







 本文详细介绍了广度优先遍历(BFS)的基本思想、步骤,并通过一个案例分析了BFS的过程。同时,给出了使用Java实现图的邻接矩阵类以及广度优先遍历的代码,包括测试类和测试结果,展示了如何在无向图中进行BFS操作。
本文详细介绍了广度优先遍历(BFS)的基本思想、步骤,并通过一个案例分析了BFS的过程。同时,给出了使用Java实现图的邻接矩阵类以及广度优先遍历的代码,包括测试类和测试结果,展示了如何在无向图中进行BFS操作。
1. 广度优先算法的原理
1.1. 广度优先遍历基本思想
- 广度优先遍历(Board First Search)类似于分层搜索.
- 广度优先遍历需要使用一个队列以保存访问过的结点的顺序,
以便按照这个顺序来访问这些结点的邻接结点.
1.2. 广度优先遍历算法步骤
-
访问初始节点 V 并标记结点 V 为已访问
-
结点 V 入队列.
-
当队列非空时, 继续执行, 否则算法结束.
-
队列第一个结点出队, 取得队头结点 U.
-
查找结点 U 的第一个邻接结点 W.
-
若结点 U 的邻接结点 W 不存在, 则跳转到步骤 3;
否则执行以下三个步骤:- 若结点 W 未被访问, 则访问结点 W 并标记为已访问, 结点 W 入队列;
若结点 W 已被访问, 直接执行下一步. - 查找结点 U 的继 W 邻接结点后的下一个邻接结点 W;
- 跳转到步骤 6 进行循环执行直到跳出.
- 若结点 W 未被访问, 则访问结点 W 并标记为已访问, 结点 W 入队列;
1.3. 广度优先遍历案例分析
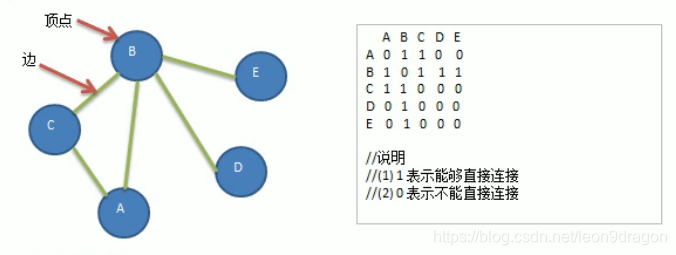
- 首先设置初始结点为 A, 结点 A 进入了队列, 输出: A
- 队列中的第一个结点出队, 即结点 A 出列, 并以结点 A 访问其邻接结点
- 访问 A 的第一个邻接结点 B, 发现能够连通, B 进入队列, 输出: A-B
- 访问 A 的下一个邻接结点 C, 发现能够联通, C 进入队列, 输出 A-B-C
- 访问 A 的下一个邻接结点 D, 发现不能联通, 则返回队列.
- 此时队列中第一个结点是结点 B, 因此结点 B 出列, 并以结点 B 来查找其邻接结点
- 访问 B 的邻接结点, A-C 都已经被访问过则继续查询直到出现或没有邻接结点为止
- 访问 B 的下一个邻接结点 D, 发现能够联通, D 进入队列, 输出 A-B-C-D
- 访问 B 的下一个邻接结点 E, 发现能够联通, E 进入队列, 输出 A-B-C-D-E
- 至此, 所有结点均被遍历输出, 遍历结束.
2. 广度优先算法的代码实现
- 均在图的基础代码上进行修改
2.1. 图的邻接矩阵类
package com.leo9.dc30.graph;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.LinkedList;
public class GraphMatrix {
//定义一个 ArrayList 用来存储图中的顶点的数据集合
private ArrayList<String> graph_vertex_list;
//定义一个二维数组存储图对应的邻接矩阵
private int[][] graph_edge_arr;
//定义变量存储图中的边的数目
private int edge_num;
//定义数组来记录某个结点是否已被访问
private boolean[] isVisited;
//region 构造器, 参数是顶点数量
public GraphMatrix(int vertex_num) {
//初始化邻接矩阵和顶点集合, 边的数目
//如果顶点有n个, 邻接矩阵就是n*n的矩阵
graph_edge_arr = new int[vertex_num][vertex_num];
//定义顶点集合的容量, 和顶点数量一致
graph_vertex_list = new ArrayList<String>(vertex_num);
//因为一开始并不知道有多少条边, 初始化的时候为0即可(这一步不写也可以)
edge_num = 0;
}
//endregion
//region 定义添加结点方法, 参数是结点对应的字符串
public void insertVertex(String vertex_str) {
//直接添加到集合即可
graph_vertex_list.add(vertex_str);
}
//endregion
//region 定义添加边的方法
/**
* @param vertex1 结点1在集合中的编号, 即顶点在集合中的下标[0~n]
* @param vertex2 结点2在集合中的编号, 即顶点在集合中的下标[0~n]
* @param edge_weight 两个结点之间边的权值, 默认为 0 不连通, 大于 0 就连通
*/
public void insertEdge(int vertex1, int vertex2, int edge_weight) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 622
622

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









