







一、引言
其实利用GEE可以做的内容太多了,很多内容换一个区域,换一个时间段就是一篇本科毕业论文(设计),甚至拓展一下硕士也不是不行。本文将详细介绍如何使用 GEE 对南京江宁区的 Landsat 8 地表反射率数据进行 K-Means 聚类分析,实现土地利用分类,并将结果可视化和导出。(后续有机会再给大家详细说一下如何完整的进行毕业论文的大纲和设计,甚至完成一篇十分简单的毕业论文。)
二、代码实现
2.1 定义研究区域
// 定义南京江宁区的研究区域(经纬度范围)
var roi = ee.Geometry.Polygon([
[
[118.60, 31.80], // 西南点
[118.60, 32.00], // 西北点
[118.90, 32.00], // 东北点
[118.90, 31.80] // 东南点
]
]);此代码块通过定义多边形的顶点坐标,确定了南京江宁区的研究区域。
2.2 加载 Landsat 8 地表反射率数据
// 加载Landsat 8地表反射率数据
var landsat = ee.ImageCollection('LANDSAT/LC08/C02/T1_L2')
.filterDate('2020-01-01', '2020-12-31') // 时间范围
.filterBounds(roi) // 空间范围
.median() // 计算中值合成
.clip(roi); // 裁剪到研究区域这里从 GEE 的影像集合中加载 Landsat 8 的地表反射率数据,通过筛选时间范围和空间范围,然后计算中值合成影像,并将其裁剪到研究区域。
2.3 选择波段并应用缩放因子
// 选择波段并应用缩放因子(Landsat 8地表反射率需缩放)
var bands = ['SR_B2', 'SR_B3', 'SR_B4', 'SR_B5', 'SR_B6', 'SR_B7'];
var scaled = landsat.select(bands)
.multiply(0.0000275) // 缩放因子
.add(-0.2); // 偏移量选择了 Landsat 8 的 6 个波段,并对这些波段应用了缩放因子和偏移量,以获得正确的地表反射率值。
2.4 从影像中随机采样训练数据
// 从影像中随机采样训练数据
var training = scaled.sample({
region: roi,
scale: 30, // 分辨率(米)
numPixels: 5000 // 采样点数
});从缩放后的影像中随机采样了 5000 个点作为训练数据,采样的分辨率为 30 米。
2.5 训练 K-Means 聚类器
// 训练K-means聚类器(假设分为5类)
var clusterer = ee.Clusterer.wekaKMeans(5).train(training);使用 Weka 的 K-Means 算法训练聚类器,将数据分为 n类。
2.6 应用聚类器到整个影像
// 应用聚类器到整个影像
var clustered = scaled.cluster(clusterer);将训练好的聚类器应用到整个缩放后的影像上,得到聚类结果。
2.7 可视化设置
// 可视化设置
Map.centerObject(roi, 10); // 地图中心设为区域,缩放级别10
Map.addLayer(scaled, {bands: ['SR_B4', 'SR_B3', 'SR_B2'], min: 0, max: 0.3}, 'RGB图像');
Map.addLayer(clustered.randomVisualizer(), {}, '聚类结果');将地图中心定位到研究区域,并设置缩放级别为 10。添加了原始的 RGB 图像和聚类结果的可视化图层。
2.8 导出结果到 Google Drive
// 可选:导出结果到Google Drive
Export.image.toDrive({
image: clustered,
description: 'Jiangning_Cluster',
scale: 30,
region: roi,
maxPixels: 1e13
});将聚类结果影像导出到 Google Drive,方便后续进一步分析和使用。
三、完整代码:
// 定义南京江宁区的研究区域(经纬度范围)
var roi = ee.Geometry.Polygon([
[
[118.60, 31.80], // 西南点
[118.60, 32.00], // 西北点
[118.90, 32.00], // 东北点
[118.90, 31.80] // 东南点
]
]);
// 加载Landsat 8地表反射率数据
var landsat = ee.ImageCollection('LANDSAT/LC08/C02/T1_L2')
.filterDate('2020-01-01', '2020-12-31') // 时间范围
.filterBounds(roi) // 空间范围
.median() // 计算中值合成
.clip(roi); // 裁剪到研究区域
// 选择波段并应用缩放因子(Landsat 8地表反射率需缩放)
var bands = ['SR_B2', 'SR_B3', 'SR_B4', 'SR_B5', 'SR_B6', 'SR_B7'];
var scaled = landsat.select(bands)
.multiply(0.0000275) // 缩放因子
.add(-0.2); // 偏移量
// 从影像中随机采样训练数据
var training = scaled.sample({
region: roi,
scale: 30, // 分辨率(米)
numPixels: 5000 // 采样点数
});
// 训练K-means聚类器(假设分为5类)
var clusterer = ee.Clusterer.wekaKMeans(5).train(training);
// 应用聚类器到整个影像
var clustered = scaled.cluster(clusterer);
// 可视化设置
Map.centerObject(roi, 10); // 地图中心设为区域,缩放级别10
Map.addLayer(scaled, {bands: ['SR_B4', 'SR_B3', 'SR_B2'], min: 0, max: 0.3}, 'RGB图像');
Map.addLayer(clustered.randomVisualizer(), {}, '聚类结果');
// 可选:导出结果到Google Drive
Export.image.toDrive({
image: clustered,
description: 'Jiangning_Cluster',
scale: 30,
region: roi,
maxPixels: 1e13
});四、结果:
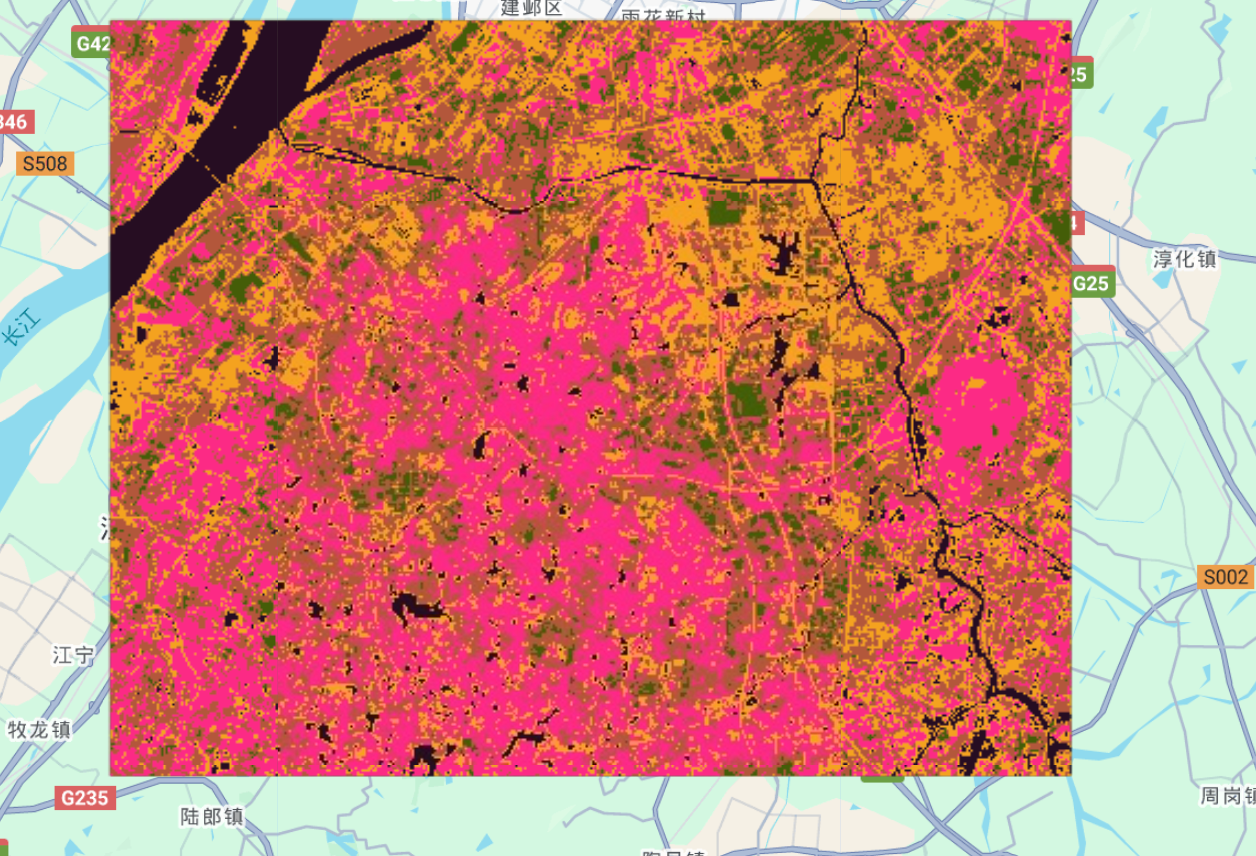
3类

12类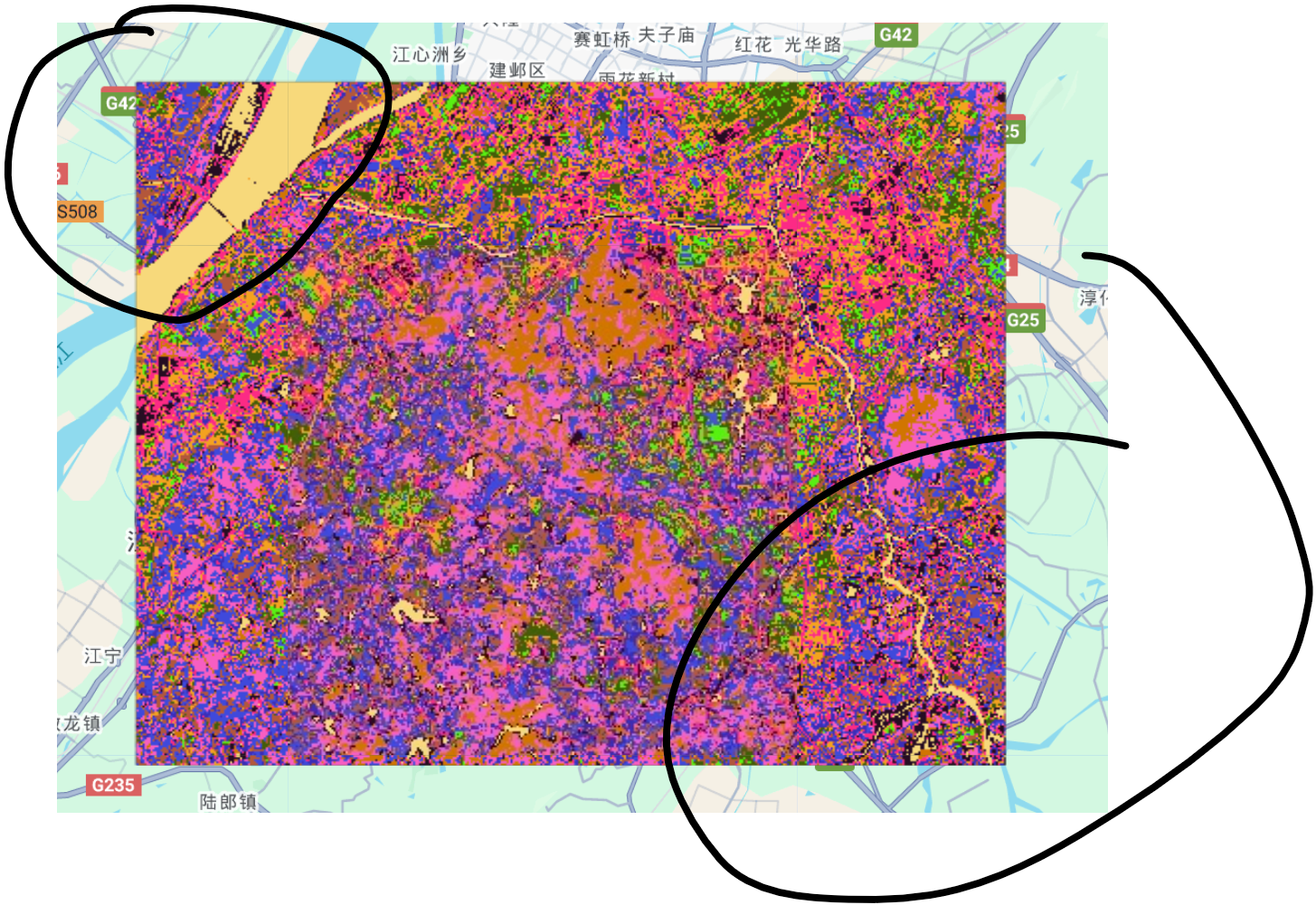
大家仔细观察,其实用无监督聚类方法的结果也还可以,尤其对于规则水体。
希望本文对大家有所帮助,欢迎在评论区留言交流!




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











