵活性,而且极大地简化了视频内容的制作过程。
语言理解与视频生成
Sora对文本的深入理解是其一项显著特性。借助先进的文本转化为词向量的技术,能够精确解读用户的文本指令,并基于这些指令创造出充满细节和情感的角色以及栩栩如生的场景。这种功能使得从简短的文本提示到复杂视频内容的转变更加顺畅和自然,无论是复杂的动作序列还是微妙情感的表现,Sora都能够精准把握并呈现出来。
多模态输入处理
Sora还能够接收静态图像或现有视频作为输入,进行内容的扩展、填充缺失的帧或进行风格转换等任务。这种多功能性极大地拓宽了Sora的应用领域,它不仅能够用于从头开始创作视频内容,还能够用于对现有内容的二次加工,为用户提供了更多的创作灵活性和想象空间。
--------------项目--------------
01 RAG
1. 背景
传统的信息检索工具,比如 Google/Bing 这样的搜索引擎,只有检索能力 ( Retrieval-only ),现在 LLM 通过预训练过程,将海量数据和知识嵌入到其巨大的模型参数中,具有记忆能力 ( Memory-only )。从这个角度看,检索增强 LLM 处于中间,将 LLM 和传统的信息检索相结合,通过一些信息检索技术将相关信息加载到 LLM 的工作内存 ( Working Memory ) 中,即 LLM 的上下文窗口 ( Context Window ),亦即 LLM 单次生成时能接受的最大文本输入
2. 检索增强 LLM 解决的问题
提升 LLM 对长尾知识的学习能力
- 虽然当前 LLM 的训练数据量已经非常庞大,动辄几百 GB 级别的数据量,万亿级别的标记数量 ( Token ),比如 GPT-3 的预训练数据使用了3000 亿量级的标记,LLaMA 使用了 1.4 万亿量级的标记。训练数据的来源也十分丰富,比如维基百科、书籍、论坛、代码等,LLM 的模型参数量也十分巨大,从几十亿、百亿到千亿量级,但让 LLM 在有限的参数中记住所有知识或者信息是不现实的,训练数据的涵盖范围也是有限的,总会有一些长尾知识在训练数据中不能覆盖到。
- 为了提升 LLM 对长尾知识的学习能力,容易想到的是在训练数据加入更多的相关长尾知识,或者- 增大模型的参数量,虽然这两种方法确实都有一定的效果,上面提到的论文中也有实验数据支撑,但这两种方法是不经济的,即需要一个很大的训练数据量级和模型参数才能大幅度提升 LLM 对长尾知识的回复准确性。而通过检索的方法把相关信息在 LLM 推断时作为上下文 ( Context ) 给出,既能达到一个比较好的回复准确性,也是一种比较经济的方式。
私有数据、数据新鲜度
ChatGPT 这类通用的 LLM 预训练阶段利用的大部分都是公开的数据,不包含私有数据,因此对于一些私有领域知识是欠缺的。比如问 ChatGPT 某个企业内部相关的知识,ChatGPT 大概率是不知道或者胡编乱造。虽然可以在预训练阶段加入私有数据或者利用私有数据进行微调,但训练和迭代成本很高。此外,有研究和实践表明,通过一些特定的攻击手法,可以让 LLM 泄漏训练数据,如果训练数据中包含一些私有信息,就很可能会发生隐私信息泄露。比如这篇论文 Extracting Training Data from Large Language Models 的研究者们就通过构造的 Query 从 GPT-2 模型中提取出了个人公开的姓名、邮箱、电话号码和地址信息等,即使这些信息可能只在训练数据中出现一次。文章还发现,较大规模的模型比较小规模的更容易受到攻击。
3. 关键模块
- 数据和索引模块:如何处理外部数据和构建索引
- 查询和检索模块:如何准确高效地检索出相关信息
- 响应生成模块:如何利用检索出的相关信息来增强 LLM 的输出
1. 数据和索引模块:如何处理外部数据和构建索引
1)数据获取
2)文本分块
- 为什么要进行文本分块?
- 一方面当前 LLM 的上下文长度是有限制的,直接把一篇长文全部作为相关信息放到 LLM 的上下文窗口中,可能会超过长度限制
- 另一方面,对于长文本来说,即使其和查询的问题相关,但一般不会通篇都是完全相关的,而分块能一定程度上剔除不相关的内容,为后续的回复生成过滤一些不必要的噪声
- 设计一个好的分块策略?
- 原始内容的特点:原始内容是长文 ( 博客文章、书籍等 ) 还是短文 ( 推文、即时消息等 ),是什么格式 ( HTML、Markdown、Code 还是 LaTeX 等 ),不同的内容特点可能会适用不同的分块策略;
- 后续使用的索引方法:目前最常用的索引是对分块后的内容进行向量索引,那么不同的向量嵌入模型可能有其适用的分块大小,比如 sentence-transformer 模型比较适合对句子级别的内容进行嵌入,OpenAI 的 text-embedding-ada-002 模型比较适合的分块大小在 256~512 个标记数量;
- 问题的长度:问题的长度需要考虑,因为需要基于问题去检索出相关的文本片段;
- 检索出的相关内容在回复生成阶段的使用方法:如果是直接把检索出的相关内容作为 Prompt 的一部分提供给 LLM,那么 LLM 的输入长度限制在设计分块大小时就需要考虑。
- 分块实现方法
- 流程:
- 将原始的长文本切分成小的语义单元,这里的语义单元通常是句子级别或者段落级别;
- 将这些小的语义单元融合成更大的块,直到达到设定的块大小 ( Chunk Size ),就将该块作为独立的文本片段;
- 迭代构建下一个文本片段,一般相邻的文本片段之间会设置重叠,以保持语义的连贯性。
- 方法
- 最常用的是基于分割符进行切分,比如句号 ( . )、换行符 ( \n )、空格等。
- 除了可以利用单个分割符进行简单切分,还可以定义一组分割符进行迭代切分,比如定义 [“\n\n”, “\n”, " ", “”] 这样一组分隔符,切分的时候先利用第一个分割符进行切分 ( 实现类似按段落切分的效果 ),第一次切分完成后,对于超过预设大小的块,继续使用后面的分割符进行切分,依此类推。这种切分方法能比较好地保持原始文本的层次结构
- 流程:
- 文本块大小的设定也是分块策略需要考虑的重要因素
- 文本块大小的计算方法,最常用的可以直接基于字符数进行统计 ( Character-level ),也可以基于标记数进行统计 ( Token-level )。至于如何确定合适的分块大小,这个因场景而异,很难有一个统一的标准,可以通过评估不同分块大小的效果来进行选择。
3)数据索引的设计-链式、树、关键词表、向量索引
下面介绍几种常见的索引结构。为了说明不同的索引结构,引入节点(Node)的概念。在这里,节点就是前面步骤中对文档切分后生成的文本块(Chunk)。索引结构图来自 LlamaIndex 的文档How Each Index Works。
- 链式索引
- 链式索引通过链表的结构对文本块进行顺序索引。在后续的检索和生成阶段,可以简单地顺序遍历所有节点,也可以基于关键词进行过滤
- 树索引
- 树索引将一组节点 ( 文本块 ) 构建成具有层级的树状索引结构,其从叶节点 (原始文本块) 向上构建,每个父节点都是子节点的摘要。在检索阶段,既可以从根节点向下进行遍历,也可以直接利用根节点的信息。树索引提供了一种更高效地查询长文本块的方式,它还可以用于从文本的不同部分提取信息。与链式索引不同,树索引无需按顺序查询
- 关键词表索引
- 关键词表索引从每个节点中提取关键词,构建了每个关键词到相应节点的多对多映射,意味着每个关键词可能指向多个节点,每个节点也可能包含多个关键词。在检索阶段,可以基于用户查询中的关键词对节点进行筛选。
- 向量索引
- 向量索引是当前最流行的一种索引方法。这种方法一般利用文本嵌入模型 ( Text Embedding Model ) 将文本块映射成一个固定长度的向量,然后存储在向量数据库中。检索的时候,对用户查询文本采用同样的文本嵌入模型映射成向量,然后基于向量相似度计算获取最相似的一个或者多个节点
补充:向量索引-文本嵌入模型、相似向量检索和向量数据库
文本嵌入模型-Word2Vec
- 文本嵌入模型 ( Text Embedding Model ) 将非结构化的文本转换成结构化的向量 ( Vector ),目前常用的是学习得到的稠密向量。
- 当前有很多文本嵌入模型可供选择,比如
- 早期的 Word2Vec、GloVe 模型等,目前很少用。
- 基于孪生 BERT 网络预训练得到的 Sentence Transformers 模型,对句子的嵌入效果比较好
- OpenAI 提供的 text-embedding-ada-002 模型,嵌入效果表现不错,且可以处理最大 8191 标记长度的文本
- Instructor 模型,这是一个经过指令微调的文本嵌入模型,可以根据任务(例如分类、检索、聚类、文本评估等)和领域(例如科学、金融等),提供任务指令而生成相对定制化的文本嵌入向量,无需进行任何微调
- BGE模型: 由智源研究院开源的中英文语义向量模型,目前在MTEB中英文榜单都排在第一位。
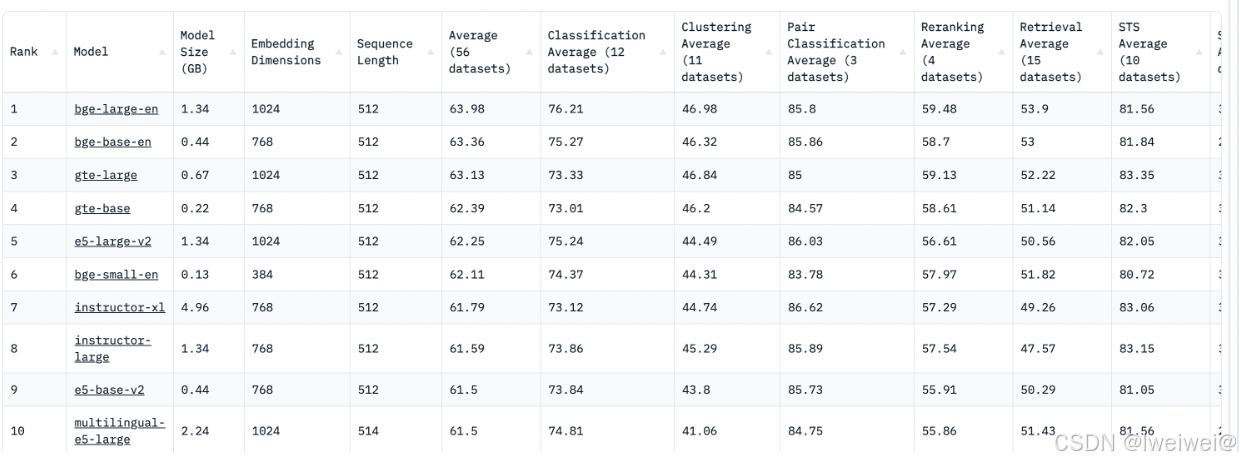
相似向量检索-*余弦相似度
- 定义:相似向量检索要解决的问题是给定一个查询向量,如何从候选向量中准确且高效地检索出与其相似的一个或多个向量。
- 首先是相似性度量方法的选择,可以采用余弦相似度、点积、欧式距离、汉明距离等,通常情况下可以直接使用余弦相似度。
- 其次是相似性检索算法和实现方法的选择,候选向量的数量量级、检索速度和准确性的要求、内存的限制等都是需要考虑的因素
- 当候选向量的数量比较少时,比如只有几万个向量,那么
Numpy 库就可以实现相似向量检索,实现简单,准确性高,速度也很快。国外有个博主做了个简单的基准测试发现 Do you actually need a vector database ,当候选向量数量在 10 万量级以下时,通过对比 Numpy 和另一种高效的近似最近邻检索实现库 Hnswlib ,发现在检索效率上并没有数量级的差异,但 Numpy 的实现过程更简单 - 对于
大规模向量的相似性检索,使用 Numpy 库就不合适,需要使用更高效的实现方案。Facebook团队开源的Faiss就是一个很好的选择。Faiss 是一个用于高效相似性搜索和向量聚类的库,它实现了在任意大小的向量集合中进行搜索的很多算法,除了可以在CPU上运行,有些算法也支持GPU加速。Faiss 包含多种相似性检索算法,具体使用哪种算法需要综合考虑数据量、检索频率、准确性和检索速度等因素
- 当候选向量的数量比较少时,比如只有几万个向量,那么
向量数据库
上面提到的基于 Numpy 和 Faiss 实现的向量相似检索方案,如果应用到实际产品中,可能还缺少一些功能,比如:
- 数据托管和备份
- 数据管理,比如数据的插入、删除和更新
- 向量对应的原始数据和元数据的存储
- 可扩展性,包括垂直和水平扩展性
所以向量数据库应运而生。简单来说,向量数据库是一种专门用于存储、管理和查询向量数据的数据库,可以实现向量数据的相似检索、聚类等。目前比较流行的向量数据库有 Pinecone、Vespa、Weaviate、Milvus、Chroma 、Tencent Cloud VectorDB等,大部分都提供开源产品。

- 索引: 使用乘积量化 ( Product Quantization ) 、局部敏感哈希 ( LSH )、HNSW 等算法对向量进行索引,这一步将向量映射到一个数据结构,以实现更快的搜索。
- 查询: 将查询向量和索引向量进行比较,以找到最近邻的相似向量。
- 后处理: 有些情况下,向量数据库检索出最近邻向量后,对其进行后处理后再返回最终结果。
2. 查询和检索模块:如何准确高效地检索出相关信息
1. 查询变换
- <font color=blue>同义改写</font>
- <font color=blue>查询分解</font>:将复杂问题分解成相对简单的子问题,回复表现会更好。这里又可以分成单步分解和多步分解
- 单步分解将一个复杂查询转化为多个简单的子查询,融合每个子查询的答案作为原始复杂查询的回复
- 多步分解,给定初始的复杂查询,会一步一步地转换成多个子查询,结合前一步的回复结果生成下一步的查询问题,直到问不出更多问题为止。最后结合每一步的回复生成最终的结果
- <font color=blue>变换三: HyDE</font>
- 全称叫 Hypothetical Document Embeddings,给定初始查询,首先利用 LLM 生成一个假设的文档或者回复,然后以这个假设的文档或者回复作为新的查询进行检索,而不是直接使用初始查询。这种转换在没有上下文的情况下可能会生成一个误导性的假设文档或者回复,从而可能得到一个和原始查询不相关的错误回复
- 排序和后处理
- 基于相似度分数进行过滤和排序
- 基于关键词进行过滤,比如限定包含或者不包含某些关键词
- 让 LLM 基于返回的相关文档及其相关性得分来重新排序
- 基于时间进行过滤和排序,比如只筛选最新的相关文档
- 基于时间对相似度进行加权,然后进行排序和筛选
2. 召回策略
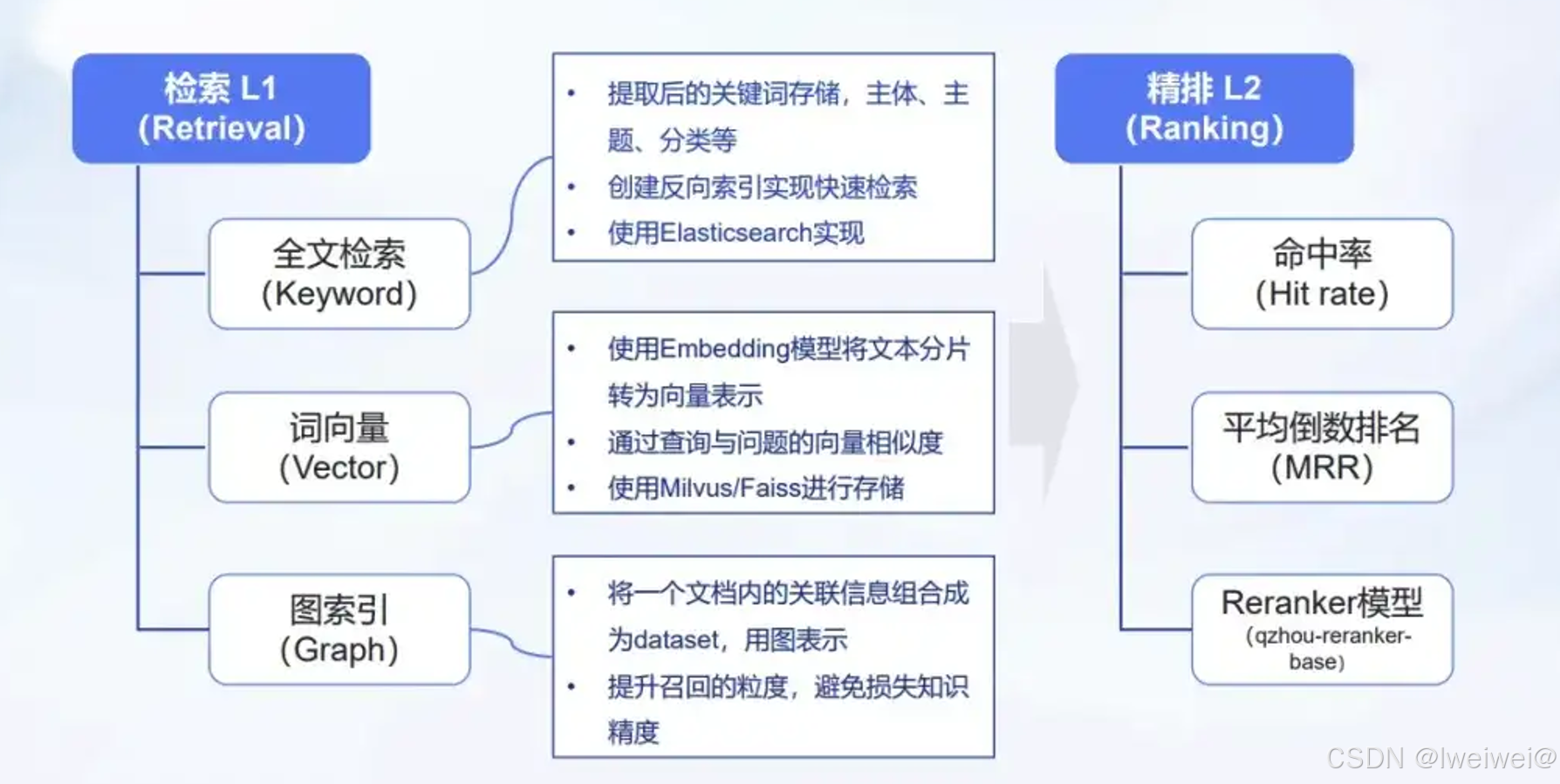
3. 检索的重要第二步:训练embedding模型
Embedding 技术是通过算法将文本转换成数字向量,然后通过转换后的数字向量之间的距离来判断文本之间的相似程度进而通过这样的方式来搜索找到相关的文本内容
技术挑战embedding
- 问题:
- Embedding 微调:通用 Embedding 模型不足以应对用户口语化严重的问题,需要针对具体业务场景进行微调,以过滤无关信息并提高准确度。
- 常见微调方案
- Query vs Original:简单高效,数据结构是直接使用用户 query 召回知识库片段;
- Query vs Query:便于维护,即使用用户的 query 召回 query,冷启动的时候可以利用模型自动化从对应的知识片段中抽取 query;
- Query vs Summary:使用 query 召回知识片段的摘要,构建摘要和知识片段之间的映射关系;
- F-Answer vs Original:根据用户 query 生成 fake answer 去召回知识片段。
当构造了优质的数据后,模型微调上,我们一般会采用分阶段微调,即首先用开源通用问答数据进行微调,然后用垂域问答数据微调,最后用人工标注的高质量问答数据进行微调。
3. 响应生成模块:如何利用检索出的相关信息来增强 LLM 的输出
- 回复生成策略
- 一种策略是依次结合每个检索出的相关文本块,每次不断修正生成的回复。这样的话,有多少个独立的相关文本块,就会产生多少次的 LLM 调用。
- 另一种策略是在每次 LLM 调用时,尽可能多地在 Prompt 中填充文本块。如果一个 Prompt 中填充不下,则采用类似的操作构建多个 Prompt,多个 Prompt 的调用可以采用和前一种相同的回复修正策略。
- 回复生成 Prompt 模板
- 下面是 LlamaIndex 中提供的一个生成回复的 Prompt 模板。从这个模板中可以看到,可以用一些分隔符 ( 比如 ------ ) 来区分相关信息的文本,还可以指定 LLM 是否需要结合它自己的知识来生成回复,以及当提供的相关信息没有帮助时,要不要回复等。
template = f'''
Context information is below.
---------------------
{context_str}
---------------------
Using both the context information and also using your own knowledge, answer the question: {query_str}
If the context isn't helpful, you can/don’t answer the question on your own.
挑战-答案生成
- 数据标注难度大:业务人员虽然知道正确答案,但难以标注出满足一致性和多样性要求的模型微调数据。因此,我们需要在获取基础答案后,通过模型润色改写答案或增加 COT 的语言逻辑,以提高数据的多样性和一致性。
- 问答种类多样:业务需要模型能够正确回答、拒答不相关问题和反问以获取完整信息。这要求我们通过构造特定的数据来训练提升模型在这些方面的能力。
- 知识混淆度高:在问答场景中,召回精度有限,模型需要先从大量相关知识片段中找到有效答案,这个过程在政务等领域难度很大,需要通过增加噪声数据来强化模型的知识搜索能力。
- 答案专业度高:在公共服务的客服场景,答案往往没有绝对准确性,资深的客服人员总能给出更有帮助性的答案。用户问题通常含糊,更加考验专业人员的回答能力。因此我们需要通过 DPO 方式训练模型,使模型能够在众多答案中找到最好最优的答案。为此,我们需要分别构造数据,并针对模型做 SFT 和 DPO。
4. 应用:LlamaIndex 和 LangChain
- LlamaIndex 是一个服务于 LLM 应用的数据框架,提供外部数据源的导入、结构化、索引、查询等功能
- LlamaIndex 主要包含以下组件和特性:
- 数据连接器:能从多种数据源中导入数据,有个专门的项目 Llama Hub,可以连接多种来源的数据
- 数据索引:支持对读取的数据进行多种不同的索引,便于后期的检索
- 查询和对话引擎:既支持单轮形式的查询交互引擎,也支持多轮形式的对话交互引擎
- 应用集成:可以方便地与一些流行的应用进行集成,比如 ChatGPT、LangChain、Flask、Docker等
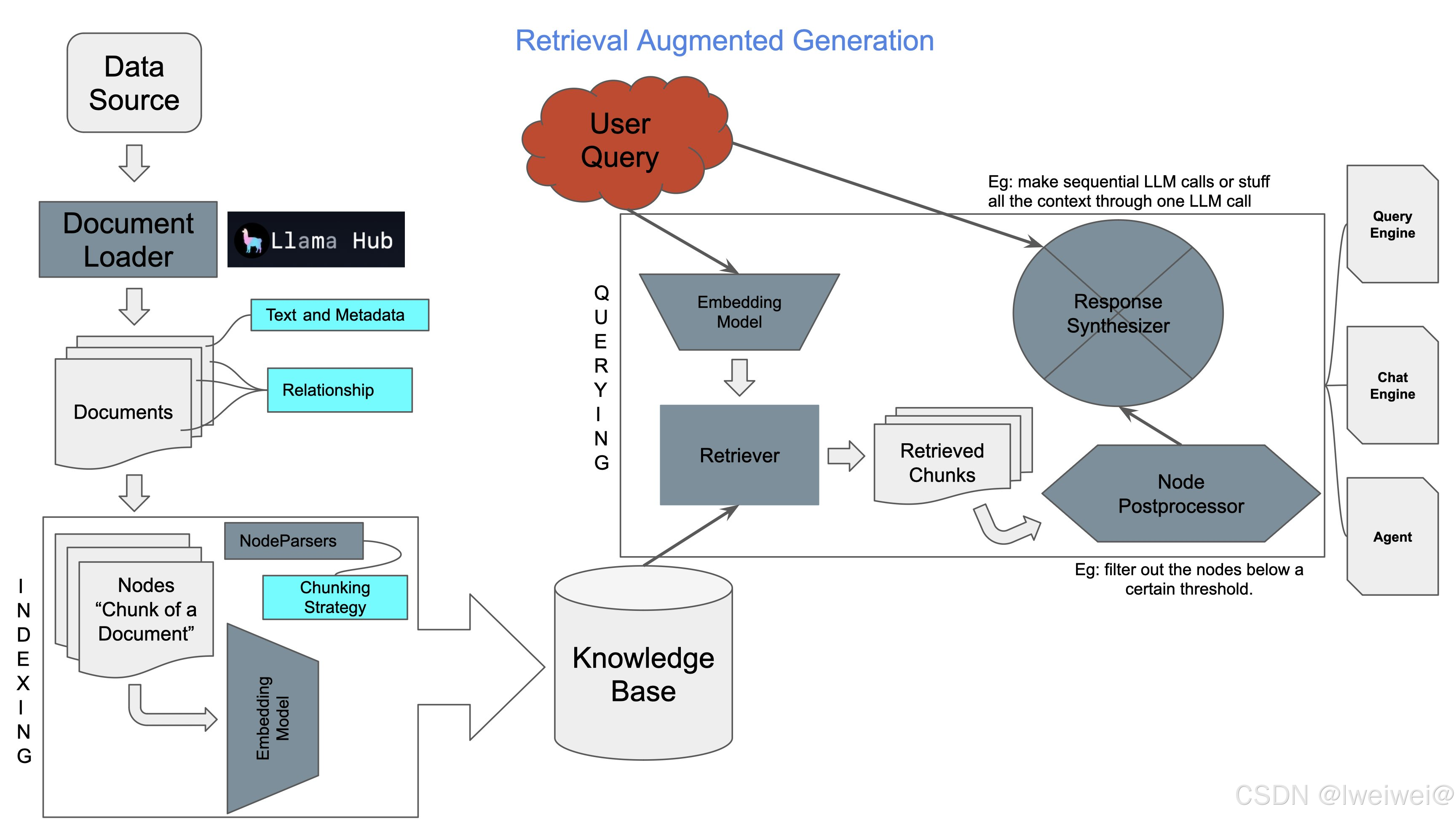
图片
RAG总体架构图
方案图
产品方案
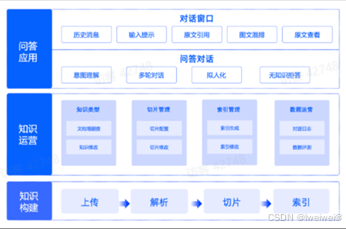
- 在知识构建过程,我们提供了包括知识类型管理、切片管理、索引管理和数据运营等知识运营和管理的工具,以此来辅助提升企业服务场景的落地效果。
- 在知识问答过程,我们提供了包括历史消息、输入提示、原文索引、图文混排、原文查看等功能,以此来加强用户对模型回复答案的信任。
- 从产品应用层面,一般有三种常见的落地类型,分别为个人使用,企业对内赋能,企业 toC 提供服务等。
5. 图和向量,如何从数据到知识
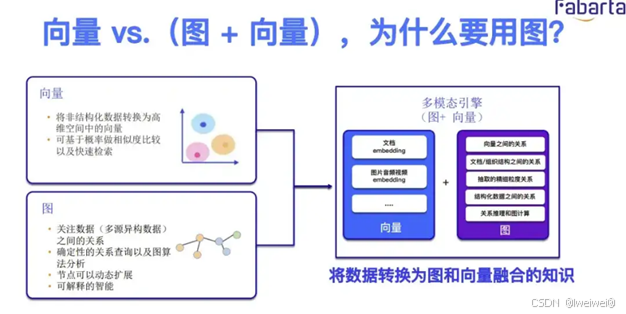
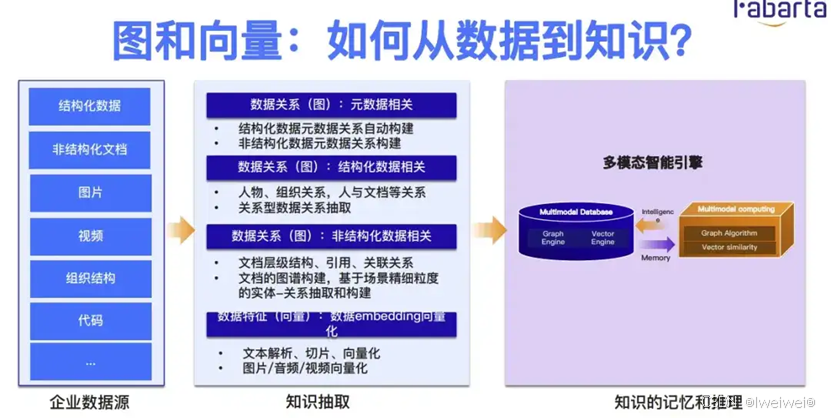
6. Agent = LLMx(规划+记忆+工具+行动)
定义
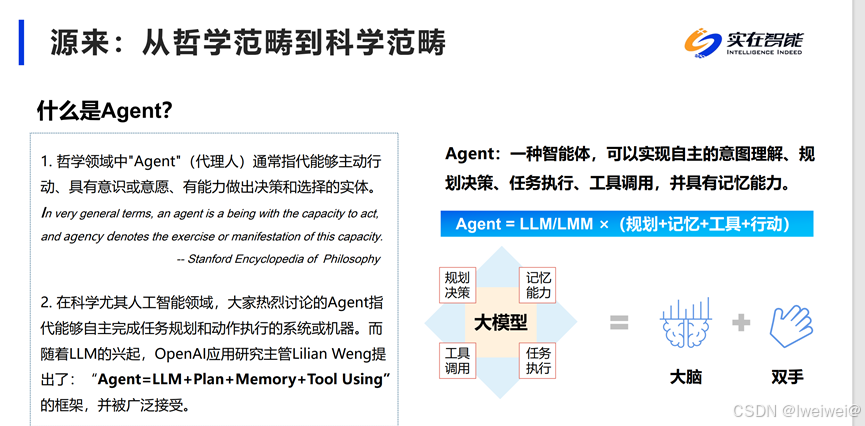
行业结构
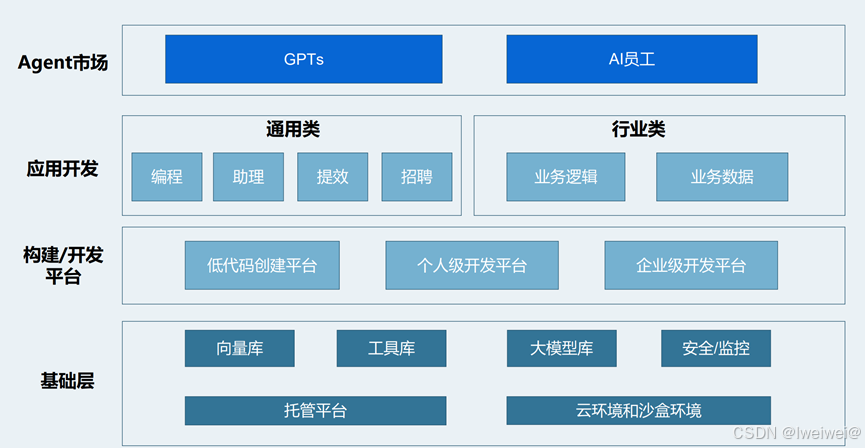
数据分析Agent
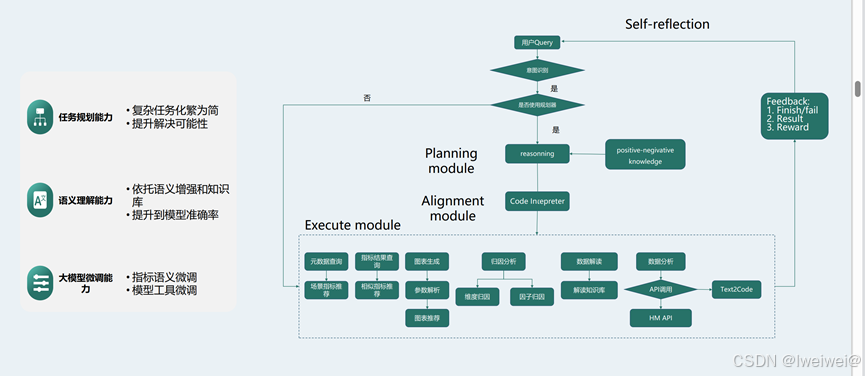
基于agent+语义加持的企业分析应用平台-挑战
幻觉:人机协作,人工干预
效率:大模型多次调用数据库、IO:状态传递机制、缓存机制
7. 未来的RAG:infiniflow=infinity+ragflow
结构
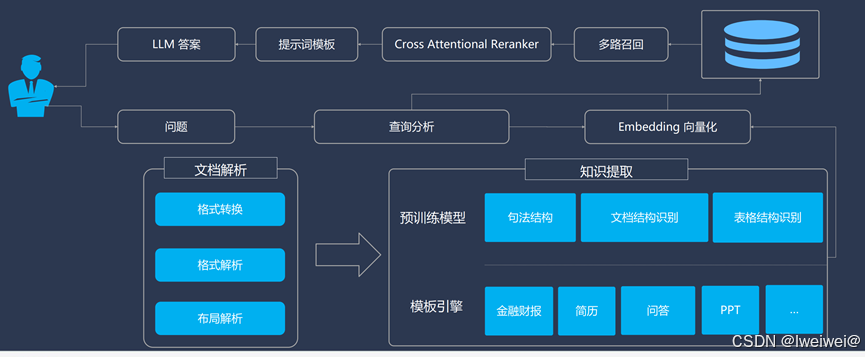
向量数据库和原生数据库的结合
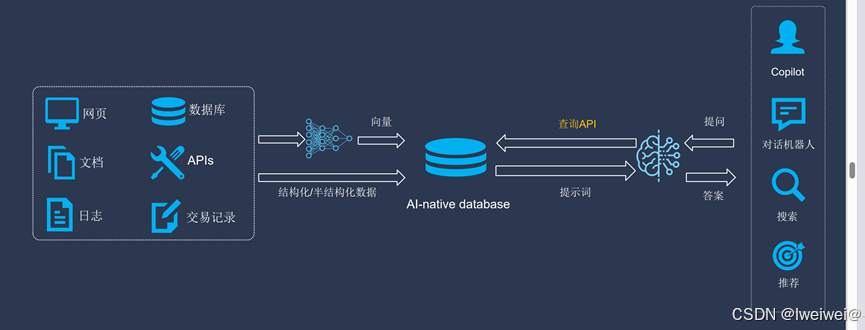
系统架构

存储架构
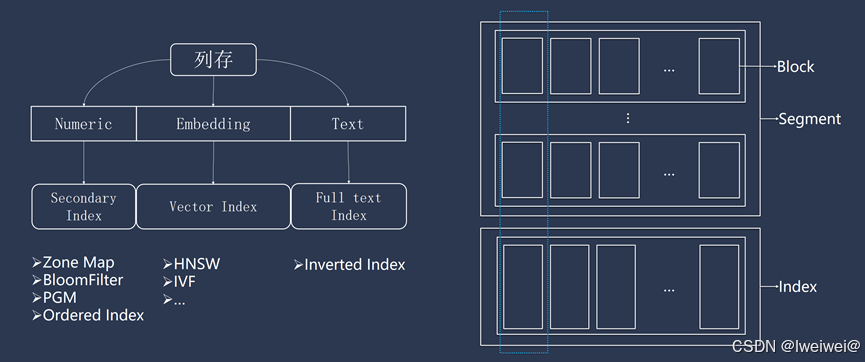
8. dingoDB技术架构-面向企业的向量数据库
特点

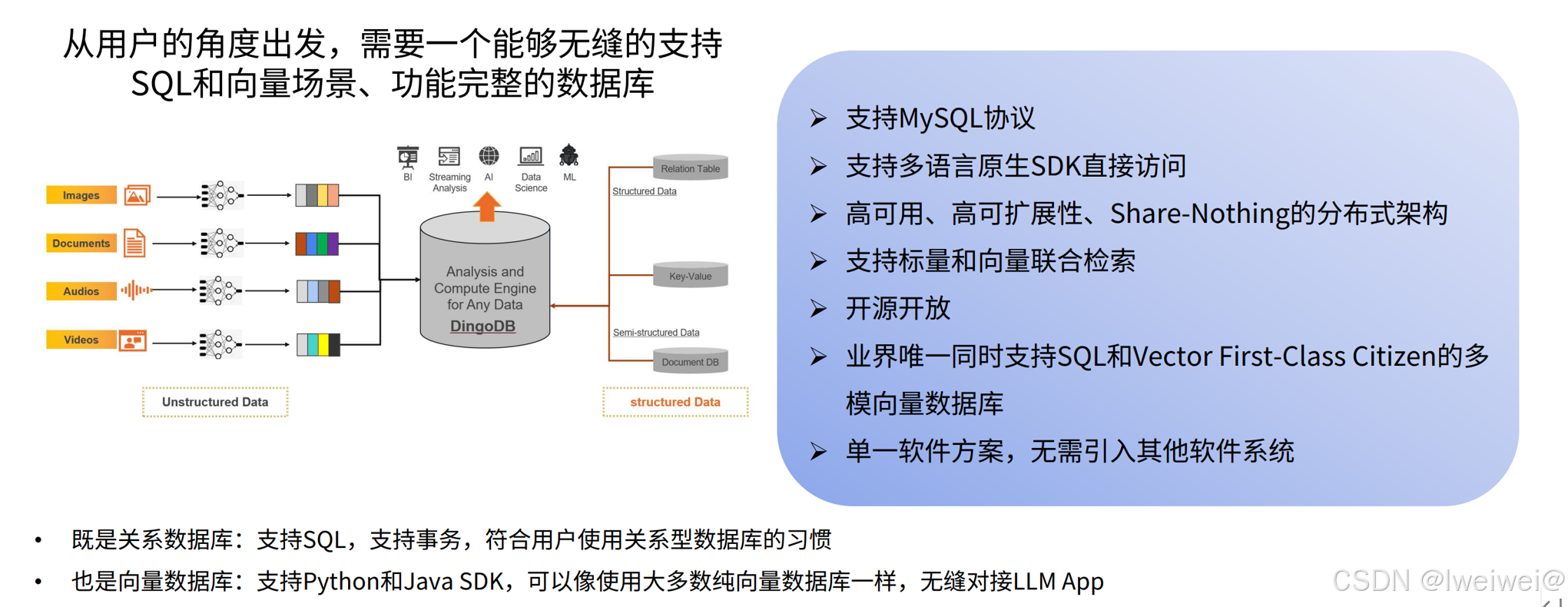
技术架构
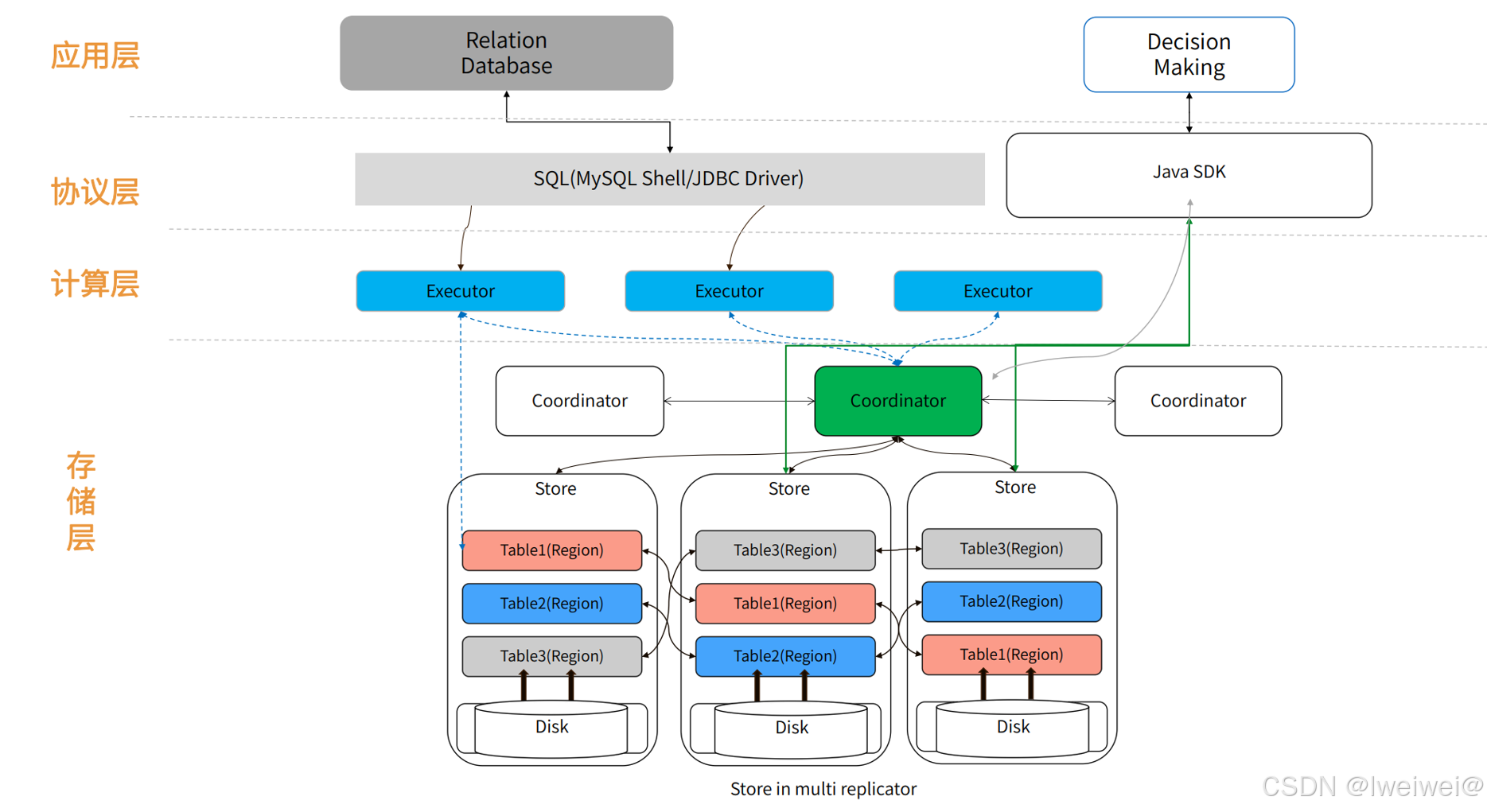
多模向量技术架构
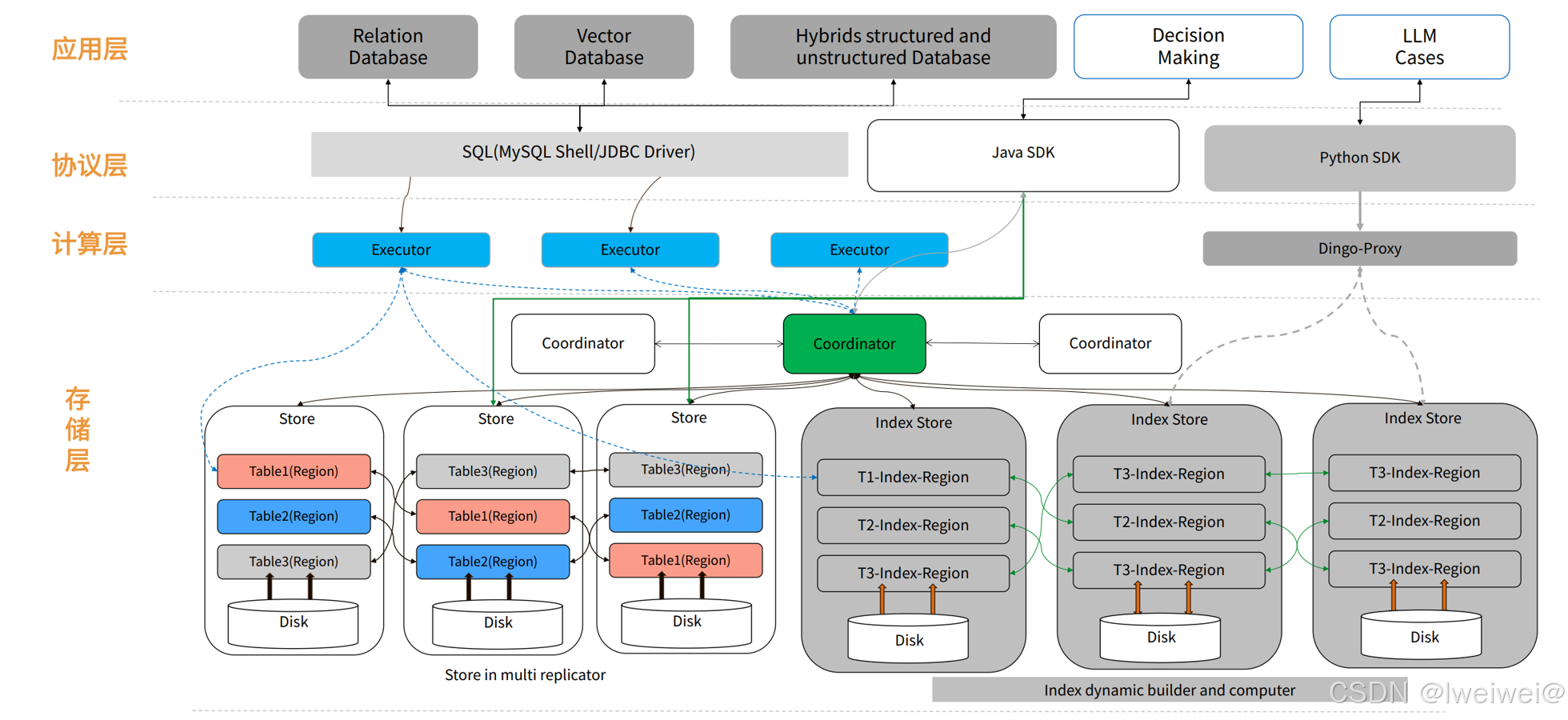
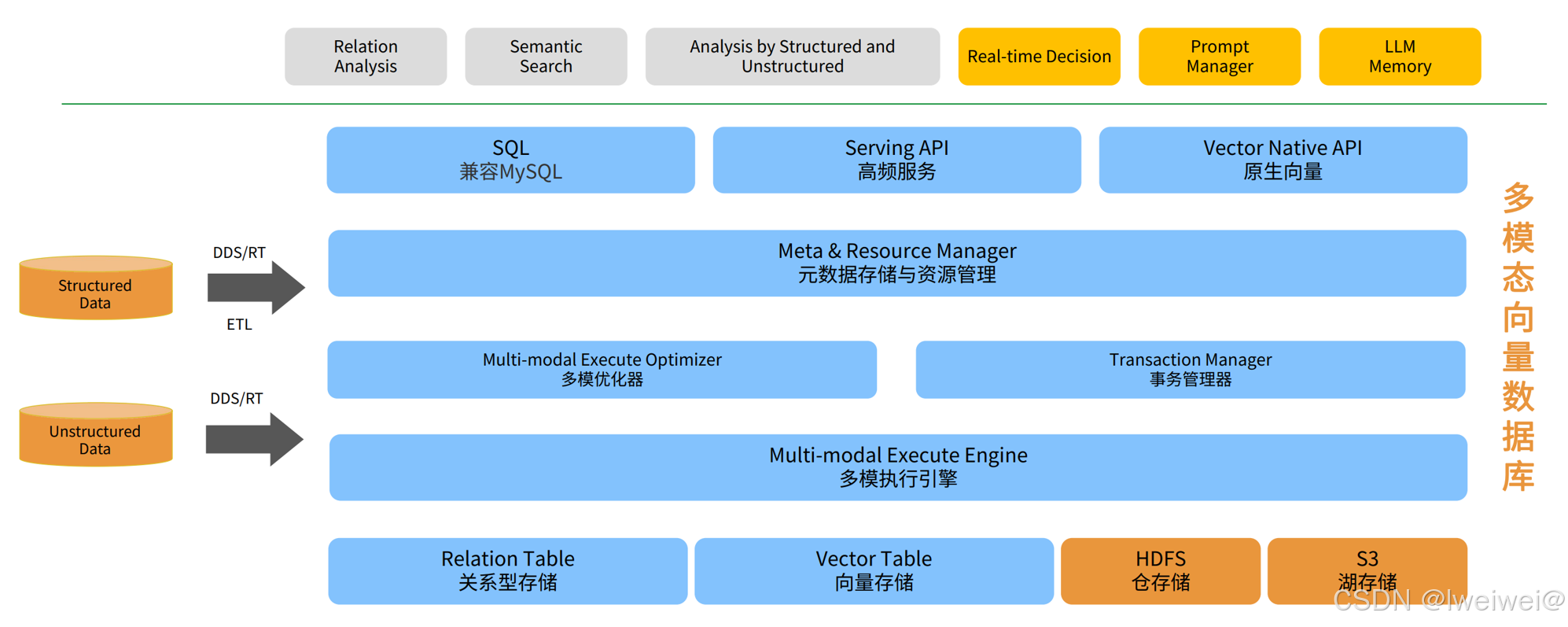
基于muti-Raft机制的分布式存储
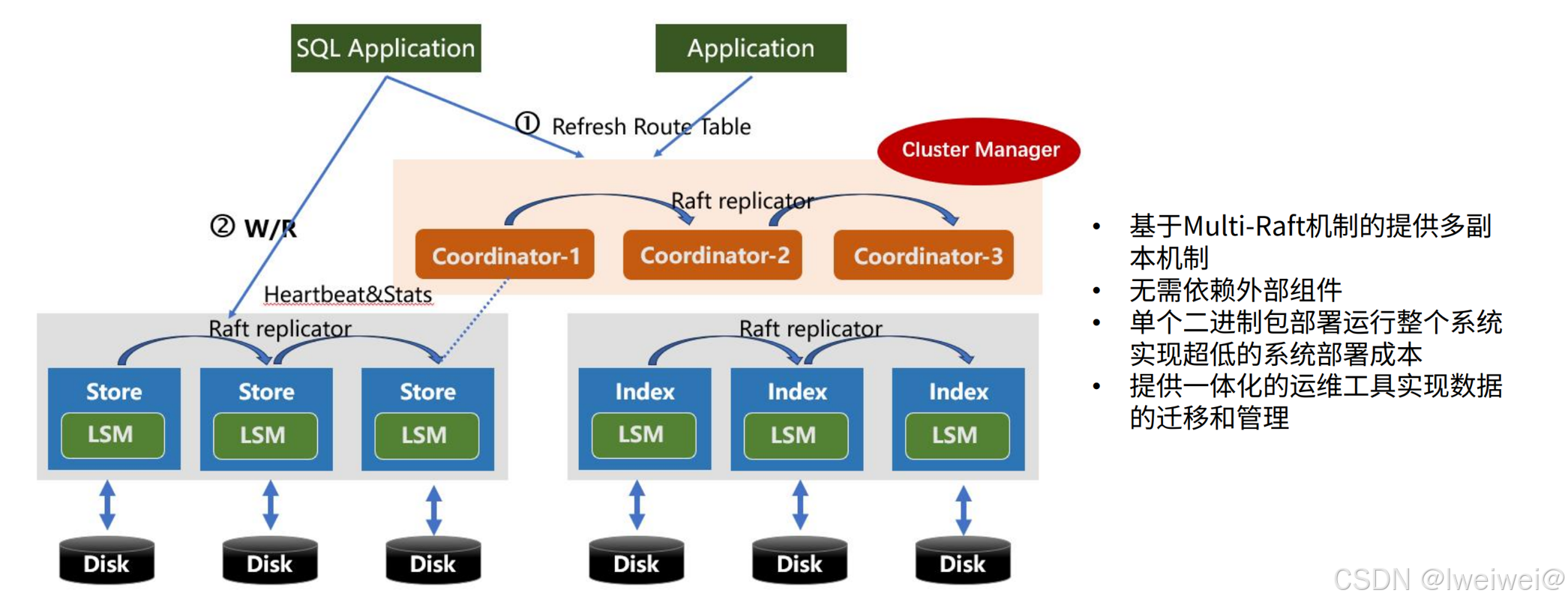
基于SQL的支持标量换个向量的联合分析
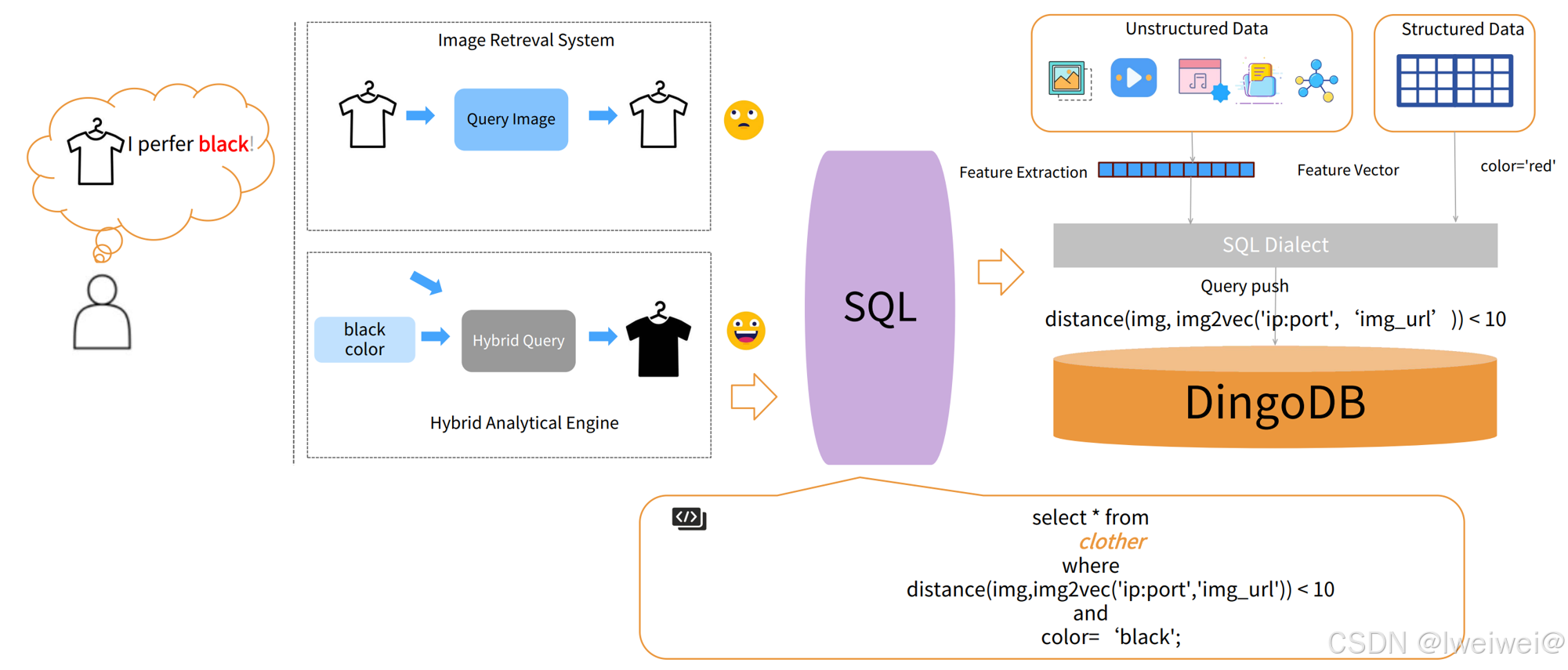
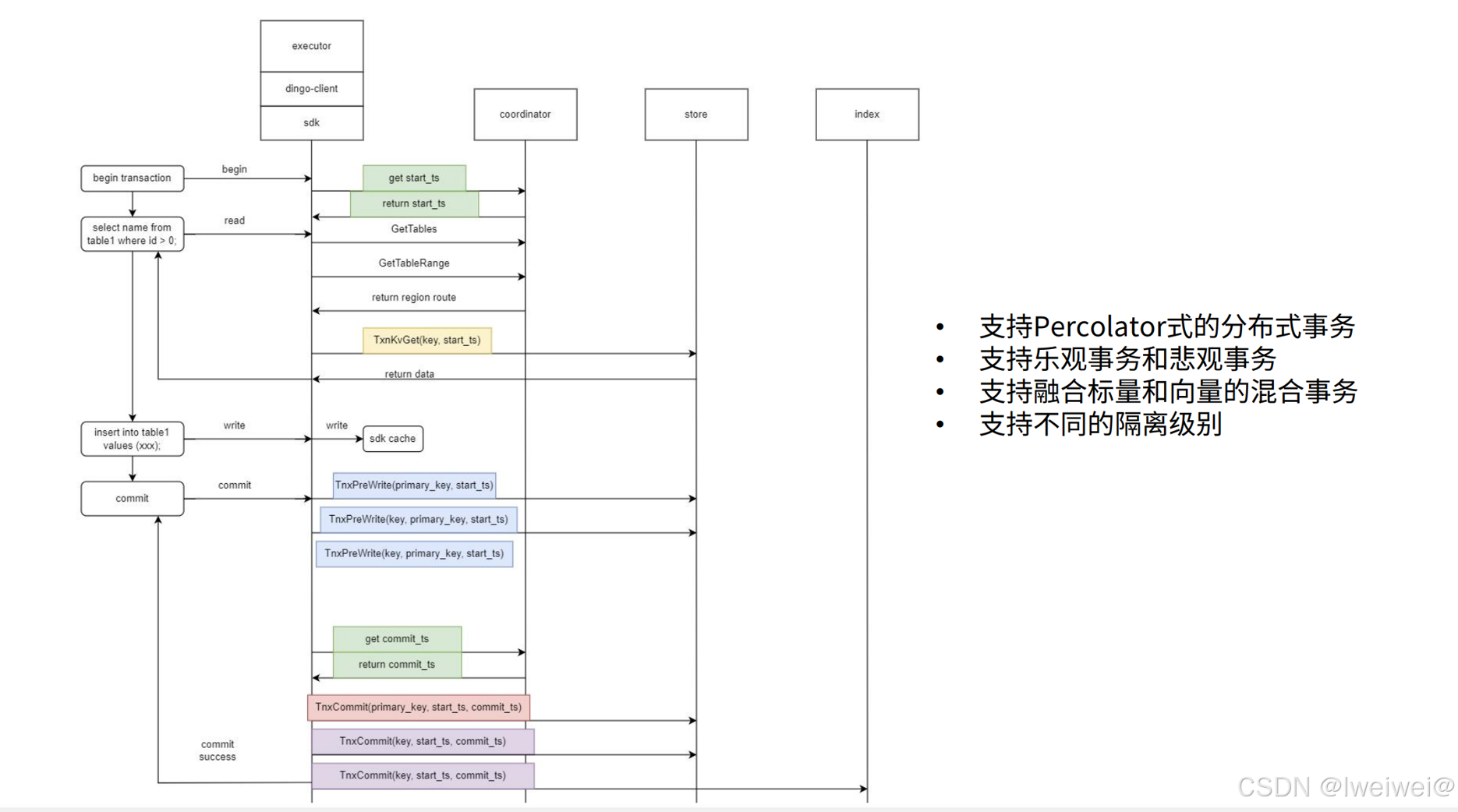
实时索引构建和优化
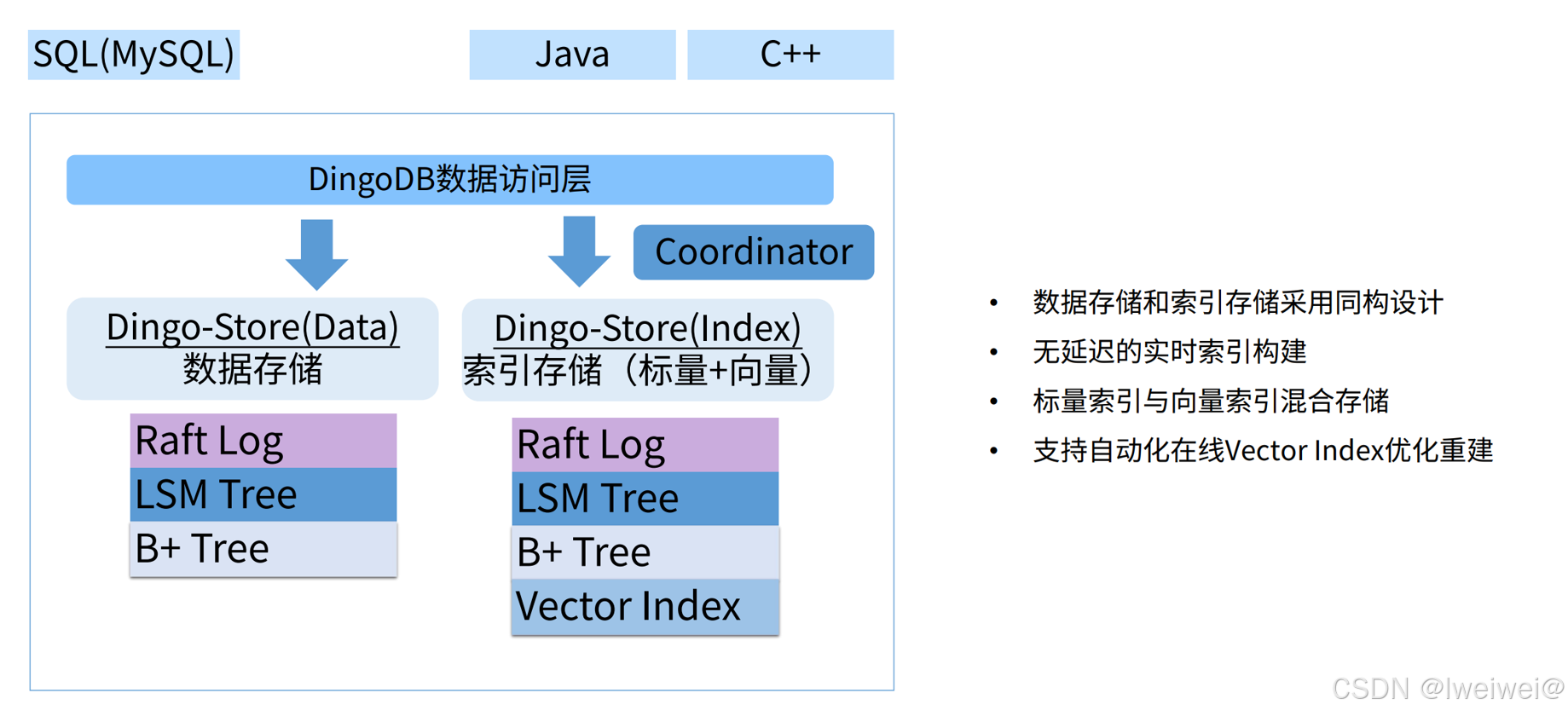
基于·dingodb的RAG
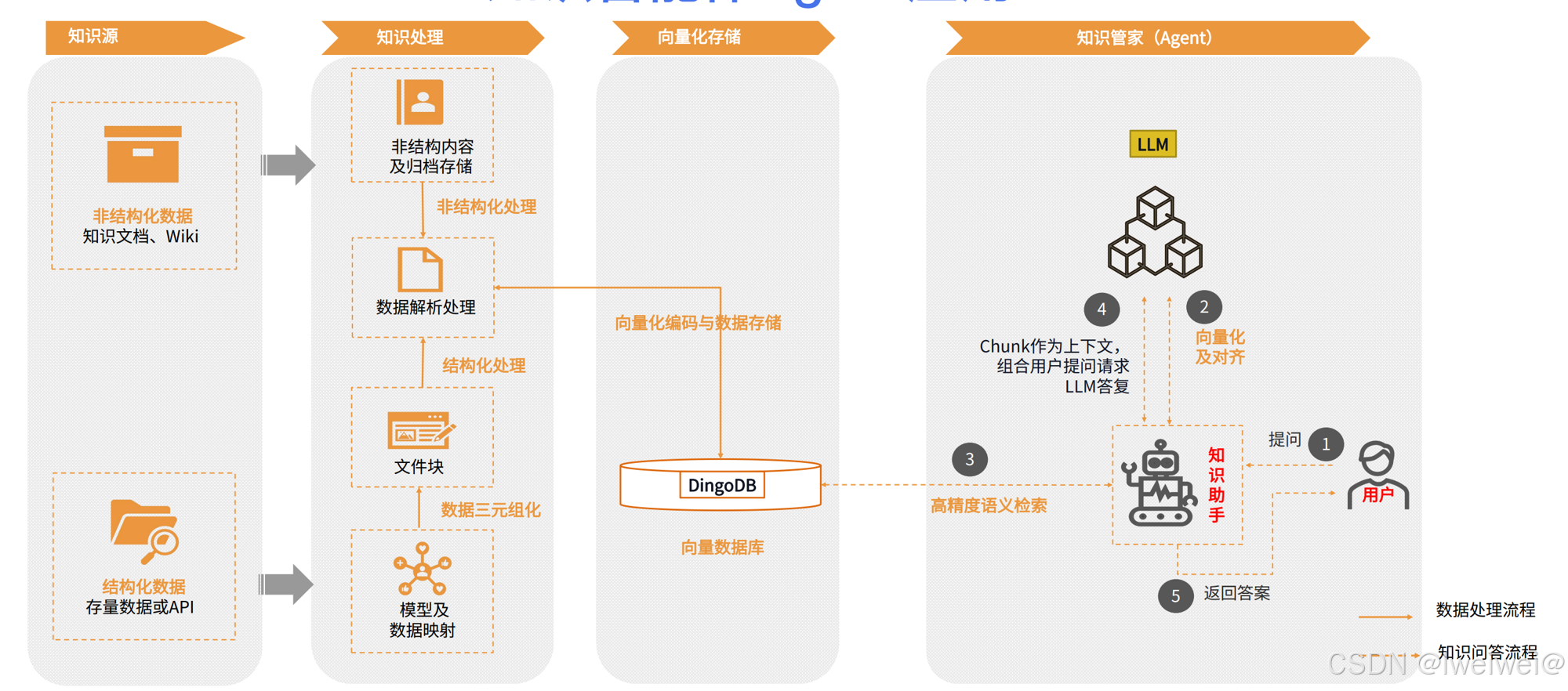
02 项目-智能客服
1. 架构
1.1 整体架构

接入层:web端、移动端,用户请求
应用服务:
- TaskBot
- kbbot:依赖知识库:QA、知识图谱
- chatBot:闲聊系统
运营:
标注、运营、评估、分析
基础服务:
算法、工程、数据、数据源、生产平台
1.2 基础架构

上面工程圈出来的这一块包括-也叫模型架构:

注解:
SQL:查询语言
模型管理:
- 算法模块
- 工程 模块
- 这些模型如何管理
- 根据用户的反馈做实时计算
- 数据
- 数据采集:只需要需要的字段
- 数据挖掘
- 数据聚合、迁移、清洗
- 数据解析之后会落到业务日志,在存储到mysql、redis中
1.3 技术难点
- 数据冷启动(大多数情况下,没有足够的数据来训练型):
先用一个通用的模型,等到数据足够多的时候优化这个模型;先用规则的方法做,先把这个模块做起来,等到数据足够多的时候,再来启用型的方法 - 多轮对话(多领域的多轮对话很难,目前还没有攻破)
单领域对话技术做得很好,比如说像最简单的订机票可以做得很好。。多领域对话技术比较难,比如订机票、查物流、退换货等 - 人机协作
没有办法最大化机器人的价值,机器人在整个智能客服的系统里面仍然是一个辅助的作用,而不是主要的作用。
技术应用发展过程
4. 单个关键词匹配
5. 多词匹配+模糊查询
6. 关键词匹配
7. 搜索技术神经网络
1.4 基于知识库的问答 流程
- 基于知识库的问答可以使用检索或者分类模型来实现。检索式回答的流程是:首先对用户的输入问题做处理,如分词、抽取关键词、同义词扩展计算句子向量等;
- 然后基于处理结果在知识库中做检索匹配,例如利用BM25、TF-IDF或者向量相似度等匹配出一个问题集合,这类似推荐系统中的召回过程;
- 由于是一个问答系统,最终是直接返回给用户一个答案,因此需要从问题集合中挑出最相似的那个问题,这里会对问题集合做重排序,例如利用规则、机器学习或者深度学习模型做排序,每个问题会被打上一个分值,最终挑选出top1,将这个问题对应的答案返回给用户这就完成了一次对话流程。
- 在实际应用中,我们还会设置阈值来保证回答的准确性,若最终每个问题的得分低于阈值,会将头部的几个问题以列表的形式返回给用户,最终用户可以选择他想问的问题,进而得到具体的答案
RAG
1.5 KBQA如何做冷启动?
- 知识为主的QA
- 知识库
- 首先,需要找到知识.
- 历史上的QA数据对。
- 聚类
- 阅读理解(NLP)
- 针对知识Q,对应的A找运营给你写话术
- 纯人工的过程,我们需要给一个知识库,让运营的人去这个知识库的平台为每一个知识配置答案
- OA对
- 通过意图识别去做,这个只适合的是意图不能太多,不建议维护太多的意图,因为分类的准确率会有折扣
- 匹配去做,更像一个搜索任务
- OA匹配配:直接去检索对应的答案
- QQ匹配:每一个知识,有很多的
相似问法,然后我们是要拿当前Q去这个知识所对应的相似Q里面直接做匹配,选一个得分最高的出来
- 首先,需要找到知识.
- 知识库

这是基于知识库的,知识库的覆盖率、命中率非常重要。所以构建知识库很重要。
1.6 TaskBot-一个工作流
-
具有固定流程的特定场景下的提供服务
-
用户的需求一般较复杂,通常需要机器人和用户做多轮互动以帮助用户明确目的自然语言理解模块会识别出当前输入问题的意图和槽位,然后输入到对话管理器去决定下-步的回答动作,最终再通过自然语言生成模块生成答案返回给用户


-
NLU:将本文信息映射为实际完成的意图
-
NLG: 话术,有基于模板的,生成回复信息
-
DM: 对话管理,包括DST–对话状态、PL–对话策略
DST(比如要拿到用户的订单、物流信息,所以会接很多API)
PL 根据DST的状态筛选出一些策略
相关的知识库KB也会被用到:DM最终给的是答案,所以要给到NLG生成话术
1.7 chatbot
- 闲聊服务是基于一个闲聊语料库,采用模板匹配、检索式回答以及生成式对话等多种技术来实现的。
- 模板匹配使用了AIML和正则表达式匹配;
- 检索式回答类似KB-Bot中的方式首先检索然后利用模型排序;
- 当模板匹配和检索式回答都不能给出闲聊回答时,我们会采用SeqSeq生成式对话,我们使用了一个标准的Seq2Seq模型,问题会首先输入到一个双向LSTM编码器,然后加入Attention机制,最终,用一个单层LSTM做解码,从而得到结果输出。生成式对话往往会生成一些让人难以理解的答案,这也是业界难以解决的问题。
03 FAQ
1.1 大模型服务吞吐太小?
- 大模型的吞吐率跟哪些有关
- 吞吐率 = 处理的请求N/延时
- 模型处理的延时与forward有关,处理的请求N与:模型一次能处理条数,也就是batch size;服务的实例数量,也就是部署了多少个结点。
- 大模型的单次推理延迟,首先是减少计算量:可以采用权重+激活量化来解决,如果profile到服务的计算资源还有空余,比如GPU的利用率只有60%,也可以用投机采样来做,比如小模型猜测+大模型验证;另一个方向是提高访存利用率,结合所用模型的计算量来分析,如果模型不是计算密集型的,也就是计算速度>访问内存速度,这时候主要就是内存访问瓶颈,在self-attention中,大部分就是属于这种情况,因此减少内存访问次数,可以极大提升单次推理速度,flash attention 就是这个思想;对于大模型的并行处理能力也有两个优化方向,一是在显存运行的情况下,增大模型一次处理的batchsize,这里有多种方法:静态batching和动态batching以及连续的batching,差别就是合并的batch方式不同。二是在业务条件允许情况下,做水平扩展,增加结点数,这里就要考虑到scaling的问题,也就是增加结点数之后,要尽可能最大化利用每个结点的计算能力,需要考虑到负载均衡的问题:k8s+GPU利用率监测+QLB负载均衡进行调优
- 优化吞吐率,影响最大的是模型处理的并行度,单次推理延时影响的是单个用户的体验,并行度是高并发情况下的多个用户的体验。如果增加batch size,会以10~30%的单次时延增加换来数倍甚至数十倍的吞吐率加速,因此可以使用目前最流行,加速最明显的continuous batching技术来讲解如何与实际业务模型结合的
- 为什么有这个方法,大模型服务不能假定固定长度的输入序列和输出序列,因此对于static batching和dynamic batching来说生成输出的变化可能会导致GPU严重未充分利用,解决这个问题的方法是采用迭代级调度,一旦一批中的一个序列完成生成,就可以在其位置插入一个新的序列,从而实现比静态批处理更高的GPU利用率,在代码层面实现时,还需要根据服务是流式输出还是一次次那个输出做进一步优化。如果是流式输出,则需要利用异步协程的async和await来实现计算机资源的切换,实现在token粒度级别的多用户输出。更进一步在这个过程中tokenize和detokenize也可以用异步协程来实现。
1.2 如何解决大模型中的badcse
- 加前置模块
- 做一级及多级的漏斗形状,最前面的式高频话术缓存,用户的问题会被逐级过滤和筛选,高频简单的问题会被优先处理掉,直接返回,这几个模块有明显的特点就是精度高,速度快,规则简单,如果命中,直接加trigger返回,比如用户的query可能会出现一些敏感话题或词语,这种情况是不能进大模型的,假如前面一层没有拦住时,往往会加一个拒识模块
- 加后处理
- 比如大模型的输出幻觉问题,在后面加一个处理模块来二次过滤,根据不可控的功能来构建检索规则,直接对这种话术,过滤删掉并快速修复,保证产品的安全性1
- 调prompt
- 一般是在bug不太紧急的情况下使用不要求立即fix,例如某些场景对输出话术有要求,比如必须回答上关键要点
- 模型微调优化
- 微调模型是使用的最低的,时间比较长,可能需要多次调优,对原有结果有影响,线上系统一般比较复杂,比如修复了A影响了B
04 多模态
1. 多模态大模型的结构范式
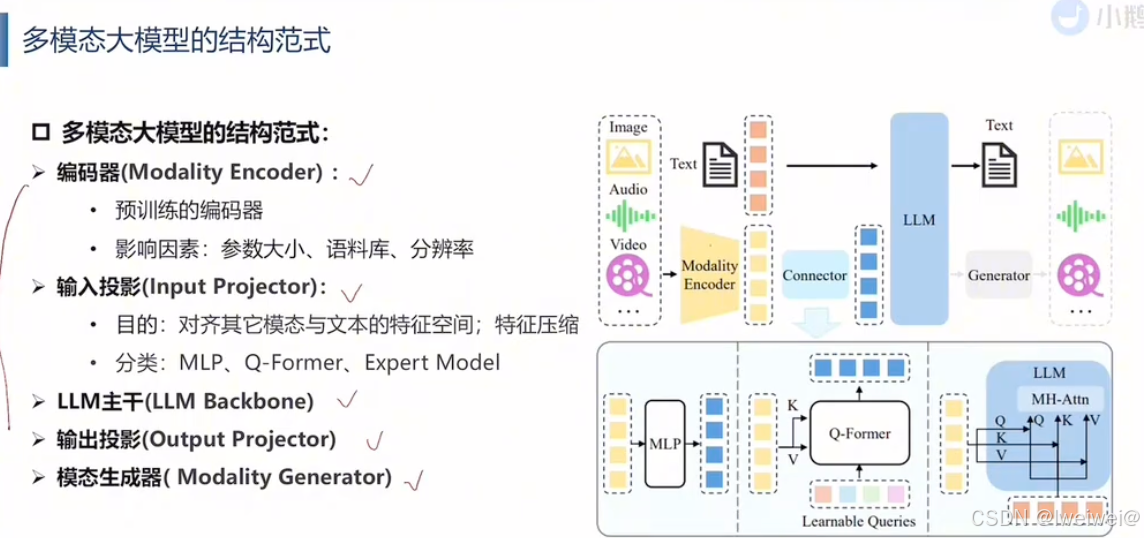



















 5605
5605

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











