






建模演练题部分摘要:
美国媒体彭博社发布的新冠疫情韧性排行榜,根据开放进程、现阶段疫情和生活质量三类指标对世界主要经济体防疫效果进行排序。我们从该榜单合理性出发,新增指标,通过主客观赋权法,利用TOPSIS方法,构建了新的世界主要国家防疫效果综合评价体系。通过对该问题的求解,可作为群众理性看待社会上疫情相关排行榜的研究支持。
我们通过彭博社官方发布的《方法论》,提取出指标代表的意义以及具体的评价方法,进而发现彭博社所发布的排名更偏向于近期抗疫情况的体现,且其评价指标权重的分配存在不合理之处,现阶段疫情的占比只有1/3,导致其最终的排名出现了与公众认知不符的情况。由此,我们建立起新的防疫效果综合评价体系,首先确立了新的评价指标,使用主客观综合赋权法对专家排序法和熵权法得到的权重进行线性集成,而后通过逼近理想解的排序法(TOPSIS),完成了对世界主要各国防疫效果的评分和排序。最终得到中国防疫效果排名第一,以色列位列第二。
指标选取
在对彭博社原有指标进行筛选的基础上,我们加入了新的指标,选取结果如表所示。
表6-1抗疫效果综合评价指标选取表
| 一级指标 | 二级指标 | 指标说明 |
| 整体疫情 | 疫苗覆盖率 | 当前疫苗剂量可覆盖的人口百分比 |
| 累计确诊人数/10万 | 每十万人中累计确诊的人数 | |
| 累计死亡人数/100万 | 每一百万人中累计死亡的人数 | |
| 累计治愈患者数/10万 | 每十万患者中累计治愈的人数 | |
| 现阶段疫情 | 月感染人数/10万 | 该月每十万人中感染的人数 |
| 月病死率 | 该月病死人数与确诊人数的比值 | |
| 最高月新增患者降比 | 该月新增患者数相对于历史最高月新增患者数的降低比例 | |
| 日核酸检测阳性率 | 体现当地是否进行了足够的检测 | |
| 复苏进程 | 人口流动率 | 与2019年同期相比,日常人员流动情况 |
| 封锁程度 | 该国的社会经济活动受到限制的程度 | |
| 2021年GDP预测增长率 | 该国2021年生产总值增长的预测 | |
| 2020年GDP增长率 | 该国2020年生产总值增长的实况 |
在新的评定体系中,我们沿用疫苗覆盖率、累计死亡人数/100万、月感染人数/10万、月病死率、月核酸检测确诊率、人口流动率、封锁程度与2020年GDP增长率共八个指标。
除此之外,我们新增了两个关于整体疫情的累计指标——累计确诊人数/10万和累计治愈患者数/10万,数据分别由网站Our World in Data中各国累计确诊人数和网站WorldOmeters中公布的各国累计治愈患者数分析处理得到,分别表示疫情发生以来各国每十万人中累计确诊的人数与每十万患者中累计治愈的人数,这更能体现在整个抗疫情过程中各国的表现。
新增了一个关于现阶段疫情的指标,即该月与最高月新增患者数的降低比率,数据由网站Our World in Data中各月新增患者数分析处理得到。用该国疫情发生后,最高月新增患者数与该月新增患者数的差值与最高月新增患者数的比值表示,其中最高月为除该月外,新增患者数最高的月份,此指标为正向指标,意在解释此阶段疫情与最高峰时期疫情的关系,可以展示该国现阶段疫情治理的有效程度。此指标的值大于0,说明该国现阶段疫情相对于高峰时期的疫情有所下降,此指标的值小于0,说明该国的疫情仍在加剧。即其数值越大,说明疫情治理有效度越好。
新增了一个关于复苏进程的经济指标,即2020年GDP增长率,数据来源于世界货币基金组织2021年4月发布的《世界经济展望》,表示该国2020年在疫情影响下,生产总值增长的实况。此指标意在解释各国在2020年正值疫情爆发之时经济的增长水平。
其中,我们通过对清风数学建模课件的学习,使用了熵权法和TOPSIS法,其具体应用如下:
熵权法:
(2)熵权法
假设有n个要评价的对象,m个评价指标构成的矩阵如下:
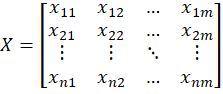
首先,对矩阵X进行标准化。由于输入的矩阵中存在负数,故标准化的公式为
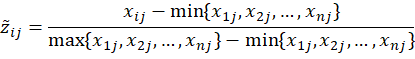
标准化后得到矩阵z。
接着,计算第j项指标下第i个样本所占的比重(并将其看作相对熵计算中用到的概率),公式为:
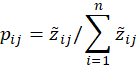
验证可得:(即保证了每一个指标所对应的概论和为1)。
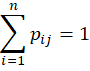
然后,计算各个指标的信息熵,并计算信息效用值,归一化得到每个指标的熵权。
对于第j个指标而言,其信息熵的计算公式为:
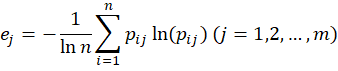 对于第j个指标而言,其信息效用值的计算公式为:
对于第j个指标而言,其信息效用值的计算公式为:
![]()
将信息效用值进行归一化,即得到每个指标的熵权:
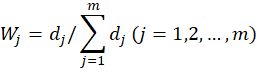
通过使用MATLAB进行上述步骤的计算,各指标及其权重如表6-5
表6-5
| 指标 | 权重 |
| 月感染人数 | 0.041 |
| 月死亡率 | 0.016 |
| 最高月新增患者降比 | 0.031 |
| 核酸检测确诊率 | 0.042 |
| 累计死亡人数 | 0.027 |
| 累计确诊人数 | 0.059 |
| 累计治愈人数 | 0.040 |
| 疫苗覆盖率 | 0.245 |
| 人口流动率 | 0.085 |
| 封锁程度 | 0.133 |
| 2020GDP增长率 | 0.153 |
| 2021GDP预测增长率 | 0.128 |
TOPSIS:
TOPSIS 法(逼近理想排序法)是系统工程中一种多目标决策方法,找出有限方案中的最优与最劣方案,当某个可行解方案最靠近最优方案同时又远离最劣方案,这个方案解的向量集就是最优影响评价指标。
Step1:将原始矩阵正向化,将极小型指标转换为极大型指标。
Setp2:将正向化后的矩阵标准化,消除不同指标量纲的影响,X为正向化后的矩阵。
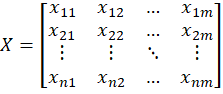
对其标准化的矩阵记为Z,Z中的每一个元素:
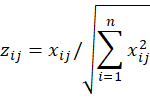
标准化矩阵:
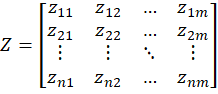
Step3:
定义最优向量:
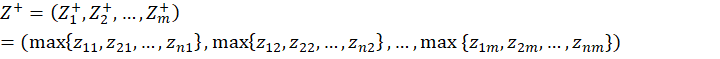
定义最劣向量:
![]()
![]()
Step4:计算所选取的国家的指标与最优向量的欧式距离:
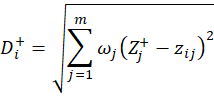
和最劣向量的欧式距离

Step5:计算出第i(i=1,2,…,n)个评价对象得分:(由于未标准化后得分更加显著,所以我们选择不对最终得分进行标准化)
综合得分![]()


TOPSIS算法流程图
对于综合得分Si的解释:
根据问题一指针体系建立的标准,对资料进行正向化和标准化处理后,可以发现与最优值的相对接近程度Si表示各国应对新冠肺炎的能力,而且当Si的得分越大,表示该国应对新冠肺炎疫情的表现越好。
我们通过MATLAB编程求解,得到最终结果如下:
表6-7各国评价综合得分
| 排名 | 国家 | 分数 |
| 1 | 中国 | 60.72 |
| 2 | 以色列 | 60.16 |
| 3 | 马来西亚 | 58.8 |
| 4 | 新西兰 | 57.71 |
| 5 | 丹麦 | 56.81 |
| 6 | 波兰 | 56.32 |
| 7 | 荷兰 | 56.29 |
| 8 | 埃及 | 55.57 |
| 9 | 韩国 | 55.56 |
| 10 | 挪威 | 55.47 |
| 11 | 阿联酋 | 54.9 |
| 12 | 土耳其 | 54.53 |
| 13 | 芬兰 | 54.23 |
| 14 | 罗马尼亚 | 53.79 |
| 15 | 美国 | 53.75 |
| 16 | 尼日利亚 | 53.7 |
| 17 | 瑞士 | 53.31 |
| 18 | 澳大利亚 | 52.38 |
| 19 | 爱尔兰 | 52.13 |
| 20 | 比利时 | 52.03 |
| 21 | 瑞典 | 52.02 |
| 22 | 捷克共和国 | 51.54 |
| 23 | 德国 | 50.99 |
| 24 | 沙特 | 50.61 |
| 25 | 法国 | 49.61 |
| 26 | 希腊 | 49.55 |
| 27 | 奥地利 | 48.83 |
| 28 | 加拿大 | 48.78 |
| 29 | 巴基斯坦 | 47.99 |
| 30 | 孟加拉国 | 47.92 |
| 31 | 俄罗斯 | 47.88 |
| 32 | 新加坡 | 47.8 |
| 33 | 伊朗 | 47.74 |
| 34 | 英国 | 47.6 |
| 35 | 日本 | 47.48 |
| 36 | 葡萄牙 | 47.39 |
| 37 | 意大利 | 47.11 |
| 38 | 墨西哥 | 47.05 |
| 39 | 伊拉克 | 47 |
| 40 | 西班牙 | 46.46 |
| 41 | 印度尼西亚 | 44.66 |
| 42 | 智利 | 43.35 |
| 43 | 巴西 | 42.28 |
| 44 | 南非 | 41.71 |
| 45 | 印度 | 41.4 |
| 46 | 越南 | 40.5 |
| 47 | 泰国 | 40.12 |
| 48 | 菲律宾 | 38.13 |
| 49 | 秘鲁 | 37.01 |
| 50 | 哥伦比亚 | 33.24 |
| 51 | 阿根廷 | 31.98 |
清风数学建模的视频讲解清晰易懂,十分有利于新手对于数学建模的学习,十分推荐。















 635
635











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









