







 本文介绍了Text-CNN模型的网络结构,包括Embedding Layer、Convolution Layer、Max-Pooling Layer和SoftMax分类层。重点讨论了卷积层如何捕获局部位置信息,并通过Max-Pooling处理可变长度输入。实验部分展示了在多个文本分类任务上的应用和效果,证明预训练词向量和适当微调的重要性。
本文介绍了Text-CNN模型的网络结构,包括Embedding Layer、Convolution Layer、Max-Pooling Layer和SoftMax分类层。重点讨论了卷积层如何捕获局部位置信息,并通过Max-Pooling处理可变长度输入。实验部分展示了在多个文本分类任务上的应用和效果,证明预训练词向量和适当微调的重要性。
文章目录
卷积神经网络相比于DNN和RNN有以下优点:
- 能捕获局部的位置信息
- 能够方便的将不定长的输入转换成定长输入接入到DNN网络中
- 相比于RNN模型计算复杂度低,在很多任务中取得不错的效果
TEXT-CNN
一篇比较老的论文了, 但是很经典, 在一些简单的分类任务上效果也还不错.
1. 网络结构
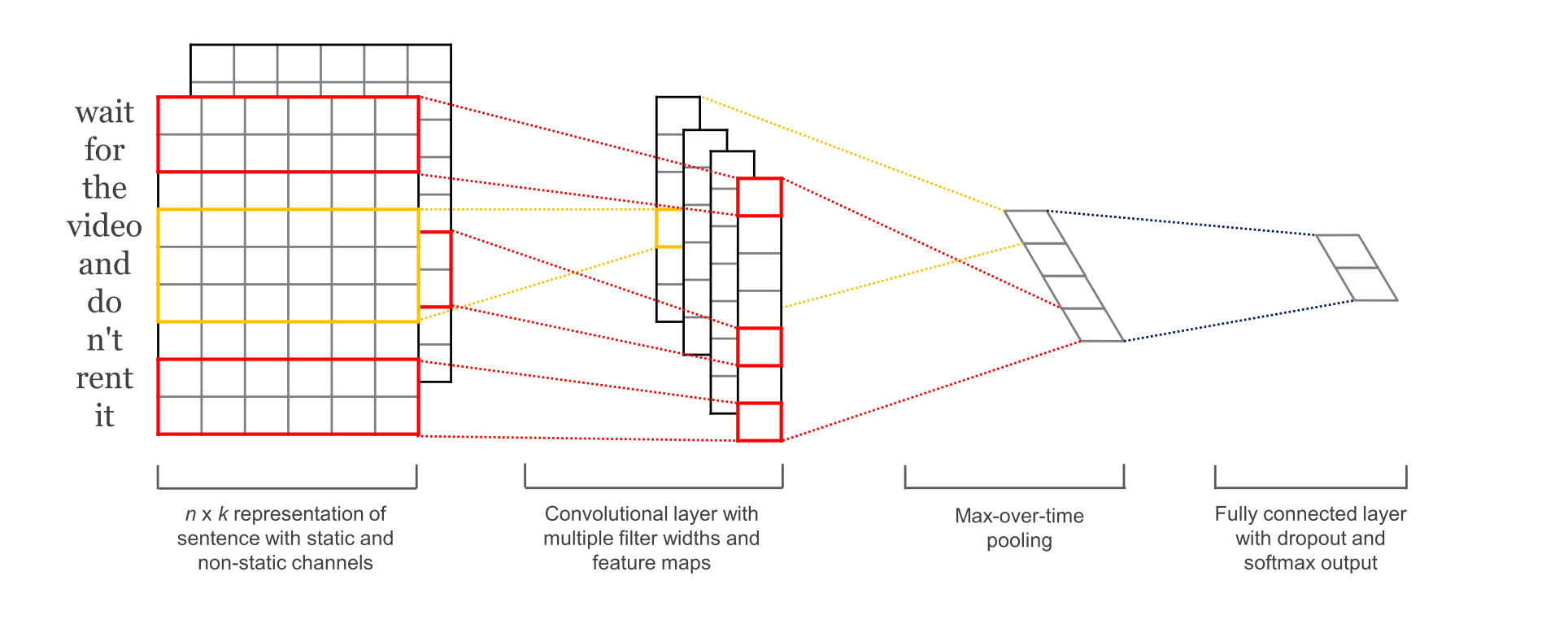
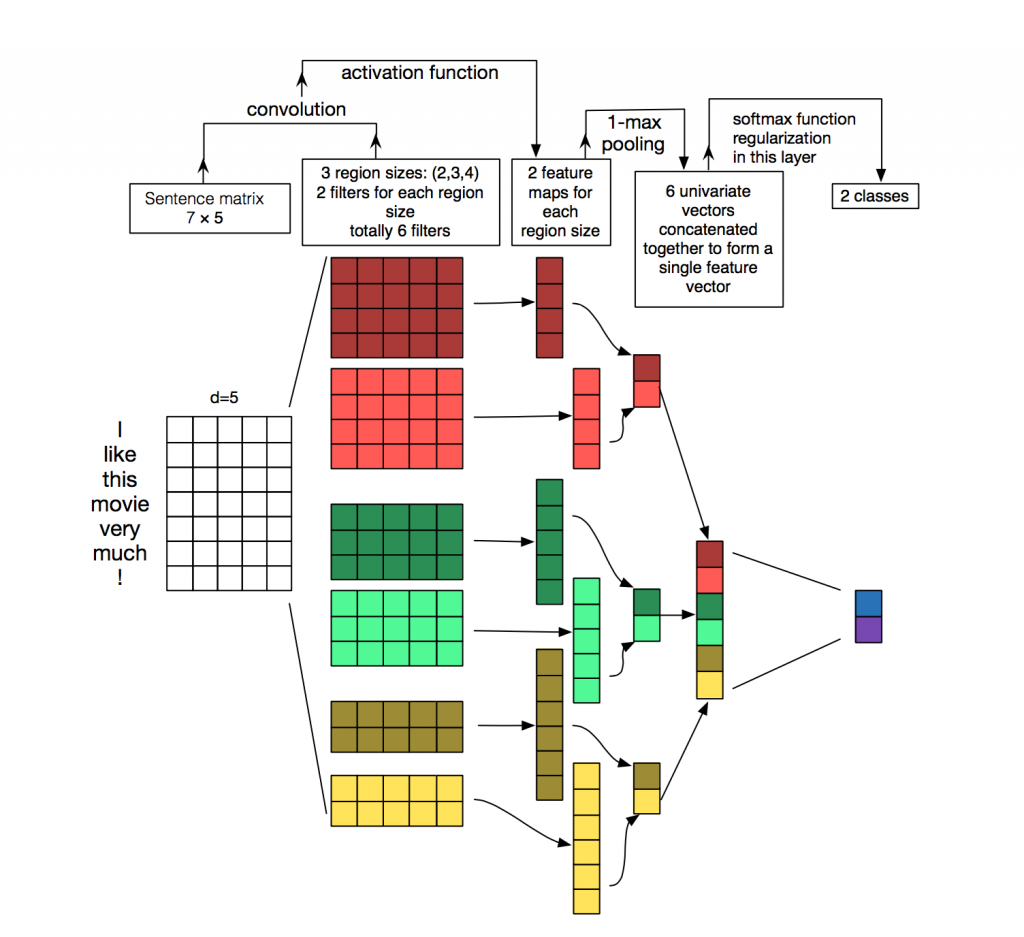
Embedding Layer
word embedding层, 没什么好说的
Convolution Layer
输入层通过卷积操作得到若干个Feature Map,卷积窗口的大小为 h×k ,其中 h 表示纵向词语的个数,而 k 表示word vector的维数。通过这样一个大型的卷积窗口,将得到若干个列数为1的Feature Map。
Max-Pooling Layer
接下来的池化层,文中用了一种称为Max-over-time Pooling的方法。这种方法就是简单地从之前一维的Feature Map中提出最大的值,文中解释最大值代表着最重要的信号。可以看出,这种Pooling方式可以解决可变长度的句子输入问题(因为不管Feature Map中有多少个值,只需要提取其中的最大值)。最终池化层的输出为各个Feature Map的最大值们,即一个一维的向量。
SoftMax分类Layer
池化层的一维向量的输出通过全连接的方式,连接一个Softmax层,Softmax层可根据任务的需要设置(通常反映着最终类别上的概率分布)。最终实现时,我们可以在倒数第二层的全连接部分上使用Dropout技术,这样做的好处是防止隐藏层单元自适应(或者对称),从而减轻过拟合的程度。
2. 参数与超参数
- sequence_length
CNN输入输出都是固定的,对句子做定长处理,超过的截断,不足的补0. - filter_size_list : 多个不同size的filter, 一般设置[2, ,3, 4]或者[3, 4, 5]
- feature map: 100
- batch_size: 50
- dropout: 0.5
- optimizer: Adadelta
3. 变种
模型结构有几个小的变种:
- CNN-rand
设计好 embedding_size 这个 Hyperparameter 后, 对不同单词的向量作随机初始化, 后续BP的时候作调整. - static
pre-trained词向量固定,训练过程不再调整 - non-static
pretrained vectors + fine-tuning - multiple channel
static与non-static搭两个通道
4. 实验
数据集
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2117
2117

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









