







统计推断一个重要问题是假设性检验。何为假设性检验,一句话概括就是:之前提出的分布,可不可以接受。就是根据样本,然后对提出的假设做出判断:接受or拒绝
具体关于假设性检验的说明可以参考文献1,本节总结了参数检验下的z检验。
1、单个总体 N(μ,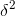
其中μ是均值,
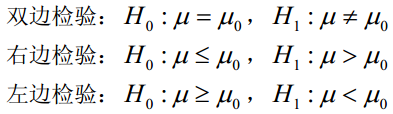
2、Z检验 (
Z检验是一般用于大样本(即样本容量大于30)标准正态分布的平均值差异性检验的方法。如果检验一个样本平均数μ与一个已知的总体平均值,其Z值计算公式为:
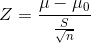
其中:
μ是检验样本的平均数
μ0是已知总体的平均数
S是样本的标准差
n是样本容量
如果检验俩个样本平均数μ是否一样,其Z值计算公式为:
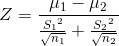
其中:
μ1和μ2是样本1,样本2的平均数;
S1,S2是样本1,样本2的标准差;
n1,n2是样本1,样本2的容量。
比较计算所得Z值与理论Z值,推断发生的概率,依据Z值与差异显著性关系表作出判断。如下表所示:
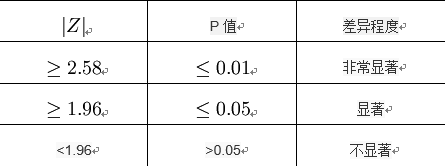
实验
假设某工厂正在生产一批图钉,之前的均值是:1.500,标准差:0.015,下面是一组机器生产的30个图钉
A组:1.497 1.506 1.518 1.524 1.498 1.511 1.520 1.515 1.512 1.511
B组:1.498 1.516 1.528 1.514 1.488 1.521 1.521 1.525 1.513 1.521
C组:1.498 1.513 1.522 1.524 1.498 1.521 1.511 1.524 1.523 1.521
问题1:机器生产是否正常
MATLAB实现:
问题1:
function processing
rowdata = [1.497 1.506 1.518 1.524 1.498 1.511 1.520 1.515 1.512 1.511...
1.498 1.516 1.528 1.514 1.488 1.521 1.521 1.525 1.513 1.521...
1.498 1.513 1.522 1.524 1.498 1.521 1.511 1.524 1.523 1.521];
[h,p,ci]=ztest(rowdata,1.5,0.015);
%结果:
% h = 1
% p = 5.3115e-07
% ci = [1.5084 1.5191]
end分析:h=0的时候接受原假设,h=1的时候拒绝原假设。说明在0.05的情况下拒绝原假设。结论:机器生产是不正常的 SparkML实验
Spark是不存在z检验的,所以需要我们自己书写函数。下面为了清晰我的设计的思路,我给出了下面几点,有助于阅读。
第一点:设计这个程序不仅仅是为了计算Z的数值,如果只计算z的时候,那么还要去查表去完成其他任务,那么這样的程序就不是优秀的程序,所以我们的程序应该包含尽量多的信息,以减少再次操作。下面是我打算作为输出的量。
1、可以不可以接受原假设,既H值?
2、拒绝域的大小,即P值?
3、置信区间是多少?
4、差异程度
差异程度是一个非常模糊的概念,所以我们在computation中一般会忽略這种,或者采用数值的形式表达。
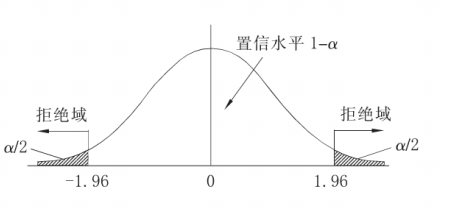
第二点:要计算 2、3俩点,需要了解下面的图形,但是必须提醒一下,正态分布,不仅仅有标准的正态分布,而且右尾、左尾,标准之分,具体可以查看相关文献,下面是标准的正态分布。
、
第三点:scala对传统的计算还是很原始,所以我借助了breeze(http://www.scalanlp.org/),所以需要加入jar包
package Basic import breeze.linalg.{ DenseVector} case class MatrixEntry(i: Long, j: Long, value: Double) /** * Created by legotime on 2016/4/12. */ /** * x:输入的检验的序列 * mu:检验的均值 * sigma:标准差 * alpha:可信度 * tail:双尾时:tail=0,右尾时:tail=1,左尾时:tail=-1 */ class ZTEST (val x: DenseVector[Double], val mu:Double, val sigma:Double, val alpha:Double,val tail:Int) { //省却的情况下,可信度为0.05,tail为双尾 //def this(x: DenseVector[Double],mu:Double,sigma:Double) = this(x,mu,sigma,0.05,0) //计算z的值 val sampleSum = x.toArray.sum val sampleSize = x.size.toDouble val sampleMean = sampleSum/sampleSize val ser = sigma/math.sqrt(sampleSize) val zValue= (sampleMean-mu)/ser val crit = breeze.stats.distributions.Gaussian(0,1).icdf(1 - alpha/2)*ser //计算正确的P值 def pValue() = tail match { case 0 => breeze.stats.distributions.Gaussian(0,1).cdf(-math.abs(zValue))*2 case 1 => breeze.stats.distributions.Gaussian(0,1).cdf(-zValue) case -1 =>breeze.stats.distributions.Gaussian(0,1).cdf(zValue) } //计算置信区间 def critValue() = { val critValue = DenseVector.zeros[Double](2) tail match { case 0 => critValue(0)=sampleMean - crit;critValue(1)=sampleMean + crit case 1 => critValue(0)=sampleMean - crit;critValue(1)=1000.0 case -1 => critValue(0)= -1000.0;critValue(1)=sampleMean + crit } critValue } //计算H的数值 def hValue() = if (this.pValue() > alpha) 0 else 1 }
package Basic import breeze.linalg.{ DenseVector} /** * Created by legotime on 2016/4/12. */ object WorkSheet { def main(args: Array[String]) { val x = DenseVector(1.497,1.506,1.518,1.524,1.498,1.511,1.520,1.515,1.512,1.511,1.498,1.516,1.528,1.514,1.488,1.521,1.521,1.525,1.513,1.521 ,1.498,1.513,1.522,1.524,1.498,1.521,1.511,1.524,1.523,1.521) val Z = new ZTEST(x,1.5,0.015,0.05,0) println(Z.hValue())//1 println(Z.pValue())//5.311508735061921E-7 println(Z.critValue())//DenseVector(1.5083657509021822, 1.519100915764485) } }
参考文献
1:https://en.wikipedia.org/wiki/Statistical_hypothesis_testing















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









