







多元线性回归(linear regression)
自变量:连续型数据,因变量:连续型数据
选自:周志华老师《机器学习》P53-55
思想:残差平方和达到最小时的关系式子即为所求,残差平方和:实际值和估计值之间差的平方和。
后续补充:求解方式1:手动推导,求解方式2:梯度下降。手动推到时矩阵不可逆如何加归纳偏好。
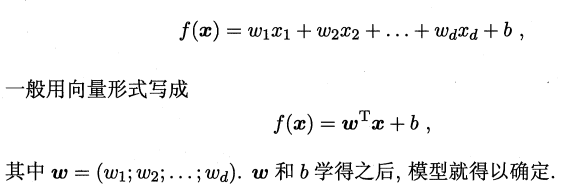
残差平方和达到最小:
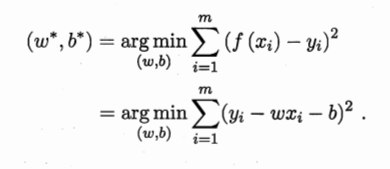
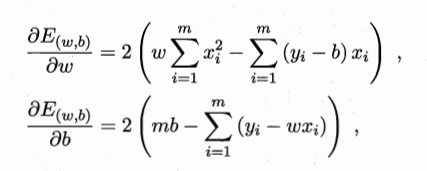
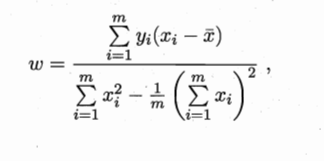

逻辑回归(logistic regression)
以下选自:王汉生《应用商务统计分析》第四章
(1)变量:连续型数据,因变量:离散型数据
(2)思想:假设了一个式子,计算事件发生的可能性。
令事件发生的可能性用Z表示:
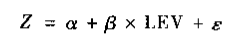
设定一个阈值c,使得:
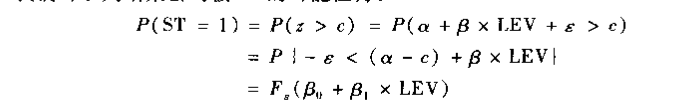
无论对F(t)的具体函数形式作任何假设,该假设都不可能完全反映真实情形,那么挑选那些“方便"的假设,假设服从正态分布。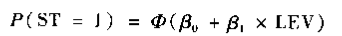 ,该模型称为probit模型,但是很多年前计算不够发达的时候,这种假设过于复杂,计算不出来,所以便产生了如下的公式:
,该模型称为probit模型,但是很多年前计算不够发达的时候,这种假设过于复杂,计算不出来,所以便产生了如下的公式:
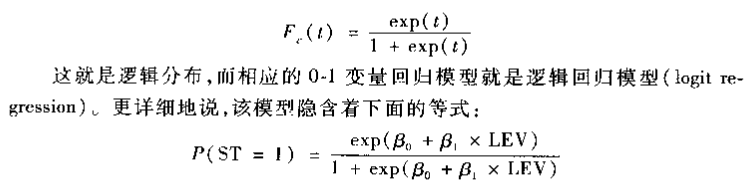
(3)效果评测方式:
TPR:召回率,有问题的预测为有问题的比例,即预测出来有问题的个数/所有有问题的个数:TP/(TP+FN)
FPR:误报,FP/(TN+FP),将正常的预测为有问题的数/所有正常的个数
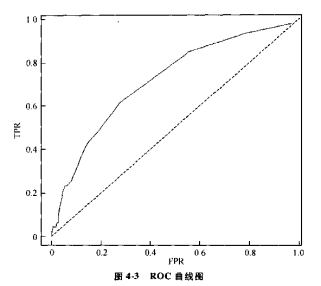
**同一个模型,找效果最好时的阈值:**设置不同的阈值后可以绘制ROC曲线,然后选取自己想要的召回率和误报平衡组合。ROC曲线同对角线(虚线)相比,永远是向上突起的。这说明TPR的取值必须高于FPR的取值,否则,这种预测方法是错误的。
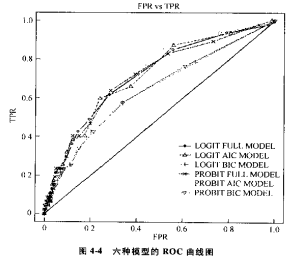
**不同模型之间的效果比较:**绘制不同模型的ROC曲线,选择最上面的曲线所代表的模型。
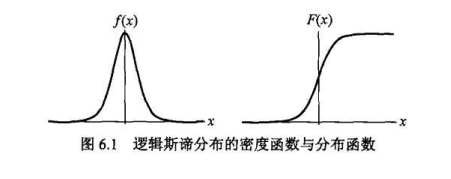
补充“公式构造符合常识”:选自李航《统计学习方法》P77-80
下图可见,t越大概率越大(t就是z,就是上面的线性函数值),t无穷大时候概率接近于1,t越接近负无穷概率值越接近0。
决策树(decision tree)
选自李航《统计学习方法》第五章
思想:找到一种划分方法,每次划分时,大大降低系统的混乱度,让系统信息明确。
3.1 知识点介绍:
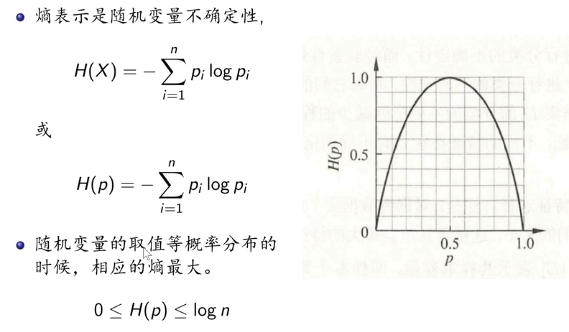
(1)熵:信息越混乱,随机变量的熵越大。
(2)信息增益

上面案例数据如下:


(3)信息增益比
特征A划分的信息增益/数据集合D中A特征的信息熵,下面截图(5.10)分母错误,作者在出版第二版的时候分母已经改为Ha(D)。
如数据集合D中”年龄“特征的信息熵:
**H年龄(D)=-(5/15)*log(5/15)-(5/15)log(5/15)-(5/15)log(5/15)=1.585
如数据集合D中”有工作“特征的信息熵:
**H有工作(D)=-(5/15)log(5/15)-(10/15)log(10/15)=0.918

3.2 算法介绍:
划分方法1:ID3算法
思想:信息增益越大,即熵降低的越多,就选此种划分方法。


**划分方法2:C4.5算法 **
思想:信息增益比越大,熵降低的越多,就选此时的划分方法。
以信息增益作为划分训练数据集的特征,存在偏向于选择取值较多的特征的问题。使用信息增益比(informationganrawo)可以对这一问题进行校正。

划分方法3:基尼指数
CART算法(分类和回归)


(1)分类

(2)回归

3.3 剪枝方法:
预剪枝:限定深度、设置阈值
后剪枝:最小误差剪枝、基于错误剪枝、降低错误剪枝、悲观错误剪枝
降低错误剪枝 (自下而上,使用测试集来剪枝。对每个结点,计算剪枝前和剪枝后的误判个数,若是剪枝有利于减少误判(包括相等的情况),则减掉该结点所在分枝。)
悲观错误剪枝(根据剪枝前后的错误率来决定是否剪枝。和rep不同之处在于,pep只需要训练集即可,不需要验证集,并且pep是自上而下剪枝的。)
后续补充:三者之间的区别,如何处理连续值。
随机森林(Random Forest,RF)
特征随机选择,有放回采样n个样本,构建很多个决策树,那么由各个决策树的结果怎么得到最终的结果呢。
选自:周志华老师《机器学习》P181-183
对于回归问题:


对于分类问题:


GBDT
XGboost
支持向量机(support vector machines,SVM)
**选自:周志华老师《机器学习》第六章 周志华老师《机器学习》的视频课程(主讲人:周老师) **
首先说下我自己的理解过程,然后再引入周老师西瓜书内容:
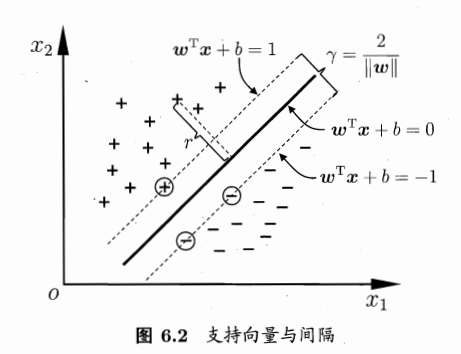
思想:找到一个平面,a)可以很好的区分不同类别的点(使得分类器的训练误差小,线性可分时要求训练误差为0),b)可以识别未知类别样本的类别(即多大程度上信任该分类器在未知样本上分类的效果。)


贴西瓜书对如上式子的推导过程:
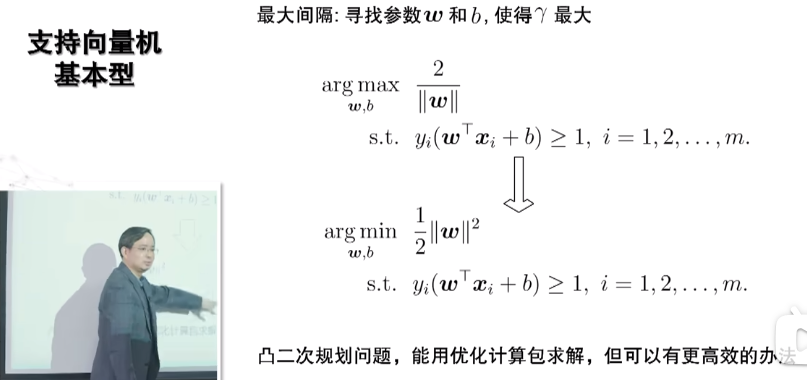

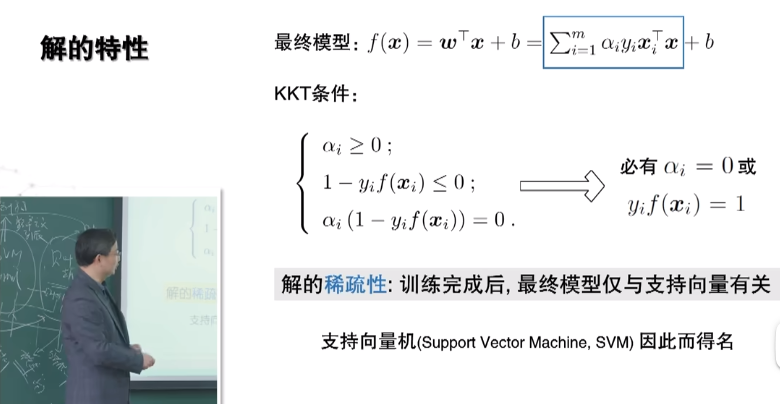
从下图最后的推导结果可知,要满足KKT条件,最优解时候的变量取值都为支持向量,也就是说最后决定这个模型的就是这些支持向量,支持向量机的名字由此而来。
线性不可分时,进行特征空间映射,使得可分:

内积不好计算,选用核函数来替代计算,理想状态下内积就等于选择的核函数,但确定性的最优解不好找,可以一个个核函数的试,在很多核函数中找一个最合适的。

朴素贝叶斯(naǐve Bayes)
思想:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,判定给概率最大的类别。在求解概率的时候假设各个属性之间独立同分布。
选自”算法杂货铺-分类算法之朴素贝叶斯分类“

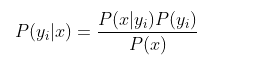
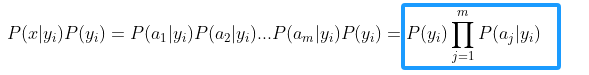
特征属性为离散值值可以直接数数求比例即可计算概率,特征属性为连续值时,用如下方法:

k近邻法(k-nearest neighbor,k-NN)
选自李航《统计学习方法》P37
可做分类和回归问题。分类思想:给定一个有标签的训练数据集,对新的实例,根据k个最近邻的训练实例的类别,通过多数表决等方式进行预测。

补充“距离加权表决”:选自Pang-Ning Tan等著,范明等译《数据挖掘导论完整版_人民邮电出版社》P138

后续补充:knn的缺陷,如计算量大,噪声敏感,补充如何降低计算开销。
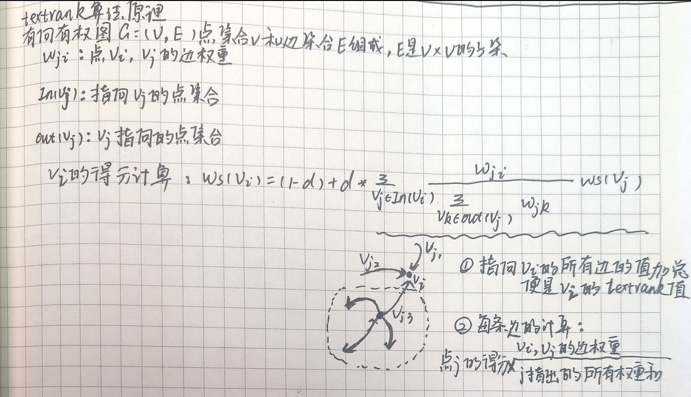
textrank
思想:指向点v(i)的所有边的值加总便是v(i)的textrank值。每条边上值的计算,如v(j)和v(i)边值的计算为:
w=v(i)和v(j)边权重/v(j)指出的所有权重和
score=v(j)的textrank
w*score便为所求。
k均值(k-means)
选自Pang-Ning Tan等著,范明等译《数据挖掘导论完整版_人民邮电出版社》P310
算法思想:
















 99
99











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









