







 文章探讨了三种分布式文件系统——HDFS的联邦架构、CephFS的动态子树分区以及CurveFS的元数据分片策略。HDFS通过联邦解决NameNode的扩展性问题,但仍有单点故障和负载均衡挑战。CephFS采用多活MDS提升性能和高可用,但频繁的元数据迁移可能带来开销。CurveFS通过元数据分片实现高可用、高扩展性和高可靠性,但在大规模元数据聚合操作时需优化性能。
文章探讨了三种分布式文件系统——HDFS的联邦架构、CephFS的动态子树分区以及CurveFS的元数据分片策略。HDFS通过联邦解决NameNode的扩展性问题,但仍有单点故障和负载均衡挑战。CephFS采用多活MDS提升性能和高可用,但频繁的元数据迁移可能带来开销。CurveFS通过元数据分片实现高可用、高扩展性和高可靠性,但在大规模元数据聚合操作时需优化性能。
上一篇文章https://blog.csdn.net/qq_58034031/article/details/129518612分享了一篇20222论文,讲述在大型分布式文件系统中高效元数据服务,以此为启发总结了目前主流分布式文件系统它们是如何管理元数据的。
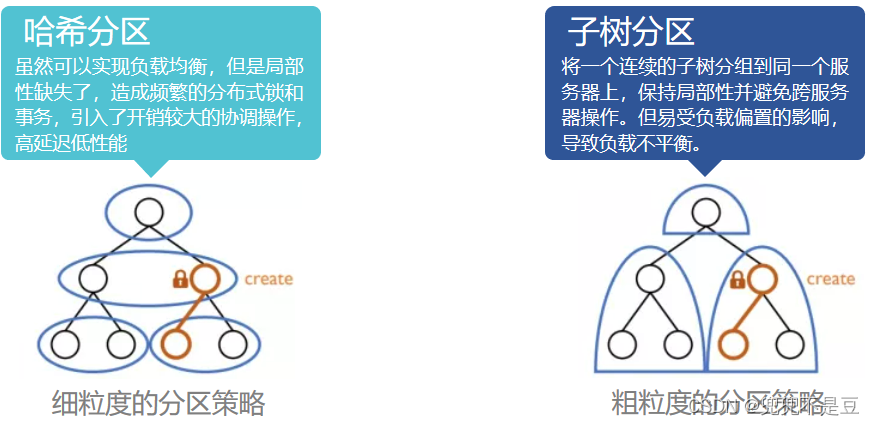
一、元数据分区方式
常用的元数据分区方式分为子树分区和hash分区,其中子树分区又分为静态子树分区和动态子树分区。
二、常见分布式文件系统元数据管理方式
本文主要从经典的中心化分布式文件系统、非中心化分布式文件系统和网易2021年发布的CurveFS(目前还在完善中)三个方面对它们元数据管理方案进行总结。
2.1 HDFS
(1)单组Namenode架构
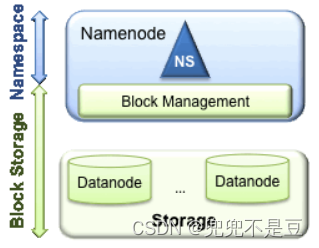
- HDFS主要有两大模块:
- Namespace(命名空间):由目录、文件和块组成,它支持所有命名空间相关的文件操作,如创建、删除、修改,查看所有文件和目录。
- Block Storage Service(块存储服务):包括Block 管理和存储两部分
- Block管理 通过控制注册以及阶段性的心跳,来保证Datanode的正常运行
- 处理Block的报告信息和维护块的位置信息; 支持Block相关的操作,如创建、删除、修改、获取Block的位置信息;
- 管理Block的冗余信息、创建副本、删除多余的副本等。
- 存储
- Block管理 通过控制注册以及阶段性的心跳,来保证Datanode的正常运行
- 单组Namenode只允许整个集群有一个活动的Namenode,管理所有的命名空间。当集群中数据增长到一定规模后,NameNode 进程占用的内存可能会达到成百上千 GB,此时,单组NameNode 成了集群的性能瓶颈。
- 为了提高 HDFS 的水平扩展能力,提出了Federation(联邦)机制。HDFS Federation 是用来解决 NameNode 内存瓶颈问题的横向扩展方案。
(2) HDFS 联邦架构
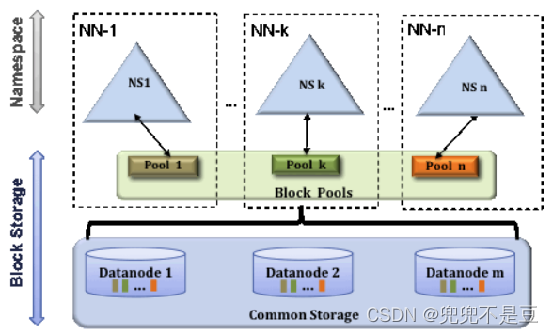
- Federation架构与单组Namenode架构相比,主要是Namespace被拆分成了多个独立的部分,分别由独立的Namenode进行管理。
- Block Pool(块池)
- Block Pool允许一个命名空间在不通知其他命名空间的情况下为一个新的block创建Block ID。同时一个Namenode失效不会影响其下Datanode为其他Namenode服务。
- 每个Block Pool内部自治,也就是说各自管理各自的block,不会与其他Block Pool交流。一个Namenode挂掉了,不会影响其他NameNode。
- Federation优点:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4369
4369

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









