







第二章 Master模块设计及实现
Master具体细分为系统配置及监控加载模块、请求及相应封装处理模块、统计模块、监控及负载均衡等模块。具体的关系图如下:
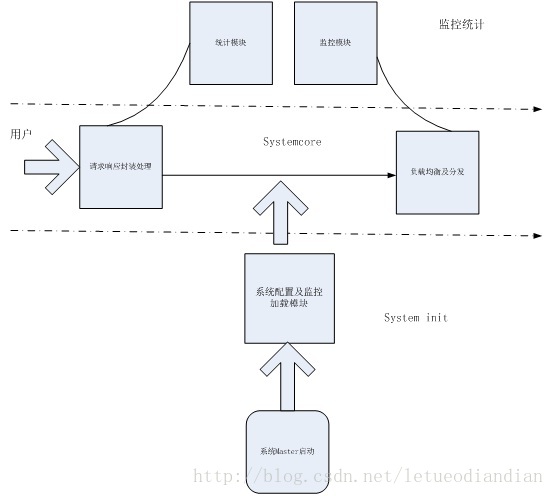
图2.1 Master系统逻辑框架图
下面逐个对这些模块及主要代码进行分析讲解。
2.1 系统配置及监控加载模块
由于系统需要在启动的时候加载一些配置和监控模块,同时还需要在最后做一些系统的资源释放和销毁动作,加上spring提供了类似的重写接口,所以系统的入口类需要实现如下三个接口:ApplicationContextAware,InitializingBean,DisposableBean,实现如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 3303
3303











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









