







1、评价的决策层不能太多,太多的话n会很大,判断矩阵和一致矩阵差异可能会很大。 2、层次分析法真正的核心是判断矩阵的填写,但是判断矩阵受人为因素比较大,所以最后计算得出的权重也比较主观。 3、如果决策层中指标的数据是已知的,那么我们如何利用这些数据来使得评价更加准确呢(就是每个方案层关于各指标的得分已知,不用通过判断矩阵去求具体的结果) |
将所有的指标转化为极大型称为指标正向化(最常用) |
| 指标名称 | 指标特点 | 例子 |
| 极大型(效益型)指标 | 越大(多)越好 | 成绩、企业利润 |
| 极小型(成本型)指标 | 越小(少)越好 | 费用、污染程度 |
| 中间型指标 | 越接近某个值越好 | 水质量评估PH值 |
| 区间型指标 | 落在某个区间最好 | 体温、营养物的含量 |
| 极小型指标→极大型指标 公式: 如果所有元素都为正数,也可以使用 | |
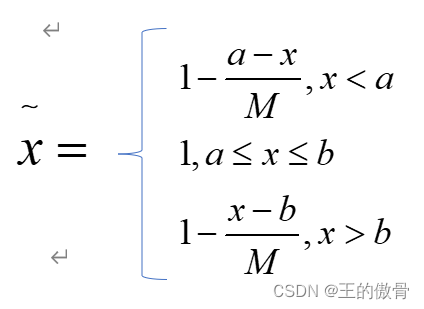
| 中间型指标→极大型指标 中间型指标:指标值不要太大也不要太小,取某特定值最好 (水质量评估PH的值) {
| |
| 区间型指标→极大型指标
| |
指标标准化处理标准化的目的:消除不同指标量纲的影响 | |
| 每一个元素/ | |
计算得分并对结果进行归一化 | |
| 定义第i(i = 1,2,…,n)个评价对象与最大值的距离为:
|
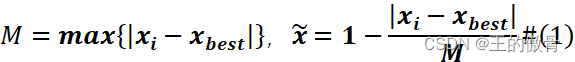
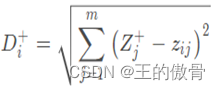
| 定义第i(i = 1,2,…,n)个评价对象与最小值的距离为:
|
| 评价对象未归一化后的评价得分: |
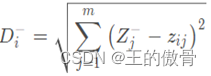
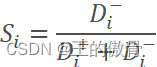

| 很明显0<Si 最后在对未归一化的得分进行归一化。
具体流程图如下所示:
TOPSIS法的评估
|

















 2250
2250











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











