





梯度下降学习法
(感觉英文文章讲的很细,内容其实不多,就是讲的基础了点)既然我们有了神经网络的设计,它怎么能学会识别数字呢?我们首先需要的是一个数据集,用来学习所谓的训练数据集,我们将使用MNIST数据集,其中包含数以万计的手写数字的扫描图像,以及它们的正确分类。MNIST的名字来源于一个事实,即它是由美国国家标准和技术研究所收集的两个数据集的一个修改子集。以下是来自MNIST的一些图片:

正如你所看到的,这些数字实际上和这一章开头所显示的一样,是一种识别的挑战。当然,在测试我们的网络时,我们会要求它识别那些不在训练集中的图像!
MNIST的数据分为两部分。第一部分包含6万张图片作为训练数据。这些图像是从250人的笔迹样本中扫描出来的,其中一半是美国人口普查局的雇员,其中一半是高中生。图像是灰度的,28 * 28像素大小。MNIST数据集的第二部分是10000个图像作为测试数据。同样,这些是28 * 28的灰度图像。我们将使用测试数据来评估我们的神经网络已经学会了如何识别数字。为了对性能进行良好的测试,测试数据取自不同的250人,而不是原始的培训数据(尽管仍然是人口普查局员工和高中生之间的分组)。这有助于让我们相信,我们的系统能够识别那些在训练中没有看到的人的数字。
我们将使用符号x来表示训练输入。会方便认为每个训练输入x是28×28 = 784维向量。向量中的每个条目表示图像中单个像素的灰度值。我们将用y =y(x)表示相应的期望输出,y是一个10维的向量。例如,如果一个特定的训练图像,x,描述了一个6,那么y(x)=(0,0,0,0,0,0,1,0,0,0,)T是网络期望的输出。注意,这里的T是转置操作,将行向量变成一个普通(列)向量。
我们想要的是一种算法,它能让我们找到权重和偏差,从而使网络输出近似于y(x),用于所有训练输入x。为了量化我们达到这个目标的程度,我们定义了一个成本函数 *有时被称为损失或目标函数。我们在本书中使用了损失函数这个术语,但是你应该注意其他术语,因为它经常用于研究论文和其他关于神经网络的讨论。:
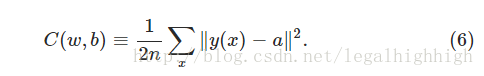
在这里,w表示网络中所有权值的集合,b所有的偏差,n是训练输入的总数,a是输入时网络输出的向量,并且总和除以所有训练输入,x。当然,输出的a依赖于x、w和b,但是为了保持符号的简单,我没有明确表示这种依赖。符号∥v∥为v向量v的长度函数。我们称它为二次成本函数;它有时也被称为平均平方误差或者只是MSE。考察了二次成本函数的形式,我们发现C(w,b)是非负的,因为求和中的每一项都是非负的。此外,成本C(w,b)变得很小,即C(w,b)≈0,即对于所有培训输入x, y(x)约等于输出a。所以我们训练算法做了很好的工作如果能找到重量和偏见, C(w,b)≈0。相比之下,当C(w,b)是大的时候,它做的不是很好,这意味着y(x)不接近于大量输入的输出a。因此,我们的训练算法的目的是将C(w,b)的成本最小化,作为权重和偏差的函数。换句话说,我们想要找到一组权重和偏差,使成本尽可能的小。我们会用一个叫做梯度下降的算法来做。
为什么要引入二次成本?毕竟,我们不是主要对通过网络正确分类的图片数量感兴趣吗?为什么不直接将这个数字最大化,而不是像二次成本那样最小化度量呢?问题是,正确分类的图像数量不是网络中权重和偏差的平滑函数。在大多数情况下,对权重和偏差进行小的修改不会对正确分类的训练图像的数量造成任何改变。这使得我们很难弄清楚如何改变权重和偏差来提高性能。如果我们使用的是一个平滑的成本函数,比如二次成本,那么我们就可以很容易地找出如何在权重和偏差中做出小的改变从而使成本得到改善。这就是为什么我们首先关注最小化二次成本,只有在那之后我们才会检查分类的准确性。
即使考虑到我们想要使用一个平滑的成本函数,你可能仍然想知道为什么我们要选择公式(6)中使用的二次函数,这不是一个特别的选择吗?也许如果我们选择一个不同的成本函数我们会得到一套完全不同的最小化权重和偏差的集合?这是一个合理的问题,稍后我们将重新讨论成本函数,并进行一些修改。然而,方程(6)的二次代价函数对于理解神经网络学习的基本知识非常有效,所以我们现在就继续。
在训练神经网络时,我们的目标是找出权重和偏差,从而最小化二次成本函数C(w,b)。这是一个适定问题,但目前有很多分散结构的构成——w的解释和b重量和偏见,σ函数潜伏在背景、网络体系结构的选择,MNIST等等。事实证明,我们可以通过忽略大部分的结构来理解巨大的数量,只关注最小化的方面。现在我们将会忘记所有关于成本函数的具体形式,神经网络的连接,等等。相反,我们会想象我们只是得到了很多变量的函数我们想要最小化这个函数。我们将开发一种叫做梯度下降的技术,它可以用来解决这样的最小化问题。然后我们回到我们想要最小化的特定函数神经网络。
假设我们要最小化某个函数,C(v)这可能是任何实值函数的变量,v = v1、v2,…。请注意,我已经用v替换了w和b表示法,以强调这可能是任何函数——我们在神经网络环境中不再具体地思考。为了最小化C(v),它有助于把C想象成两个变量的函数,我们称之为v1和v2:
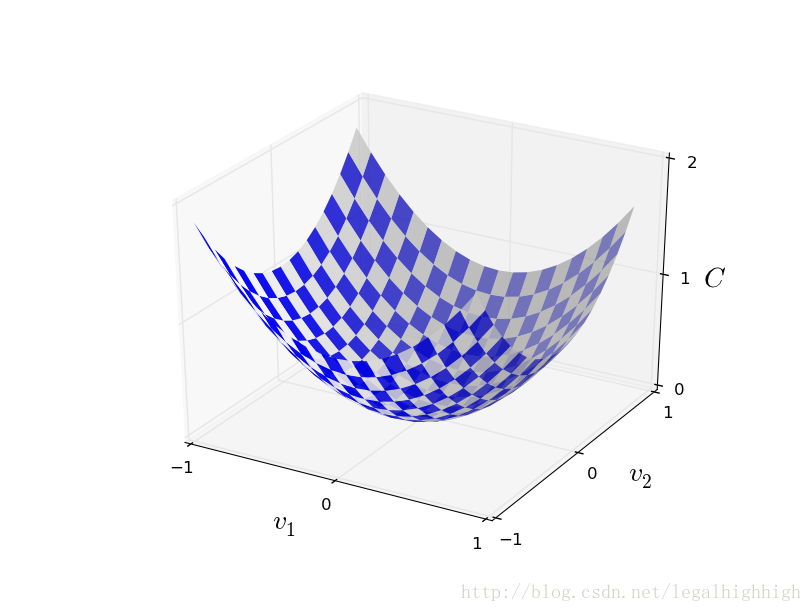
我们希望找到C达到全局最小值的地方。当然,对于上面绘制的函数,我们可以看一下这个图,找到最小值。从这个意义上说,我可能有点过于简单的一个函数!一般的函数,C,可能是很多变量的一个复杂函数,通常不可能只盯着图来找出最小值。
解决这个问题的一种方法是使用微积分来试图找到最小的解析。我们可以计算导数,然后试着用它们来找出C是极值的位置。当C只是一个或几个变量的函数时,可能会有一些运气。但是当我们有更多的变量时,它就变成了一场噩梦。对于神经网络来说,我们通常需要更多的变量——最大的神经网络有成本函数,它以极其复杂的方式依赖数十亿的权重和偏差。用微积分来最小化这是行不通的!
(在断言我们将通过把C想象成两个变量的函数来想象内部图像,我在两段中翻了两遍,然后说,“嘿,但是如果它是一个多变量的函数呢?“很抱歉。但请相信我,把C想象成两个变量的函数确实有助于我们去理解。有时这种情况也会发生,比如最后两段处理的是这样的问题。而对数学的思考经常涉及到要同时处理多个直观的图形,有时候是可行的。)这一段翻译的很烂,可以不看
所以微积分不起作用了。幸运的是,有一个漂亮的类比提出了一种算法,它运行得很好。我们首先想到的是我们作为一个山谷的功能。如果你只是稍微看一下上面的情节,那应该不会太难。我们想象一个球滚下山谷的斜坡。我们的日常经验告诉我们,球最终会滚到谷底。也许我们可以用这个方法来找出函数的最小值?我们随机选择一个(假想的)球的起点,然后模拟球滚到谷底时的运动。我们可以简单地通过计算衍生工具(也许是一些二阶导数)来做这个模拟——这些衍生品会告诉我们所有我们需要知道的关于这个山谷的“形状”的信息,因此我们的球应该如何滚动。
根据我刚刚写的,你可能会认为我们会尝试写下牛顿的运动方程,考虑摩擦力和重力的影响,等等。实际上,我们不打算把球滚动的类比当真——我们正在设计一种算法来最小化抄送,而不是对物理定律进行精确的模拟!从球的视角来解释是在激发我们的想象力,而不是束缚我们的思维。因此我们不用去理清混乱的物理细节,而知识让我们简单地问自己:如果某天我们自己成为了上帝,并可以去构建自己的物理定律,可以决定如何滚球,那我们选择什么规律或运动定律来让球总是滚山谷的底部?
为了把这个问题描述的更加精准,让我们来思考当球在V1的方向移动了很小的距离V1,在V2方向移动了很小的距离V2,我们计算C函数的变化公式是:
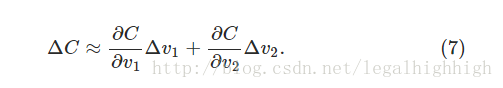
我们会找到一个合适的V1和V2用来使得C为负数,这样即是让球滚下山谷。















 1124
1124

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









