






为什么选择Weaviate
- 开源
- 行业TOP 3
- 支持混合检索
搭建步骤
- 安装docker 这里就不赘述docker的安装方法了
- 运行容器
docker run -d --name wea -p 8080:8080 -p 50051:50051 cr.weaviate.io/semitechnologies/weaviate:1.25.0
注意前面的ip是宿主机ip 后面的是docker容器ip - 查询运行状态
docker ps

- 使用编排的方式创建容器
创建 docker-compose.yml
version: '3.4'
services:
weaviate:
command:
- --host
- 0.0.0.0
- --port
- '8080'
- --scheme
- http
image: cr.weaviate.io/semitechnologies/weaviate:1.25.0
ports:
- 8081:8080
- 8082:50051
volumes:
- /root/wea/data:/root/wea/data
restart: on-failure:0
environment:
QUERY_DEFAULTS_LIMIT: 25
AUTHENTICATION_ANONYMOUS_ACCESS_ENABLED: 'true'
PERSISTENCE_DATA_PATH: '/root/wea/data'
DEFAULT_VECTORIZER_MODULE: 'none'
CLUSTER_HOSTNAME: 'node1'
DATA_PATH存放数据
volumes是映射宿主机和容器的路径
使用docker compose up -d创建并启动
Weaviate的使用
以下使用python代码示范如何灌库和查询
- 初始化创建链接
def __init__(self, index_name):
url = os.environ["WEAVIATE_URL"]
port = os.environ["WEAVIATE_PORT"]
grcp_port = os.environ["WEAVIATE_GRPC_PORT"]
self.weaviate_client = weaviate.connect_to_custom(
http_host=url,
http_port=port,
http_secure=False,
grpc_host=url,
grpc_port=grcp_port,
grpc_secure=False
)
self.db = WeaviateVectorStore(
client=self.weaviate_client,
index_name=index_name,
text_key="text",
embedding=get_embedding(),
)
index_name是库的名字
embedding传入向量化模型
这里的WeaviateVectorStore是用的langchain里的
from langchain_weaviate.vectorstores import WeaviateVectorStore
- 向量入库
def add_documents(self, documents):
self.init_client()
try:
self.db.add_documents(documents)
except Exception as e:
logging.error(f"Error adding documents: {str(e)}")
self.weaviate_client.close()
- 查询
def query(self, query, top_n=5):
self.init_client()
try:
# 0.5指 一半向量,一半关键字混合检索,值越小越偏向关键字
#docs = self.db.similarity_search(query, k=top_n, alpha=0.5)
docs = self.db.similarity_search_with_score(query, k=top_n)
except Exception as e:
logging.error(f"Error query documents: {str(e)}")
self.weaviate_client.close()
return ''
self.weaviate_client.close()
return docs
langchain里提供了多种查询方式
similarity_search_with_score是根据得分高低返回top n
similarity_search可以指定alpha,0-1,值越小越偏向关键字检索,越大越偏向向量化检索
演示
- 灌库
测试文本如下
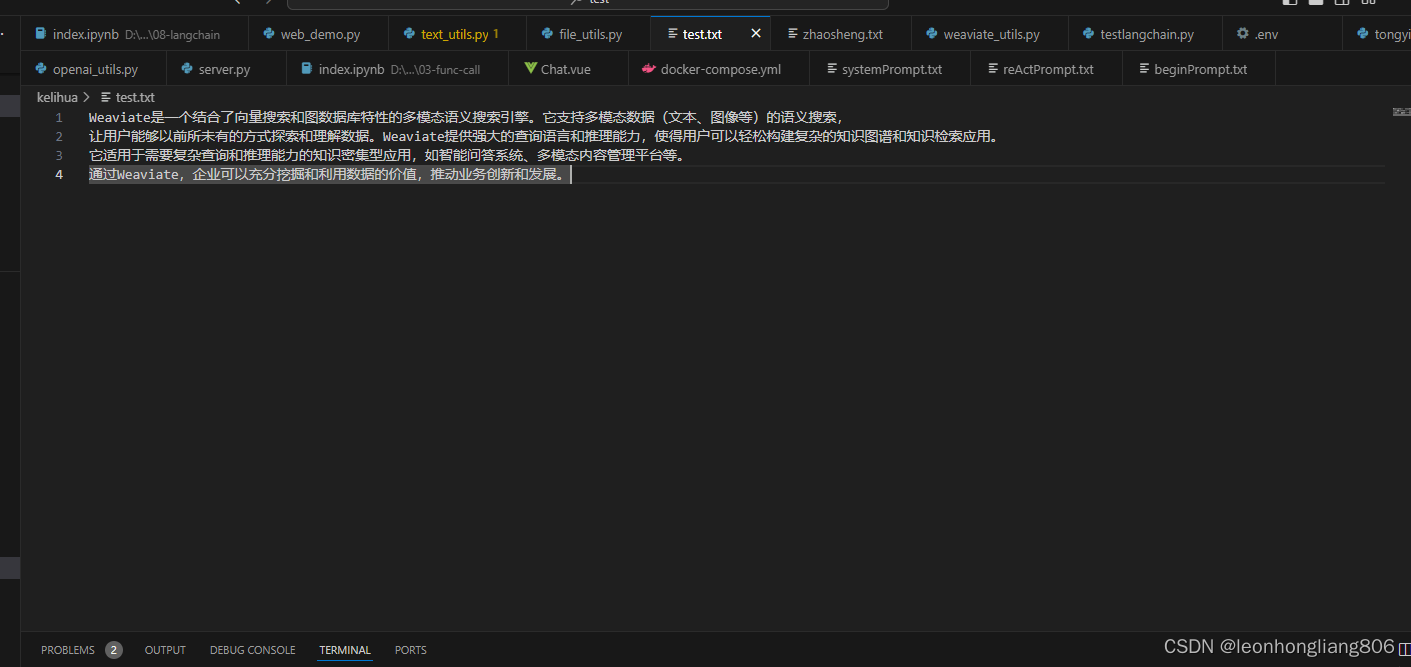
灌库完成

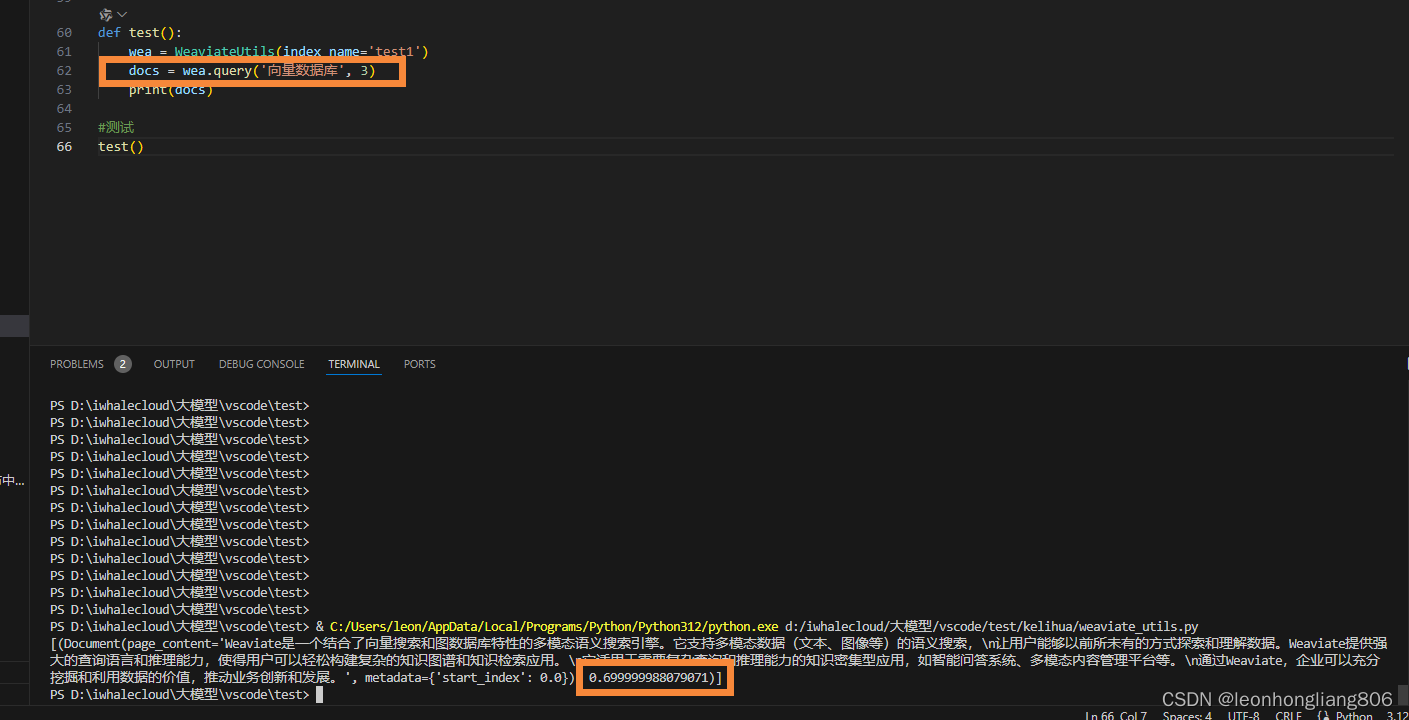
- 查询
检索成功















 591
591











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









