







什么是RAG
RAG(Retrieval Augmented Generation)检索增强生成
通常用于在大模型交互过程中通过检索的方法来增强生成模型的能力。
由于大模型存在的局限性(大模型的知识不是实时的,大模型可能不知道某些私有领域的知识),可以使用检索的方式给大模型提供相应的知识,再参考回答问题
一张图说明RAG的流程
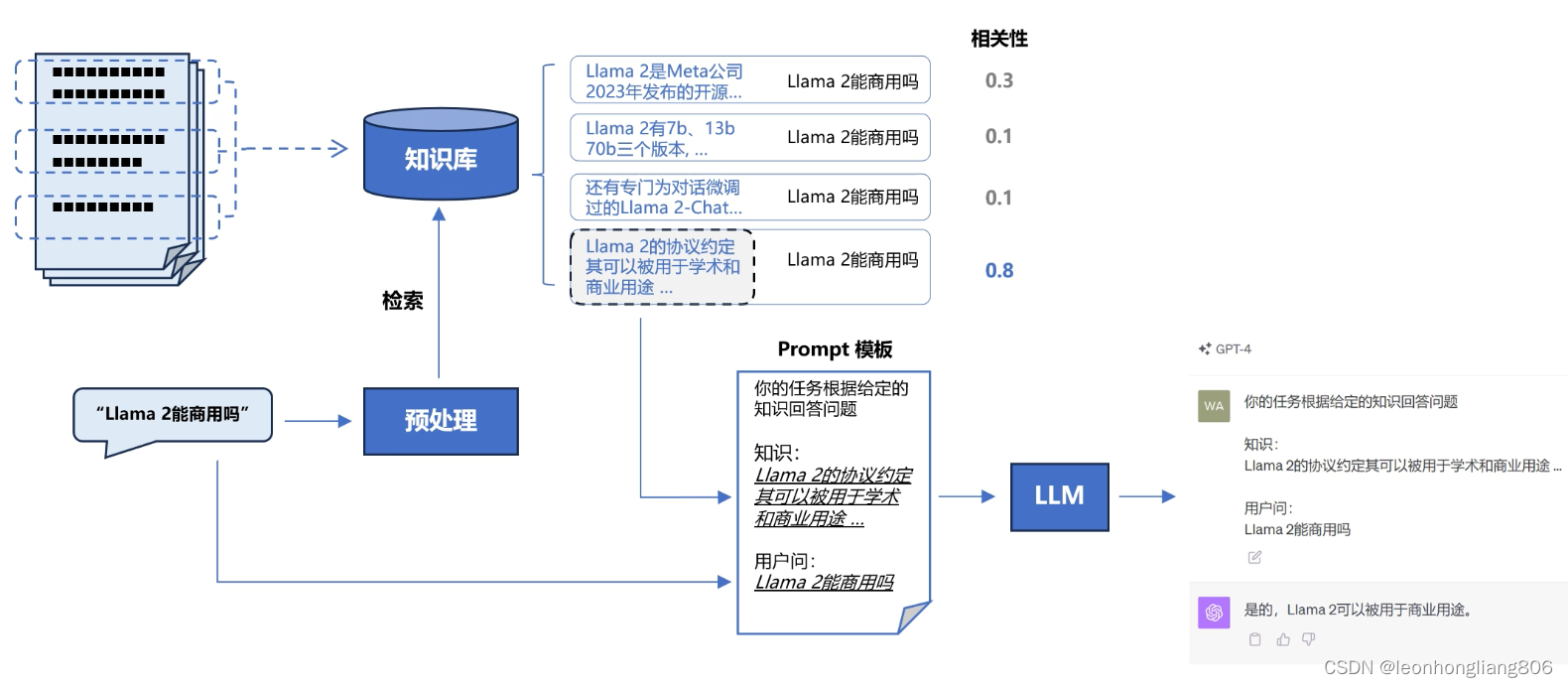
- 将知识灌入数据库
- 用户提问
- 先去数据库检索相关知识
- 将检索出的内容结合prompt送给大模型
- 大模型给出回答
什么是向量检索
提到检索,我们通常会使用elastic search,但是es是基于关键字的检索,有其局限性,同一个语义,用词不同,就会导致无法检索出想要的数据
举例:
es中存储 “小明喜欢吃汉堡”,如果检索关键字“小明喜欢吃”,那么可以找到“汉堡”,但是如果检索“小明爱吃”,那么就找不到这个数据了
为了解决这种问题,所以需要使用向量检索
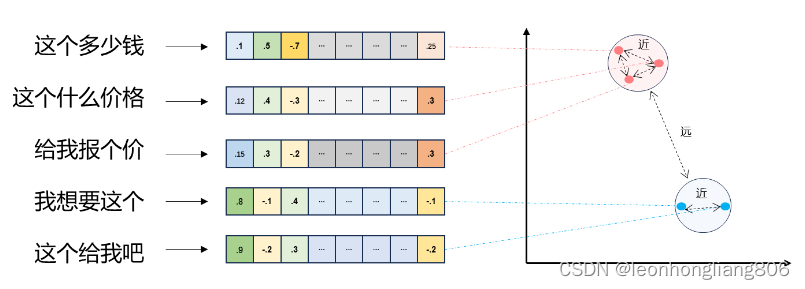
文本向量
- 将文本转成一组浮点数:每个下标 i i i,对应一个维度
- 整个数组对应一个 n n n 维空间的一个点,即文本向量又叫 Embeddings
- 向量之间可以计算距离,距离远近对应语义相似度大小
文本向量是怎么得到的
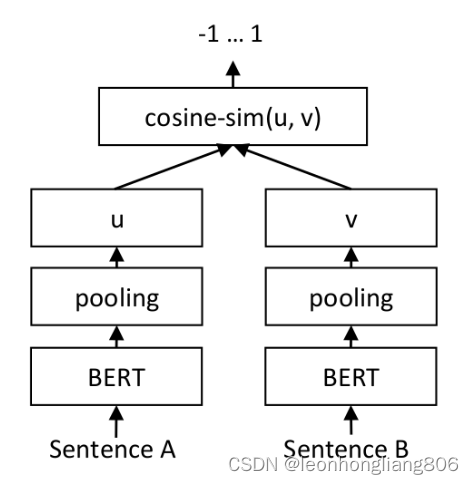
- 构建相关(正立)与不相关(负例)的句子对照样本
- 训练双塔式模型,让正例间的距离小,负例间的距离大
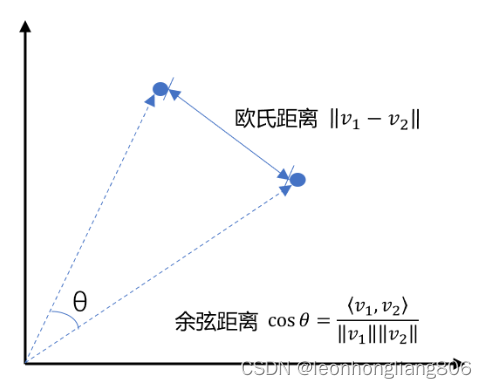
向量间的相似度计算
两种计算方式
欧氏距离
余弦距离
def cos_sim(a, b):
'''余弦距离 -- 越大越相似'''
return dot(a, b)/(norm(a)*norm(b))
def l2(a, b):
'''欧式距离 -- 越小越相似'''
x = np.asarray(a)-np.asarray(b)
return norm(x)
向量数据库
向量数据库,是专门为向量检索设计的中间件
向量数据库本身不生成向量,向量是由 Embedding 模型产生的
向量数据库与传统的关系型数据库是互补的,不是替代关系,在实际应用中根据实际需求经常同时使用。
主流的向量数据库
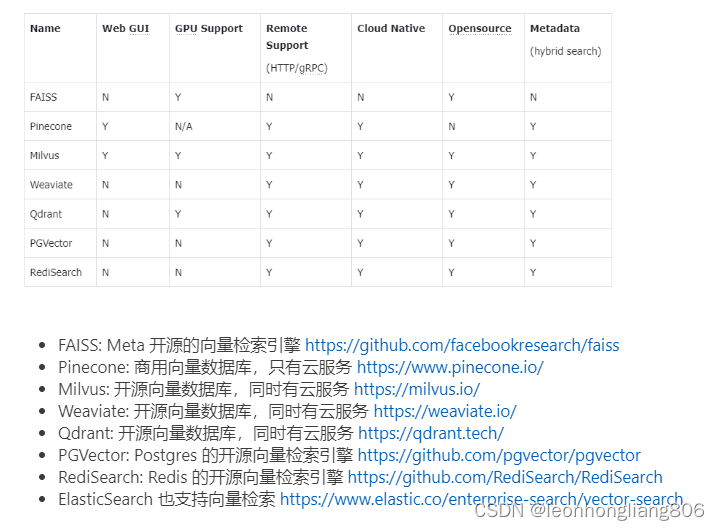
实现一个基于文档向量检索的RAG
流程如下:
1. 文档加载
def extract_text_from_pdf(filename,page_numbers=None,min_line_length=10):
"""从 PDF 文件中(按指定页码)提取文字"""
paragraphs = []
buffer  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 211
211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









