






我们在利用布尔索引,进行数据选择的时候,需要深入理解逻辑操作符,也就是与或非操作。特别是布尔索引对行索引的处理,往往过于冗长和复杂,还需要注意行索引下标的起始位置。这对于非计算机专业的数据分析人员来说,相对于不太友好。
针对以上问题,本篇文章详细介绍一个数据选择的重量级方法,也就是query()方法。通过query()方法对数据进行查询,可以提高查询速度和效率,还可以让查询的代码更加清晰和简便。这对于非计算机专业的数据分析人员来说,是一个不错的数据查询方法。
先看一个布尔索引或操作的query()方法实现方式
生成原始数据集
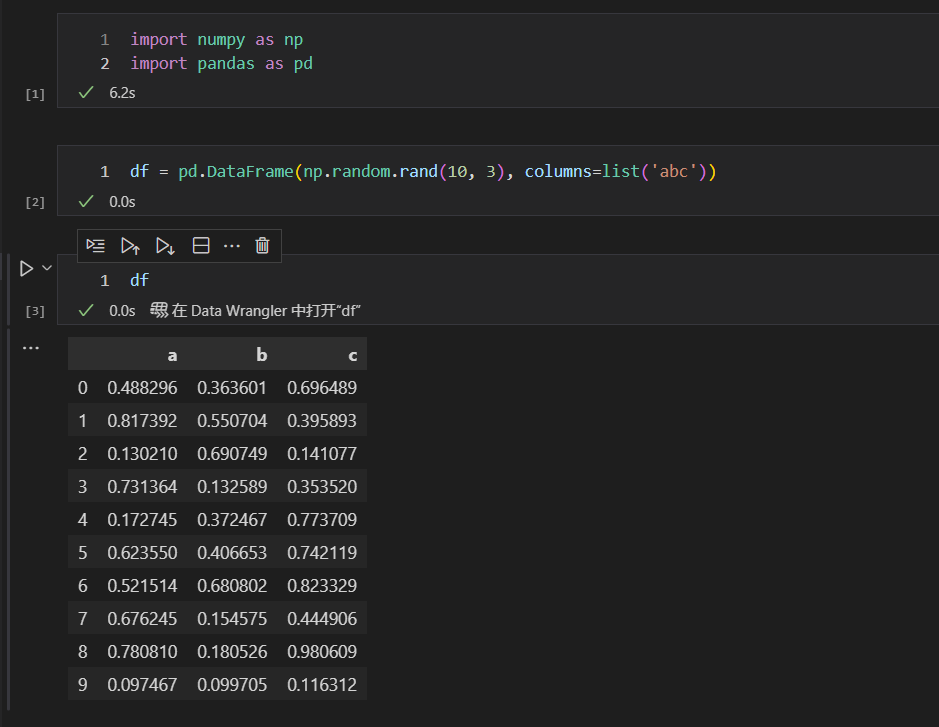
这里分别用纯净的python查询方法和query方法进行对比
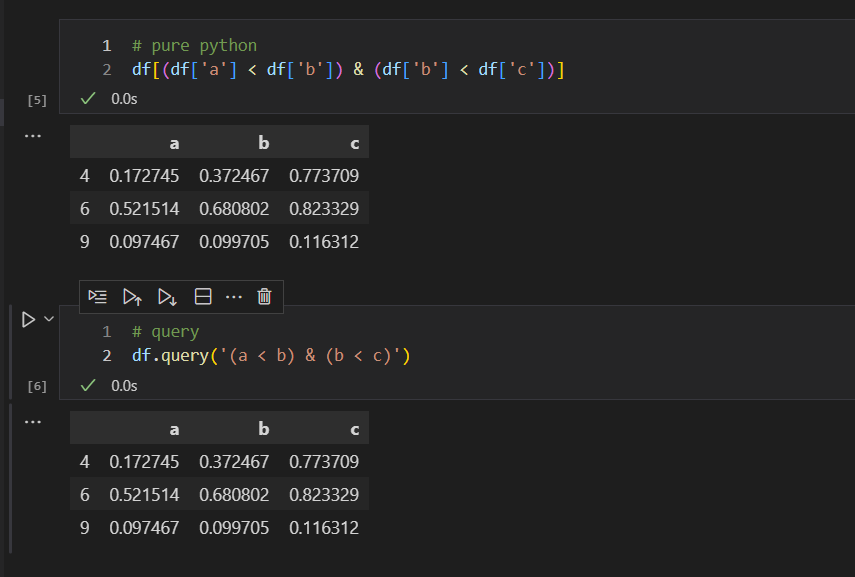
从上图中的查询代码,以及查询结果可以看到,实现同样的查询过程,用query方法的话,代码更加清晰,而且复杂度大大降低,让人容易理解。
我们甚至可以把和操作符&,换成英文and表示
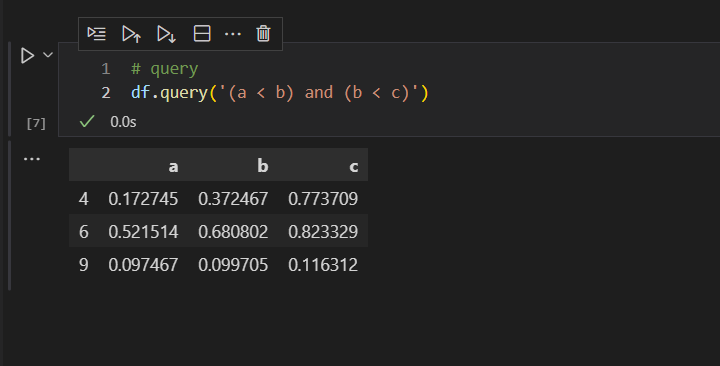
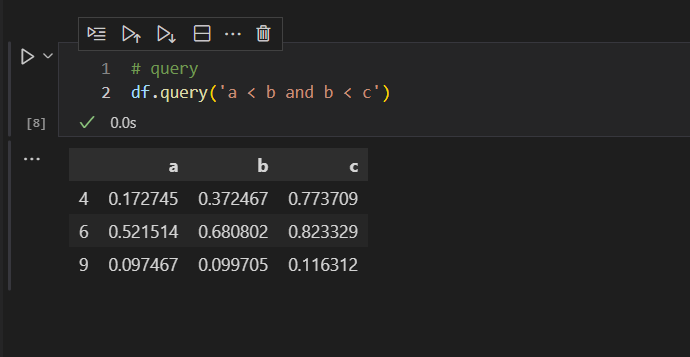
还可以去掉小括号,进一步优化代码,让查询代码更加简洁
in 和 not in 操作符的 query 方法替代
这里,我们重新生成一个数据集
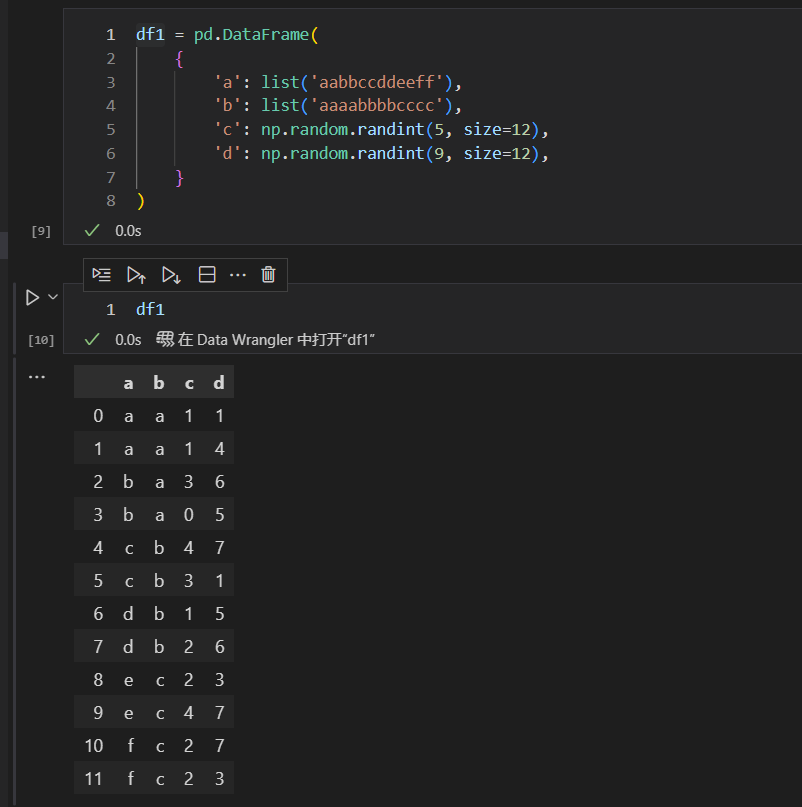
先来看in操作的query方法
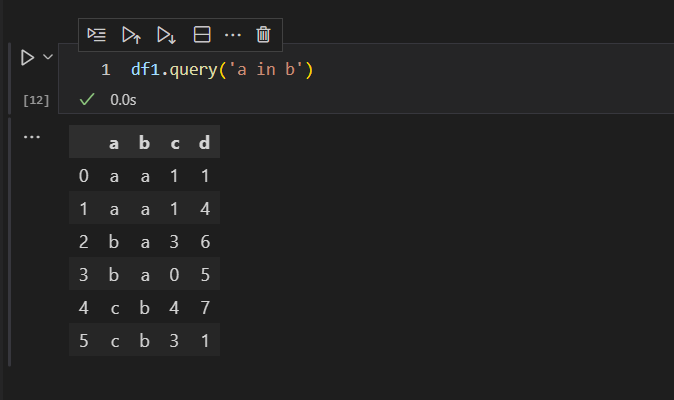
这里的in操作符,表示的是包含的意思,也就是a列的值,在b列中出现的数据行。
我们可以从原始数据集看到,a列有a,b,c,d,e,f这几个数据值,b列有a,b,c三个不重复的数据值。那么,a列在b列中出现的数据值,就是a,b,c三个,包含重复值。
用纯净的python语句查询的话,是下面这样的
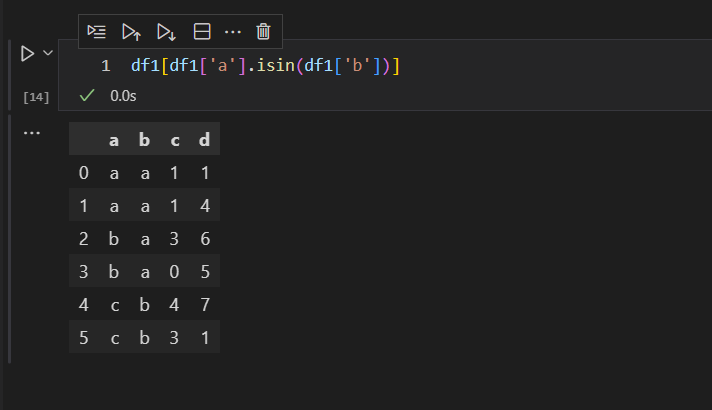
再来看看not in操作的query方法实现方式
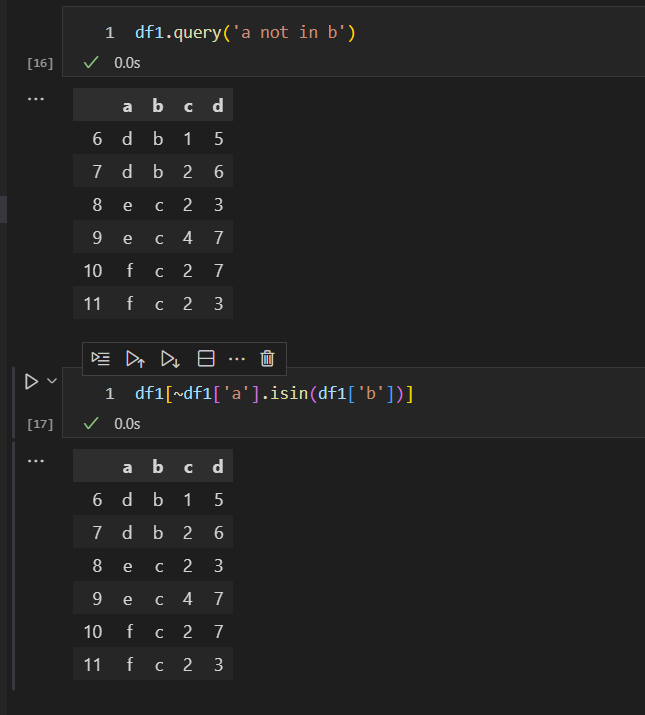
query方法的组合查询方式
我们可以把in和not in操作,以及布尔操作组合起来,通过query方法来实现
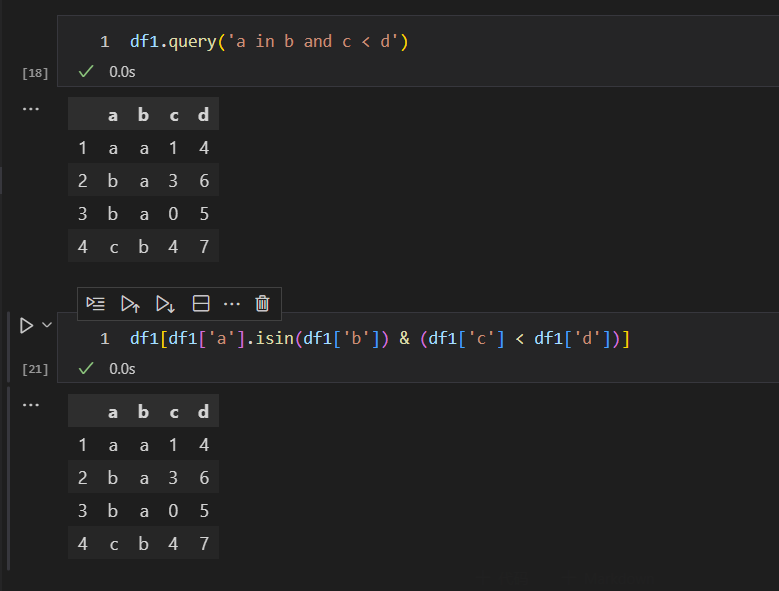
通过list对象实现的==和!=操作符的query实现方式
==操作符等同于in操作符
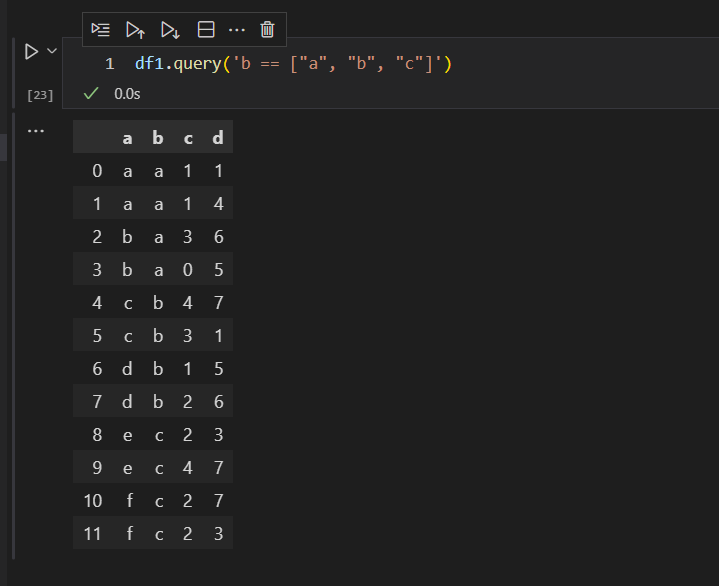
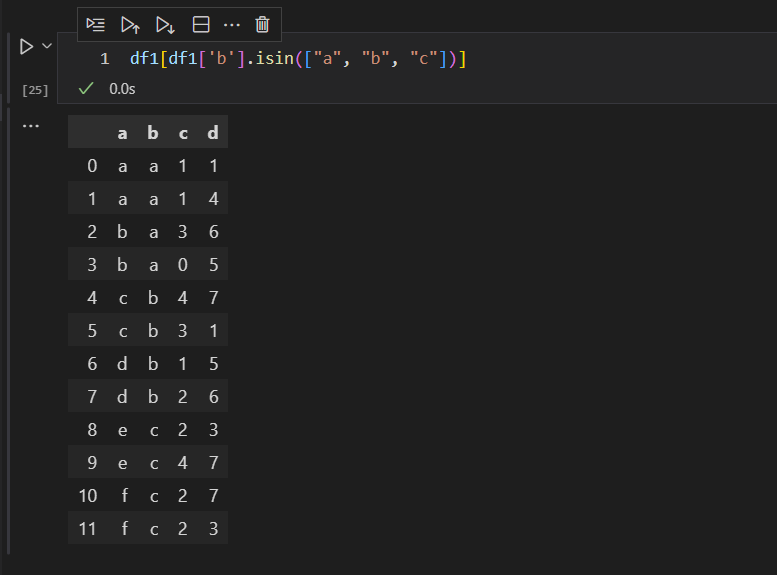
代码的含义是,选择b列中的数值,同时在a,b,c三列中都出现过的数据。我们可以看出,b列中的a,b,c三个值,在a列中全部出现过,所以等同于选择全部数据。
纯净的python查询语句,是下面这样的
query方法的性能
我们再来看看query方法,和纯净的python查询语句相比,性能如何?
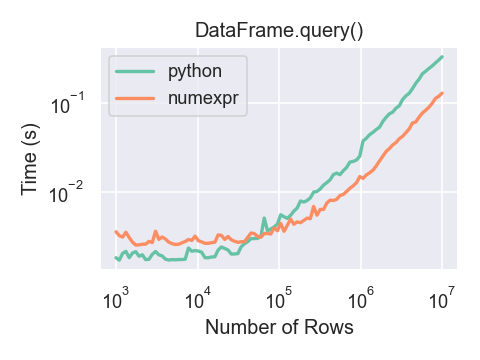
从上图可以看出,绿色的曲线,代表纯净的python查询语句的执行速度。橘红色的曲线,代表的是query方法的执行速度。
在不超过100,000行数据的情况下,query方法稍微慢一些,需要的时间更多。但是,超过100,000行数据的情况下,query方法的查询速度,就优于纯净的python查询语句了。
总结
query方法的语句,要比python的查询语句,更加简单易懂。对于非计算机专业的数据分析人员来说,可以用query方法,替代布尔索引,还有逻辑的与或非操作,以及in和not in操作。
在执行速度方面,100,000行数据是query方法和python查询语句的分界线。小于100,000行数据的情况下,python查询语句稍微快一些。大于100,000行数据的情况下,query方法要优于python查询语句。
















 830
830

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











