







https://draveness.me/golang/docs/part1-prerequisite/ch02-compile/golang-compile-intro
https://space.bilibili.com/567195437/channel/series
学习笔记
对输入的文件先进行词法分析形成token,然后再对token进行语法分析形成抽象语法树,得到抽象语法树后分九个阶段对抽象语法树进行更新和编译:
- 检查常量、类型和函数的类型;
- 处理变量的赋值;
- 对函数的主体进行类型检查;
- 决定如何捕获变量;
- 检查内联函数的类型;
- 进行逃逸分析;
- 将闭包的主体转换成引用的捕获变量;
- 编译顶层函数;
- 检查外部依赖的声明;
在遍历整个语法树对类型做判断的时候还会重写make->(makechan,makeslice,makemap),最后生成中间代码,再把中间代码并根据目标cpu的架构(arm,x86不同的指令集)生成机器码。
词法与语法分析 -> 类型检查 -> 中间代码生成 -> 机器码生成
静态类型:静态类型为代码在编译期间提供了约束,编译器能够在编译期间约束变量的类型。
动态类型:动态类型检查是在运行时确定程序类型安全的过程,它需要编程语言在编译时为所有的对象加入类型标签等信息,运行时可以使用这些存储的类型信息来实现动态派发、向下转型、反射以及其他特性6。
Go 语言的编译器不仅使用静态类型检查来保证程序运行的类型安全,还会在编程期间引入类型信息,让工程师能够使用反射来判断参数和变量的类型。
中间代码:中间代码是编译器或者虚拟机使用的语言,它可以来帮助我们分析计算机程序。在编译过程中,编译器会在将源代码转换到机器码的过程中,先把源代码转换成一种中间的表示形式,即中间代码1。
在不考虑逃逸分析的情况下,如果数组中元素的个数小于或者等于 4 个,那么所有的变量会直接在栈上初始化,如果数组元素大于 4 个,变量就会在静态存储区初始化然后拷贝到栈上,这些转换后的代码才会继续进入中间代码生成和机器码生成两个阶段,最后生成可以执行的二进制文件。数组:指向数组开头的指针,元素数量,每个元素的大小
append扩容:
- 如果期望容量大于当前容量的两倍就会使用期望容量;
- 如果当前切片的长度小于 1024 就会将容量翻倍;
- 如果当前切片的长度大于 1024 就会每次增加 25% 的容量,直到新容量大于期望容量;
上述代码片段仅会确定切片的大致容量,下面还需要根据切片中的元素大小对齐内存,当数组中元素所占的字节大小为 1、8 或者 2 的倍数时,运行时会使用如下所示的代码对齐内存

map
渐近式扩容:当产生hash扩容的时候,我只有在每次hash表读写的时候把旧桶的数据迁移到新桶。避免一次性扩容带来的瞬时性能抖动。
go语言中,map变量本质上是一个hamp结构体,
type hmap struct {
count int//键值对数目
flags uint8//
B uint8//桶的数目 2^B
noverflow uint16
hash0 uint32
buckets unsafe.Pointer//桶的地址
oldbuckets unsafe.Pointer//旧桶
nevacuate uintptr //即将迁移的旧桶编号
extra *mapextra
}
go中的map的桶是bmap,每个桶能放8个健值对,为了使内存更加紧凑,8个key放一起,8个value放一起。在8个key前面则是8个tophash(取key的hash值的高8位),在最后是一个bmap的指针,表示溢出桶。(一般情况下如果B也就是桶的个数大于2的4次方,就认为使用溢出桶的概率较大),hmap最后的extra字段记录的就是溢出桶的信息
map的扩容规则:go语言默认的负载因子是6.5。大于这个数就会触发翻倍扩容
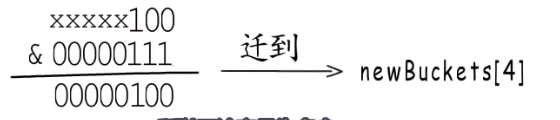
假设当前的桶是4,发生翻倍扩容之后桶为8,所以原先0号位置的数据会被迁移到新桶的中0号或者4号新桶中。
如果负载因子没超标而使用的溢出桶的数量过多,会发生等量扩容。既然是等量那有没有迁移有啥区别呢?这是因为当使用多个溢出桶,并且对健值对进行删除操作后,我们触发等量扩容机制之后可以似的健值对更加紧凑。


- 线程安全的map
go语言本身的map并不是线程安全的,可以用sync.map来实现线程安全的map。
string
golang中string使用utf-8编码,utf-8可以根据高位来确定是一个字节还是多个字节

go语言中的string 是一个指向内存地址的指针以及len表示字节个数。字符串内容不能被修改不能执行s[2] =‘o’,内存会把字符串的内存分配到只读内存段中。如果一定要修改,可以直接对变量整体赋新值 s1 = “hello”,他存取的地址就会指向新的内容。也可以将字符串强制类型转换成slice再做修改。

函数调用栈
虚拟地址空间分为栈,堆 数据段,代码段。栈区从高地址向低地址区增长,有一个sp栈顶指针,函数栈帧包括调用者地址,局部变量,返回值,参数。函数A调用函数B,会先压入函数A的栈帧,然后再压入返回地址,然后再压入函数B的栈帧。访问局部变量,参数,返回值等是通过栈顶指针sp+偏移值。

golang使用的是一次行分配栈内存,然后再通过偏移值来操作相应的栈,如果是逐步扩张的有可能导致栈访问越界。

匿名返回值与命名返回值的区别。在执行defer之前,会先赋值返回值,也就是return value,然后再执行defer的内容。
defer
defer函数会转化成 deferproc(注册),然后执行代码,最后 runtime.deferreturn()执行

defer会以链表的形式存在,采用的是头插法,所以defer是倒序执行的。

defer结构体
type _defer struct {
siz int32 //参数和返回值共占多少字节
started bool//是否已执行
sp uintptr//调用者栈指针
pc uintptr//返回地址
fn *funcval//注册的函数
_panic *_panic
link *_defer // next_defer
}
defer在注册的时候会在堆上创建defer结构体,在defer函数运行时,会把在堆上的参数拷贝到调用者栈中,

以上是go1.12版本的defer设计思路,这一版本的defer比较明显的问题就是慢,defer是在堆上创建的,其次参数要在堆栈之间来回拷贝。1.12版本的defer在注册阶段是将defer对象分配在堆上,之后的1.13版本是将defer对象直接分配在栈上。再注册到defer链表上。但是1.13中显示循环与隐式循环还是要用到1.12中的分配方式。通过在defer结构体中定义heap字段来标识是在堆上还是在栈上分配。

那么1.14版本的defer又做了哪些改动呢?对于A1将defer函数的参数直接定义为局部变量,在函数的最后再调用A1,这样也实现了defer的延迟效果,省去了defer结构体的定义以及链表的使用。但是A2就不能这样处理了,他要到执行阶段才能确定是否需要被调用,go语言用标识变量df来解决这个问题,df里的每一位对应标识一个defer函数是否要被执行。go1.14就是在编译阶段插入代码,把defer函数的执行逻辑展开在所属函数内,从而免于创建defer结构体与注册defer链表。这种方式称为open coded defer。


为什么堆比栈慢呢?,首先栈上的空间分配是固定的已知的,可以在编译阶段就确定大小,所以可以直接通过栈顶指针的偏移来确定访问和确定大小,而堆上的分配的对象空间大小不不固定的,所以要在运行时确定,这里分配大小要用到操作系统的函数malloc,函数调用,从用户态转换为内核态。
panic
panic也和defer一样会以链表的形式注册,

代码部分遇到panic之后,会停止执行panic之后的代码段,会在goroutine结构体中注册一个panic链表,然后再执行defer部分的链表。
会修改defer结构体中的started字段,标识为true,并且将defer中的panice字段指向当前的panic。表示当前的defer是该panic触发的。
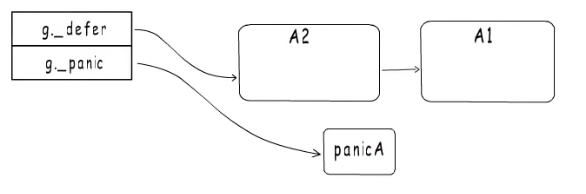
如果执行到A1又触发了一个panic,这时候会在panic链表头插入一个panicA1,然后再执行defer,但是当前的A1defer是由panicA触发的,然后会标识PanicA为终止,然后将A1这一项移除,这时候defer链表为空。然后会从panic链表尾向panic链表头进行打印panic信息。

panic结构体
type _painc struct {
argp unsafe.Pointer // defer的参数空间地址
arg interface{} //panic的参数
link *_panic //link to earlier painc
recovered bool//是否被恢复
aborted bool//是否被终止
}
recover
recover只做一件事,就是将当前的panic置为已恢复。也就是将panic结构体中的recover字段设置为true。
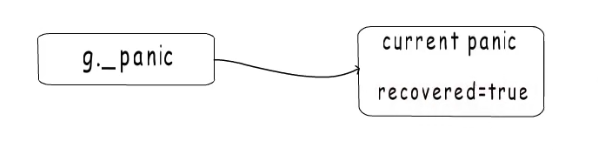
再每个defer函数执行完之后,panic流程都会检查当前的panic是否被它恢复啦,如果被恢复啦也就是recovered字段为true,就将当前panic从panic链表中移除。
闭包
在go语言中,函数可以作为参数,返回值,也可以作为变量,我们称这种函数为function value,函数的指令在编译期间形成在代码段中,function value本质上是一个指针,并不直接指向函数指令入口,而是指向一个runtime.funcval结构体。而funcval结构体里只有一个地址,指向函数指令的入口地址,

为什么要通过funcval结构体包装这函数的入口地址呢?这里主要是为了处理闭包的情况。闭包:1.必须有在函数外部定义,并且在函数内部引用的变量。2.脱离了行程闭包的上下文,也能照常运行。我们将在函数外部定义的并且在函数内部使用的变量称为捕获变量,

addr1就是闭包函数的地址,每次调用一个create函数,都会创建一个funcval结构体,该结构体中存储捕获变量c。将funcval结构体的地址存入寄存器中,然后再通过偏移值来获取对应funcval结构体中的捕获变量c。当函数A局部变量i被函数B这个闭包捕获,原先的局部变量会从原来的栈内存逃逸到堆内存初始化,栈内存只保存变量i在堆内存的地址

类型系统
不管是内置类型还是自定义类型,都有对应的类型描述信息,成为类型元数据。每种类型的元数据都是全局唯一的,这些类型元数据共同构成了go语言的“类型系统”。类型元数据是 runtime._type,uncommontype 是自定义类型数据时才有。例如myslic这个自定义的数据类型的元数据。首先是一个slicetype然后跟一个uncommontype,可以根据uncommontype 中的moff偏移值来获取myslice关联的方法元数据数组比如len,cap

每一种类型都有对应的类型元数据,而类型定义的方法都可以通过类型元数据中的uncommontype中的moff偏移值来查找。
interface接口
空接口类型可以接收任意类型的数据。他只要记录这个数据在哪,是什么类型的就可以了。_type就指向动态类型的元数据,data就指向接口的动态值。

如果对空接口变量赋值

非空接口,就是有方法列表的接口类型,一个变量要想赋值给一个非空接口类型,必须实现接口的所有方法。接口所要的方法都存储在itab这个结构体中,第一个字段指向接口的类型元数据,在接口类型元数据中有所有的方法列表


其中的itab结构体是可以复用的,用将itab缓存起来,以哈希表的形式存储。
reflect
反射的作用就是把类型元数据暴露给用户使用,reflect包有一个TypeOf函数,用于获取一个变量的类型信息。返回一个reflect.Type类型。
func TypeOf(i interface{}) Type {
eface := *(*emptyInterface)(unsafe.Pointer(&i))
return toType(eface.type)
}
type Type interface {
Align() int //对其边界
FieldAlign() int
Method(int) //方法
MethodByName(string) (Methid, bool)//方法名
NumMethod() int
Name() string //
PkgPath() string //路径
Size() uintptr
Kind() Kind
Implements(u Type) bool
AssignableTo(u Type) bool
ConvertibleTo(u Type) bool
Comparable() bool
}
在以空接口为传递参数时,只能传递地址,但是传参是值拷贝,不能直接拷贝对应参数的地址,所以会在局部变量区域复制一份对应的参数,然后再把该参数的地址作为空接口的参数。
进程线程和协程
为什么会有进程呢?是为了系统的并发执行,为了更好的调度和管理运行时的程序,但是引入了进城的概念之后同时也产生了一些问题,
进程之间的上下文切换会高消耗cpu资源,并且进程是占用虚拟内存空间一般情况下是GB级别的,线程只有MB级别。所以为了减少进城切换而造成的开销,所以引入了线程,多个线程可以共享一个进程的资源。进程上下文:通用寄存器,pc计数器,状态寄存器,用户栈,内核栈,内核数据结构:页表,打开文件信息的文件表。线程上下文:通用寄存器,pc计数器,栈,栈指针,每个线程共享进程的上下文的剩余部分,包括整个进程的虚拟地址空间,栈区 堆区 数据区 代码区 也共享进程打开文件的文件表。然后呢又将线程划分为内核态线程和用户态线程,用户态的线程就称为协程。进行协程和线程划分之后,协程的切换就不需要陷入内核态,这就节省了开销时间,这其中就产生了三种不同的对应关系a.N:1的对应关系的话 如果一个协程阻塞了那么所有的协程都阻塞了。b.1:1如果是1比1的对应关系那么不同协程之间的切换还是要跟内核态的线程切换相对应,还是要内陷内核态中。3m:n多对多的关系是最好的。也就是多个内核态的线程通过一个用户态的调度器进行对应多个用户态的协程。这里的性能瓶颈就是在调度器的设计了。
GMP模型
G就是协程goroutine,P是processor处理器他包含了每个goroutine运行所需要的资源(栈区 堆区 代码区 数据区),可以通过gomaxprocs设置p的个数, M就是线程thread。每个p上面有一个p的本地队列,p的本地队列中包含多个排队等待的G。除了每个p的本地队列之外还有一个全局的队列。当前程序能够并行执行的最多的goroutine的数量就是gomaxprocs的数量,可以通过runtime.gomaxproce()方法设置数量。优先会将新创建的G放在P的本地队列中,如果放满了会放在全局队列中。
GMP调度器的设计策略
- 复用线程:采用work stealing和 hand off 机制。work stealing机制是说当前的P的本地队列为空的时候,可以采用该机制从其他P的本地队列中偷取G执行。hand off 机制是说如果当前P绑定的G如果阻塞了,我们可以重新创建或者唤醒一个M2,将当前的本地队列与P与M2进行绑定。
- 利用并行:就是可以手动设置gomaxproc个数
- 抢占: 每个G有最多10ms的运行时间,时间一到就被其他的G抢占,防止其他G饿死。
- 全局G队列:如果采用work stealing机制其余的P的本地队列也为空的话就用去全局G队列获取G,当然这个操作是要加锁与解锁操作的。
go func()到底执行了什么过程
1、我们通过 go func()来创建⼀一个goroutine;
2、有两个存储G的队列列,⼀一个是局部调度器器P的本地队列列、⼀一个是全局G队列列。新创建的G会先 保存在P的本地队列列中,如果P的本地队列列已经满了了就会保存在全局的队列列中;
3、G只能运⾏行行在M中,⼀一个M必须持有⼀一个P,M与P是1:1的关系。M会从P的本地队列列弹出⼀一个可执 ⾏行行状态的G来执⾏行行,如果P的本地队列列为空,就会想其他的MP组合偷取⼀一个可执⾏行行的G来执⾏行行;
4、⼀一个M调度G执⾏行行的过程是⼀一个循环机制;
5、当M执⾏行行某⼀一个G时候如果发⽣生了了syscall或则其余阻塞操作,M会阻塞,如果当前有⼀一些G在执⾏行行, runtime会把这个线程M从P中摘除(detach),然后再创建⼀一个新的操作系统的线程(如果有空闲的线程可 ⽤用就复⽤用空闲线程)来服务于这个P;
6、当M系统调⽤用结束时候,这个G会尝试获取⼀一个空闲的P执⾏行行,并放⼊入到这个P的本地队列列。如果获取不不 到P,那么这个线程M变成休眠状态, 加⼊入到空闲线程中,然后这个G会被放⼊入全局队列列中。
调度器的生命周期
M0:启动程序后,编号为0的主线程。在全局变量runtime.m0中,不需要在heap上分配,负责执行初始化操作和启动第一个G。启动第一个G后,M0就和其他的M一样了。
G0:每次启动一个M,都会第一个创建的goroutine,就是G0。G0仅用于负责调度其他的G。G0不指向任何可执行的函数。假设要从G1切换到G2,那么需要先切换到G0,然后再通过G0切换到G2。通过G0来调度。在调度或系统调用时会使用G0的栈空间。
三色标记+gc混合写屏障
1.3标记清楚->1.5三色标记法->1.8混合写屏障机制
- 1.3标记清楚算法
先启动stw(stop the word 暂停业务逻辑),然后对可达对象进行标记。对不可达的对象进行回收,清除。清除完了之后再停止stw。
缺点:stw,让程序暂停,程序出现卡顿。标记需要扫描整个heap,清除数据会产生heap碎片。 - 1.5三色标记
会有白色标记表,灰色标记表,黑色标记表。程序起初创建,全部标记为白色,将所有对象放入白色集合中。先遍历root set,得到灰色节点。然后遍历灰色标记表,将可达的对象从白色标记为灰色,遍历之后的灰色标记为黑色。重复上一步,直到灰色标记表中没有任何对象。最后只剩下白色和黑色。最后将所有的白色对象视为垃圾,进行回收。

由于没有stw,如果出现黑色对象引用了一个白色对象,并且该白色对象由原来的灰色对象引用,并且原来的灰色对象取消了对该白色对象的引用,那么就会出现对象3被清除的情况。
三色标记最不希望出现的事:条件1.一个白色对象被一个黑色对象引用(白色挂在黑色对象下)。条件2.灰色对象与它之间的可达关系的白色对象遭到破坏(灰色同时丢了该白色)。
只要破坏上述两个条件同时成立,就可以解决该问题。于是引出了强弱三色不变式
强三色不变式:强制性的不允许黑色对象引用白色对象。
弱三色不变式:黑色对象可以引用白色对象,白色对象存在其他灰色对象对它的引用,或者可达它的链路上游存在灰色对象。在三色标记中如果满足强/弱之一,即可保证对象不丢失。
可以通过屏障机制来实现强弱三色不变式。
插入屏障:当对象被引用时,触发的机制。在A对象引用B对象的时候,不管B对象是什么颜色都设置为灰色。(将B挂在A下游,B必须被标记为灰色)。因为对象要么在栈上要么在堆上,为了保证栈上对象的速度,插入屏障不在栈上使用。那么要怎么回收栈上的对象呢?当只剩下黑色和白色对象之后,在回收白色对象前,重新遍历扫描一次栈空间。此时加STW保护栈空间,防止外界干扰。
不足:结束时需要stw来重新扫描栈,大约需要10-100ms。
删除屏障:当对象被删除时,触发的机制。被删除的对象,如果自身为灰色或者白色,那么被标记为灰色。这会导致对象2,3,5存活。但是可以在下一轮gc中将2,3,5对象删除。
不足:回收精度度,有些对象要通过下一轮gc才能被删除。

- 1.8的混合写屏障机制
- gc开始将栈上的可达对象全部扫描并标记为黑色(之后不再进行第二次重复扫描,无需stw)
- gc期间,任何在栈上创建的新对象,均为黑色(为什么之前的插入屏障要重新扫描栈区,因为栈区不使用插入屏障,当一个黑色对象引用一个白色对象的时候,该白色对象只有通过第二次扫描才会变成黑色。)
- 被删除的对象标记为灰色
- 被添加的对象标记为灰色
mutex
type Mutex struct {
state int32
sema uint32
}
mutex的结构体如上所示,state字段标识状态,当state为0值时,为未加锁状态。mutex的加锁与解锁都是通过automi包的原子操作来进行的。sema是一个信号量,主要用在等待队列。当state=1时为正常模式,当一个goroutine尝试获得锁的时候会自旋几次,若自旋几次之后仍然获得不到锁,则通过信号量排队等待,按FIFO先入先出的模式入队。当锁被释放之后,第一个在队列中等待的goroutine并不会立刻获得锁,而是会和在处于自旋尝试获得锁的,并未排队等待goroutine竞争锁。这种情况下,处于自旋的goroutine更有优势,因为他们正在cpu上运行,另一方面,处于自旋的goroutine可以有很多,而刚从队列中被唤醒的goroutine只有一个,所以被唤醒的goroutine很大概率拿不到锁,这时候它会重新插入队伍的头部继续等待,而如果一个goroutine加锁时间超过1ms之后,他会将正常模式改为饥饿模式,在饥饿模式下,mutex的执行权从原来的goroutine直接切换为等待队列头部的goroutine,后面来的goroutine不会自旋,也不会尝试获得锁(就算mutex是unlock),它们会直接从队列的尾部排队等待。当一个等待者获得锁之后,他会在以下两种方式将饥饿模式改为正常模式:第一种情况是它的等待时间小于1ms,第二种情况是它是最后一个等待者,等待队列已空了。正常情况下是会导致队列末尾的goroutine迟迟获取不到锁,而饥饿模式严格按照先来后到的原则,

mutex的state是一个人int32类型,它的第一位是标识mutex的状态是否已经锁住,第二位用于记录是否有goroutine已经被唤醒(来提醒释放锁的goroutine是否需要唤醒其他goroutine),第三位标识是否为饥饿状态,剩余的所有位表示有多少个排队等待的goroutine。
func (m *Mutex) Lock() {
if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {
return
}
m.lockSlow()
}
luck()函数,期望state是unlock状态,也就是state的第一位为0,但是如果一个自旋操作没能获得锁,就会进入lockSlow(),
func (m *Mutex) Unlock() {
new := atomic.AddInt32(&m.state, -mutexLocked)
if new != 0 {
m.unlockSlow(new)
}
}
unlock() 通过原子操作,减去mutexLocked,也就是减去1,修改状态。然后再通过新值new,来判断是否要进入unlockSlow函数,如果new=0,也就是没有其他goroutine在排队等待,所以不需要执行额外的操作,如果new!=0,
semaphore,runtime内部有一个大小251的semtable,来管理所有的semaphore,semtable存储的是251颗平衡树的根,每个平衡树都是一个sudog对象,mutex中的sema就是一个记录数值的变量,通过该数值来找到semtable中的位置,然后再查找对应的平衡二叉树,找到对应的等待队列。

channel
当我们用 ch:=make(chan int, 5) 创建一个channel时,会在栈上创建一个ch指针,该指针指向堆上的hchan对象。
type hchan strcut {
luck mutex//锁
buf unsafe.Pointer//缓冲区在哪的位置指针,实际上缓冲区就是一个数组
qcount uint //已经存储了多少个元素
dataqsiz uint //最多存储多少个元素
elemsize uint6 //每个元素占多少个空间
elemtype* _type//指向元素类型的类型元数据
sendx uint//读下标
recvx uint//写下标
recvq waitq//读等待队列
sendq waitq//写等待队列
closed uint32//关闭状态
}

ch := make(chan int, 5)
初始化缓冲区为空,读写下标都指向0的位置。

ch <- 1
ch <- 2
ch <- 3
ch <- 4
ch <- 5
ch <- 6
当第五个元素存入缓冲区之后,sendx会重新回到0下标的位置。

当运行到ch<-6时,缓冲区已经没有空闲位置了。这时候g1就会进入ch的发送等待队列中,发送等待队列是一个sudog类型的链表,会有两个指针分别指向哪个协程在等待,该协程在等待哪个channel,等待发送的数据在哪等信息。

这时候,协程g2从channel接收一个元素,recvx下标右移一个单位。第0个位置就空出来了。

所以这时候会唤醒sendq中的g1,将sudog结构体中的elem元素发送给ch,这时候缓冲区又满了,senq队列为空。

channel缓冲区是一个环型缓冲区。

ch <- 10
像这样对channel发送数据时,只有当缓冲区没有满,或者有其他的协程在等待接收(也就是在recvq中有sudog链表)时,才不会阻塞。

当遇到 channel为nil,或者无缓冲区,或者缓冲区满的情况下都会发生阻塞。

如果想要非阻塞方式,可以用select写法
/*
发送数据写法
如果可以发送数据则走case分支
否则走default分支
*/
select {
case ch <- 10:
...
default:
...
}
如果需要接收channel中的数据可以用以下三种写法,
<- ch
v := <-ch
v, ok := <-ch
上面三种接收方式都会发生阻塞,只有当缓冲区有数据,或者有协程在发送数据(也就是在sendq中有sudog链表数据),才不会发生阻塞。

当ch为nil,或者无缓冲区而且没有协程发送数据,或者有缓冲区但是缓冲区数据为空时,都会发生阻塞

如果不想阻塞,也可以按照select来写非阻塞式的写法。
select {
case <- ch:
...
default:
...
}
select …多路逻辑
堆内存管理
go语言的runtime将堆地址空间划分为一个个arena,arena区域的起始地址被定义为常量arenaBaseOffset,在64位的linux系统下每个arena大小为64MB,每一个arena包含8192个page,每个page大小为8k。

为了降低碎片化内存而对程序性能造成不良的影响,go语言的堆分配采用了tcmalloc内存分配器类似的算法。
按照大小不同规格把内存页划分为块,然后把不同规格的内存快放入对应的空闲链表中。go runtime的包给出了67个大小不同的链表,最小8B最大32k。

所以会把arena划分成大小规格不同的span,每个span包含一组连续的page,并且按照规格划分成了等大的内存块。arena,span,page,内存块就组成了堆内存。
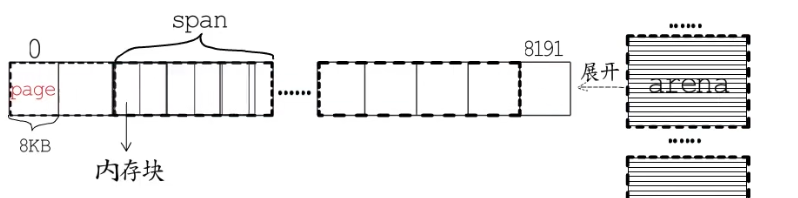
arena的管理是采用位图标记。
context机制
在go语言中当一个goroutine创建了多个子协程来负责不同任务的场景非常多见,这些协程需要传递一些截止时间,取消信号或其他请求的相关数据。这时候就可以使用context。
context中主要包括一个接口context,四个具体实现实现emptyCtx, cancelCtx, timerCtx, valueCtx,还有六个函数

context接口提供了四个方法。
type Context interface {
Deadline() (deadline time.Time, ok bool)
Done() <-chan struct{}
Err() error
Value(key interface{}) interface{}
}
- emptyCtx
其中emptyCtx本质上是一个int。 type emptyCtx int
Background函数,主要用于在初始化时获取一个context。这里的ctx是非空接口类型,itabl会指向一个类型元数据,data指向一个emptyCtx也就是int。这就是Background返回的变量结构。

而TODO()函数,官方文档建议在本来应该使用外层传递的ctx,而外层没有传递的地方使用。就想函数名称表达的意思一样,留下一个todo。
- cancelCtx
而cancelCtx结构是这样的:
type cancelCtx struct {
Context
mu sync.Mutex
done chan struct{}
children map[canceler]struct{}
err error
}
这是一种可取消的context,done用来获取该context的取消通知。children存储以当前节点为根节点的所有可取消的context。以便在根节点取消时一并将子节点一起取消。mu用来保护这几个字段的锁,以保证cancelCtx是线程安全的。
withCancel函数可以将一个context包装成cancelCtx,并提供一个取消函数。
func WithCancel(parent Context) (ctx Context, cancel CancelFunc) {
} // cancel是提供的取消函数
ctx1, cancel := WithCancel(ctx)
调用cancel可以cancel掉对应的context。
这里的data指向一个context结构体,第一个字段ctx指向他的父级context,

- timerCtx
type timerCtx struct {
cancelCtx
timer *time.Timer//定时器
dedline time.Time//截止时间
}
timerCtx在cancelCtx的基础上又封装了一个定时器和截止时间。这样可以根据需要主动取消,也可以在到达deadline时,自动取消。多个不同类型的context会形成一个context树,例如timerCtx是要基于cancelCtx创建的,对于可取消的context会被注册到离他最近的可取消的祖先节点中。对于ctx2来说离他最近的祖先是ctx1,所以在ctx1的children map中会存储ctx2。如果ctx2取消,只会影响以他为节点的context,而如果ctx1取消了,那么ctx2也会被取消。

- valueCtx
type valueCtx struct {
Context
key, value interface{}
}
他用来支持键值对打包,
















 168
168











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









