







上文回顾
在上文深入源码分析HashMap到底是怎样将元素put进去的
我们着重分析了无参构造函数是如何创建map对象和HashMap是如何将第一个元素put进table的。
此篇重点
这篇我们将逐行代码分析
1、有参构造函数是如何创建map对象的
2、当元素增多导致扩容之后,元素是如何重新分布的
同样,为了方便读者复盘,我截取源码是尽量将行号带上。
jdk版本还是1.8
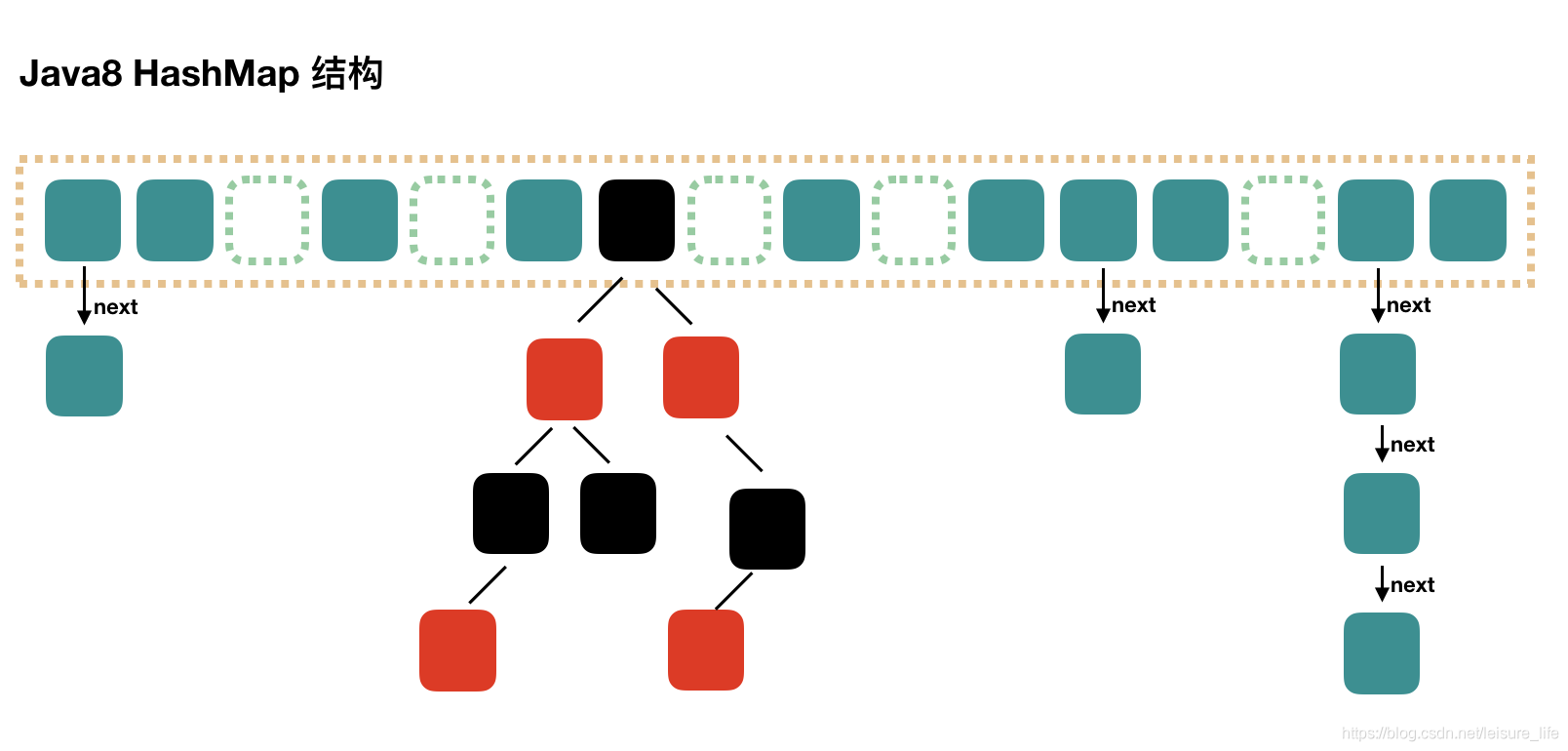
结构图
再重复一遍,HashMap的底层数据结构为数组+链表+红黑树的结构,放一个HashMap的结构示意图,有个大致印象。
解剖思路
创建一个有参构造函数,并往其中添加若干元素,直至触发扩容机制
为了方便方便计算hash值,key和value都选用比较小的字符串
关于调试键的使用请参照:IDEA调试键的说明,在此不再赘诉
调试代码
public static void main(String[] args) {
System.out.println("★★★★★★解剖开始★★★★★★");
HashMap<String, String> map = new HashMap<>(12);
map.put("1", "1");
map.put("2", "2");
map.put("3", "3");
map.put("4", "4");
// 实验key相同的情况
map.put("4", "D");
map.put("5", "5");
map.put("6", "6");
map.put("7", "7");
map.put("8", "8");
map.put("9", "9");
map.put("10", "10");
map.put("11", "11");
map.put("12", "12");
// 第一个扩容点
map.put("13", "13");
map.put("14", "14");
map.put("15", "15");
map.put("16", "16");
map.put("17", "17");
map.put("18" 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 359
359

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









