






2023年起,以ChatGPT为开端的AI原生应用开始走进生产场景,无论是日常对话、创作生成、还是解答专业问题,似乎“无所不知、无所不能”。
其底层是相关企业所训练出来的通用大模型,使用过这类工具的同学都能感觉到,现有的通用模型在一些专业化或个性化的任务上,往往并不够 专业、精准 ,比如: 角色扮演 和 模拟特定人物的语气与行为 。
对于需要特定语言风格、情感表达和人物设定的任务,标准大模型往往难以做到精准模仿。 在这种情况下, 定制专属大模型 的技术被广泛关注,我们期待通过投喂特定语料,改造大模型,让模型在某些专业领域或特定任务中表现得更为出色。
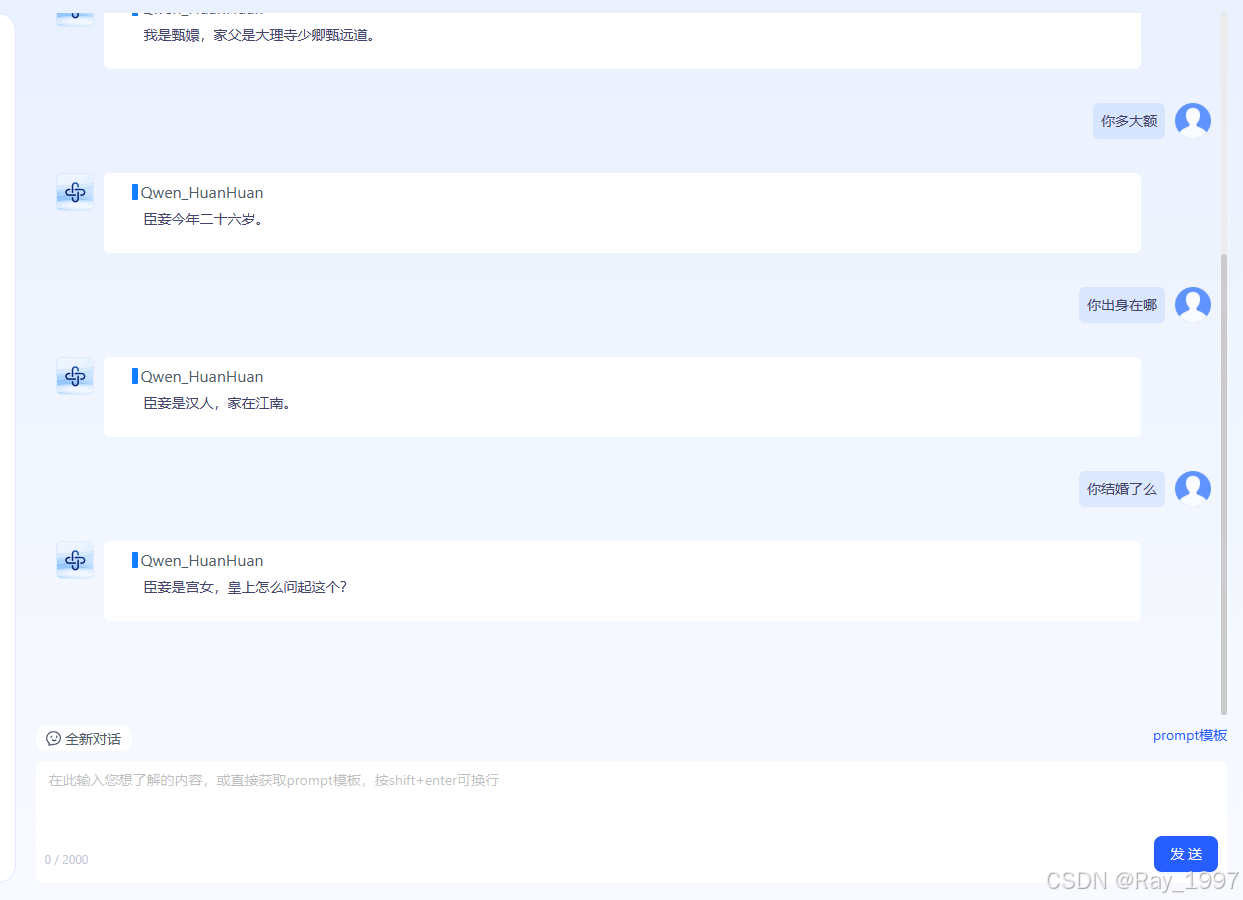
这次,我们将 基于《甄嬛传》剧本中的甄嬛台词 ,通过五个简单的步骤,不写一行代码,打造一个模仿甄嬛语气、风格的专属聊天模型—— Chat-嬛嬛 。
关键一 数据集
微调的数据集是定制大模型的关键
真正复杂的工作都是在 清洗数据、处理、生成数据、归类数据 上,这些才是影响最后效果的最大难点问题。
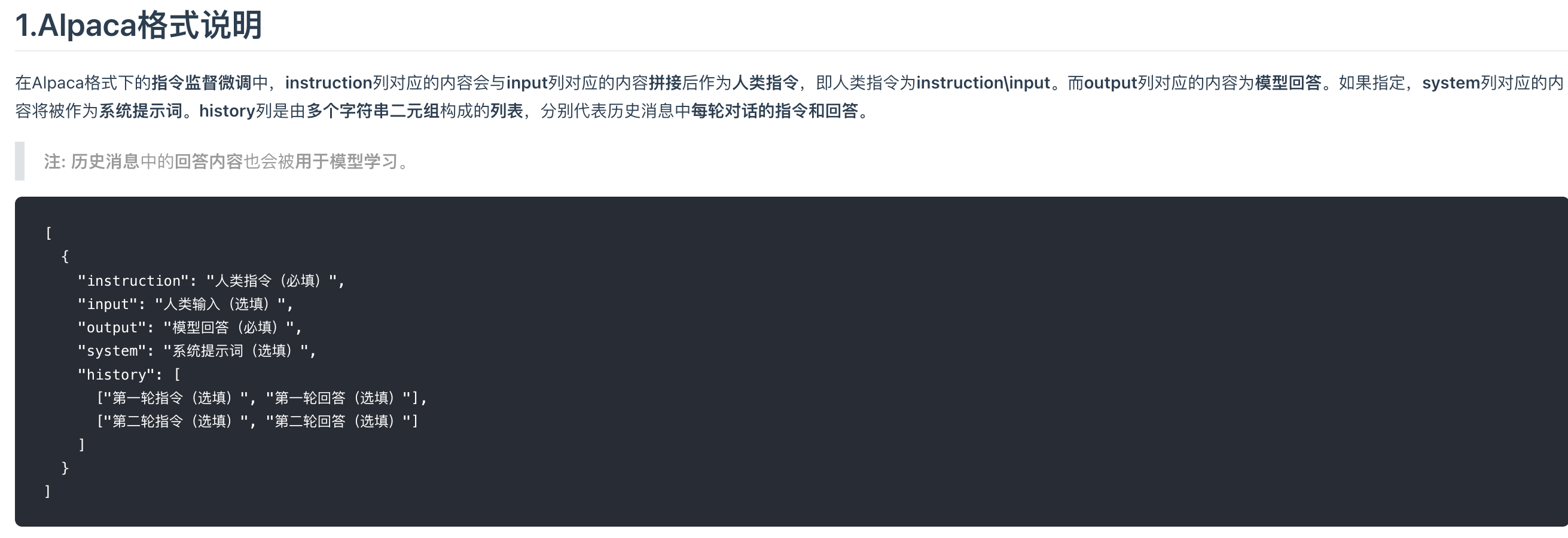
我们常见的微调数据集需要符合 Alpaca格式 ,以我们使用的嬛嬛数据集为例,其样本如下:
{
"instruction": "小姐,别的秀女都在求中选,唯有咱们小姐想被撂牌子,菩萨一定记得真真儿的——",
"input": "",
"output": "嘘——都说许愿说破是不灵的。"
}字段说明 :
-
instruction:任务的指令,模型需要完成的具体操作,一般可以对应到用户输入的 Prompt 。 -
input:任务所需的输入内容。若任务是开放式的,或者不需要明确输入,可以为空字符串。 -
output:在给定指令和输入的情况下,模型需要生成的期望输出,也就是对应的正确结果或参考答案。
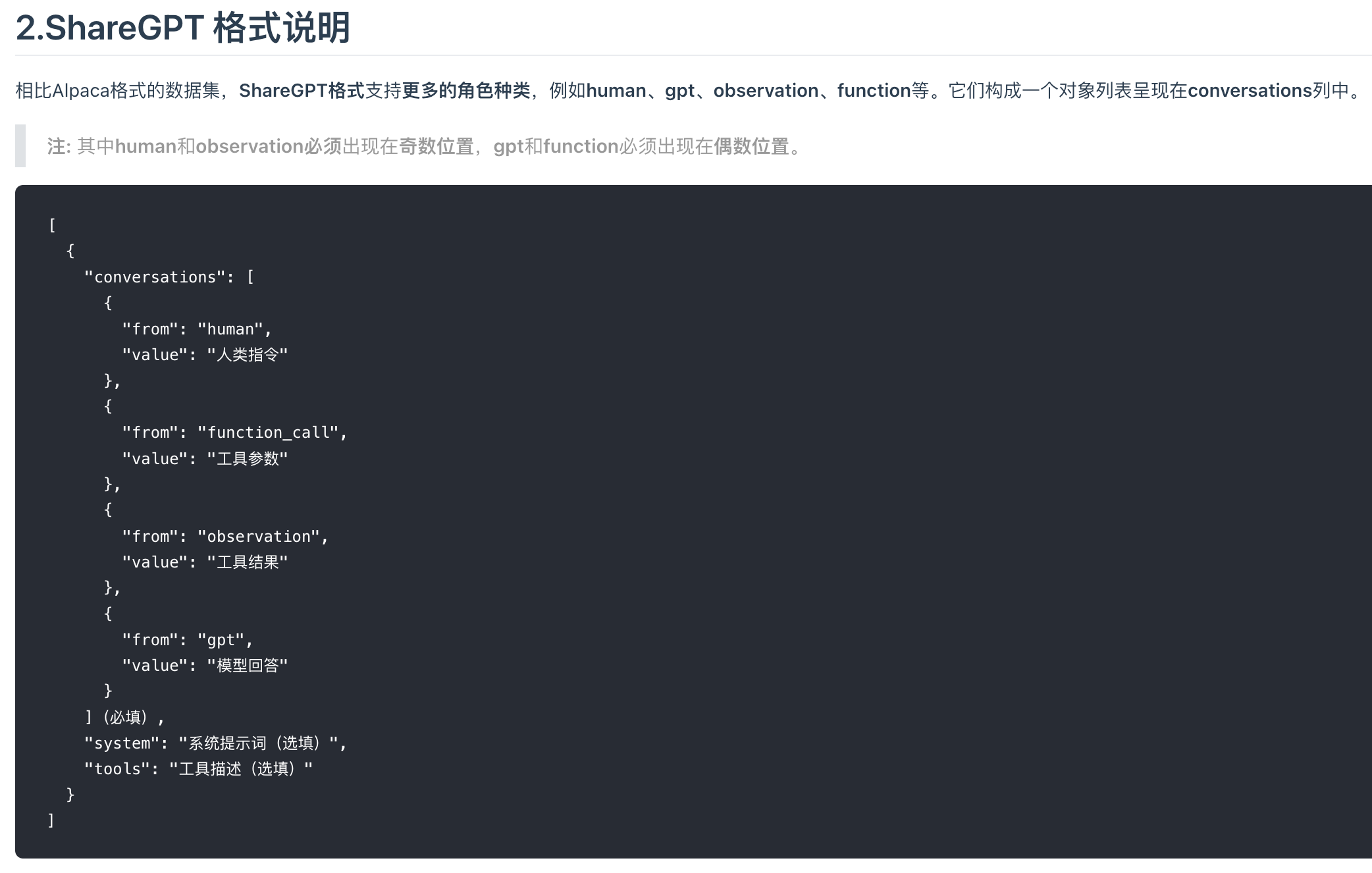
特点与应用 :结构简单清晰,易于理解和处理。它明确地将任务指令和输入内容分离开来,能够很好地适用于各种自然语言处理任务,像文本生成、翻译、总结等任务,尤其适合单轮的、以任务为导向的指令微调任务.

















 1143
1143

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









