







版权声明:本文为原创文章,未经博主允许不得用于商业用途。
词法分析
1、基本概念
- 词法单元(Token):由词法单元名和属性值(可选)组成。其中属性值用于区分同一符号表中重复的同种词法单元。
- 模式(Pattern):描述一类词法单元可能具有的形势。
- 词素(Lexeme):源程序中的一个字符序列,可以和某个词法单元的模式匹配,并被词法分析器识别为该词法单元的一个实例。
可以看出,词法单元、模式和词素是"一对一对多"的关系,下图给出了c语言词法一个示例:

2、概述
词法分析在编译器中位于以下位置:

从图片上可知,词法分析将字符串形式的源程序解析为词法单元,并且生成符号表。具体来说,词法分析器具有如下作用:
-
读入字符流,组成词素,输出词法单元序列
-
过滤空白、换行、制表符、注释等
-
将词素添加到符号表中
-
将编译器生成的错误信息和在源程序中的位置联系起来(后续)
从作用可以看出,其工作流程分为扫描阶段(去除注释、多余的空白符)和词法分析(生成词法单元)阶段。
3、正则表达式
这里所说的正则表达式为最基本的正则表达式,只包含如下四种运算:并(a|b)、连接(ab)、Kleene闭包(a*)、正闭包(a+)。其中运算优先级为{‘*’,‘+’}>‘连接’>‘|’。
递归定义
正则表达式可以通过递归定义,设正则表达式集合为R,则
- 空串 ϵ ∈ R \epsilon\in R ϵ∈R, ∀ a ∈ Σ , a ∈ R \forall a\in \Sigma, a\in R ∀a∈Σ,a∈R
- ∀ r , s ∈ R , ( r ) , ( r ) ( s ) , ( r ) ∣ ( s ) , ( r ) ∗ , ( r ) + ∈ R \forall r,s\in R,(r),(r)(s),(r)|(s),(r)^*,(r)^+\in R ∀r,s∈R,(r),(r)(s),(r)∣(s),(r)∗,(r)+∈R
正则定义
为了书写方便,主流语言常常使用了正则定义预定义了常用正则串。正则定义规则如下:
按照如下形式定义串:
d
1
→
r
1
,
d
2
→
r
2
,
d
3
→
r
3
,
.
.
.
d_1\rightarrow r_1,\ d_2\rightarrow r_2,\ d_3\rightarrow r_3,...
d1→r1, d2→r2, d3→r3,...
其中满足:
- d i d_i di为新符号,不在符号集合 Σ \Sigma Σ中,且各不相同
- r i r_i ri是定义在字母表$\Sigma \bigcup {d_1,d_2,…,d_{i-1}} $上的正则表达式。(避免递归定义)
有穷自动机
比正则表达式更加优秀的语言表示方法是有穷自动机。所有的正则表达式都可以用有穷自动机来表示。
一个有穷自动机包含:
- 有限的状态集合 S S S
- 有限的符号集合 Σ \Sigma Σ
- 转移函数(可以用状态表表示)
- 初始状态 s 0 s_0 s0(有些有穷自动机可以有多个)
- 接受状态集合 F F F
有穷自动机分为两类:
- 不确定的又穷自动机(Nondeterministic Finite Automate, NFA),即对状态图中边上的标号没有限制,特别的,同一符号可以出现在离开同一状态的多条边上,且空串 ϵ \epsilon ϵ可以作为符号出现在边上。
- 确定的有穷自动机(Deterministic Finite Automate,DFA),对于每个状态及一个符号有且只有一条边。
算法1:NFA到DFA
算法如下:

其中, ϵ − c l o s u r e ( s ) \epsilon-closure(s) ϵ−closure(s)表示NFA中通过空串符可以从s状态到达的状态集合, m o v e ( T , a ) move(T,a) move(T,a)表示T状态接收到a字符后可达的状态集合, D t r a n [ T , a ] Dtran[T,a] Dtran[T,a]表示转换表中T行a列的表项,即T状态接收到a字符后的下一个状态。
算法的流程即将0步可达的状态合并为同一个状态,之后不断遍历字符集移动到下一个状态集合,如果之前没出现过此状态集合则定义为DFA中的新的状态。
例:NFA转化为DFA

初始状态 A : ϵ − c l o s u r e ( 0 ) = { 0 , 1 , 2 , 4 , 7 } A:\epsilon-closure(0)=\{0,1,2,4,7\} A:ϵ−closure(0)={0,1,2,4,7},接受a后可达 m o v e ( A , a ) = { 3 , 8 } move(A,a)=\{3,8\} move(A,a)={3,8},因此下一个状态为 ϵ − c l o s u r e ( { 3 , 8 } ) = { 1 , 2 , 3 , 4 , 6 , 7 , 8 } \epsilon-closure(\{3,8\})=\{1,2,3,4,6,7,8\} ϵ−closure({3,8})={1,2,3,4,6,7,8},之前没有出现过,因此作为DFA中的新状态B。
按顺序计算即可得转换表:

其中A为初始状态,E为接受状态。
算法2:正则表达式到NFA
正则表达式到NFA的转化可以通过对四种运算的递归获得。
-
基本规则:
-
ϵ
\epsilon
ϵ:

-
a
a
a:
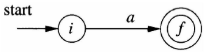
-
ϵ
\epsilon
ϵ:
-
归纳部分
-
s
∣
t
s|t
s∣t:
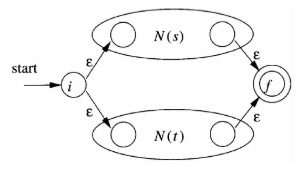
-
s
t
st
st:
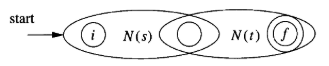
-
s
∗
s^*
s∗:

-
s
∣
t
s|t
s∣t:
算法3:DFA状态数量最小化
- 把所有可区分的状态分开 (迭代过程)
- 基本步骤:ε区分了接受状态和非接受状态
- 归纳步骤:如果s和t是可区分的,且s’到s、t’到t有标号 为a的边,那么s’和t’也是可区分的
- 最终没有区分开的状态就是等价的
例:简化DFA

如图,
-
首先区分接受状态 { A , B , C , D } \{A,B,C,D\} {A,B,C,D}和非接受状态 { E } \{E\} {E}
-
之后细分第一个集合,根据字符b可以划分为 { A , B , C } \{A,B,C\} {A,B,C}和 { D } \{D\} {D}(D收到b后移动到可区分状态E)
-
之后细分第一个集合,根据字符b可以划分为 { A , C } \{A,C\} {A,C}和 { B } \{B\} {B}(B收到b后到达可区分状态状态D)
-
{ A , C } \{A,C\} {A,C}对于任何字符都不可区分,因此可以合并为一个状态。简化完成。















 2902
2902











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









