






来源:大邓和他的Python
SHAP机器学习模型解释库
想象一下,你正试图训练一个机器学习模型来预测广告是否被特定的人点击。在收到关于某人的一些信息后,模型预测某人会不会点击广告。
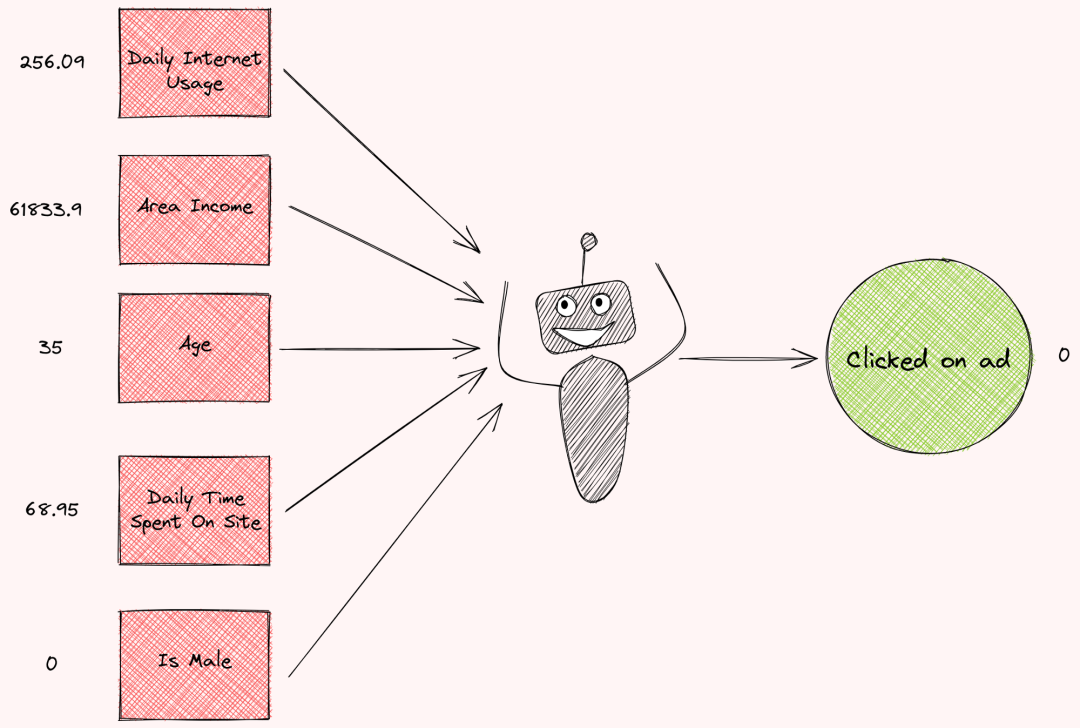
但是为什么模型会输出这样的预测结果呢?每个特征对预测的贡献有多大?如果您能看到一个图表,显示每个特征对预测的贡献程度,如下所示,不是很好吗?
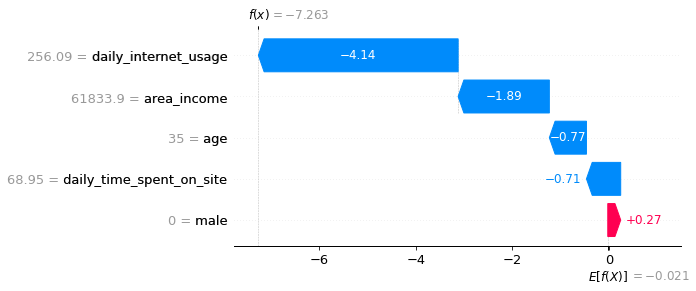
Shapley值就能起到特征权重测度的作用。
Shapley值是什么?
Shapley值是博弈论中使用的一种方法,它涉及公平地将收益和成本分配给在联盟中工作的行动者。由于每个行动者对联盟的贡献是不同的,Shapley值保证每个行动者根据贡献的多少获得公平的份额。

小案例
Shapley值被广泛地应用于求解群体中每个工人(特征)的贡献问题。要理解Shapley值的作用,让我们想象一下贵公司刚刚做了A/B测试,他们在测试广告策略的不同组合。
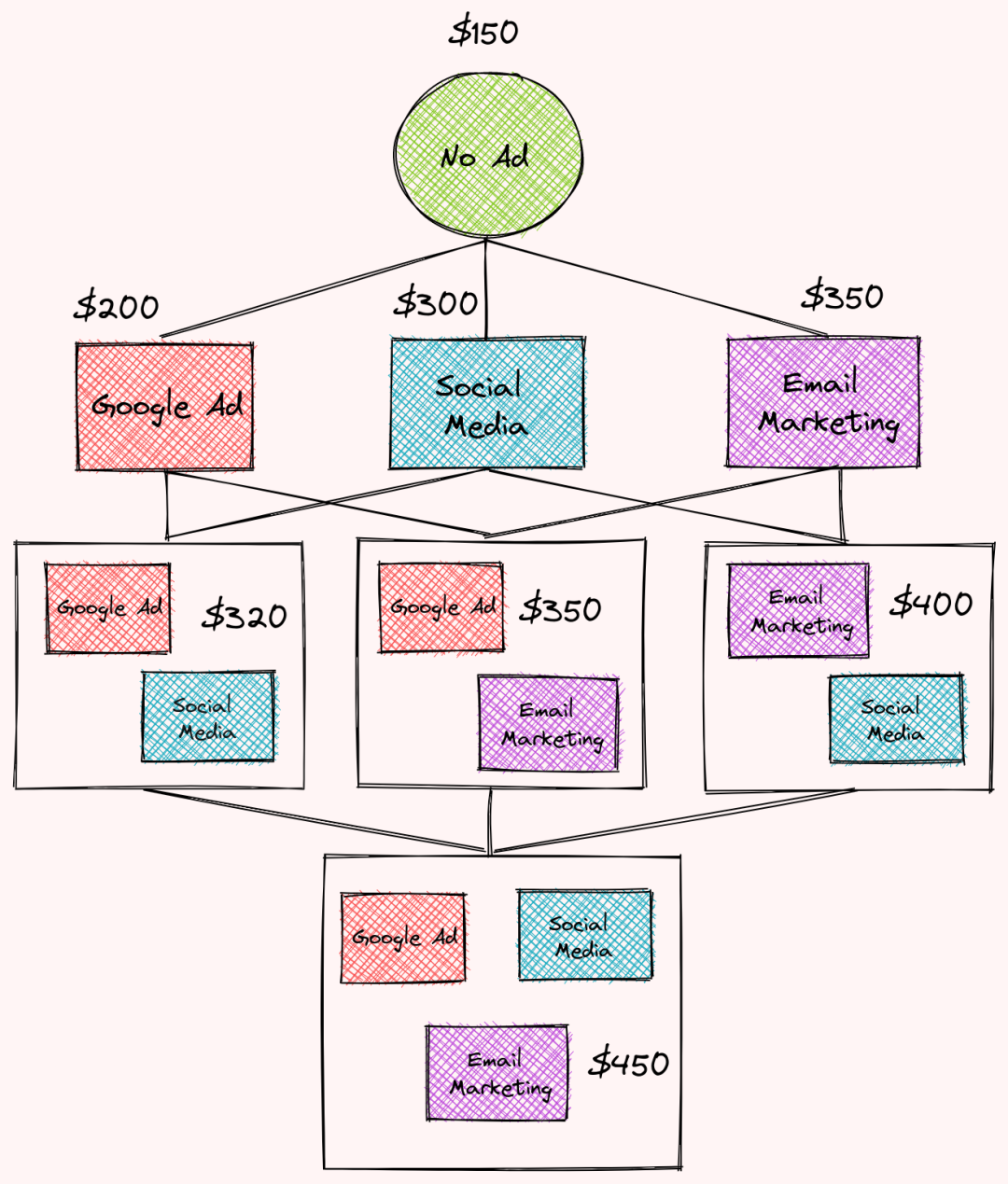
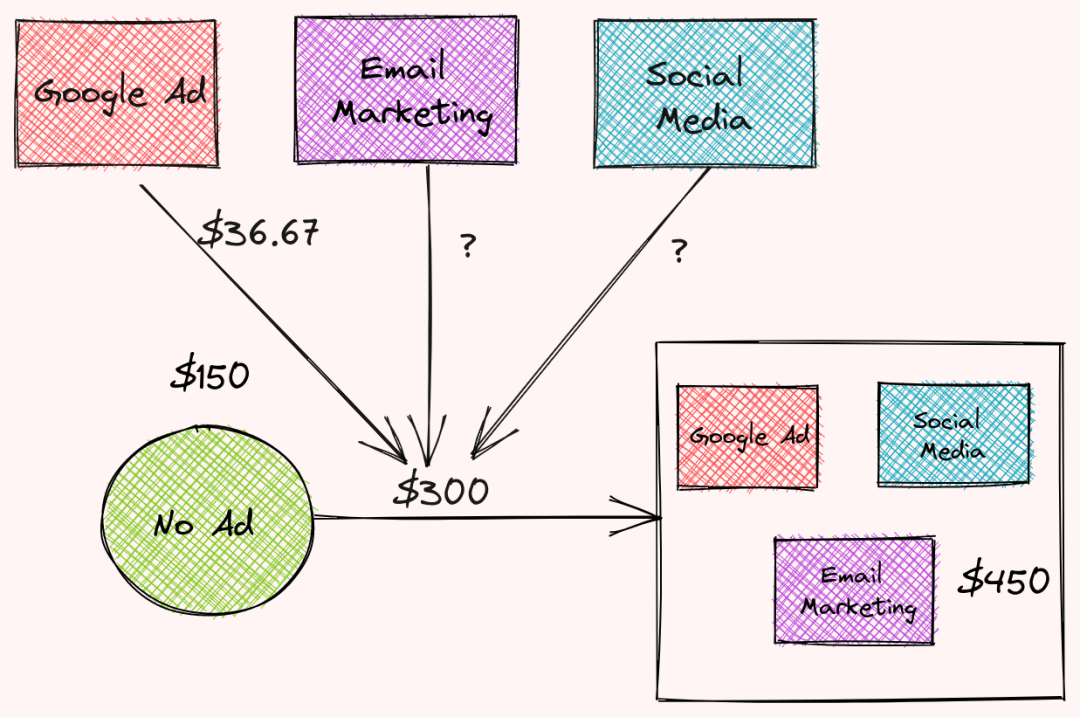
每个策略在特定月份的收入是:
无广告:150美元
社交媒体:300美元
谷歌广告:200美元
电子邮件营销:350美元
社交媒体和谷歌广告:320美元
社交媒体和电子邮件营销:400美元
谷歌广告和电子邮件营销:350美元
电子邮件营销,谷歌广告和社交媒体:450美元
使用三则广告与不使用广告的收入相差300美元,每则广告对这一差异有多大的贡献?
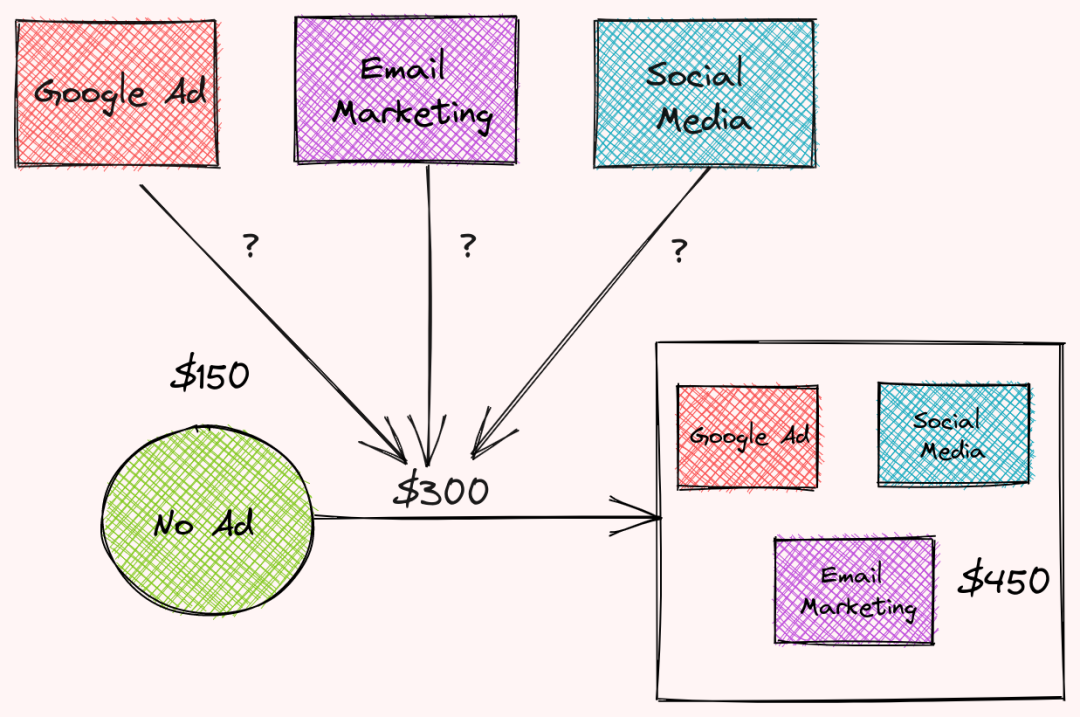
我们可以通过计算每一类广告的Shapley值来计算谷歌广告对公司收入的总贡献入手,通过公式可以计算出Google广告的总贡献:

让我们找到Google广告的边际贡献及其权重。
寻找谷歌广告的边际贡献
第一,我们将发现谷歌广告对以下群体的边际贡献:
无广告
谷歌广告+社交媒体
谷歌广告+电子邮件营销
谷歌广告+电子邮件营销+社交媒体
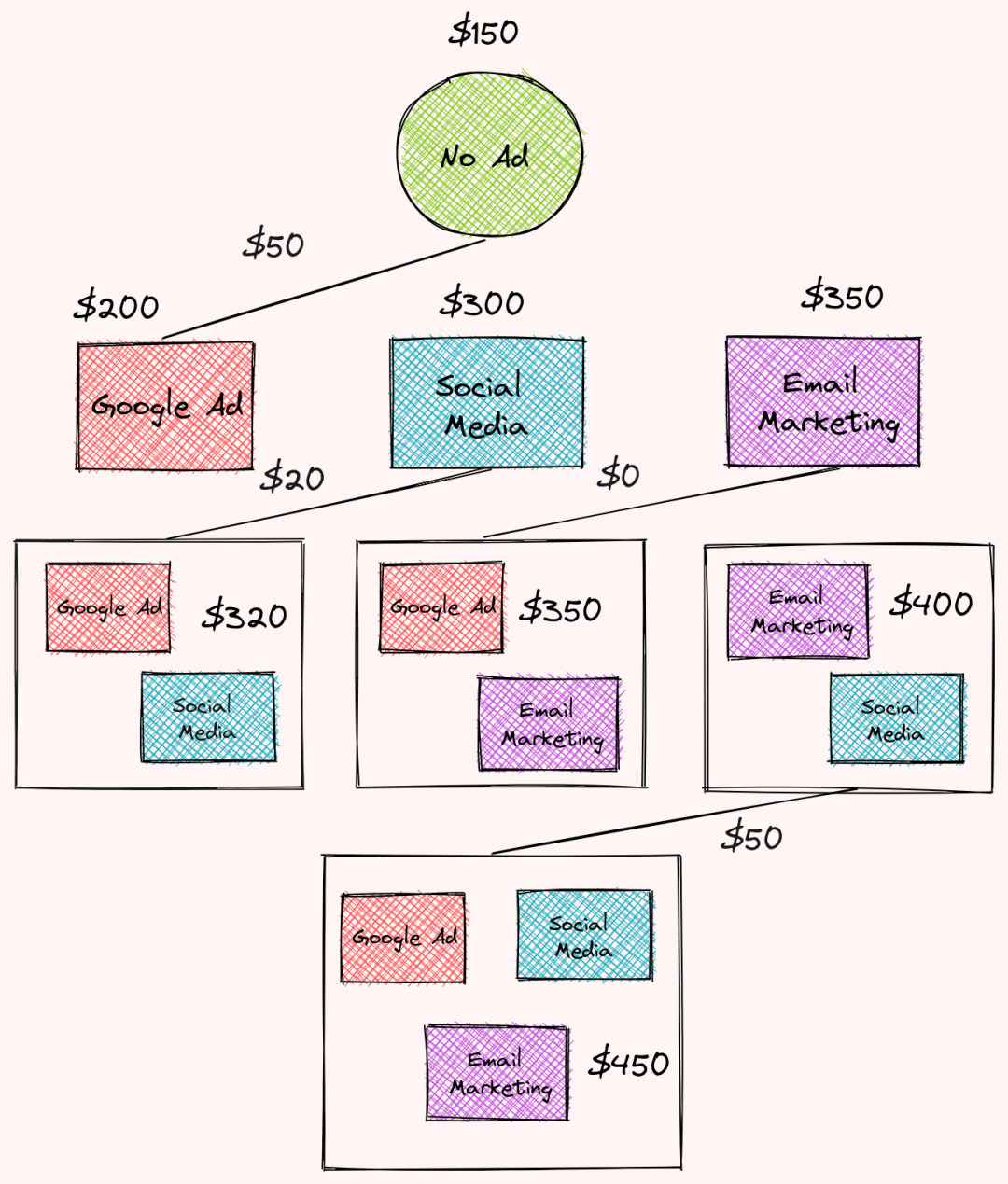
Google广告 对 无广告 的边际贡献是:

谷歌广告 对 谷歌广告&社交媒体组合 的边际贡献是:
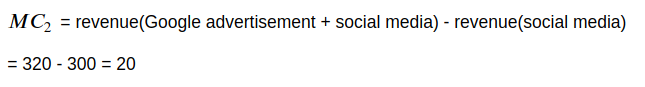
谷歌广告 对 谷歌广告&电子邮件营销组合 的边际贡献是:

谷歌广告 对 谷歌广告、电子邮件营销和社交媒体组合 的边际贡献是:

发现权重
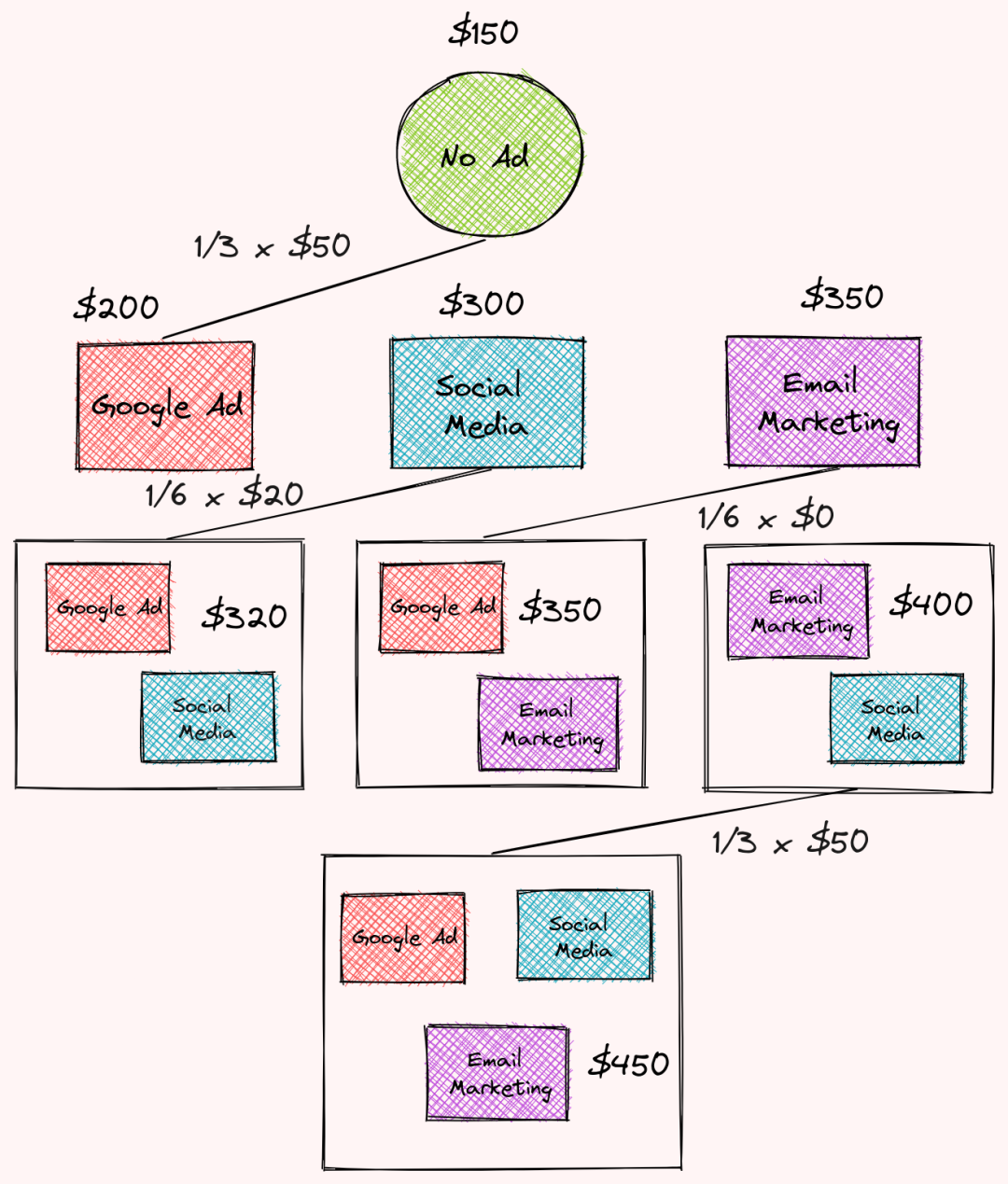
为了发现权重,我们将把不同广告策略的组合组织成如下多个层次,每个层次对应于每个组合中广告策略的数量。
然后根据每个层次的边数分配权重,我们看到了这一点:
第一级包含3条边,因此每个边的权重为1/3
第二级包含6条边,因此每条边的权重将为1/6
第三级包含3条边,因此每条边的权重将为1/3

发现Google广告的总贡献
根据前面的权重和边际贡献,我们已经可以找到Google广告的总贡献!
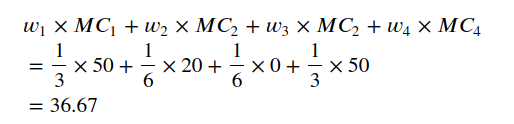
酷!所以谷歌广告在使用3种广告策略与不使用广告的总收入差异中贡献了36.67美元。36.67是Google广告的Shapey值。
重复以上步骤,对于另外两种广告策略,我们可以看出:
电子邮件营销贡献151.67美元
社交媒体贡献116.67美元
谷歌广告贡献36.67美元
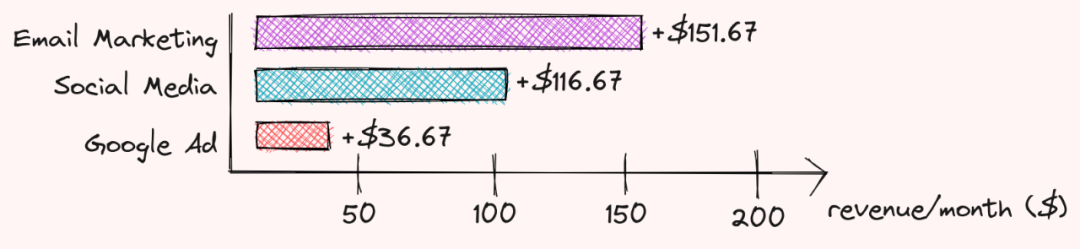
他们共同出资300美元,用于使用3种不同类型的广告与不使用广告的区别!挺酷的,不是吗? 既然我们理解了Shapley值,那么让我们看看如何使用它来解释机器学习模型。
SHAP-在Python中解释机器学习模型
SHAP是一个Python库,它使用Shapley值来解释任何机器学习模型的输出。
安装SHAP
!pip3 install shap训练模型
为了理解SHAP工作原理,我们使用Kaggle平台内的advertising广告数据集。
import pandas as pd
df = pd.read_csv("advertising.csv")
df.head()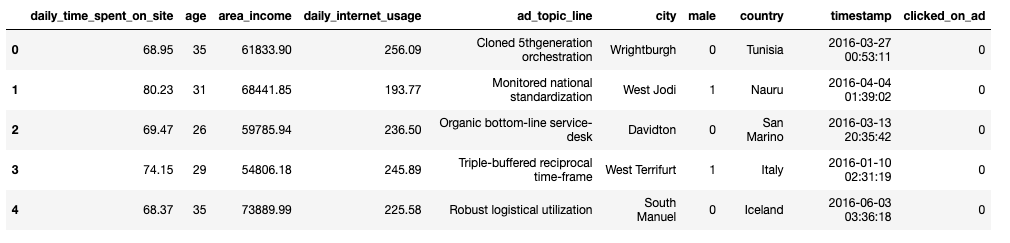
我们将建立一个机器学习模型, 该模型根据用户个人特质信息来预测其是否点击广告。
我们使用Patsy将DataFrame转换为一组特征和一组目标值:
from patsy import dmatrices
from sklearn.model_selection import train_test_split
y, X = dmatrices(
"clicked_on_ad ~ daily_time_spent_on_site + age + area_income + daily_internet_usage + male -1",
data=df,
)
X_frame = pd.DataFrame(data=X, columns=X.design_info.column_names)把数据分为测试集和训练接
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=7)接下来使用XGBoost训练模型,并做预测
import xgboost
model = xgboost.XGBClassifier().fit(X_train, y_train)
y_predicted = model.predict(X_test)为了查看模型表现,我们使用F1得分
from sklearn.metrics import f1_score
f1 = f1_score(y_test, y_predicted)
f10.9619047619047619太好了!
解释该模型
该模型很好地预测了用户是否点击广告。但它是如何得出这样的预测的? 每个特征对最终预测与平均预测的差异贡献了多少?
注意,这个问题与我们在文章开头论述的问题非常相似。
因此,寻找每个特征的Shapley值可以帮助我们确定它们的贡献。得到特征i的重要性的步骤与之前类似,其中i是特征的索引:
获取所有不包含特征i的子集
找出特征i对这些子集中每个子集的边际贡献
聚合所有边际贡献来计算特征i的贡献
若要使用SHAP查找Shapley值,只需将训练好的模型插入shap.Explainer
import shap
explainer = shap.Explainer(model)
shap_values = explainer(X_frame)ntree_limit is deprecated, use `iteration_range` or model slicing instead.SHAP瀑布图
可视化第一个预测的解释:
#第一条记录是未点击
shap.plots.waterfall(shap_values[0])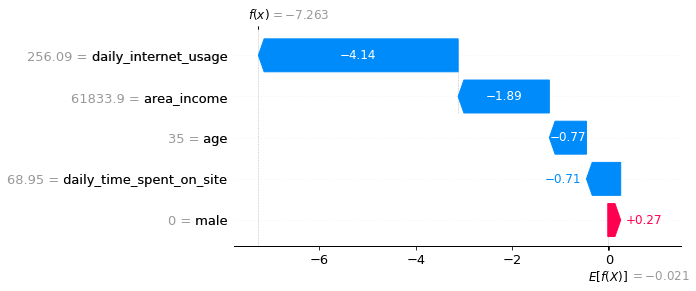
啊哈!现在我们知道每个特征对第一次预测的贡献。对上图的解释:

蓝色条显示某一特定特征在多大程度上降低了预测的值。
红条显示了一个特定的特征在多大程度上增加了预测值。
负值意味着该人点击广告的概率小于0.5
我们应该期望总贡献等于预测与均值预测的差值。我们来验证一下:
总贡献等于预测与均值预测的差值.png)
酷!他们是平等的。
可视化第二个预测的解释:
#第二条记录也是未点击
shap.plots.waterfall(shap_values[1])
SHAP摘要图
我们可以使用SHAP摘要图,而不是查看每个单独的实例,来可视化这些特性对多个实例的整体影响:
shap.summary_plot(shap_values, X)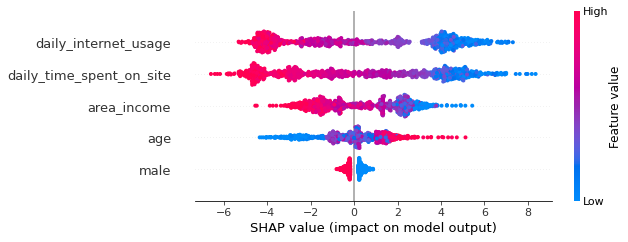
SHAP摘要图告诉我们数据集上最重要的特征及其影响范围。
从上面的情节中,我们可以对模型的预测获得一些有趣的见解:
用户的 daily_internet_usage 对该用户是否点击广告的影响最大。
随着daily_time_spent_on_site的增加,用户点击广告的可能性降低。
随着area_income的增加,用户点击广告的可能性降低。
随着age的增长,用户更容易点击广告。
如果用户是male,则该用户点击广告的可能性较小。
SHAP条形图
我们还可以使用SHAP条形图得到全局特征重要性图。
shap.plots.bar(shap_values)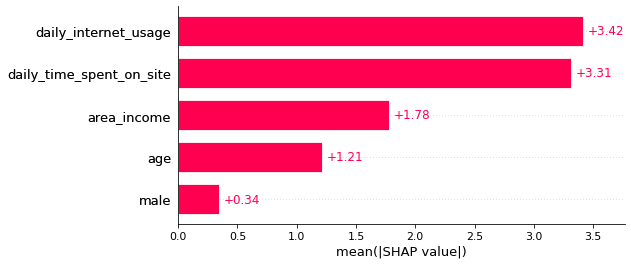
很酷!
结论
恭喜你!您刚刚了解了Shapey值以及如何使用它来解释一个机器学习模型。希望本文将提供您使用Python来解释自己的机器学习模型的基本知识。
下载代码
链接:https://pan.baidu.com/s/1R8i-9F7n8IhqdvXkpYIMCg 密码:iqkt
原文作者: khuyentran
原文链接 https://towardsdatascience.com/shap-explain-any-machine-learning-model-in-python-24207127cad7
---------End---------
顺便给大家推荐下我的微信视频号「Python数据之道」,欢迎扫码关注。

















 3022
3022

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









