






第一章 OpenCV入门
1.1 如何使用
1.2 图像处理基本操作
1.3 OpenCV贡献库
第二章 图像处理基础
2.1 图像的基本表示方法
在 OpenCV 中,图像的基本表示方法可以根据图像类型不同而有所区别。主要区分为二值图像、灰度图像和彩色图像。下面分别解释这三种类型的图像在 OpenCV 中的表示方法:
1. 二值图像(Binary Image)
- 特点:二值图像仅包含两种颜色,通常是黑色和白色。每个像素只能取两个值,通常是0(黑色)或255(白色)。
- 表示:在 OpenCV 中,二值图像通常表示为一个单通道的 NumPy 数组,数组的数据类型通常是
uint8。 - 应用:二值图像常用于阈值处理、轮廓检测、形态学操作等。
2. 灰度图像(Grayscale Image)
- 特点:灰度图像中的每个像素仅表示亮度信息,不包含颜色。像素值通常在0(黑色)到255(白色)之间。
- 表示:在 OpenCV 中,灰度图像也表示为一个单通道的 NumPy 数组,但每个像素可以有256个可能的灰度级。
- 应用:灰度图像用于边缘检测、图像增强、图像分割等。
3. 彩色图像(Color Image)
- 特点:彩色图像通常包含多个颜色通道,最常见的是 RGB(红绿蓝)格式。但在 OpenCV 中,默认使用 BGR(蓝绿红)格式。
- 表示:彩色图像在 OpenCV 中表示为一个三通道的 NumPy 数组,每个通道分别代表 B、G、R。每个像素的每个通道值在0到255之间。
- 应用:彩色图像广泛用于图像识别、追踪、分割等。
示例代码
以下是一个简单的 Python 示例,展示了如何在 OpenCV 中创建和处理这三种类型的图像:
import cv2
import numpy as np
# 创建一个灰度图像
gray_image = np.zeros((100, 100), dtype=np.uint8) # 100x100像素的灰度图像
# 创建一个二值图像
binary_image = np.zeros((100, 100), dtype=np.uint8)
binary_image[50:, 50:] = 255 # 将右下角设置为白色
# 加载一个彩色图像
color_image = cv2.imread('path_to_color_image.jpg') # 确保这是一个彩色图像
# 显示图像
cv2.imshow('Gray Image', gray_image)
cv2.imshow('Binary Image', binary_image)
cv2.imshow('Color Image', color_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
在这个示例中,我们创建了一个灰度图像和一个二值图像,同时加载了一个彩色图像。注意,这里使用了 numpy 创建灰度和二值图像,而使用 cv2.imread() 加载彩色图像。每种图像类型在 OpenCV 中都有其特定的应用和处理方法。
2.2 像素处理
2.3 使用numpy.array访问像素
2.4 感兴趣区域(ROI)
在OpenCV中,感兴趣区域(Region of Interest,简称ROI)是指图像中我们关注的特定区域。这个概念在图像处理和计算机视觉中非常重要,因为它允许我们只处理图像的某个部分,而不是整个图像。这在进行特征检测、图像分割、图像识别等操作时非常有用。
在Python中使用OpenCV处理ROI通常涉及以下步骤:
-
读取图像:首先使用
cv2.imread函数读取整个图像。 -
定义ROI区域:确定你感兴趣的区域。ROI通常以矩形框的形式定义,指定其左上角的坐标(x, y)以及宽度和高度(w, h)。
-
提取ROI:使用Python的数组切片功能从图像中提取ROI。在OpenCV中,图像表示为NumPy数组,所以你可以直接使用数组切片。
-
处理ROI:在提取的ROI上进行所需的图像处理操作。
-
替换/修改原图像:如果需要,你可以将处理过的ROI放回原图像中。
示例一:获取图像lena的脸部信息,并将其显示出来
import cv2 a=cv2.imread("lenacolor.png", cv2.IMREAD_UNCHANGED) face=a[220:400,250:350] cv2.imshow("original", a) cv2.imshow("face", face) cv2.waitKey() cv2.destroyAllWindows()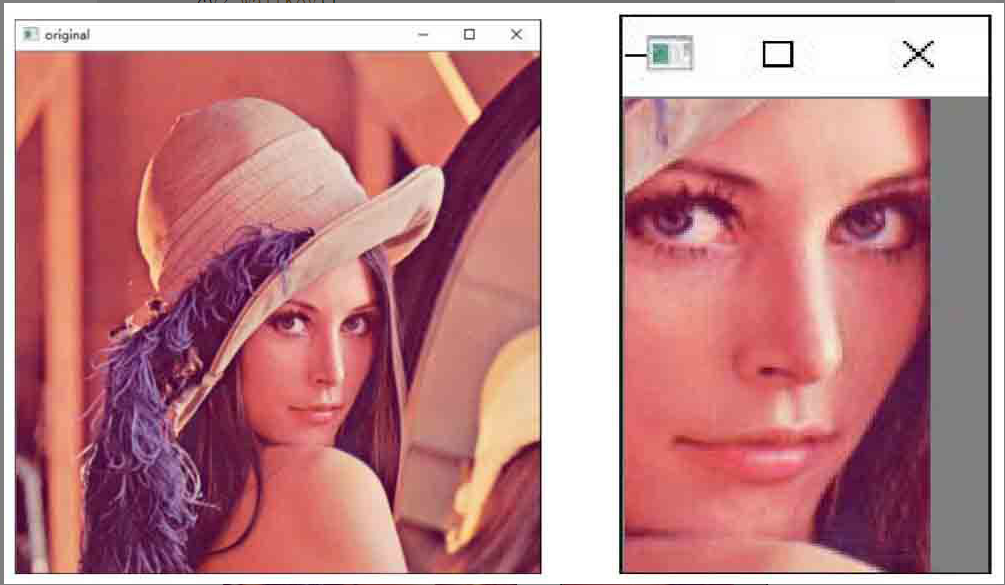
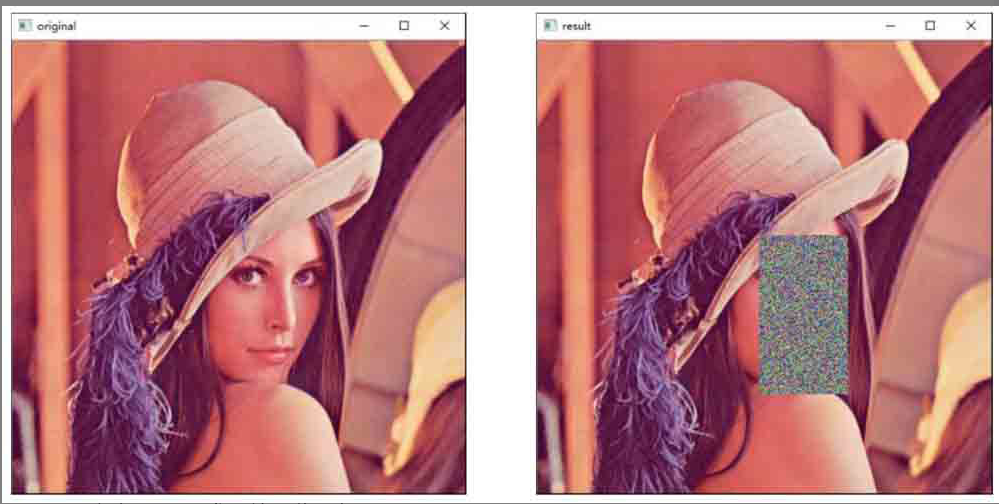
示例二:对lena图像的脸部进行打码
import cv2 import numpy as np a=cv2.imread("lenacolor.png", cv2.IMREAD_UNCHANGED) cv2.imshow("original", a) # 使用随机数生成的三维数组模拟了一幅随机图像,实现了对脸部图像的打码。 face=np.random.randint(0,256, (180,100,3)) a[220:400,250:350]=face cv2.imshow("result", a) cv2.waitKey() cv2.destroyAllWindows()
示例三:将一幅图像内的ROI复制到另一幅图像内
import cv2
lena=cv2.imread("lena512.bmp", cv2.IMREAD_UNCHANGED)
dollar=cv2.imread("dollar.bmp", cv2.IMREAD_UNCHANGED)
cv2.imshow("lena", lena)
cv2.imshow("dollar", dollar)
face=lena[220:400,250:350]
dollar[160:340,200:300]=face
cv2.imshow("result", dollar)
cv2.waitKey()
cv2.destroyAllWindows()
其中,左图是lena的原始图像,中间的图是dollar图像,右图是将lena图像内的ROI复制到dollar图像的效果。

2.5 通道操作
在 OpenCV 中,对于多通道(如彩色)图像,你可以通过索引或使用特定函数来拆分通道。同时,也可以将多个单通道图像合并成一个多通道图像。以下是如何进行通道拆分和合并的详细说明:
通道拆分
1. 通过索引拆分
彩色图像在 OpenCV 中以 BGR 格式存储(注意,不是 RGB)。每个颜色通道可以通过索引直接访问。
import cv2
# 加载彩色图像
image = cv2.imread('path_to_image.jpg')
# 通过索引拆分通道
blue_channel = image[:, :, 0] # 蓝色通道
green_channel = image[:, :, 1] # 绿色通道
red_channel = image[:, :, 2] # 红色通道
2. 通过函数拆分
OpenCV 提供了 cv2.split() 函数,可以直接将图像分成单独的颜色通道。
import cv2
# 加载彩色图像
image = cv2.imread('path_to_image.jpg')
# 通过函数拆分通道
b, g, r = cv2.split(image)
通道合并
使用 cv2.merge() 函数,可以将多个单通道图像合并成一个多通道图像。
import cv2
# 假设 b, g, r 是拆分的单通道图像
# ...(拆分通道的代码)
# 合并通道
merged_image = cv2.merge([b, g, r])
注意事项
- 在处理大图像时,使用索引拆分通道比
cv2.split()更内存效率,因为cv2.split()会创建新的图像数组。 - 在合并通道时,确保所有单通道图像具有相同的尺寸和数据类型。
2.6 获取图像属性
在 OpenCV 中,获取图像的属性是一个非常基本且重要的操作,它涉及到获取图像的尺寸、数据类型、像素数等信息。以下是如何在 OpenCV 中获取这些基本图像属性的方法:
1. 图像尺寸
图像的尺寸可以通过图像数组的 shape 属性获得。对于彩色图像,shape 属性将返回一个包含行数(高度)、列数(宽度)和通道数的元组。对于灰度图像,shape 只返回行数和列数。
import cv2
# 加载图像
image = cv2.imread('path_to_image.jpg')
# 获取图像尺寸
height, width = image.shape[:2]
# 如果是彩色图像,还可以获取通道数
if len(image.shape) == 3:
channels = image.shape[2]
else:
channels = 1 # 灰度图像
2. 图像数据类型
图像的数据类型通常是 numpy 数组的数据类型。这可以通过访问图像数组的 dtype 属性获得。
# 获取图像数据类型
data_type = image.dtype
3. 像素总数
图像的像素总数可以通过 size 属性获得,它返回图像中的元素总数(高度 x 宽度 x 通道数)。
# 获取像素总数
total_pixels = image.size
4. 图像的每个通道的位深度
通常,标准的彩色图像每个通道的位深度是8位,这意味着每个通道的像素值范围是0到255。对于特定应用,如医学图像处理或高动态范围(HDR)图像,位深度可能更高。
示例代码
下面是一个完整的示例,演示如何获取一个图像的各种属性:
import cv2
# 加载图像
image = cv2.imread('path_to_image.jpg')
# 获取图像属性
height, width = image.shape[:2]
channels = 1 if len(image.shape) == 2 else image.shape[2]
data_type = image.dtype
total_pixels = image.size
# 打印图像属性
print(f"Height: {height}")
print(f"Width: {width}")
print(f"Channels: {channels}")
print(f"Data Type: {data_type}")
print(f"Total Pixels: {total_pixels}")
通过获取图像的这些基本属性,你可以更好地理解图像的结构和需要进行的处理类型。这对于后续的图像处理和分析任务非常重要。
第三章 图像处理高级技巧
3.1 图像加法运算
在 OpenCV 中,图像加法运算是一个基本的图像处理操作。这种操作可以用于多种目的,如图像融合、亮度增强等。OpenCV 提供了两种类型的图像加法:普通加法和饱和加法。
普通加法(加号运算符)
这是最直接的加法类型,其中两个图像或一个图像和一个标量值逐像素相加。这种加法不考虑值溢出的问题。如果计算结果超出了数据类型的范围,它将循环回到数据类型的最小值。在 Python 中,这可以通过使用 + 操作符或 numpy 的加法来实现。
import cv2
import numpy as np
# 加载两个图像
image1 = cv2.imread('path_to_image1.jpg')
image2 = cv2.imread('path_to_image2.jpg')
# 确保图像是相同大小
image2 = cv2.resize(image2, (image1.shape[1], image1.shape[0]))
# 普通加法
result = image1 + image2
饱和加法(OpenCV加法)
OpenCV 的 cv2.add() 函数执行饱和加法。在这种加法中,值在达到数据类型的最大值时饱和,不会发生循环。这是处理图像时更常用的方法,因为它可以防止像素值由于溢出而意外变暗。
# 饱和加法
result = cv2.add(image1, image2)
图像和标量的加法
需要注意,函数cv2.add()中的参数可能有如下三种形式。
-
形式1:计算结果=cv2.add(图像1,图像2),两个参数都是图像,此时参与运算的图像大小和类型必须保持一致。
-
形式2:计算结果=cv2.add(数值,图像),第1个参数是数值,第2个参数是图像,此时将超过图像饱和值的数值处理为饱和值(最大值)。
-
形式3:计算结果=cv2.add(图像,数值),第1个参数是图像,第2个参数是数值,此时将超过图像饱和值的数值处理为饱和值(最大值)。
注意事项
- 在进行图像加法之前,确保两个图像具有相同的大小和类型。
- 如果图像大小不同,你可能需要先调整它们的大小以确保它们匹配。
- 在处理颜色图像时,确保它们都在相同的颜色空间中(通常是 BGR)。
代码示例
分别使用加号运算符和函数cv2.add()计算两幅灰度图像的像素值之和,观察处理结果。
import cv2
a=cv2.imread("lena.bmp",0)
b=a
result1=a+b
result2=cv2.add(a, b)
cv2.imshow("original", a)
cv2.imshow("result1", result1)
cv2.imshow("result2", result2)
cv2.waitKey()
cv2.destroyAllWindows()
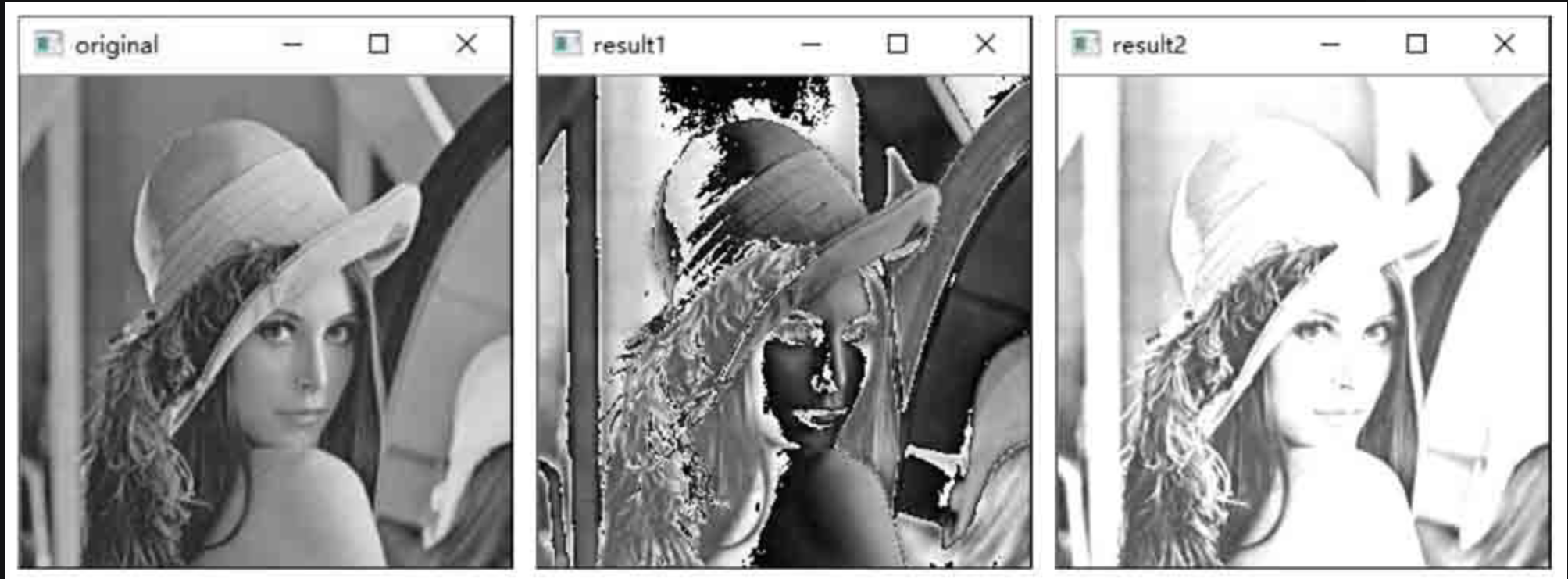
-
使用加号运算符计算图像像素值的和时,将和大于255的值进行了取模处理,取模后大于255的这部分值变得更小了,导致本来应该更亮的像素点变得更暗了,相加所得的图像看起来并不自然。
-
使用函数cv2.add()计算图像像素值的和时,将和大于255的值处理为饱和值255。图像像素值相加后让图像的像素值增大了,图像整体变亮。
3.2 图像加权和
3.3 按位逻辑运算
当然,我将为每个按位逻辑运算提供相关的 OpenCV 函数及其基本用法。这些函数是 OpenCV 库中处理图像的基本工具,用于执行各种像素级别的操作。
1. 按位与(AND) - cv2.bitwise_and()
按位与操作在两个图像的对应像素都为1(或255,对于8位图像)时返回1,否则返回0。这在掩模操作中非常有用。这个函数用于执行两个图像之间的按位与操作。如果你有一个掩码图像,这个函数也可以用来只在掩码的非零区域上应用操作。
bitwise_and = cv2.bitwise_and(src1, src2, mask = mask)
src1,src2: 输入图像,尺寸和类型必须相同。mask(可选): 掩码图像,单通道,与源图像大小相同。仅在掩码的非零像素位置上应用按位与操作。
2. 按位或(OR) - cv2.bitwise_or()
按位或操作在两个图像的对应像素中至少有一个为1时返回1,如果都为0则返回0。它通常用于合并图像。
这个函数用于执行两个图像之间的按位或操作。
bitwise_or = cv2.bitwise_or(src1, src2, mask = mask)
- 同
cv2.bitwise_and(),src1,src2是输入图像,mask是可选的掩码图像。
3. 按位非(NOT) - cv2.bitwise_not()
按位非操作对图像中的每个像素取反:1变为0,0变为1。这常用于图像反转或找到掩模的补集。
这个函数用于对单个图像执行按位取反操作,即将图像中的所有像素值反转。
bitwise_not = cv2.bitwise_not(src, mask = mask)
src: 输入图像。mask(可选): 掩码图像。
4. 按位异或(XOR) - cv2.bitwise_xor()
按位异或操作在两个图像的对应像素不相同时返回1,相同时返回0。它可用于图像比较。
这个函数用于执行两个图像之间的按位异或操作。
bitwise_xor = cv2.bitwise_xor(src1, src2, mask = mask)
- 同
cv2.bitwise_and()和cv2.bitwise_or(),src1,src2是输入图像,mask是可选的掩码图像。
示例代码:构造一个掩模图像,使用按位与运算保留图像中被掩模指定的部分。
在本例中,我们构造一个掩模图像,保留图像lena的头部。
import cv2
import numpy as np
a=cv2.imread("lena.bmp",0)
b=np.zeros(a.shape, dtype=np.uint8)
b[100:400,200:400]=255
b[100:500,100:200]=255
c=cv2.bitwise_and(a, b)
cv2.imshow("a", a)
cv2.imshow("b", b)
cv2.imshow("c", c)
cv2.waitKey()
cv2.destroyAllWindows()
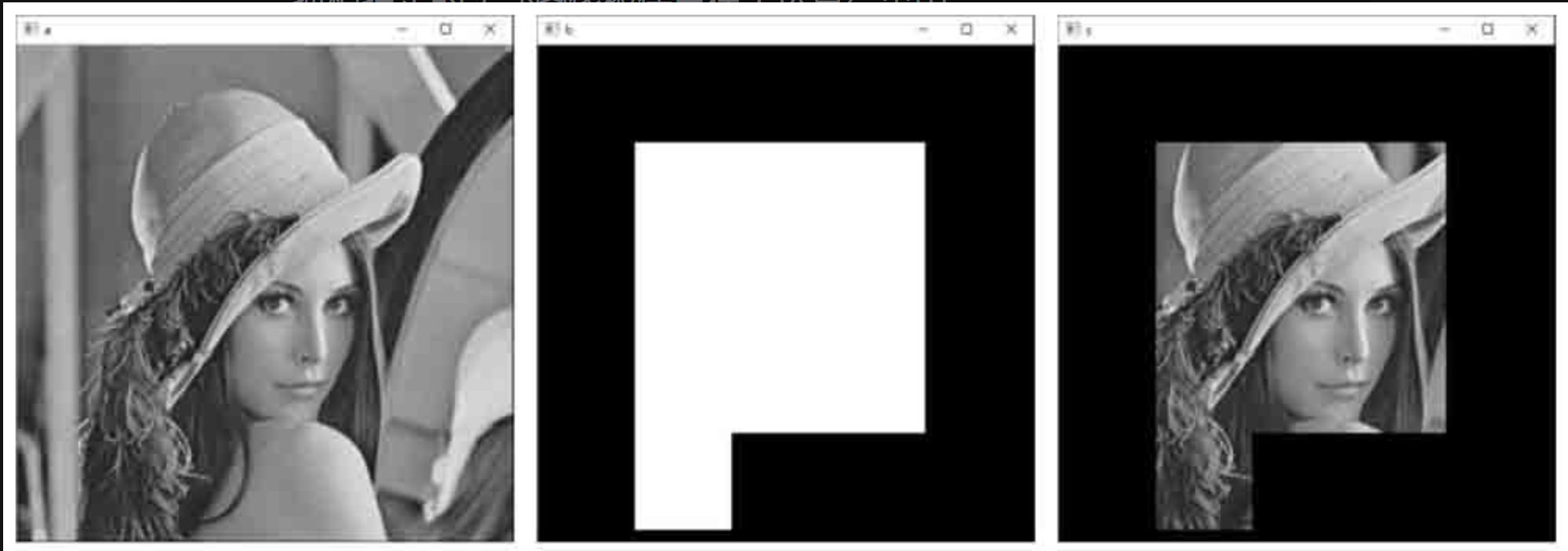
3.4 掩膜
在 OpenCV 中,掩模(mask)是一个非常有用的概念,它通常用于指定图像的某些区域以进行操作,同时保留其他区域不变。一个掩模是一个与原图像尺寸相同的数组,其中某些区域是零(或假),而其他区域是非零(或真)。通过这种方式,你可以选择性地对图像的特定部分应用操作,如图像处理、分割或特征提取。
基本概念
- 创建掩模:掩模通常是一个单通道的二值图像,其中非零像素表示我们感兴趣的区域,零像素表示我们不关心的区域。
- 使用掩模:在应用图像操作时,掩模用于指示操作应该影响的图像区域。
创建掩模
你可以使用不同的方法创建掩模,例如使用阈值操作、图像分割技术或简单的 NumPy 操作。
import cv2
import numpy as np
# 加载图像
image = cv2.imread('path_to_image.jpg')
# 创建一个同样大小的掩模
mask = np.zeros(image.shape[:2], dtype=np.uint8)
# 假设我们想要关注图像的一个特定区域
# 我们可以将这个区域在掩模中设置为白色(255)
mask[100:200, 100:200] = 255
使用掩模
一旦你有了掩模,就可以将其用于各种图像操作中,如掩模加法、按位操作等。
掩模加法
这可以将两个图像相加,但只在掩模指定的区域内。
# 掩模加法
result = cv2.add(image, image, mask=mask)
按位操作
按位操作(如按位与、按位或)允许你执行更复杂的操作,如将掩模区域内的图像与另一个图像合并。
# 创建一个输出图像
output = np.zeros_like(image)
# 将掩模区域的图像复制到输出图像
cv2.bitwise_and(image, image, mask=mask, dst=output)
注意事项
- 确保掩模的大小与原始图像相匹配。
- 掩模通常是单通道的,即使原始图像是多通道的。
- 在某些操作中,零值表示“不操作”,非零值表示“操作”。了解你正在使用的特定函数或方法的文档是很重要的。
掩模在图像处理中是一个非常强大的工具,可以用来指定感兴趣的区域、保护某些区域不受处理影响或将操作局限于特定区域。
3.5 图像与数值的运算
3.6 位平面分解
3.7 图像加密和解密
3.8 数字水印
3.9 脸部打码及解码
第四章 色彩空间类型转换
4.1 色彩空间基础
4.2 类型转换函数
在 OpenCV 中,cv2.cvtColor() 函数用于在不同的颜色空间之间转换图像。这个函数非常有用,因为它让你能够将图像从一个颜色空间转换到另一个颜色空间,例如从 BGR 转换到灰度或从 BGR 转换到 HSV。
函数原型是:
dst = cv2.cvtColor(src, code[, dst[, dstCn]])
- src: 输入图像。
- code: 转换代码,指示如何进行转换。
- dst: 输出图像;它与输入图像有相同的大小和深度。(非必传)
- dstCn: 输出图像的通道数;如果参数是 0,则通道数是从源图像和代码自动推断出来的。(非必传)
常见的颜色空间转换
-
BGR ↔ Gray: 在 BGR 和灰度图像之间转换。
gray_image = cv2.cvtColor(color_image, cv2.COLOR_BGR2GRAY) color_image = cv2.cvtColor(gray_image, cv2.COLOR_GRAY2BGR) -
BGR ↔ HSV: 在 BGR 和 HSV 之间转换。HSV 颜色空间经常用于颜色分割。
hsv_image = cv2.cvtColor(color_image, cv2.COLOR_BGR2HSV) color_image = cv2.cvtColor(hsv_image, cv2.COLOR_HSV2BGR) -
BGR ↔ YCrCb: 在 BGR 和 YCrCb 之间转换。YCrCb 通常用于人脸检测。
ycrcb_image = cv2.cvtColor(color_image, cv2.COLOR_BGR2YCrCb) color_image = cv2.cvtColor(ycrcb_image, cv2.COLOR_YCrCb2BGR) -
BGR ↔ RGB: 在 BGR 和 RGB 之间转换。用于图像显示和图像保存
rgb_image = cv2.cvtColor(bgr_image, cv2.COLOR_BGR2RGB) bgr_image = cv2.cvtColor(rgb_image, cv2.COLOR_RGB2BGR)
注意事项
- 在使用
cv2.cvtColor()之前,确保输入图像是有效的,并且它的类型和内容符合你想要转换的颜色空间的要求。 - 颜色空间转换不是无损的。转换图像到另一种颜色空间,然后再转换回来,可能不会得到与原始图像完全相同的结果。
- 在处理视频流或实时图像时,考虑性能,因为颜色空间转换可能是计算密集型的。
4.3 类型转换实例
代码示例
将图像从BGR模式转换为RGB模式
import cv2
lena=cv2.imread("lenacolor.png")
rgb = cv2.cvtColor(lena, cv2.COLOR_BGR2RGB)
cv2.imshow("lena", lena)
cv2.imshow("rgb", rgb)
cv2.waitKey()
cv2.destroyAllWindows()
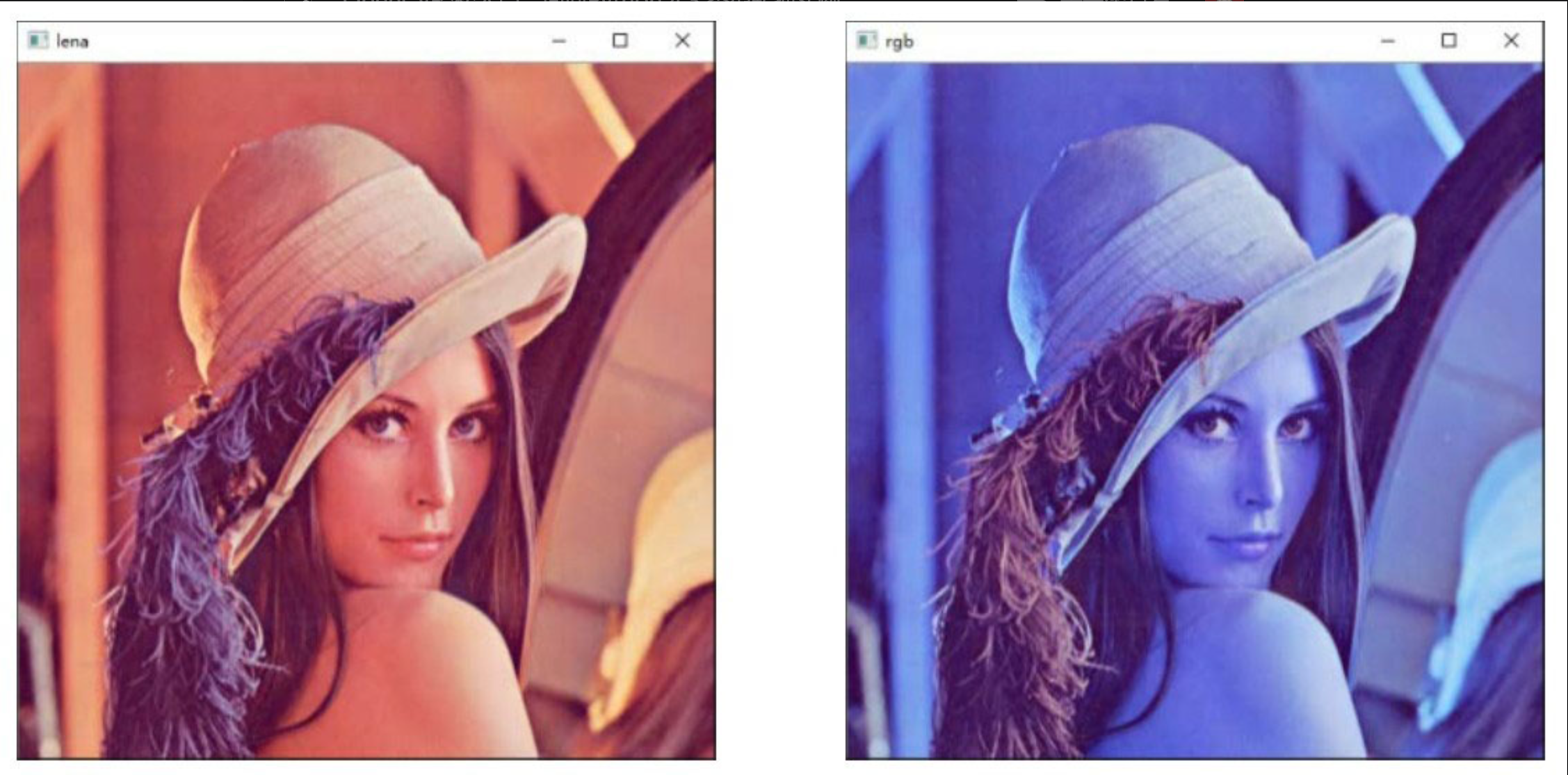
左图是BGR通道顺序的图像,右图是RGB通道顺序的图像。可以看到,读取的lena图像在BGR模式下正常显示,将其调整为RGB通道顺序后,显示的图像呈现浅蓝色。
4.4 HSV色彩空间讨论
4.5 Alpha通道
第五章 几何变换
5.1 缩放
在 OpenCV 中,cv2.resize() 函数用于调整图像的尺寸。这个函数可以放大或缩小图像,对于图像预处理、特征提取或将图像输入到特定算法中时需要特定尺寸的图像时非常有用。
函数原型
dst = cv2.resize(src, dsize[, dst[, fx[, fy[, interpolation]]]])
- src: 输入图像。
- dsize: 输出图像的尺寸。以元组形式给出 (宽度, 高度)。
- dst (可选): 输出图像。
- fx (可选): 沿水平轴的比例因子。如果它是 0,它会从
dsize计算得出。 - fy (可选): 沿垂直轴的比例因子。如果它是 0,它会从
dsize计算得出。 - interpolation (可选): 插值方法。插值方法决定了在调整图像大小时如何计算新像素值。常用的插值方法有:
cv2.INTER_NEAREST- 最近邻插值cv2.INTER_LINEAR- 双线性插值(默认)cv2.INTER_AREA- 区域插值,适合图像缩小cv2.INTER_CUBIC- 双三次插值,适合图像放大cv2.INTER_LANCZOS4- Lanczos 插值
使用示例
以下是一个简单的使用示例,演示了如何用 cv2.resize() 函数缩小和放大图像:
import cv2
# 加载图像
image = cv2.imread('path_to_image.jpg')
# 缩小图像到一半大小
resized_image_half = cv2.resize(image, None, fx=0.5, fy=0.5)
# 将图像大小调整为 300x300
resized_image_300x300 = cv2.resize(image, (300, 300))
# 放大图像到两倍大小,使用双三次插值
resized_image_double = cv2.resize(image, None, fx=2, fy=2, interpolation=cv2.INTER_CUBIC)
# 显示图像
cv2.imshow('Original image', image)
cv2.imshow('Resized image (half)', resized_image_half)
cv2.imshow('Resized image (300x300)', resized_image_300x300)
cv2.imshow('Resized image (double)', resized_image_double)
cv2.waitKey(0)
cv2.destroyAllWindows()
注意事项
- 当调整图像大小时,选择正确的插值方法很重要,因为它会影响输出图像的质量。
- 对于缩小图像,通常推荐使用
cv2.INTER_AREA。 - 对于放大图像,
cv2.INTER_CUBIC和cv2.INTER_LINEAR是比较好的选择。 - 插值方法的选择取决于具体应用和对图像质量的要求。
5.2 翻转
在 OpenCV 中,cv2.flip() 函数用于翻转图像。这个函数可以水平、垂直或同时进行水平和垂直翻转。它对于图像处理、数据增强或简单的图像效果非常有用。
函数原型
dst = cv2.flip(src, flipCode)
- src: 输入图像。
- flipCode: 翻转方向的指示符。
flipCode = 0: 沿x轴翻转,即垂直翻转。flipCode > 0: 沿y轴翻转,即水平翻转。flipCode < 0: 同时沿x轴和y轴翻转,即对角线翻转。
使用示例1
以下是一个简单的使用示例,演示了如何用 cv2.flip() 函数进行不同方向的翻转:
import cv2
# 加载图像
image = cv2.imread('path_to_image.jpg')
# 垂直翻转图像
flip_vertical = cv2.flip(image, 0)
# 水平翻转图像
flip_horizontal = cv2.flip(image, 1)
# 对角线翻转图像
flip_both = cv2.flip(image, -1)
# 显示图像
cv2.imshow('Original image', image)
cv2.imshow('Flip Vertical', flip_vertical)
cv2.imshow('Flip Horizontal', flip_horizontal)
cv2.imshow('Flip Both', flip_both)
cv2.waitKey(0)
cv2.destroyAllWindows()
使用示例2
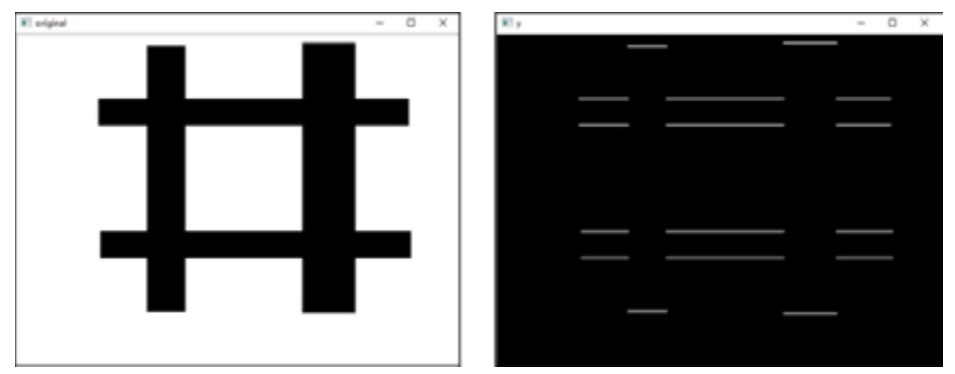
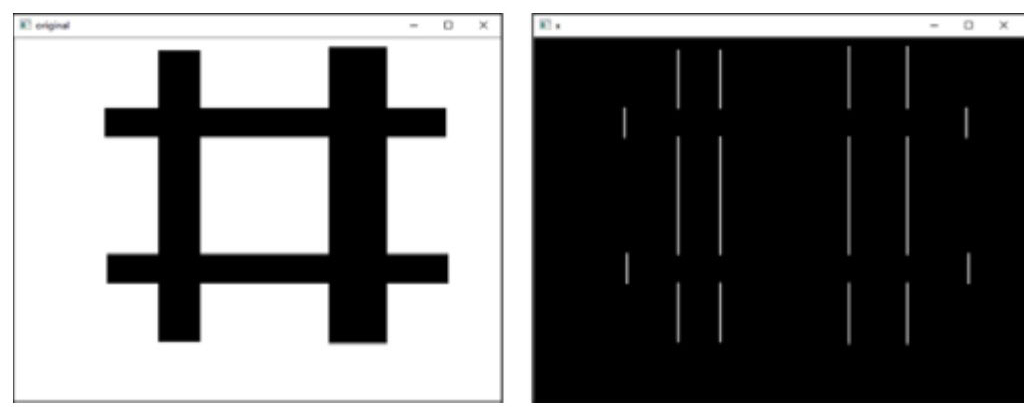
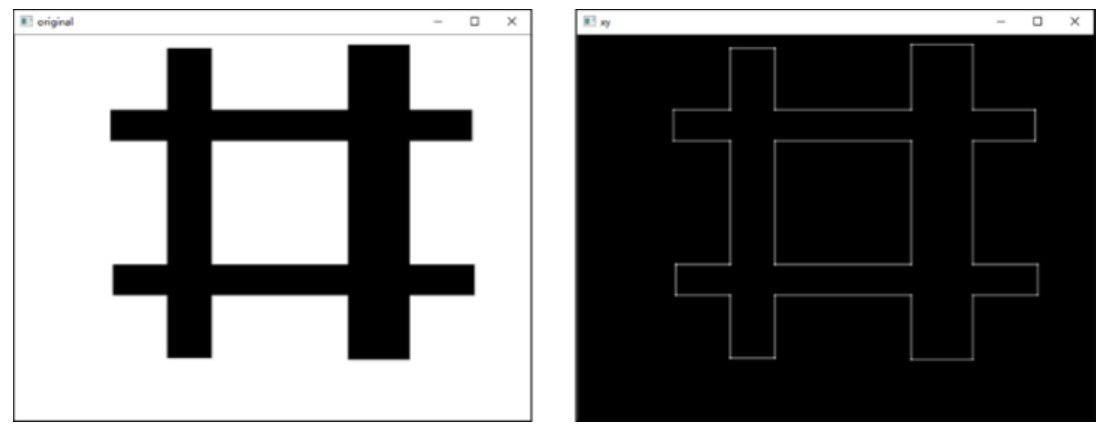
完成lena图像的翻转
import cv2
img=cv2.imread("lena.bmp")
# 垂直翻转图像
x=cv2.flip(img,0)
# 水平翻转图像
y=cv2.flip(img,1)
# 对角线翻转图像
xy=cv2.flip(img, -1)
cv2.imshow("img", img)
cv2.imshow("x", x)
cv2.imshow("y", y)
cv2.imshow("xy", xy)
cv2.waitKey()
cv2.destroyAllWindows()

-
图(a)是原始图像lena。
-
图(b)是语句x=cv2.flip(img,0)生成的图像,该图像由图像lena围绕x轴翻转得到。
-
图©是语句y=cv2.flip(img,1)生成的图像,该图像由图像lena围绕y轴翻转得到。
-
图(d)是语句xy=cv2.flip(img, -1)生成的图像,该图像由图像lena围绕x轴、y轴翻转得到。
注意事项
cv2.flip()是一个简单且有效的函数,它不仅可以用于图像效果处理,也适用于图像预处理,特别是在数据增强和深度学习训练数据准备中。- 在使用此函数时,确保
flipCode参数正确设置,以便按照你的需求翻转图像。
5.3 仿射
在 OpenCV 中,仿射变换是一种非常重要的图像处理技术。它是一种二维坐标到二维坐标的线性变换,保持了图像的直线性和平行性。这意味着在仿射变换之后,原图像中的所有直线仍然是直线,平行线仍然是平行的。
仿射变换的类型
- 平移:移动图像的位置。
- 缩放:更改图像的大小。
- 旋转:围绕某一点旋转图像。
- 倾斜:沿X轴、Y轴或两者将图像倾斜。
cv2.warpAffine() 是 OpenCV 中用于执行仿射变换的函数。仿射变换是一种保持图像直线和平行线关系不变的线性变换,它可以实现图像的旋转、缩放、平移和倾斜等操作。这个函数通过给定的变换矩阵对图像进行变换。
函数原型
dst = cv2.warpAffine(src, M, dsize[, dst[, flags[, borderMode[, borderValue]]]])
- src: 输入图像。
- M: 仿射变换矩阵,2x3 的浮点型矩阵。
- dsize: 输出图像的尺寸,以元组形式给出 (宽度, 高度)。
- dst (可选): 输出图像,与输入图像具有相同的类型。
- flags (可选): 插值方法。最常见的是
cv2.INTER_LINEAR和cv2.INTER_NEAREST。 - borderMode (可选): 边界像素模式。
- borderValue (可选): 当边界模式是
cv2.BORDER_CONSTANT时的边界值。
创建仿射变换矩阵
要使用 cv2.warpAffine(),首先需要创建一个仿射变换矩阵。这可以通过 cv2.getRotationMatrix2D() 来旋转图像,或者通过 cv2.getAffineTransform() 来实现更复杂的仿射变换。
旋转变换矩阵
# 获取旋转矩阵
# 参数分别是旋转中心、旋转角度和缩放比例
M = cv2.getRotationMatrix2D((width/2, height/2), angle, scale)
一般仿射变换矩阵
# 需要三个点及其在输出图像中的对应位置
pts1 = np.float32([[50,50], [200,50], [50,200]])
pts2 = np.float32([[10,100], [200,50], [100,250]])
# 获取仿射变换矩阵
M = cv2.getAffineTransform(pts1, pts2)
应用仿射变换
一旦有了仿射变换矩阵,就可以使用 cv2.warpAffine() 来应用它。
# 应用仿射变换
transformed_image = cv2.warpAffine(src, M, (width, height))
示例代码
下面是一个应用 cv2.warpAffine() 的简单示例,展示了如何对图像进行旋转。
import cv2
import numpy as np
# 加载图像
image = cv2.imread('path_to_image.jpg')
height, width = image.shape[:2]
# 创建旋转矩阵(以图像中心旋转45度,不缩放)
M = cv2.getRotationMatrix2D((width/2, height/2), 45, 1)
# 应用仿射变换
rotated_image = cv2.warpAffine(image, M, (width, height))
# 显示图像
cv2.imshow('Rotated Image', rotated_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
注意事项
- 在进行仿射变换时,输出图像的尺寸
dsize需要适当选择,以确保变换后的图像不会被裁剪或留下空白区域。 - 选择合适的插值方法(
flags参数)对于保持图像质量非常重要。例如,cv2.INTER_LINEAR适用于大多数情况。 - 变换矩阵
M决定了变换的类型和程度,正确设置它对于达到期望的变换效果至关重要。
5.4 透视
透视变换(Perspective Transformation)是计算机视觉和图像处理中的一种常见技术,用于改变图像视角,从而模拟在不同视点下观察到的场景。这种变换能够将图像中的一个平面从一个视角转换到另一个视角。它广泛应用于图像校正、3D重建和增强现实等领域。
原理
透视变换的核心在于将图像上的点从一个坐标系映射到另一个坐标系,同时保持直线的直线性(即直线在变换前后仍然是直线)。在透视变换中,直线的平行性可能不会被保持,这与仿射变换(保持平行性)不同。
关键步骤
透视变换通常包括以下几个步骤:
-
选择四个点:在原图像上选择四个点,这些点通常是某个矩形或四边形区域的四个角。
-
确定目标点:确定这四个点在目标图像上的对应位置。在许多应用中,这些目标点会形成一个矩形,以此来校正原始图像中的扭曲。
-
计算变换矩阵:使用原始点和目标点计算透视变换矩阵。在OpenCV中,这可以通过
cv2.getPerspectiveTransform函数实现。 -
应用变换:使用计算出的变换矩阵对原始图像进行透视变换。在OpenCV中,这可以通过
cv2.warpPerspective函数实现。
应用示例
透视变换的一个常见应用是文档扫描和校正。例如,如果文档的照片是从角度拍摄的,透视变换可以用来校正图像,使文档看起来就像是正对着拍摄的。通过选择文档的四个角作为源点,然后将这些点映射到一个矩形中,可以实现这种校正。
getPerspectiveTransform函数原型
这个函数常用于图像处理中的透视变换,例如将摄像头拍摄的图像转换为鸟瞰图,或者校正图像中的透视畸变。通过指定源点和目标点,该函数计算出一个矩阵,用于后续的图像变换处理。
函数原型:
M = cv2.getPerspectiveTransform(src, dst)
参数说明:
- src:源点坐标的数组。这个数组应该是一个大小为 4x2 或 1x8 的浮点数数组,包含四个点的坐标。这些点通常是图像中某个区域的四个角点。
- dst:目标点坐标的数组。这个数组也应该是一个大小为 4x2 或 1x8 的浮点数数组,包含变换后希望得到的四个点的坐标。
返回值:
- M:透视变换矩阵。这是一个 3x3 的浮点数数组,可用于
cv2.warpPerspective函数来进行实际的透视变换。
warpPerspective函数原型
这个函数广泛用于图像矫正、透视校正或创建场景的鸟瞰图等任务。可选参数提供了灵活性,尤其是在处理边界效应和选择变换的插值类型时。
函数原型:
warped_image = cv2.warpPerspective(src, M, dsize, flags=cv2.INTER_LINEAR, borderMode=cv2.BORDER_CONSTANT, borderValue=0)
参数描述:
-
src(必需):源图像,即要应用透视变换的输入图像。
-
M(必需):变换矩阵。这是一个3x3的浮点数矩阵,用于定义透视变换。通常由
cv2.getPerspectiveTransform函数获得。 -
dsize(必需):输出图像的大小。以元组
(width, height)的形式指定。 -
flags(可选):插值方法的组合(如
cv2.INTER_LINEAR,cv2.INTER_NEAREST等)和可选标志cv2.WARP_INVERSE_MAP,用于设置逆变换。默认值为cv2.INTER_LINEAR。 -
borderMode(可选):像素外推方法(如
cv2.BORDER_CONSTANT,cv2.BORDER_REPLICATE等)。它指定在变换过程中如何处理源图像的边界。默认值为cv2.BORDER_CONSTANT。 -
borderValue(可选):在使用常数边界时使用的值;默认为0。
返回值:
- warped_image:透视变换的结果。这是一个经过指定矩阵
M变换后的新图像。
例:简单示例
import cv2
import numpy as np
# 读取图像
image = cv2.imread('path_to_image.jpg')
# 设置原始点坐标和目标点坐标
pts_src = np.array([[x1, y1], [x2, y2], [x3, y3], [x4, y4]])
pts_dst = np.array([[0, 0], [width, 0], [width, height], [0, height]])
# 计算透视变换矩阵
M = cv2.getPerspectiveTransform(pts_src, pts_dst)
# 应用透视变换
warped = cv2.warpPerspective(image, M, (width, height))
例:将梯形透视变换成矩形
import cv2
import numpy as np
# 读取图像
img = cv2.imread('demo.bmp')
# 获取图像的行数和列数
rows, cols = img.shape[:2]
print(rows, cols)
# 定义源点坐标(透视变换前的坐标)
# 这里选取图像中的四个点
pts1 = np.float32([[150,50], [400,50], [60,450], [310,450]])
# 定义目标点坐标(透视变换后的坐标)
# 这里将图像的四个角点移动到新的位置
pts2 = np.float32([[50,50], [rows-50,50], [50, cols-50], [rows-50, cols-50]])
# 计算透视变换矩阵
M = cv2.getPerspectiveTransform(pts1, pts2)
# 应用透视变换
# 注意:透视变换的输出大小为 (cols, rows)
dst = cv2.warpPerspective(img, M, (cols, rows))
# 显示原始图像和变换后的图像
cv2.imshow("img", img)
cv2.imshow("dst", dst)
# 等待键盘输入,之后关闭所有窗口
cv2.waitKey()
cv2.destroyAllWindows()

5.5 重映射
第六章 阈值处理
6.1 threshold函数
cv2.threshold() 是 OpenCV 中用于进行图像阈值处理的函数。阈值处理是一种基本的图像分割技术,用于创建二值图像,其中像素要么是最大值(通常是255,表示白色),要么是最小值(通常是0,表示黑色),这取决于像素值是否高于或低于指定的阈值。
函数原型:
retval, dst = cv2.threshold(src, thresh, maxval, type)
参数说明:
-
src:输入图像,必须是单通道灰度图。
-
thresh:阈值。当像素值超过(或低于,取决于阈值类型)这个值时,它会被赋予新值。
-
maxval:当像素值超过(或等于,取决于阈值类型)阈值时赋予的最大值。
-
type:阈值类型。常见的类型包括:
cv2.THRESH_BINARY:如果像素值超过阈值,则赋予maxval;否则,赋予0。cv2.THRESH_BINARY_INV:THRESH_BINARY的反转。cv2.THRESH_TRUNC:如果像素值超过阈值,则赋予阈值;否则不变。cv2.THRESH_TOZERO:如果像素值低于阈值,则赋予0;否则不变。cv2.THRESH_TOZERO_INV:THRESH_TOZERO的反转。
返回值:
- retval:实际使用的阈值。
- dst:阈值处理后的输出图像。
下面是一个简单的例子,展示如何使用threshold函数:
import cv2
# 读取图像
image = cv2.imread('path_to_image.jpg', cv2.IMREAD_GRAYSCALE)
# 应用阈值
retval, thresholded = cv2.threshold(image, 127, 255, cv2.THRESH_BINARY)
# 显示图像
cv2.imshow('Original Image', image)
cv2.imshow('Thresholded Image', thresholded)
cv2.waitKey(0)
cv2.destroyAllWindows()
在这个例子中,我们读取了一个图像,将其转换为灰度图,然后应用了一个固定的阈值127。所有超过127的像素值被设置为255(白色),其他的都被设置为0(黑色),生成了一个二值图像。
6.2 自适应阈值处理
cv2.adaptiveThreshold() 是 OpenCV 中用于进行自适应阈值处理的函数。不同于简单的阈值处理(其中阈值是全局的,对整个图像应用),自适应阈值考虑图像的局部区域,因此可以在图像亮度不均匀的情况下得到更好的结果。
函数原型
dst = cv2.adaptiveThreshold(src, maxValue, adaptiveMethod, thresholdType, blockSize, C)
- src: 输入图像,必须是单通道、8位图像。
- maxValue: 阈值化后的非零像素值。
- adaptiveMethod: 自适应阈值算法。主要有两种类型:
cv2.ADAPTIVE_THRESH_MEAN_C:阈值是邻域区域的平均值减去常数C。cv2.ADAPTIVE_THRESH_GAUSSIAN_C:阈值是邻域区域的高斯加权和减去常数C。
- thresholdType: 阈值类型。通常是
cv2.THRESH_BINARY或cv2.THRESH_BINARY_INV。 - blockSize: 代表块大小。表示一个像素在计算其阈值时所使用的邻域尺寸,通常为3、5、7等。
- C: 一个常数,从平均值或加权平均值中减去,用于微调阈值。
使用示例
以下是一个使用自适应阈值处理图像的示例:
import cv2
img=cv2.imread("computer.jpg",0)
t1, thd=cv2.threshold(img,127,255, cv2.THRESH_BINARY)
athdMEAN=cv2.adaptiveThreshold(img,255, cv2.ADAPTIVE_THRESH_MEAN_C,cv2.THRESH_BINARY,5,3)
athdGAUS=cv2.adaptiveThreshold(img,255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C,cv2.THRESH_BINARY,5,3)
cv2.imshow("img", img)
cv2.imshow("thd", thd)
cv2.imshow("athdMEAN", athdMEAN)
cv2.imshow("athdGAUS", athdGAUS)
cv2.waitKey()
cv2.destroyAllWindows()

-
图(a)是原始图像。
-
图(b)是二值化阈值处理结果。
-
图©是自适应阈值采用方法cv2.ADAPTIVE_THRESH_MEAN_C的处理结果。
-
图(d)是自适应阈值采用方法cv2.ADAPTIVE_THRESH_GAUSSIAN_C的处理结果。
注意事项
- 自适应阈值处理特别适用于图像的局部区域具有不同亮度的情况。
blockSize应该是一个奇数,以便于在当前像素周围有一个均匀的邻域。- 选择适当的
C值对于获得良好的阈值结果至关重要。C值过高或过低都可能导致不良结果。 - 输入图像必须是灰度图,因此在应用自适应阈值之前,你可能需要先将图像转换为灰度。
6.3 Otsu处理
Otsu’s 方法是一种自动阈值确定的技术,用于将图像从灰度转换为二值(即黑白)。这种方法特别适用于图像的背景和前景有明显对比的情况。Otsu’s 方法通过最小化前景和背景的加权方差或最大化两者之间的类间方差来自动计算最优阈值。
在 OpenCV 中,Otsu’s 阈值处理可以结合 cv2.threshold() 函数使用。
函数原型
ret, dst = cv2.threshold(src, thresh, maxval, type)
要使用 Otsu’s 方法,你需要将 type 参数设置为 cv2.THRESH_BINARY | cv2.THRESH_OTSU。在这种情况下,thresh 参数会被忽略,Otsu’s 方法会自动计算最优阈值。
使用示例
以下是一个使用 Otsu’s 方法进行图像阈值处理的示例:
import cv2
img=cv2.imread("tiffany.bmp",0)
t1, thd=cv2.threshold(img,127,255, cv2.THRESH_BINARY)
t2, otsu=cv2.threshold(img,0,255, cv2.THRESH_BINARY+cv2.THRESH_OTSU)
cv2.imshow("img", img)
cv2.imshow("thd", thd)
cv2.imshow("otus", otsu)
cv2.waitKey()
cv2.destroyAllWindows()

-
图(a)是原始图像。
-
图(b)是进行普通二值化阈值处理,以127为阈值的处理结果。
-
图©是二值化阈值处理采用参数cv2.THRESH_OTSU后的处理结果。
注意事项
- Otsu’s 方法自动选择一个阈值,这意味着你不需要提前知道用于分离前景和背景的确切阈值。
- 这种方法对于图像的全局对比度高的场景效果最好,如果图像的局部区域有不同的亮度水平,Otsu’s 方法可能不会得到最佳结果。
- 输入图像必须是灰度图。如果你的原始图像是彩色的,你需要先将其转换为灰度图。
第七章 图像平滑处理
在尽量保留图像原有信息的情况下,过滤掉图像内部的噪声,这一过程称为对图像的平滑处理,所得的图像称为平滑图像。
7.1 均值滤波
均值滤波是指用当前像素点周围N·N个像素值的均值来代替当前像素值。使用该方法遍历处理图像内的每一个像素点,即可完成整幅图像的均值滤波。
在 OpenCV 中,cv2.blur() 函数用于对图像进行简单的平均模糊处理。这种模糊是通过将图像上的每个像素替换为其邻域像素的平均值来实现的。平均模糊可以用来去噪或降低图像的细节层次。
函数原型
dst = cv2.blur(src, ksize[, dst[, anchor[, borderType]]])
- src: 输入图像。它可以有任意数量的通道,并能对各个通道独立处理。
- ksize: 模糊核的大小,以元组形式给出 (宽度, 高度)。核的大小越大,模糊效果越明显。
- dst (可选): 输出图像。
- anchor (可选): 核的锚点。默认值 (-1, -1) 表示锚点位于核的中心。
- borderType (可选): 边界类型。
- 一般只要传src和ksize这两个参数就行。
使用示例1
以下是一个使用 cv2.blur() 对图像进行平均模糊处理的示例:
import cv2
o=cv2.imread("image\\lenaNoise.png") #读取待处理图像
r=cv2.blur(o, (5,5)) #使用blur函数处理
cv2.imshow("original", o)
cv2.imshow("result", r)
cv2.waitKey()
cv2.destroyAllWindows()

在这个例子中,使用了 5x5 的核对图像进行平均模糊处理。
使用示例二
针对噪声图像,使用不同大小的卷积核对其进行均值滤波,并显示均值滤波的情况。
import cv2
o=cv2.imread("image\\noise.bmp")
r5=cv2.blur(o, (5,5))
r30=cv2.blur(o, (30,30))
cv2.imshow("original", o)
cv2.imshow("result5", r5)
cv2.imshow("result30", r30)
cv2.waitKey()
cv2.destroyAllWindows()

从图中可以看出,使用5×5的卷积核进行滤波处理时,图像的失真不明显;而使用30×30的卷积核进行滤波处理时,图像的失真情况较明显。
注意事项
- 核的大小(
ksize)直接影响模糊的程度。核越大,模糊效果越强。 cv2.blur()适用于实现简单的模糊效果,但如果需要更复杂或特定类型的模糊效果(如高斯模糊、中值模糊等),则应该使用相应的其他 OpenCV 函数。- 平均模糊虽然可以减少图像噪声,但也会导致图像边缘和细节的损失。
7.2 方框滤波
7.3 高斯滤波
在进行均值滤波和方框滤波时,其邻域内每个像素的权重是相等的。在高斯滤波中,会将中心点的权重值加大,远离中心点的权重值减小,在此基础上计算邻域内各个像素值不同权重的和。
在 OpenCV 中,cv2.GaussianBlur() 函数用于应用高斯模糊,这是一种广泛使用的图像平滑技术。高斯模糊通过将每个像素的值替换为其邻域像素的加权平均值来实现,其中权重由高斯函数决定,使得靠近中心的像素比远离中心的像素具有更高的权重。
函数原型
dst = cv2.GaussianBlur(src, ksize, sigmaX[, dst[, sigmaY[, borderType]]])
- src: 输入图像。
- ksize: 高斯核的大小,以元组形式给出 (宽度, 高度)。宽度和高度应为正奇数。
- sigmaX: X方向上的高斯核标准差。如果指定为0,则从核大小计算得出。
- dst (可选): 输出图像。
- sigmaY (可选): Y方向上的高斯核标准差。如果为0,则将其设置与
sigmaX相同。 - borderType (可选): 边界类型。一般情况下,不需要考虑该值,直接采用默认值即可。
使用示例
以下是一个使用 cv2.GaussianBlur() 对图像进行高斯模糊处理的示例:
import cv2
o=cv2.imread("image\\lenaNoise.png")
r=cv2.GaussianBlur(o, (5,5),0,0)
cv2.imshow("original", o)
cv2.imshow("result", r)
cv2.waitKey()
cv2.destroyAllWindows()

注意事项
- 核的大小(
ksize)决定了模糊的程度。核越大,图像越模糊。 sigmaX和sigmaY值决定了高斯函数的“宽度”。这些值越大,权重分布越宽,导致更强的模糊效果。- 高斯模糊通常用于去除噪声、平滑图像,也常作为图像处理流程中的预处理步骤。
- 与简单的平均模糊(
cv2.blur())相比,高斯模糊考虑了像素间的空间距离,通常能更自然地模糊图像,保留更多的结构信息。
7.4 中值滤波
在 OpenCV 中,cv2.medianBlur() 函数用于实现中值模糊,这是一种非线性滤波技术,常用于去除图像中的椒盐噪声(salt-and-pepper noise)。中值模糊通过将每个像素值替换为其邻域(即核窗口内)像素值的中值来工作。这种方法在去除噪声的同时保持边缘相对锐利,使其成为处理包含此类噪声的图像的理想选择。
函数原型
dst = cv2.medianBlur(src, ksize)
- src: 输入图像,1通道或3通道的图像。
- ksize: 中值模糊的核大小,它必须是大于1的奇数。核的大小决定了滤波器的强度。
使用示例
以下是一个使用 cv2.medianBlur() 对图像进行中值模糊处理的示例:
import cv2
o=cv2.imread("image\\lenaNoise.png")
r=cv2.medianBlur(o,3)
cv2.imshow("original", o)
cv2.imshow("result", r)
cv2.waitKey()
cv2.destroyAllWindows()
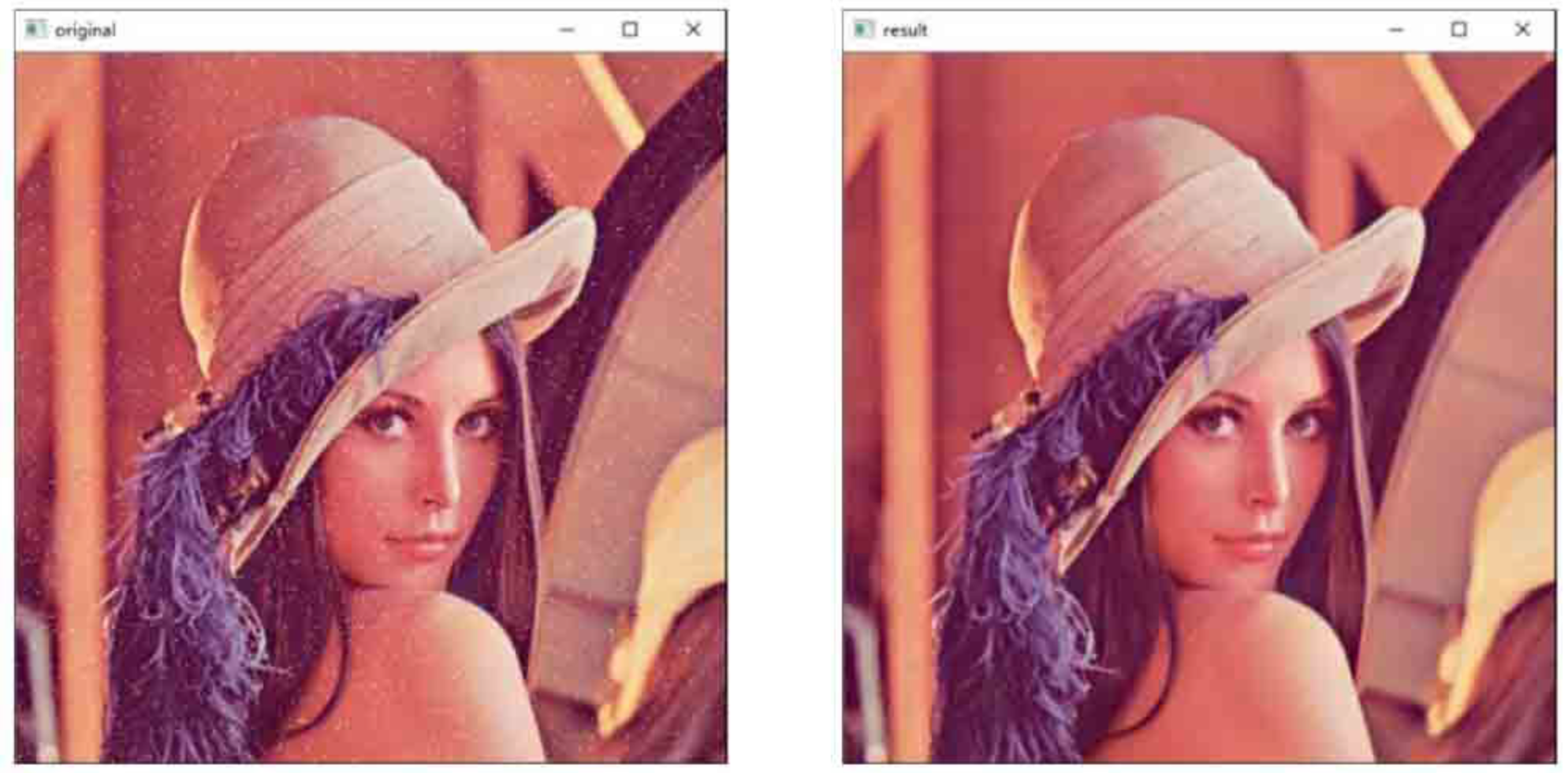
注意事项
- 中值模糊对于椒盐噪声非常有效,但可能不适用于其他类型的噪声。
- 核的大小(
ksize)应该是一个奇数。增加核的大小会增加模糊效果,但同时也可能导致图像细节的丢失。 - 与平均模糊或高斯模糊不同,中值模糊不计算像素邻域的平均值或加权平均值,而是直接取邻域内的中值。因此,它通常能更好地保留图像的边缘信息。
- 由于需要进行排序等操作,中值滤波需要的运算量较大。
7.5 双边滤波
cv2.bilateralFilter() 是 OpenCV 中的一个函数,用于实现双边滤波。双边滤波是一种高效的去噪方法,它在平滑图像的同时保留边缘。与其他滤波方法(如高斯模糊)相比,双边滤波在平滑图像噪声的同时,能更好地保持图像边缘的清晰度。
函数原型
dst = cv2.bilateralFilter(src, d, sigmaColor, sigmaSpace[, dst[, borderType]])
- src: 输入图像。
- d: 滤波时使用的各领域像素的直径。
- sigmaColor: 颜色空间的标准差。这个参数决定了哪些颜色在颜色空间中被认为是相似的。较大的值意味着更远的颜色将彼此影响,从而产生更大范围的颜色混合。
- sigmaSpace: 坐标空间中的标准差。较大的值意味着只有距离中心像素更远的像素才会相互影响,只要它们的颜色足够接近。
- dst (可选): 输出图像。
- borderType (可选): 边界类型。
工作原理
双边滤波在两个方面考虑了像素的相似性:空间相似性(像素之间的空间接近度)和颜色相似性(像素之间的颜色接近度)。这意味着它会考虑到邻近像素的位置和颜色差异,仅平滑那些在空间上接近且颜色相似的像素。这样,双边滤波可以有效地去除噪点,同时保留图像边缘和纹理细节。
应用场景
双边滤波常用于:
- 图像去噪,特别是在保留边缘信息时。
- 在图像风格化中,如在卡通化图像处理中模拟手绘效果。
- 作为图像预处理步骤,例如在边缘检测之前平滑图像。
注意事项
sigmaColor和sigmaSpace的选择对滤波效果有显著影响。较大的sigmaColor和sigmaSpace值将增加滤波的强度,但可能导致图像的过度平滑。- 双边滤波相对于其他类型的滤波(如高斯模糊)在计算上更为昂贵,因此在实时应用中可能需要考虑其性能影响。
- 双边滤波尤其适合于那些需要平滑图像而又不希望丢失边缘信息的应用场景。
代码示例1
import cv2
o=cv2.imread("image\\lenaNoise.png")
r=cv2.bilateralFilter(o,25,100,100)
cv2.imshow("original", o)
cv2.imshow("result", r)
cv2.waitKey()
cv2.destroyAllWindows()
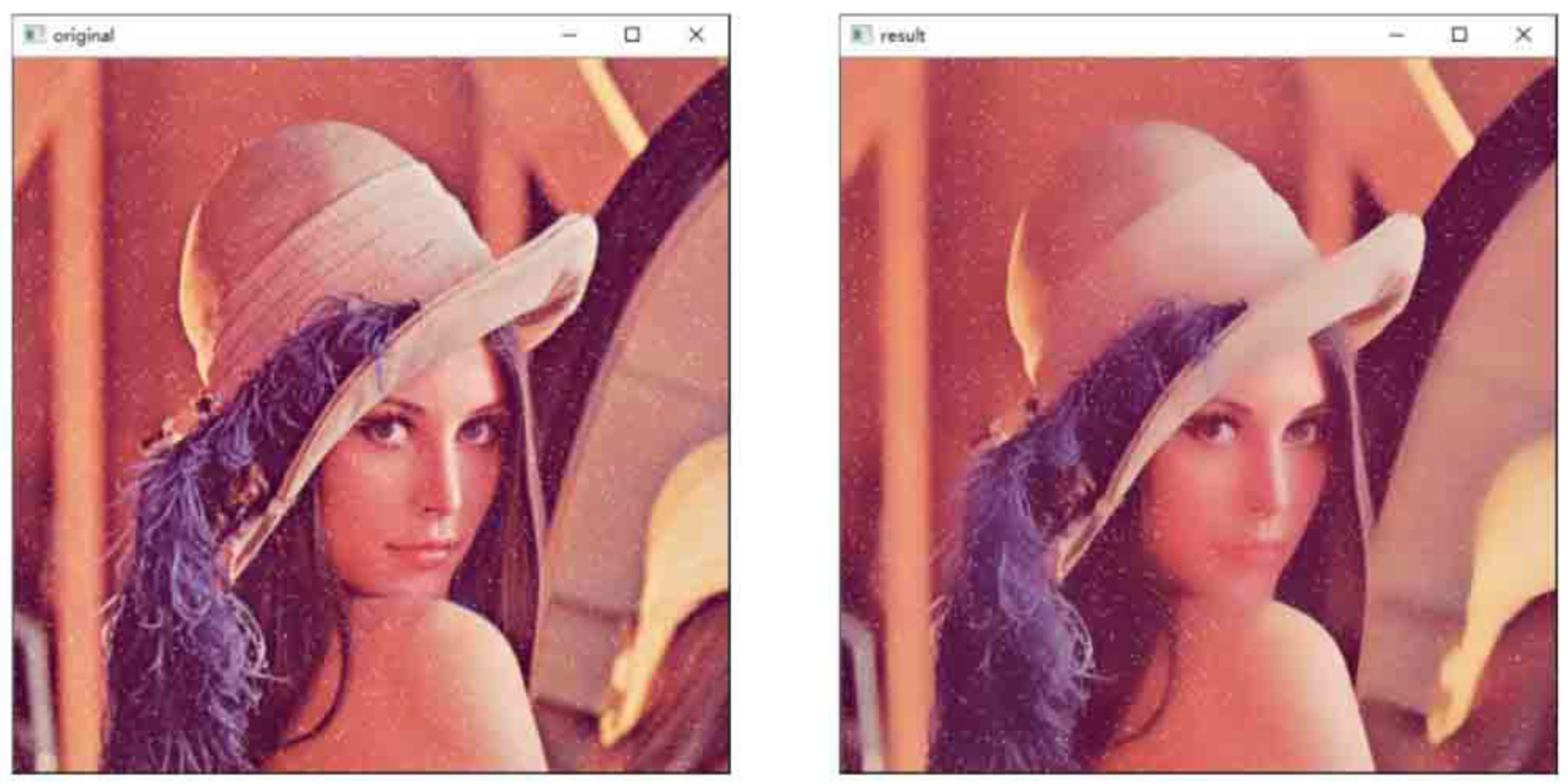
- 从图中可以看出,双边滤波去除噪声的效果并不好。
代码示例2
针对噪声图像,分别对其进行高斯滤波和双边滤波,比较不同滤波方式对边缘的处理结果是否相同。
import cv2
o=cv2.imread("image\\bilTest.bmp")
g=r=cv2.GaussianBlur(o, (55,55),0,0)
b=cv2.bilateralFilter(o,55,100,100)
cv2.imshow("original", o)
cv2.imshow("Gaussian", g)
cv2.imshow("bilateral", b)
cv2.waitKey()
cv2.destroyAllWindows()

- 从图中可以看到,经过高斯滤波的边缘被模糊虚化了,而经过双边滤波的边缘得到了较好的保留。
7.6 2D卷积
第八章 形态学操作
形态学,即数学形态学(Mathematical Morphology),是图像处理过程中一个非常重要的研究方向。形态学主要从图像内提取分量信息,该分量信息通常对于表达和描绘图像的形状具有重要意义,通常是图像理解时所使用的最本质的形状特征。例如,在识别手写数字时,能够通过形态学运算得到其骨架信息,在具体识别时,仅针对其骨架进行运算即可。形态学处理在视觉检测、文字识别、医学图像处理、图像压缩编码等领域都有非常重要的应用。
形态学操作主要包含:腐蚀、膨胀、开运算、闭运算、形态学梯度(Morphological Gradient)运算、顶帽运算(礼帽运算)、黑帽运算等操作。腐蚀操作和膨胀操作是形态学运算的基础,将腐蚀和膨胀操作进行结合,就可以实现开运算、闭运算、形态学梯度运算、顶帽运算、黑帽运算、击中击不中等不同形式的运算。
8.1 腐蚀
腐蚀是最基本的形态学操作之一,它能够将图像的边界点消除,使图像沿着边界向内收缩,也可以将小于指定结构体元素的部分去除。腐蚀用来“收缩”或者“细化”二值图像中的前景,借此实现去除噪声、元素分割等功能。
左图是原始图像,右图是对其腐蚀的处理结果。

cv2.erode() 是 OpenCV 中用于图像腐蚀操作的函数。腐蚀是一种基本的形态学操作,通常用于消除图像中的小白噪声、分离或缩小图像中的对象,以及在图像中突出强调特定区域。
函数原型
dst = cv2.erode(src, kernel[, dst[, anchor[, iterations[, borderType[, borderValue]]]]])
- src: 输入图像。
- kernel: 用于腐蚀的结构元素。它是一个
numpy.ndarray,其中的非零元素决定了腐蚀操作的性质。你可以使用cv2.getStructuringElement()来生成特定形状的结构元素。 - dst (可选): 输出图像,与输入图像有相同的尺寸和类型。
- anchor (可选): 结构元素的锚点。默认值 (-1, -1) 表示锚点位于结构元素的中心。
- iterations (可选): 腐蚀的次数。默认为1。
- borderType (可选): 一般采用其默认值
cv2.BORDER_CONSTANT。 - borderValue (可选): 一般采用默认值。
工作原理
腐蚀操作通过在图像上滑动结构元素(也称为核),并将结构元素覆盖区域的最小值(通常是0)应用到输出图像的中心像素上来工作。这会导致图像中的高亮区域(白色区域)缩小,而暗区域(黑色区域)扩大。
应用场景
腐蚀操作常用于:
- 去除小白点或噪声。
- 分离彼此接触或重叠的对象。
- 作为开运算和闭运算的一部分,这两种运算是腐蚀和膨胀操作的结合,用于去噪和强调图像特征。
注意事项
- 结构元素(
kernel)的大小和形状对腐蚀的效果有重要影响。较大的核会产生更明显的腐蚀效果。 - 多次迭代会增加腐蚀的效果。
- 在选择腐蚀作为处理步骤时,需要注意它可能会改变图像中对象的大小和形状,有时会导致信息的丢失。
示例代码1
import cv2
import numpy as np
o=cv2.imread("erode.bmp", cv2.IMREAD_UNCHANGED)
kernel = np.ones((5,5), np.uint8)
erosion = cv2.erode(o, kernel)
cv2.imshow("orriginal", o)
cv2.imshow("erosion", erosion)
cv2.waitKey()
cv2.destroyAllWindows()

- 从图中可以看到,腐蚀操作将原始图像内的毛刺腐蚀掉了。
示例代码2
调节函数cv2.erode()的参数,观察不同参数控制下的图像腐蚀效果。
import cv2
import numpy as np
o=cv2.imread("erode.bmp", cv2.IMREAD_UNCHANGED)
kernel = np.ones((9,9), np.uint8)
erosion = cv2.erode(o, kernel, iterations = 5)
cv2.imshow("orriginal", o)
cv2.imshow("erosion", erosion)
cv2.waitKey()
cv2.destroyAllWindows()

- 从图中可以看到,腐蚀操作将原始图像内的毛刺腐蚀掉了,而且,由于本例使用了更大的核、更多的迭代次数,所以图像被腐蚀得更严重了。
8.2 膨胀
膨胀操作是形态学中另外一种基本的操作。膨胀操作和腐蚀操作的作用是相反的,膨胀操作能对图像的边界进行扩张。膨胀操作将与当前对象(前景)接触到的背景点合并到当前对象内,从而实现将图像的边界点向外扩张。如果图像内两个对象的距离较近,那么在膨胀的过程中,两个对象可能会连通在一起。膨胀操作对填补图像分割后图像内所存在的空白相当有帮助。二值图像的膨胀示例如图所示。
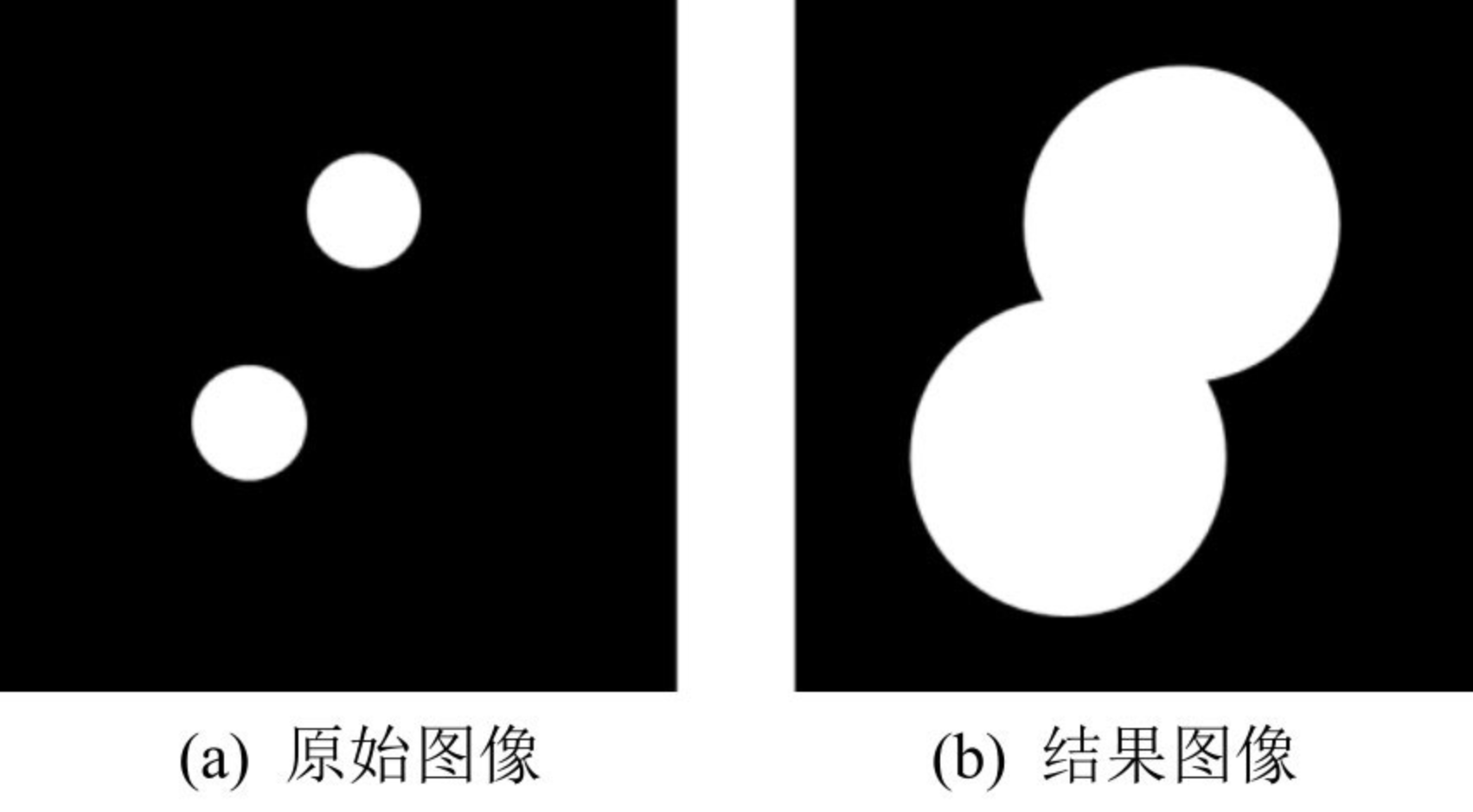
cv2.dilate() 是 OpenCV 中用于图像膨胀操作的函数。膨胀是形态学操作中的一个基本步骤,与腐蚀操作相反,它通常用于增加图像中对象的大小、填充对象内的小孔,以及连接靠近的元素。
函数原型
dst = cv2.dilate(src, kernel[, dst[, anchor[, iterations[, borderType[, borderValue]]]]])
- src: 输入图像。
- kernel: 用于膨胀的结构元素。这是一个
numpy.ndarray,其中的非零元素决定了膨胀操作的性质。你可以使用cv2.getStructuringElement()创建特定形状的结构元素。 - dst (可选): 输出图像,大小和类型与输入图像相同。
- anchor (可选): 结构元素的锚点。默认值 (-1, -1) 表示锚点位于结构元素的中心。
- iterations (可选): 膨胀操作的次数。默认为1。
- borderType (可选): 一般采用其默认值
cv2.BORDER_CONSTANT。 - borderValue (可选): 一般采用默认值。
工作原理
膨胀操作通过在图像上滑动结构元素(核),并将结构元素覆盖区域的最大值应用到输出图像的中心像素上来工作。这会导致图像中的暗区域缩小,而亮区域扩大。
应用场景
膨胀操作常用于:
- 增大图像中的白色区域或前景对象。
- 填充对象内部的小孔或裂缝。
- 增加相邻对象之间的连接。
- 在开运算(先腐蚀后膨胀)和闭运算(先膨胀后腐蚀)中与腐蚀结合使用,用于不同的图像处理任务。
注意事项
- 结构元素(
kernel)的大小和形状对膨胀的效果有显著影响。较大的核会产生更明显的膨胀效果。 - 多次迭代会增加膨胀的效果。
- 膨胀可以增加图像中对象的大小,但也可能导致对象之间的不期望的连接或信息的丢失,尤其是在对象间距较小的情况下。
示例代码1
import cv2
import numpy as np
o=cv2.imread("dilation.bmp", cv2.IMREAD_UNCHANGED)
kernel = np.ones((9,9), np.uint8)
dilation = cv2.dilate(o, kernel)
cv2.imshow("original", o)
cv2.imshow("dilation", dilation)
cv2.waitKey()
cv2.destroyAllWindows()

- 从图中可以看到,膨胀操作将原始图像“变粗”了。
示例代码2
import cv2
import numpy as np
o=cv2.imread("dilation.bmp", cv2.IMREAD_UNCHANGED)
kernel = np.ones((5,5), np.uint8)
dilation = cv2.dilate(o, kernel, iterations = 9)
cv2.imshow("original", o)
cv2.imshow("dilation", dilation)
cv2.waitKey()
cv2.destroyAllWindows()
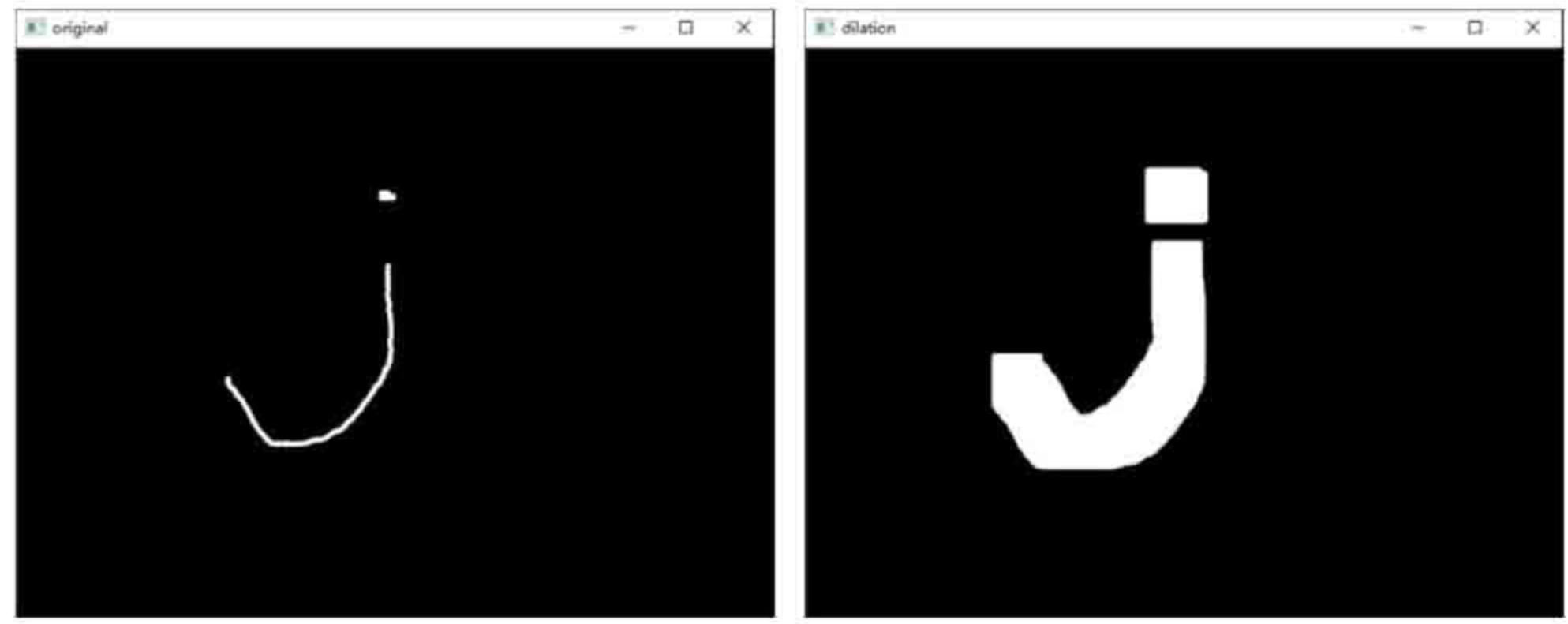
- 从图中可以看到,膨胀操作让原始图像实现了“生长”。在本例中,由于重复了9次,所以图像被膨胀得更严重了。
8.3 通用形态学函数
腐蚀操作和膨胀操作是形态学运算的基础,将腐蚀和膨胀操作进行组合,就可以实现开运算、闭运算(关运算)、形态学梯度(Morphological Gradient)运算、礼帽运算(顶帽运算)、黑帽运算、击中击不中等多种不同形式的运算。
在 OpenCV 中,cv2.morphologyEx() 函数用于执行各种高级形态学变换。这个函数通过结合基本的形态学操作(如腐蚀和膨胀)来实现更复杂的操作,例如开运算、闭运算、形态学梯度、顶帽运算和黑帽运算。
函数原型
dst = cv2.morphologyEx(src, op, kernel[, dst[, anchor[, iterations[, borderType[, borderValue]]]]])
- src: 输入图像。
- op: 形态学操作类型。它可以是以下之一:
cv2.MORPH_OPEN: 开运算(先腐蚀后膨胀)。cv2.MORPH_CLOSE: 闭运算(先膨胀后腐蚀)。cv2.MORPH_GRADIENT: 形态学梯度(膨胀图像与腐蚀图像之差)。cv2.MORPH_TOPHAT: 顶帽运算(原图像与开运算之差)。cv2.MORPH_BLACKHAT: 黑帽运算(闭运算与原图像之差)。
- kernel: 结构元素。可以使用
cv2.getStructuringElement()生成特定形状和大小的结构元素。 - dst (可选): 输出图像。
- anchor (可选): 结构元素的锚点。
- iterations (可选): 操作的迭代次数。
- borderType (可选): 边界类型。
- borderValue (可选): 边界值。
应用场景
- 开运算(Opening):用于去除小的白噪声,也可以用于断开两个接触的对象。
- 闭运算(Closing):用于填充对象内的小孔或小黑点,也可用于连接靠近的对象。
- 形态学梯度(Morphological Gradient):用于提取图像边缘。
- 顶帽(Top Hat):用于提取比邻近区域亮的小对象。
- 黑帽(Black Hat):用于提取比邻近区域暗的小对象。
注意事项
- 正确选择结构元素的形状和大小对于达到期望的形态学操作效果至关重要。
- 多次迭代可以增强形态学操作的效果,但也可能导致图像特征的过度改变。
- 形态学操作对于图像预处理和后处理非常有用,特别是在图像分割和特征提取中。
8.4 开运算
基础概念
开运算进行的操作是先将图像腐蚀,再对腐蚀的结果进行膨胀。开运算可以用于去噪、计数等。例如,在下图中,通过先腐蚀后膨胀的开运算操作实现了去噪。

开运算还可以用于计数。例如,在对下图中的区域进行计数前,可以利用开运算将连接在一起的不同区域划分开。

函数原型
通过将函数cv2.morphologyEx()中操作类型参数op设置为cv2.MORPH_OPEN,可以实现开运算。其语法结构如下:
opening = cv2.morphologyEx(img, cv2.MORPH_OPEN, kernel)
示例代码
import cv2
import numpy as np
img1=cv2.imread("opening.bmp")
img2=cv2.imread("opening2.bmp")
k=np.ones((10,10), np.uint8)
r1=cv2.morphologyEx(img1, cv2.MORPH_OPEN, k)
r2=cv2.morphologyEx(img2, cv2.MORPH_OPEN, k)
cv2.imshow("img1", img1)
cv2.imshow("result1", r1)
cv2.imshow("img2", img2)
cv2.imshow("result2", r2)
cv2.waitKey()
cv2.destroyAllWindows()

8.5 闭运算
基础概念
闭运算是先膨胀、后腐蚀的运算,它有助于关闭前景物体内部的小孔,或去除物体上的小黑点,还可以将不同的前景图像进行连接。
在下图中,通过先膨胀后腐蚀的闭运算去除了原始图像内部的小孔(内部闭合的闭运算)。

闭运算还可以实现前景图像的连接。例如,在下图中,利用闭运算将原本独立的两部分前景图像连接在一起

函数原型
通过将函数cv2.morphologyEx()中操作类型参数op设置为“cv2.MORPH_CLOSE”,可以实现闭运算。其语法结构如下:
closing = cv2.morphologyEx(img, cv2.MORPH_CLOSE, kernel)
示例代码
import cv2
import numpy as np
img1=cv2.imread("closing.bmp")
img2=cv2.imread("closing2.bmp")
k=np.ones((10,10), np.uint8)
r1=cv2.morphologyEx(img1, cv2.MORPH_CLOSE, k, iterations=3)
r2=cv2.morphologyEx(img2, cv2.MORPH_CLOSE, k, iterations=3)
cv2.imshow("img1", img1)
cv2.imshow("result1", r1)
cv2.imshow("img2", img2)
cv2.imshow("result2", r2)
cv2.waitKey()
cv2.destroyAllWindows()

8.6 形态学梯度运算
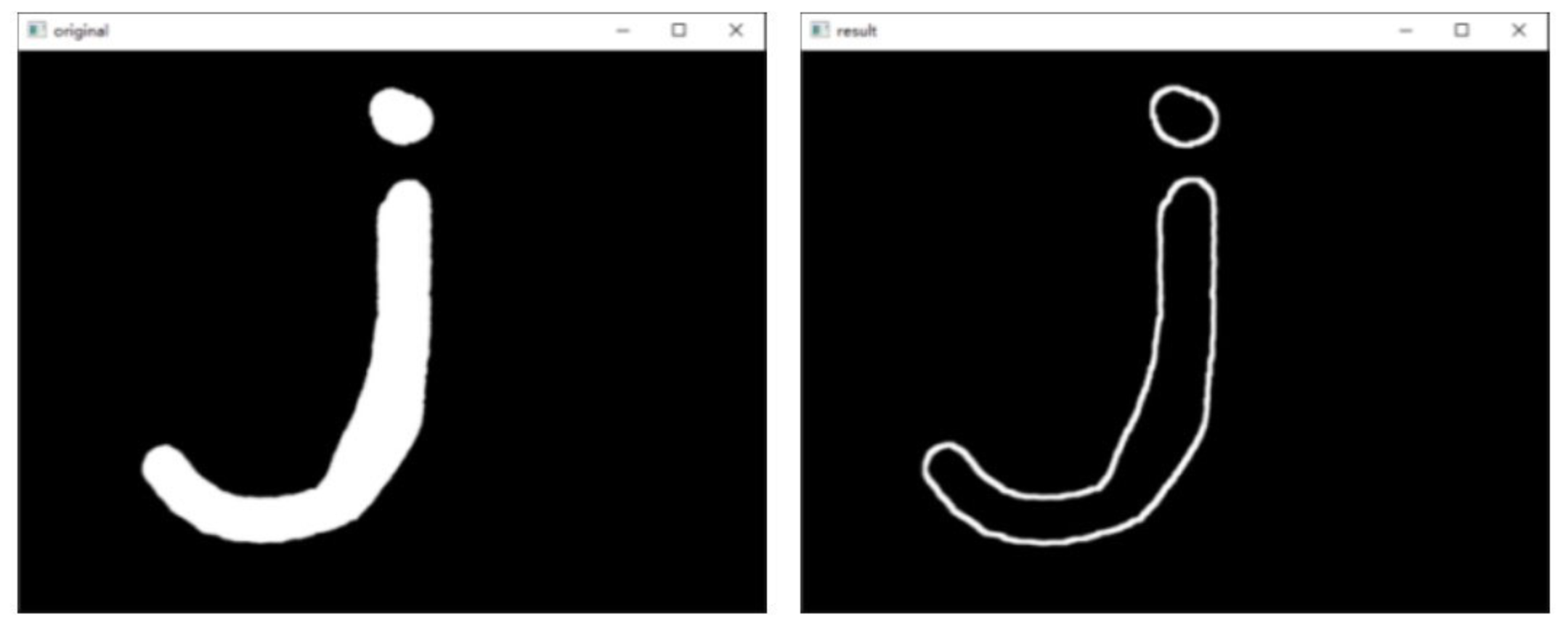
基础概念
形态学梯度运算是用图像的膨胀图像减腐蚀图像的操作,该操作可以获取原始图像中前景图像的边缘。
下图演示了形态学梯度运算。

函数原型
通过将函数cv2.morphologyEx()的操作类型参数op设置为“cv2.MORPH_GRADIENT”,可以实现形态学梯度运算。其语法结构如下:
result = cv2.morphologyEx(img, cv2.MORPH_GRADIENT, kernel)
示例代码
import cv2
import numpy as np
o=cv2.imread("gradient.bmp", cv2.IMREAD_UNCHANGED)
k=np.ones((5,5), np.uint8)
r=cv2.morphologyEx(o, cv2.MORPH_GRADIENT, k)
cv2.imshow("original", o)
cv2.imshow("result", r)
cv2.waitKey()
cv2.destroyAllWindows()
8.7 礼帽运算
基础概念
礼帽运算是用原始图像减去其开运算图像的操作。礼帽运算能够获取图像的噪声信息,或者得到比原始图像的边缘更亮的边缘信息。
下图是一个礼帽运算获取图像的噪声信息示例

下图是是比原始图像的边缘更亮的边缘信息

函数原型
通过将函数cv2.morphologyEx()中操作类型参数op设置为“cv2.MORPH_TOPHAT”,可以实现礼帽运算。其语法结构如下:
result = cv2.morphologyEx(img, cv2.MORPH_TOPHAT, kernel)
示例代码
import cv2
import numpy as np
o1=cv2.imread("tophat.bmp", cv2.IMREAD_UNCHANGED)
o2=cv2.imread("lena.bmp", cv2.IMREAD_UNCHANGED)
k=np.ones((5,5), np.uint8)
r1=cv2.morphologyEx(o1, cv2.MORPH_TOPHAT, k)
r2=cv2.morphologyEx(o2, cv2.MORPH_TOPHAT, k)
cv2.imshow("original1", o1)
cv2.imshow("original2", o2)
cv2.imshow("result1", r1)
cv2.imshow("result2", r2)
cv2.waitKey()
cv2.destroyAllWindows()

8.8 黑帽运算
基础概念
黑帽运算是用闭运算图像减去原始图像的操作。黑帽运算能够获取图像内部的小孔,或前景色中的小黑点,或者得到比原始图像的边缘更暗的边缘部分。
下图是获取图像内部的小孔的示例

下图是获取比原始图像的边缘更暗的边缘部分的示例

函数原型
通过将函数cv2.morphologyEx()中操作类型参数op设置为“cv2.MORPH_BLACKHAT”,可以实现黑帽运算。其语法结构如下:
result = cv2.morphologyEx(img, cv2.MORPH_BLACKHAT, kernel)
示例代码
import cv2
import numpy as np
o1=cv2.imread("blackhat.bmp", cv2.IMREAD_UNCHANGED)
o2=cv2.imread("lena.bmp", cv2.IMREAD_UNCHANGED)
k=np.ones((5,5), np.uint8)
r1=cv2.morphologyEx(o1, cv2.MORPH_BLACKHAT, k)
r2=cv2.morphologyEx(o2, cv2.MORPH_BLACKHAT, k)
cv2.imshow("original1", o1)
cv2.imshow("original2", o2)
cv2.imshow("result1", r1)
cv2.imshow("result2", r2)
cv2.waitKey()
cv2.destroyAllWindows()

8.9 核函数
在 OpenCV 中,cv2.getStructuringElement() 函数用于生成指定形状和大小的结构元素,这些结构元素常用于形态学操作,如腐蚀、膨胀、开运算和闭运算等。结构元素是一个矩阵,用于决定形态学操作的性质。
函数原型
element = cv2.getStructuringElement(shape, ksize[, anchor])
- shape: 结构元素的形状。常用的形状包括:
cv2.MORPH_RECT: 矩形结构元素。cv2.MORPH_ELLIPSE: 椭圆形结构元素。cv2.MORPH_CROSS: 十字形结构元素。
- ksize: 结构元素的大小,以元组形式给出 (宽度, 高度)。
- anchor (可选): 结构元素的锚点。默认值 (-1, -1) 表示锚点位于结构元素的中心。
结构元素的选择
- 矩形(MORPH_RECT):在每个像素的邻域内进行统一处理时适用。通常用于腐蚀和膨胀操作。
- 椭圆形(MORPH_ELLIPSE):当需要更平滑的边界或者模仿光圈的形状时使用。
- 十字形(MORPH_CROSS):主要用于保留交叉点信息,如在细化或骨架化算法中。
应用场景
- 结构元素是形态学操作的关键组成部分,其形状和大小直接影响操作的效果。
- 在不同的应用场景中,选择合适的结构元素形状和大小对于实现期望的图像处理效果非常重要。
注意事项
- 结构元素的大小(
ksize)不应该过大,以避免过度改变图像的特征。 - 锚点(
anchor)通常设为默认,即结构元素的中心。如果需要,可以修改锚点位置以改变形态学操作的行为。 - 不同的结构元素形状对于同一形态学操作可能会产生截然不同的效果。
第九章 图像梯度
图像梯度计算的是图像变化的速度。对于图像的边缘部分,其灰度值变化较大,梯度值也较大;相反,对于图像中比较平滑的部分,其灰度值变化较小,相应的梯度值也较小。一般情况下,图像梯度计算的是图像的边缘信息。
严格来讲,图像梯度计算需要求导数,但是图像梯度一般通过计算像素值的差来得到梯度的近似值(近似导数值)。
9.1 Sobel理论基础
Sobel算子概述
Sobel算子是一种用于边缘检测的算法,在图像处理和计算机视觉中应用广泛。它主要用于计算图像灰度的一阶导数,从而突出显示图像中的边缘。
工作原理
Sobel算子的工作原理基于图像的空间梯度计算。它使用两个3x3的卷积核(或滤波器)来估计图像中每个像素点的横向和纵向灰度变化率。
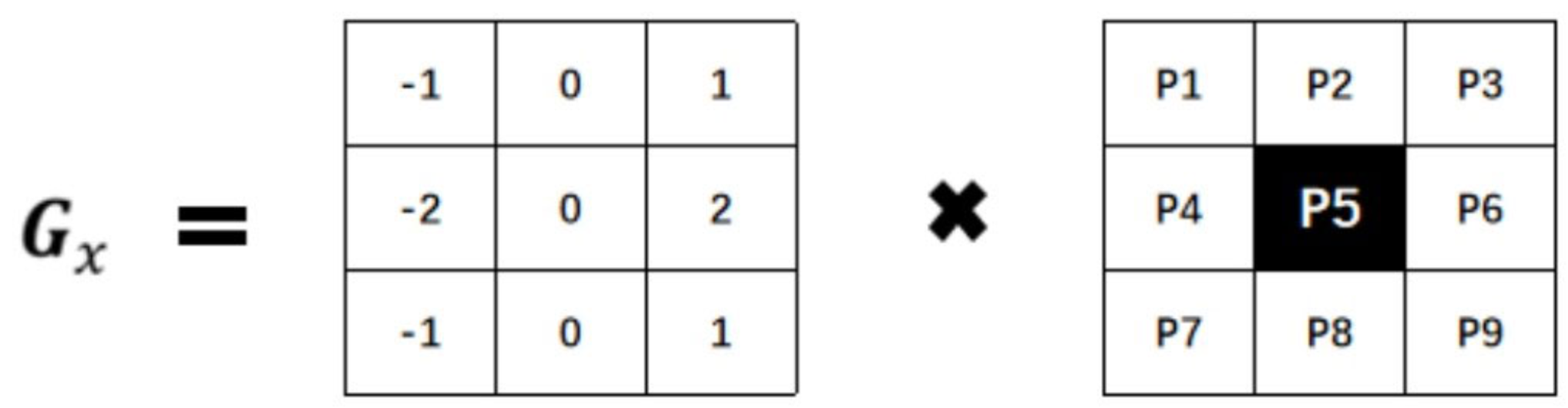
卷积核
Sobel算子有两个主要的卷积核:
- 水平方向核 (Gx): 用于检测垂直边缘。
-1 0 1 -2 0 2 -1 0 1 - 垂直方向核 (Gy): 用于检测水平边缘。
-1 -2 -1 0 0 0 1 2 1
边缘检测步骤
-
灰度化: Sobel算子通常在灰度图像上操作,因为它是基于灰度强度变化来检测边缘。
-
应用卷积核: 将上述两个核分别应用于图像,计算每个方向上的梯度(Gx和Gy)。
-
当Sobel算子的大小为3×3时,水平方向偏导数Gx的计算方式为:

上式中,src是原始图像,假设其中有9个像素点
-
当Sobel算子的大小为3×3时,垂直方向偏导数Gy的计算方式为

上式中,src是原始图像,假设其中有9个像素点

-
-
计算梯度的幅度和方向:
- 梯度幅度:
G = sqrt(Gx^2 + Gy^2)。这个值表示边缘的强度。 - 梯度方向:
θ = atan2(Gy, Gx)。这个值表示边缘的方向。
- 梯度幅度:
-
阈值处理: 通常会设置一个阈值来确定哪些梯度强度足够大,可以视为边缘。
Sobel算子的特点
- 抗噪声能力: 相比于其他边缘检测算子(如Prewitt或Roberts算子),Sobel算子对噪声更为鲁棒。
- 方向敏感性: 可以分别检测水平和垂直方向上的边缘。
- 运算简单: 使用卷积核进行运算,计算过程简单高效。
应用
Sobel算子在图像分析领域有着广泛的应用,包括图像边缘检测、特征提取、图像分割等。由于其相对简单且有效的特点,它常被用作图像预处理的一步,为更复杂的图像处理和分析任务做准备。
9.2 Sobel算子及函数使用
cv2.Sobel() 是 OpenCV 中用于执行 Sobel 边缘检测的函数。Sobel 算子是一种用于边缘检测的离散微分算子,它通过计算图像灰度的空间梯度来突出显示图像中的边缘区域。
函数原型
dst = cv2.Sobel(src, ddepth, dx, dy[, dst[, ksize[, scale[, delta[, borderType]]]]])
- src: 输入图像。
- ddepth: 输出图像的所需深度,通常为cv2.CV_64F。
- dx: X方向上的导数的阶数。
- dy: Y方向上的导数的阶数。
- dst (可选): 输出图像。
- ksize (可选): Sobel 核的大小。值为 1、3、5 或 7。
- scale (可选): 计算导数值时可选的缩放因子。
- delta (可选): 可选的增量,将添加到结果中。
- borderType (可选): 图像边界的模式。
Sobel 边缘检测
- Sobel 算子通过对输入图像进行卷积来计算图像在水平和垂直方向的一阶导数,从而检测出图像中的水平和垂直边缘。
- 可以通过调整
dx和dy的值来控制边缘检测的方向。例如,dx = 1和dy = 0将检测水平边缘,而dx = 0和dy = 1将检测垂直边缘。 ksize参数控制 Sobel 核的大小,较大的核会导致边缘更平滑。
边缘检测类型
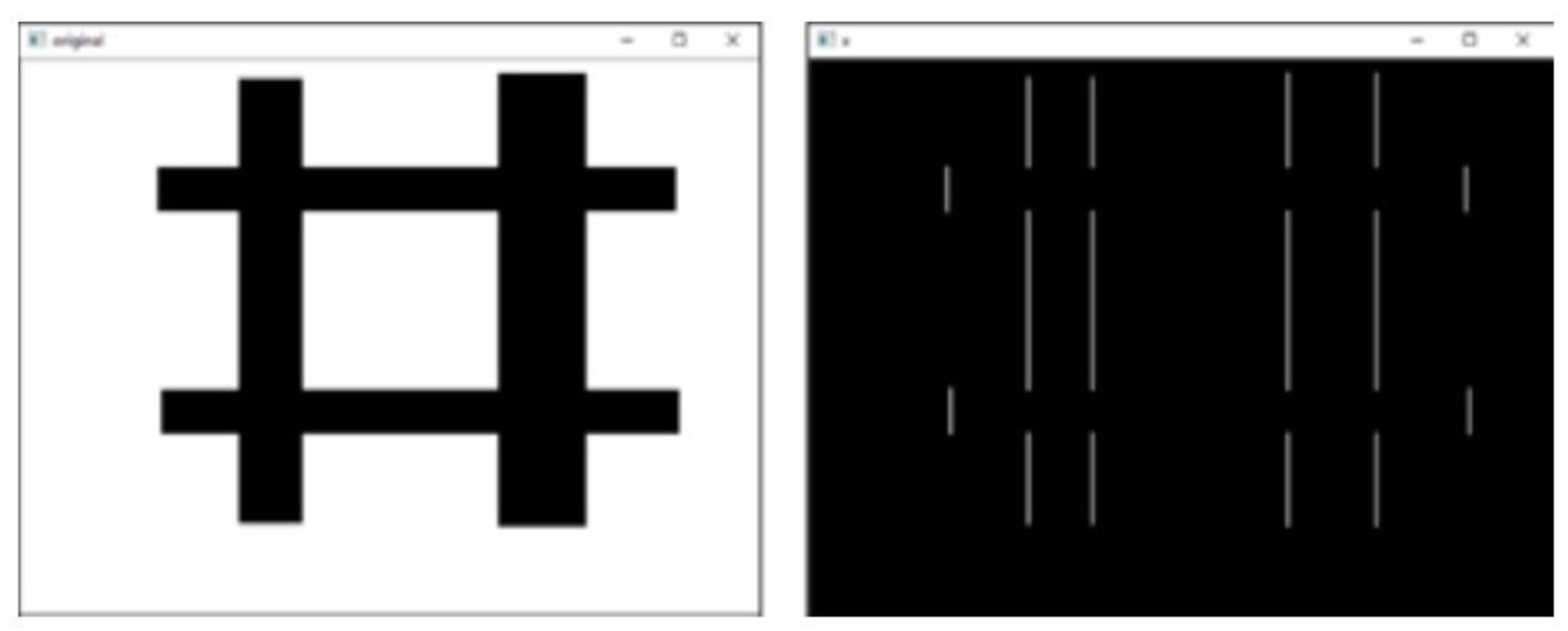
计算x方向边缘(梯度)
如果想只计算x方向(水平方向)的边缘,需要将函数cv2.Sobel()的参数dx和dy的值设置为dx=1, dy=0。
语法格式为:
dst = cv2.Sobel( src , ddepth , 1 , 0 )
计算y方向边缘(梯度)
如果想只计算y方向(垂直方向)的边缘,需要将函数cv2.Sobel()的参数dx和dy的值设置为“dx=0, dy=1”。
语法格式为:
dst = cv2.Sobel( src , ddepth , 0 , 1 )
的参数dx和dy的值设置为“dx=1, dy=1”,也可以设置为“dx=2, dy=2”,或者两个参数都不为零的其他情况。此时,会获取两个方向的边缘信息,此时的语法格式为:
dst = cv2.Sobel( src , ddepth , 1 , 1 )

dy= cv2.Sobel( src , ddepth , 0 , 1 )
dst=cv2.addWeighted( src1 , alpha , src2 , beta , gamma )
注意事项
- 深度(ddepth):在实际操作中,计算梯度值可能会出现负数。通常处理的图像是8位图类型,如果结果也是该类型,那么所有负数会自动截断为0,发生信息丢失。所以,为了避免信息丢失,我们在计算时使用更高的数据类型cv2.CV_64F,再通过取绝对值将其映射为cv2.CV_8U(8位图)类型。
- 在OpenCV中,使用函数cv2.convertScaleAbs()对参数取绝对值
- 核大小(ksize):较小的核(如 3)会更精确地检测边缘,而较大的核(如 5 或 7)则会产生更平滑的边缘效果,但可能丢失细节。
- Sobel 算子对噪声敏感,因此在应用 Sobel 边缘检测之前,通常先对图像进行平滑处理(如使用高斯模糊)是有益的。
- Sobel 算子是一种基本的边缘检测技术,适用于许多图像处理场景,但在处理高噪声或需要高级边缘检测功能的场合可能不足够。
示例代码1
使用函数cv2.Sobel()获取图像水平方向的完整边缘信息。
在本例中,将参数ddepth的值设置为cv2.CV_64F,并使用函数cv2.convertScaleAbs()对cv2.Sobel()的计算结果取绝对值。
import cv2
o = cv2.imread('Sobel4.bmp', cv2.IMREAD_GRAYSCALE)
# 先设cv2.CV_64F,再取绝对值
Sobelx = cv2.Sobel(o, cv2.CV_64F,1,0)
Sobelx = cv2.convertScaleAbs(Sobelx)
cv2.imshow("original", o)
cv2.imshow("x", Sobelx)
cv2.waitKey()
cv2.destroyAllWindows()
示例代码2
使用函数cv2.Sobel()获取图像垂直方向的边缘信息。
在本例中,将参数ddepth的值设置为cv2.CV_64F,并使用函数cv2.convertScaleAbs()对cv2.Sobel()的计算结果取绝对值。
import cv2
o = cv2.imread('Sobel4.bmp', cv2.IMREAD_GRAYSCALE)
Sobely = cv2.Sobel(o, cv2.CV_64F,0,1)
Sobely = cv2.convertScaleAbs(Sobely)
cv2.imshow("original", o)
cv2.imshow("y", Sobely)
cv2.waitKey()
cv2.destroyAllWindows()

示例代码3
计算函数cv2.Sobel()在水平、垂直两个方向叠加的边缘信息。
import cv2
o = cv2.imread('Sobel4.bmp', cv2.IMREAD_GRAYSCALE)
Sobelx = cv2.Sobel(o, cv2.CV_64F,1,0)
Sobely = cv2.Sobel(o, cv2.CV_64F,0,1)
Sobelx = cv2.convertScaleAbs(Sobelx)
Sobely = cv2.convertScaleAbs(Sobely)
Sobelxy = cv2.addWeighted(Sobelx,0.5, Sobely,0.5,0)
cv2.imshow("original", o)
cv2.imshow("xy", Sobelxy)
cv2.waitKey()
cv2.destroyAllWindows()
示例代码4
使用不同方式处理图像在两个方向的边缘信息。
在本例中,分别使用两种不同的方式获取边缘信息。
-
方式1:分别使用“dx=1, dy=0”和“dx=0, dy=1”计算图像在水平方向和垂直方向的边缘信息,然后将二者相加,构成两个方向的边缘信息。
-
方式2:将参数dx和dy的值设为“dx=1, dy=1”,获取图像在两个方向的梯度。
import cv2
o = cv2.imread('lena.bmp', cv2.IMREAD_GRAYSCALE)
# 方式1,水平和垂直梯度叠加
Sobelx = cv2.Sobel(o, cv2.CV_64F,1,0)
Sobely = cv2.Sobel(o, cv2.CV_64F,0,1)
Sobelx = cv2.convertScaleAbs(Sobelx)
Sobely = cv2.convertScaleAbs(Sobely)
Sobelxy = cv2.addWeighted(Sobelx,0.5, Sobely,0.5,0)
# 方式2,两个方向的梯度
Sobelxy11=cv2.Sobel(o, cv2.CV_64F,1,1)
Sobelxy11=cv2.convertScaleAbs(Sobelxy11)
cv2.imshow("original", o)
cv2.imshow("xy", Sobelxy)
cv2.imshow("xy11", Sobelxy11)
cv2.waitKey()
cv2.destroyAllWindows()
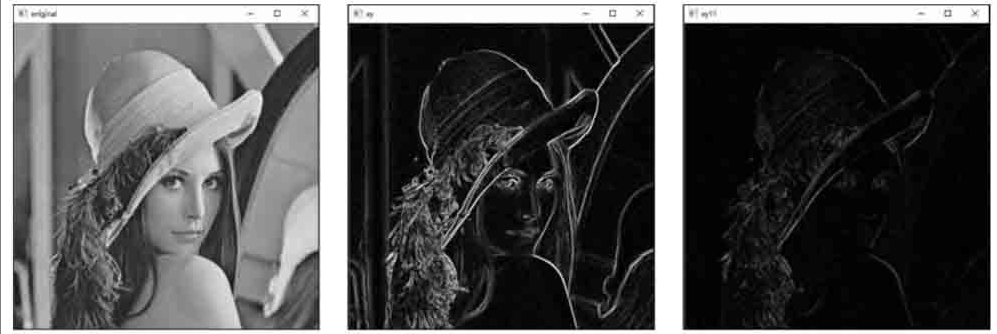
- 显然方式1效果好很多
9.3 Scharr算子及函数使用
概述
Scharr算子是一种计算机视觉中用于边缘检测的算法。它是一种基于卷积的技术,用于突出图像中的快速强度变化,这通常对应于物体的边界。Scharr算子是Sobel算子的变体,提供了更好的边缘检测精度。
工作原理
Scharr算子的工作原理基于图像的一阶导数。在图像处理中,边缘可以被理解为像素强度的快速变化区域。通过计算图像在每个点处的一阶导数,可以确定像素强度变化最大的区域,即边缘。
卷积核
Scharr算子使用两个3x3的卷积核,分别用于水平和垂直边缘检测:
-
水平方向的卷积核 (检测垂直边缘):
[ − 3 0 3 − 10 0 10 − 3 0 3 ] \begin{bmatrix} -3 & 0 & 3 \\ -10 & 0 & 10 \\ -3 & 0 & 3 \end{bmatrix} −3−10−30003103 -
垂直方向的卷积核 (检测水平边缘):
[ − 3 − 10 − 3 0 0 0 3 10 3 ] \begin{bmatrix} -3 & -10 & -3 \\ 0 & 0 & 0 \\ 3 & 10 & 3 \end{bmatrix} −303−10010−303
这些核通过卷积操作应用于图像,用于计算水平和垂直方向的像素强度梯度。
边缘检测步骤
-
图像预处理:通常先将图像转换为灰度格式,因为边缘检测通常在单通道图像上进行。
-
应用卷积核:分别使用水平和垂直卷积核对图像进行卷积操作,以计算梯度。
-
计算梯度幅度和方向:结合两个方向的梯度结果,计算每个像素的总梯度幅度和方向。
-
边缘强度确定:基于梯度幅度,可以确定边缘的位置和强度。
特点
- 精度高:Scharr算子提供比传统Sobel算子更精确的边缘检测,尤其是在边缘方向的判定上。
- 对噪声敏感:由于其高灵敏度,Scharr算子可能对图像噪声更加敏感。
- 计算效率:虽然精度高,但Scharr算子的计算复杂度与Sobel算子相当,适用于实时图像处理。
cv2.Scharr()函数原型
cv2.Scharr() 函数的函数原型如下:
cv2.Scharr(src, ddepth, dx, dy[, dst[, scale[, delta[, borderType]]]])
其中:
src:输入图像。ddepth:输出图像的所需深度,常用的值是cv2.CV_8U,cv2.CV_16U,cv2.CV_32F或cv2.CV_64F。dx:x方向上的导数阶数。dy:y方向上的导数阶数。dst:输出图像。scale:可选的缩放因子,用于缩放导数的大小,默认值为1。delta:可选的附加值,添加到输出图像中,默认值为0。borderType:像素外推方法,用于处理边界。
参数说明
- src (输入图像):通常是灰度图像。在边缘检测之前,彩色图像应该先转换成灰度格式。
- ddepth (输出深度):参数ddepth的值应该设置为
cv2.CV_64F,并对函数cv2.Scharr()的计算结果取绝对值,才能保证得到正确的处理结果。 - dx 和 dy (导数阶数):这两个参数决定了计算哪个方向的导数。例如,
dx=1, dy=0检测垂直边缘(水平方向的变化),dx=0, dy=1检测水平边缘(垂直方向的变化)。
边缘检测类型
计算x方向边缘(梯度)
dx=1, dy=0,此时,使用的语句是:
dst=Scharr(src, ddpeth, dx=1, dy=0)
计算y方向边缘(梯度)
dx=0, dy=1,此时,使用的语句是:
dst=Scharr(src, ddpeth, dx=0, dy=1)
计算x方向与y方向的边缘叠加
将两个方向的边缘相加,使用的语句是:
dx=Scharr(src, ddpeth, dx=1, dy=0)
dy=Scharr(src, ddpeth, dx=0, dy=1)
Scharrxy=cv2.addWeighted(dx,0.5, dy,0.5,0)
注意:和Sobel算子不一样,参数dx和dy的值不能都为1
注意事项
- 使用 Scharr 算子时,通常将图像转换为灰度格式。
- Scharr 算子对噪声比较敏感,因此在应用之前,有时需要对图像进行平滑处理。
- 选择合适的
ddepth参数很重要,特别是在需要精确检测边缘方向的情况下。例如,使用cv2.CV_64F可以获取完整的梯度方向信息。 - 由于 Scharr 算子的高灵敏度,它可能会放大图像中的噪声,因此在有噪声的环境中使用时要小心。
示例代码1
使用函数cv2.Scharr()获取图像水平方向的边缘信息。
import cv2
o = cv2.imread('Scharr.bmp', cv2.IMREAD_GRAYSCALE)
Scharrx = cv2.Scharr(o, cv2.CV_64F,1,0)
Scharrx = cv2.convertScaleAbs(Scharrx)
cv2.imshow("original", o)
cv2.imshow("x", Scharrx)
cv2.waitKey()
cv2.destroyAllWindows()

示例代码2
使用函数cv2.Scharr()获取图像垂直方向的边缘信息。
import cv2
o = cv2.imread('Scharr.bmp', cv2.IMREAD_GRAYSCALE)
Scharry = cv2.Scharr(o, cv2.CV_64F,0,1)
Scharry = cv2.convertScaleAbs(Scharry)
cv2.imshow("original", o)
cv2.imshow("y", Scharry)
cv2.waitKey()
cv2.destroyAllWindows()
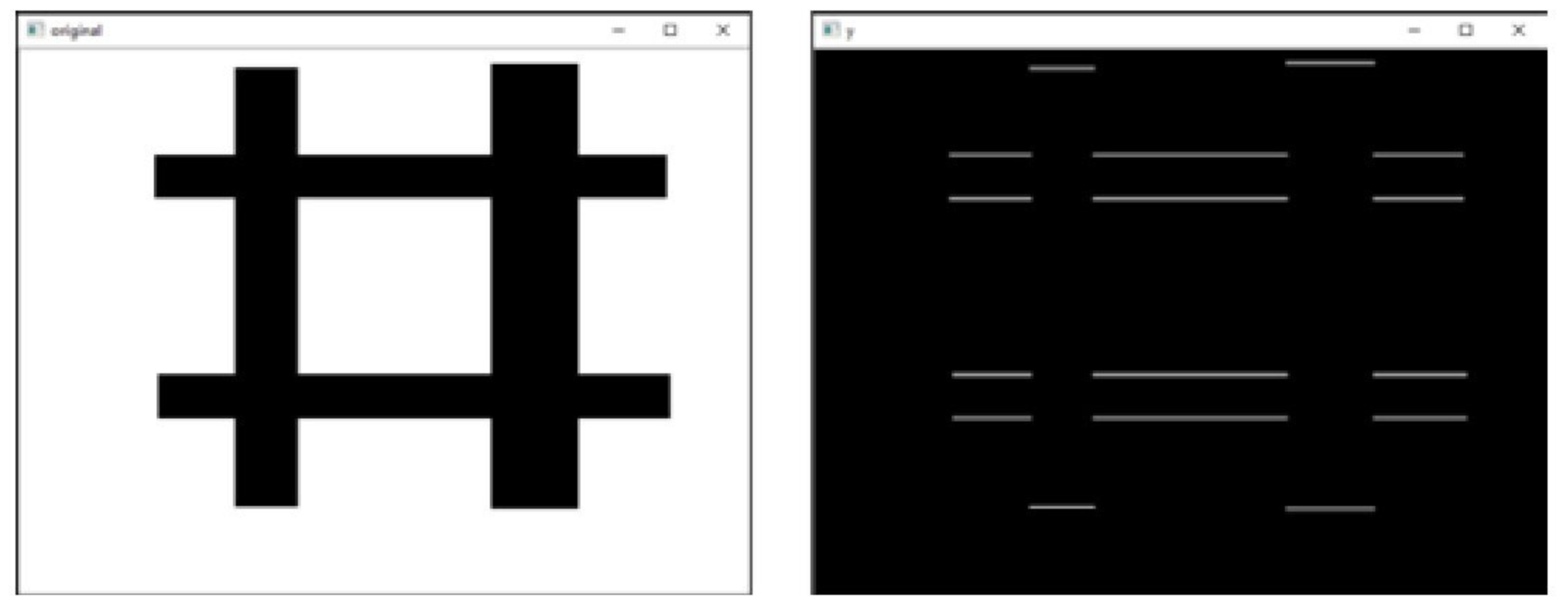
示例代码3
使用函数cv2.Scharr()实现水平方向和垂直方向边缘叠加的效果。
import cv2
o = cv2.imread('scharr.bmp', cv2.IMREAD_GRAYSCALE)
scharrx = cv2.Scharr(o, cv2.CV_64F,1,0)
scharry = cv2.Scharr(o, cv2.CV_64F,0,1)
scharrx = cv2.convertScaleAbs(scharrx)
scharry = cv2.convertScaleAbs(scharry)
scharrxy = cv2.addWeighted(scharrx,0.5, scharry,0.5,0)
cv2.imshow("original", o)
cv2.imshow("xy", scharrxy)
cv2.waitKey()
cv2.destroyAllWindows()

9.4 Sobel算子和Scharr算子的比较
9.5 Laplacian算子及函数使用
9.6 算子总结
第十章 Canny边缘检测
10.1 Canny边缘检测基础
10.2 Canny函数及使用
第十一章 图像金字塔
图像金字塔是由一幅图像的多个不同分辨率的子图所构成的图像集合。该组图像是由单个图像通过不断地降采样所产生的,最小的图像可能仅仅有一个像素点。下图是一个图像金字塔的示例。从图中可以看到,图像金字塔是一系列以金字塔形状排列的、自底向上分辨率逐渐降低的图像集合。
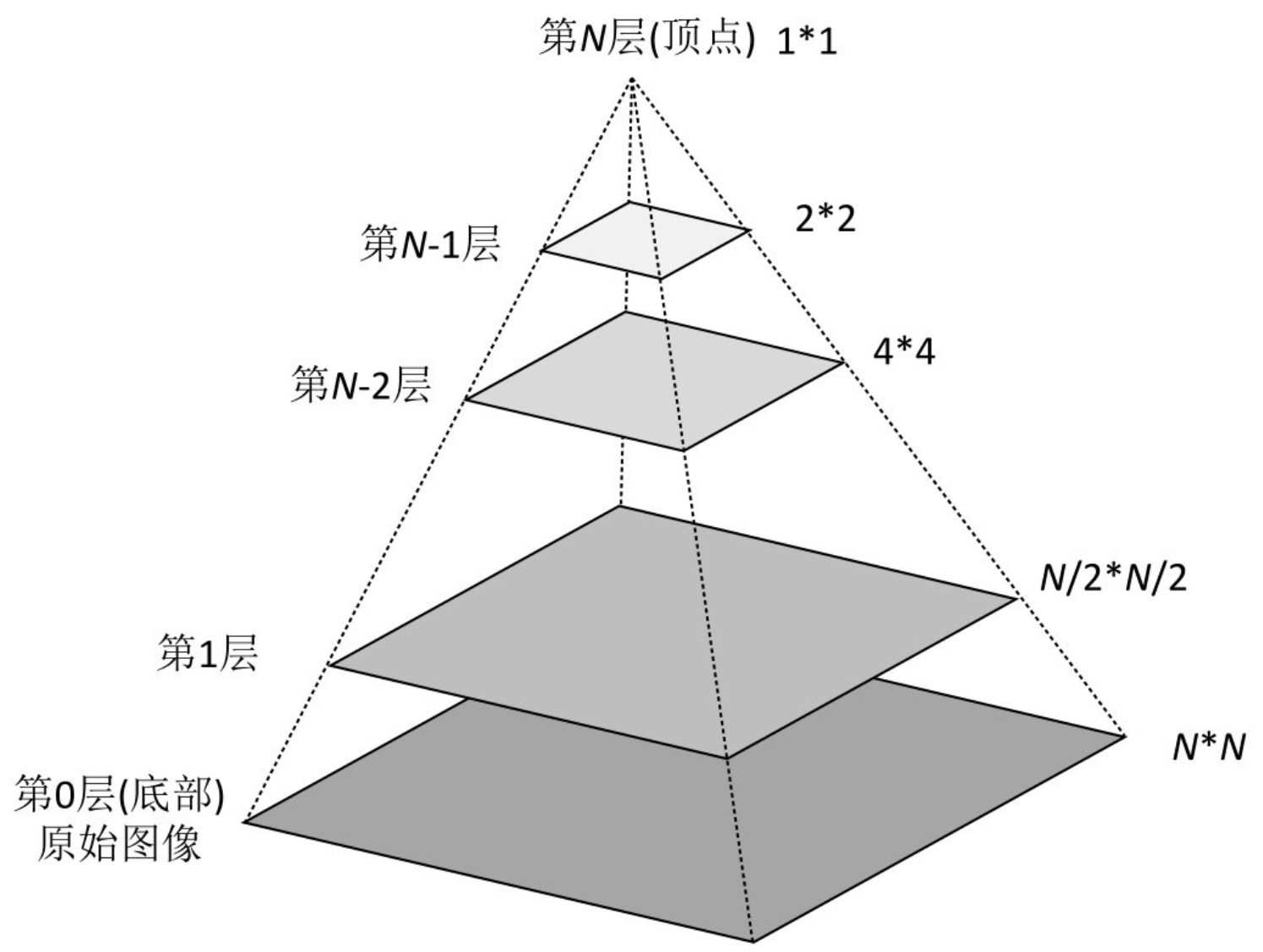
通常情况下,图像金字塔的底部是待处理的高分辨率图像(原始图像),而顶部则为其低分辨率的近似图像。向金字塔的顶部移动时,图像的尺寸和分辨率都不断地降低。通常情况下,每向上移动一级,图像的宽和高都降低为原来的二分之一。
11.1 理论基础
图像金字塔是一种在计算机视觉和图像处理中常用的概念,用于表示不同分辨率的图像集合。这种结构允许进行多尺度分析,即在不同的分辨率下观察和处理图像。图像金字塔的主要应用包括图像压缩、图像金字塔合成、特征提取和图像分割。
图像金字塔通常有两种类型:高斯金字塔和拉普拉斯金字塔。
高斯金字塔
- 构造:高斯金字塔通过重复应用高斯模糊和下采样(降低分辨率)来构建。每个层级的图像是前一个图像的模糊和缩小版本。
- 用途:高斯金字塔主要用于图像的多尺度表示,可以用于图像压缩和图像分析。
- 操作步骤:
- 将原始图像作为最顶层。
- 对每层图像应用高斯滤波,然后将其下采样(通常每个维度缩小一半)。
- 重复上述过程直至达到所需的层数或图像尺寸。
拉普拉斯金字塔
- 构造:拉普拉斯金字塔是基于高斯金字塔构建的。它通过存储图像的细节信息来构建,这些细节在高斯金字塔的相邻层级之间的图像差异中被去除。
- 用途:拉普拉斯金字塔用于图像重建和图像融合任务,如在图像编辑中实现无缝融合。
- 操作步骤:
- 从高斯金字塔的顶层开始。
- 对每层图像进行上采样(扩大),并使用高斯滤波,以匹配下一层高斯金字塔图像的尺寸。
- 将这个上采样的图像从原始高斯金字塔的图像中减去,得到拉普拉斯金字塔的当前层。
- 重复上述过程,直到所有层完成。
应用
- 图像压缩:通过移除图像中的冗余信息,可以用于有效的图像存储。
- 图像融合:在图像融合任务中,可以使用拉普拉斯金字塔来平滑地合并不同图像的区域。
- 对象检测和识别:多尺度分析有助于检测不同大小的对象。
- 图像恢复:可以使用拉普拉斯金字塔来增强图像的细节。
在 OpenCV 中,可以使用 pyrDown 和 pyrUp 函数来分别实现图像的下采样和上采样,从而构建和操作图像金字塔。
11.2 pyrDown函数及使用
cv2.pyrDown() 是 OpenCV 中用于实现图像金字塔下采样的函数。图像金字塔是一种用于多尺度图像表示的结构,其中 pyrDown() 用于降低图像的分辨率。这个过程涉及对图像进行高斯平滑,然后将其尺寸减半。
语法
cv2.pyrDown() 函数的基本语法如下:
dst = cv2.pyrDown(src[, dst[, dstsize[, borderType]]])
其中:
src:输入图像。dst:输出图像。dstsize:输出图像的大小。默认情况下,输出图像的尺寸是输入图像尺寸的一半。borderType:用于推断图像外部像素的边界类型。
参数说明
- src (输入图像):需要降低分辨率的原始图像。
- dst (输出图像):结果图像,其尺寸是源图像的一半。
- dstsize (目标尺寸):可选参数,指定输出图像的尺寸。通常留空,让函数自动计算尺寸。
- borderType (边界类型):可选参数,指定如何处理边界像素。默认情况下,使用
cv2.BORDER_DEFAULT。
注意事项
- 在进行下采样之前,不需要对图像进行额外的平滑处理,因为
pyrDown()自身就包含了高斯平滑的步骤。 - 下采样后的图像尺寸大约是原始图像尺寸的一半,具体取决于原始图像的尺寸。
pyrDown()可以连续使用,以进一步降低图像的分辨率。
示例代码1
以下是一个使用 cv2.pyrDown() 函数的简单例子:
import cv2
# 读取图像
image = cv2.imread('path_to_image')
# 应用 pyrDown() 函数进行下采样
downsampled_image = cv2.pyrDown(image)
# 显示原始图像和下采样后的图像
cv2.imshow('Original Image', image)
cv2.imshow('Downsampled Image', downsampled_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
在这个例子中,cv2.pyrDown() 函数被用来将原始图像的分辨率减半。这种下采样在构建图像金字塔、进行多尺度分析或简单地减少图像尺寸时非常有用。
示例代码2
使用函数cv2.pyrDown()对一幅图像进行向下采样,观察采样的结果。
import cv2
o=cv2.imread("lena.bmp", cv2.IMREAD_GRAYSCALE)
r1=cv2.pyrDown(o)
r2=cv2.pyrDown(r1)
r3=cv2.pyrDown(r2)
print("o.shape=", o.shape)
print("r1.shape=", r1.shape)
print("r2.shape=", r2.shape)
print("r3.shape=", r3.shape)
cv2.imshow("original", o)
cv2.imshow("r1", r1)
cv2.imshow("r2", r2)
cv2.imshow("r3", r3)
cv2.waitKey()
cv2.destroyAllWindows()

11.3 pyrUp函数及使用
cv2.pyrUp() 是 OpenCV 库中用于实现图像金字塔上采样的函数。图像金字塔是一种多尺度图像处理方法,在图像金字塔中,pyrUp() 用于增加图像的分辨率。这个过程通常涉及将图像尺寸增大一倍,并使用高斯滤波来平滑结果,从而减少上采样过程中可能产生的走样效应。
语法
cv2.pyrUp() 函数的基本语法如下:
dst = cv2.pyrUp(src[, dst[, dstsize[, borderType]]])
其中:
src:输入图像。dst:输出图像。dstsize:输出图像的大小。默认情况下,输出图像的尺寸是输入图像尺寸的两倍。borderType:用于推断图像外部像素的边界类型。
参数说明
- src (输入图像):需要提高分辨率的原始图像。
- dst (输出图像):结果图像,其尺寸是源图像的两倍。
- dstsize (目标尺寸):可选参数,指定输出图像的尺寸。通常留空,让函数自动计算尺寸。
- borderType (边界类型):可选参数,指定如何处理边界像素。默认情况下,使用
cv2.BORDER_DEFAULT。
注意事项
pyrUp()不会恢复原始图像在下采样过程中丢失的信息。上采样后的图像可能在视觉上与原始图像相似,但细节可能会有所不同。- 上采样后的图像尺寸大约是原始图像尺寸的两倍,具体取决于原始图像的尺寸。
pyrUp()后通常会使用高斯滤波来平滑图像,以减少上采样可能产生的走样效应。
示例代码1
以下是一个使用 cv2.pyrUp() 函数的简单例子:
import cv2
# 读取图像
image = cv2.imread('path_to_image')
# 应用 pyrUp() 函数进行上采样
upsampled_image = cv2.pyrUp(image)
# 显示原始图像和上采样后的图像
cv2.imshow('Original Image', image)
cv2.imshow('Upsampled Image', upsampled_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
在这个例子中,使用 cv2.pyrUp() 函数将原始图像的分辨率增加一倍。这种上采样在重建图像、图像金字塔的操作或者在需要更高分辨率的图像分析时非常有用。
示例代码2
使用函数cv2.pyrUp()对一幅图像进行向上采样,观察采样的结果。
import cv2
o=cv2.imread("lenas.bmp")
r1=cv2.pyrUp(o)
r2=cv2.pyrUp(r1)
r3=cv2.pyrUp(r2)
print("o.shape=", o.shape)
print("r1.shape=", r1.shape)
print("r2.shape=", r2.shape)
print("r3.shape=", r3.shape)
cv2.imshow("original", o)
cv2.imshow("r1", r1)
cv2.imshow("r2", r2)
cv2.imshow("r3", r3)
cv2.waitKey()
cv2.destroyAllWindows()
# o.shape= (64, 64, 3)
# r1.shape= (128, 128, 3)
# r2.shape= (256, 256, 3)
# r3.shape= (512, 512, 3)
# 经过向上采样后,图像的宽度和高度都会变为原来的2倍,图像整体大小会变为原来的4倍。

11.4 采样可逆性的研究
原始图像o与先后经过向上采样、向下采样得到的图像down,在大小上是相等的,在外观上是相似的,但是它们的像素值并不一致。
11.5 拉普拉斯金字塔
前面我们介绍了高斯金字塔,高斯金字塔是通过对一幅图像一系列的向下采样所产生的。有时,我们希望通过对金字塔中的小图像进行向上采样以获取完整的大尺寸高分辨率图像,这时就需要用到拉普拉斯金字塔。
定义
一幅图像在经过向下采样后,再对其进行向上采样,是无法恢复为原始状态的。对此,我们也用程序进行了验证。向上采样并不是向下采样的逆运算。这是很明显的,因为向下采样时在使用高斯滤波器处理后还要抛弃偶数行和偶数列,不可避免地要丢失一些信息。
为了在向上采样时能够恢复具有较高分辨率的原始图像,就要获取在采样过程中所丢失的信息,这些丢失的信息就构成了拉普拉斯金字塔。
拉普拉斯金字塔的定义形式为: L i = G i − pyrUp ( G i + 1 ) L_i = G_i - \text{pyrUp}(G_{i+1}) Li=Gi−pyrUp(Gi+1)
-
Li表示拉普拉斯金字塔中的第i层。
-
Gi表示高斯金字塔中的第i层。
应用
拉普拉斯金字塔的作用在于,能够恢复高分辨率的图像。下图演示了如何通过拉普拉斯金字塔恢复高分辨率图像。
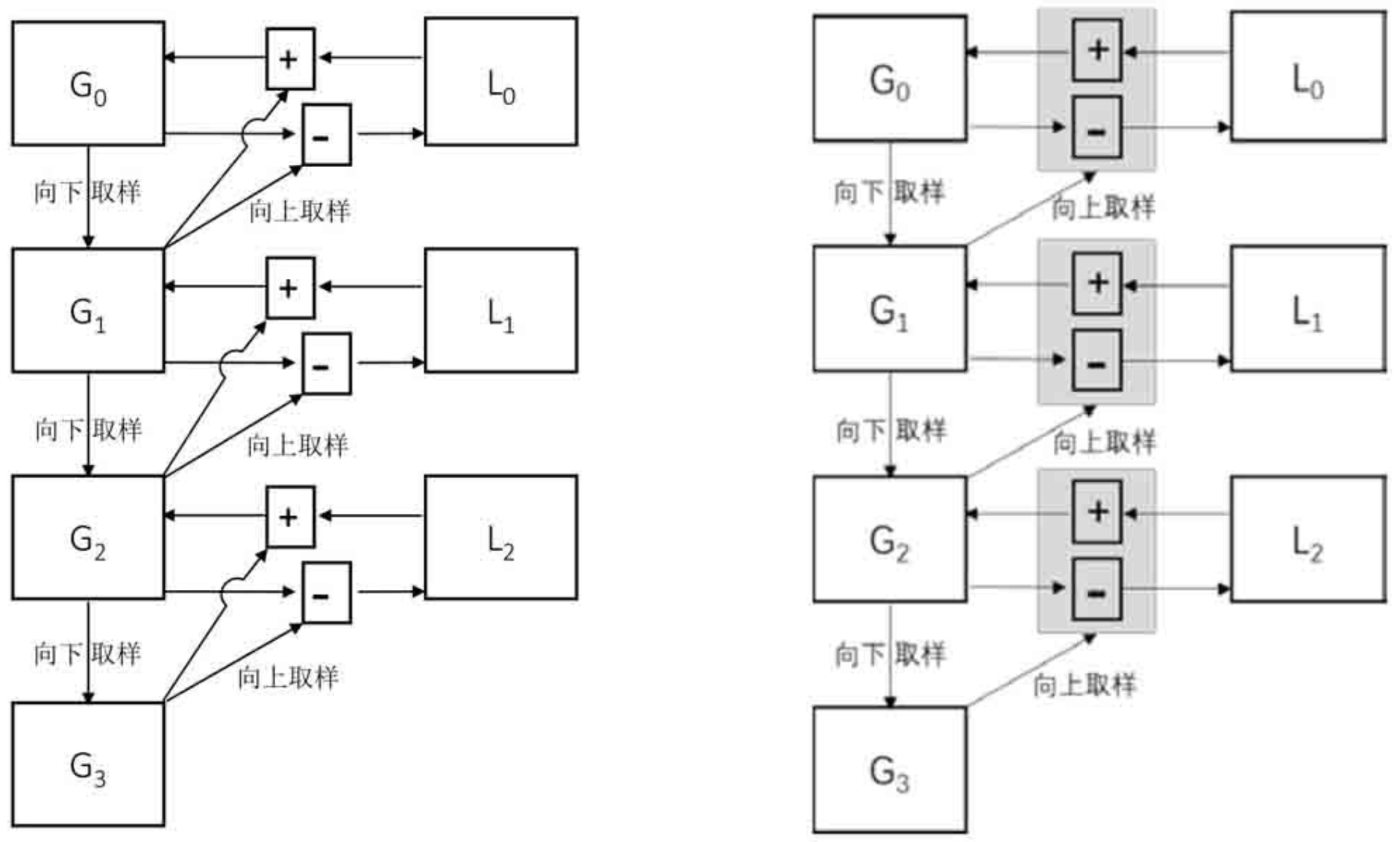
-
向下采样(高斯金字塔的构成)
G1=cv2.pyrDown(G0) G2=cv2.pyrDown(G1) G3=cv2.pyrDown(G2) -
拉普拉斯金字塔
L0=G0-cv2.pyrUp(G1) L1=G1-cv2.pyrUp(G2) L2=G2-cv2.pyrUp(G3) -
向上采样恢复高分辨率图像
G0=L0+cv2.pyrUp(G1) G1=L1+cv2.pyrUp(G2) G2=L2+cv2.pyrUp(G3)
示例代码1
使用函数cv2.pyrDown()和cv2.pyrUp()构造拉普拉斯金字塔。
import cv2
O=cv2.imread("lena.bmp")
G0=O
G1=cv2.pyrDown(G0)
G2=cv2.pyrDown(G1)
G3=cv2.pyrDown(G2)
L0=G0-cv2.pyrUp(G1)
L1=G1-cv2.pyrUp(G2)
L2=G2-cv2.pyrUp(G3)
print("L0.shape=", L0.shape)
print("L1.shape=", L1.shape)
print("L2.shape=", L2.shape)
cv2.imshow("L0", L0)
cv2.imshow("L1", L1)
cv2.imshow("L2", L2)
cv2.waitKey()
cv2.destroyAllWindows()
输出为:
L0.shape= (512, 512, 3)
L1.shape= (256, 256, 3)
L2.shape= (128, 128, 3)

示例代码2
使用拉普拉斯金字塔及高斯金字塔恢复原始图像。
import cv2
import numpy as np
O = cv2.imread("lena.bmp")
G0 = O
G1 = cv2.pyrDown(G0)
L0 = O - cv2.pyrUp(G1)
RO = L0 + cv2.pyrUp(G1) # 通过拉普拉斯图像复原的原始图像
print("O.shape=", O.shape)
print("RO.shape=", RO.shape)
result = RO - O # 将O和RO做减法运算
result = abs(result)
print("原始图像O与恢复图像RO之差的绝对值和:", np.sum(result))
输出为:
O.shape= (512, 512, 3)
RO.shape= (512, 512, 3)
原始图像O与恢复的图像RO之差的绝对值和:0
- 从程序运行结果可以看到,原始图像与恢复图像差值的绝对值和为
0。这说明使用拉普拉斯金字塔恢复的图像与原始图像完全一致。
示例代码3
使用拉普拉斯金字塔及高斯金字塔恢复高斯金字塔内的多层图像。
import cv2
import numpy as np
O = cv2.imread("lena.bmp")
# 生成高斯金字塔
G0 = O
G1 = cv2.pyrDown(G0)
G2 = cv2.pyrDown(G1)
G3 = cv2.pyrDown(G2)
# 生成拉普拉斯金字塔
L0 = G0 - cv2.pyrUp(G1) # 拉普拉斯金字塔第0层
L1 = G1 - cv2.pyrUp(G2) # 拉普拉斯金字塔第1层
L2 = G2 - cv2.pyrUp(G3) # 拉普拉斯金字塔第2层
# 复原G0
RG0 = L0 + cv2.pyrUp(G1) # 通过拉普拉斯图像复原的原始图像G0
print("G0.shape=", G0.shape)
print("RG0.shape=", RG0.shape)
result = RG0 - G0 # 将RG0和G0相减
result = abs(result)
print("原始图像G0与恢复图像RG0差值的绝对值和:", np.sum(result))
# 复原G1
RG1 = L1 + cv2.pyrUp(G2) # 通过拉普拉斯图像复原G1
print("G1.shape=", G1.shape)
print("RG1.shape=", RG1.shape)
result = RG1 - G1 # 将RG1和G1相减
print("原始图像G1与恢复图像RG1之差的绝对值和:", np.sum(abs(result)))
# 复原G2
RG2 = L2 + cv2.pyrUp(G3) # 通过拉普拉斯图像复原G2
print("G2.shape=", G2.shape)
print("RG2.shape=", RG2.shape)
result = RG2 - G2 # 将RG2和G2相减
print("原始图像G2与恢复图像RG2之差的绝对值和:", np.sum(abs(result)))
输出为:
G0.shape= (512, 512, 3)
RG0.shape= (512, 512, 3)
原始图像G0与恢复图像RG0之差的绝对值和:0
G1.shape= (256, 256, 3)
RG1.shape= (256, 256, 3)
原始图像G1与恢复图像RG1之差的绝对值和:0
G2.shape= (128, 128, 3)
RG2.shape= (128, 128, 3)
原始图像G2与恢复图像RG2之差的绝对值和:0
第十二章 图像轮廓
12.1 查找并绘制轮廓
findContours 是 OpenCV 库中的一个功能强大的函数,用于在二值图像中查找轮廓。轮廓可以简单地理解为连接具有相同颜色或强度的所有连续点的曲线。此函数广泛用于图像分析、对象检测和识别系统。
findContours语法
findContours 函数的基本语法如下:
contours, hierarchy = cv2.findContours(image, mode, method[, contours[, hierarchy[, offset]]])
其中:
-
image:二值图像,即图像应该是黑色和白色的,通常是通过阈值处理或边缘检测后的结果。 -
mode:轮廓检索模式,常用的模式包括:-
cv2.RETR_LIST:检索所有轮廓,但不创建任何父子关系。
-
cv2.RETR_EXTERNAL:只检索最外层的轮廓。
-
cv2.RETR_CCOMP:检索所有轮廓并将它们组织成两层:顶层为外部边界,第二层为孔的边界。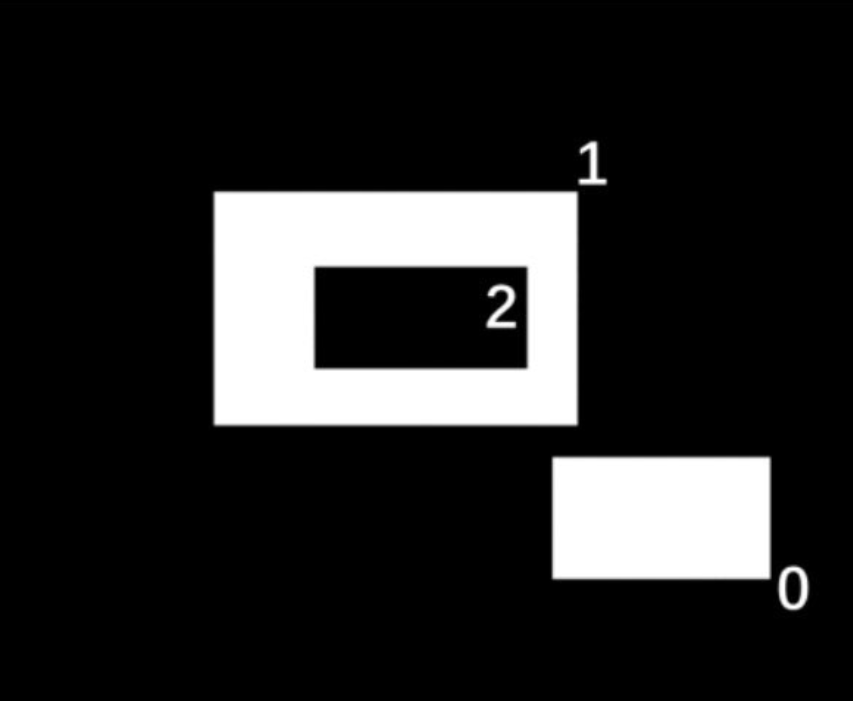
-
cv2.RETR_TREE:检索所有轮廓并重建完整的层次结构。
-
-
method:轮廓逼近方法,常用的方法包括:-
cv2.CHAIN_APPROX_NONE:存储所有轮廓点。 -
cv2.CHAIN_APPROX_SIMPLE:压缩水平、垂直和对角线段,仅保留它们的端点。
-
-
contours:检测到的轮廓,可以使用len(contours)获取轮廓的个数。 -
hierarchy:关于图像轮廓的层次信息。
参数hierarchy
定义
hierarchy 是一个 NumPy 数组,具有以下结构:
[hierarchy] = [[[Next, Previous, First_Child, Parent], [Next, Previous, First_Child, Parent], ...]]
这个数组中的每个元素都对应于 contours 数组中的一个轮廓。每个元素都是包含四个整数的列表,这四个整数分别表示:
- Next:同一层级中下一个轮廓的索引。如果没有更多的轮廓,则值为 -1。
- Previous:同一层级中前一个轮廓的索引。如果没有更多的轮廓,则值为 -1。
- First_Child:当前轮廓的第一个子轮廓的索引。如果没有子轮廓,则值为 -1。
- Parent:包含当前轮廓的父轮廓的索引。如果当前轮廓没有父轮廓,则值为 -1。
示例
假设我们的image图像包含以下轮廓:
- 两个独立的外轮廓(轮廓A和轮廓B)。
- 轮廓A内部有一个子轮廓(轮廓C)。
- 轮廓C内部有一个子轮廓(轮廓D)。
调用Python代码
contours, hierarchy = cv2.findContours(image, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
输出为
hierarchy = [[[ 1, -1, 2, -1],
[-1, 0, -1, -1],
[-1, -1, 3, 0],
[-1, -1, -1, 2]]]
hierarchy 数组中的每个元素都对应一个轮廓,包含四个值:[Next, Previous, First_Child, Parent]。
- 轮廓A:
[ 1, -1, 2, -1]- Next: 轮廓B的索引为1。
- Previous: 没有前一个轮廓,值为-1。
- First_Child: 轮廓C的索引为2。
- Parent: 没有父轮廓,值为-1(它是最外层轮廓)。
- 轮廓B:
[-1, 0, -1, -1]- Next: 没有下一个轮廓,值为-1。
- Previous: 轮廓A的索引为0。
- First_Child: 没有子轮廓,值为-1。
- Parent: 没有父轮廓,值为-1(它是最外层轮廓)。
- 轮廓C:
[-1, -1, 3, 0]- Next: 没有下一个轮廓,值为-1。
- Previous: 没有前一个轮廓,值为-1。
- First_Child: 轮廓D的索引为3。
- Parent: 轮廓A的索引为0。
- 轮廓D:
[-1, -1, -1, 2]- Next: 没有下一个轮廓,值为-1。
- Previous: 没有前一个轮廓,值为-1。
- First_Child: 没有子轮廓,值为-1。
- Parent: 轮廓C的索引为2。
findContours注意事项
- 使用
findContours函数之前,确保图像是二值的(黑白),通常通过阈值处理或 Canny 边缘检测来实现。 findContours函数会修改源图像,所以如果你希望保留原始图像,应该在调用该函数之前对其进行复制。- 轮廓检索模式和逼近方法的选择取决于具体应用场景和需要提取的轮廓信息的类型。
drawContours语法
cv2.drawContours() 函数的基本语法如下:
cv2.drawContours(image, contours, contourIdx, color[, thickness[, lineType[, hierarchy[, maxLevel[, offset]]]]])
其中:
- image: 这是要绘制轮廓的图像。轮廓将直接在这个图像上绘制,因此该操作是原地进行的(in-place)。
- contours: 这是一个 Python 列表,包含了所有要绘制的轮廓。每个轮廓都是由点组成的数组,这些点一般通过
cv2.findContours()函数获取。 - contourIdx: 指定要绘制的轮廓索引。如果这个值是 -1,那么所有轮廓都会被绘制。否则,它可以被设置为特定的索引,只绘制特定的轮廓。
- color: 轮廓的颜色,使用 (B, G, R) 格式表示,其中 B、G、R 分别是蓝色、绿色、红色通道的强度值。
- thickness: 轮廓线条的厚度。如果这个值是正数,它表示线条的厚度。如果设置为 -1,轮廓的内部将被完全填充。
- lineType (可选): 线条的类型。例如,
cv2.LINE_8或cv2.LINE_AA。这影响轮廓的边缘是锯齿状还是平滑的。 - hierarchy (可选): 轮廓的层次信息,通常从
cv2.findContours()获取。这个参数在绘制特定层次的轮廓时很有用。 - maxLevel (可选): 用于定义层次结构中要绘制轮廓的最大层级。如果设置为 0,只绘制指定的轮廓。如果设置为 1,绘制轮廓及其直接的子轮廓,依此类推。
- offset (可选): 轮廓点的偏移量。这对于移动轮廓位置很有用。
drawContours注意事项
cv2.drawContours()函数可以修改原始图像,或者你可以在一个图像的副本上绘制轮廓。- 选择合适的颜色和厚度可以改善轮廓的可视化效果。
- 如果轮廓是从灰度图或二值图中检测到的,绘制轮廓前可能需要将其转换回彩色图像。
- 通过调整
contourIdx和hierarchy参数,可以有选择性地绘制特定的轮廓或轮廓组。
例:常规用法
import cv2
# 读取图像并转换为灰度图
img = cv2.imread('path_to_image')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 应用阈值
ret, thresh = cv2.threshold(gray, 127, 255, 0)
# 查找轮廓
contours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
# 在原始图像上绘制所有轮廓
cv2.drawContours(img, contours, -1, (0,255,0), 3)
# 显示图像
cv2.imshow('Image with Contours', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
例:绘制所有轮廓
绘制一幅图像内的所有轮廓。如果要绘制图像内的所有轮廓,需要将函数cv2.drawContours()的参数contourIdx的值设置为-1。
import cv2
# 读取图片
o = cv2.imread('contours.bmp')
cv2.imshow("original", o)
# 转换为灰度图
gray = cv2.cvtColor(o, cv2.COLOR_BGR2GRAY)
# 应用二值化
ret, binary = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
# 寻找轮廓
contours, hierarchy = cv2.findContours(binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 在原图上绘制轮廓
o = cv2.drawContours(o, contours, -1, (0, 0, 255), 5)
# 显示结果图像
cv2.imshow("result", o)
# 等待按键后关闭所有窗口
cv2.waitKey()
cv2.destroyAllWindows()

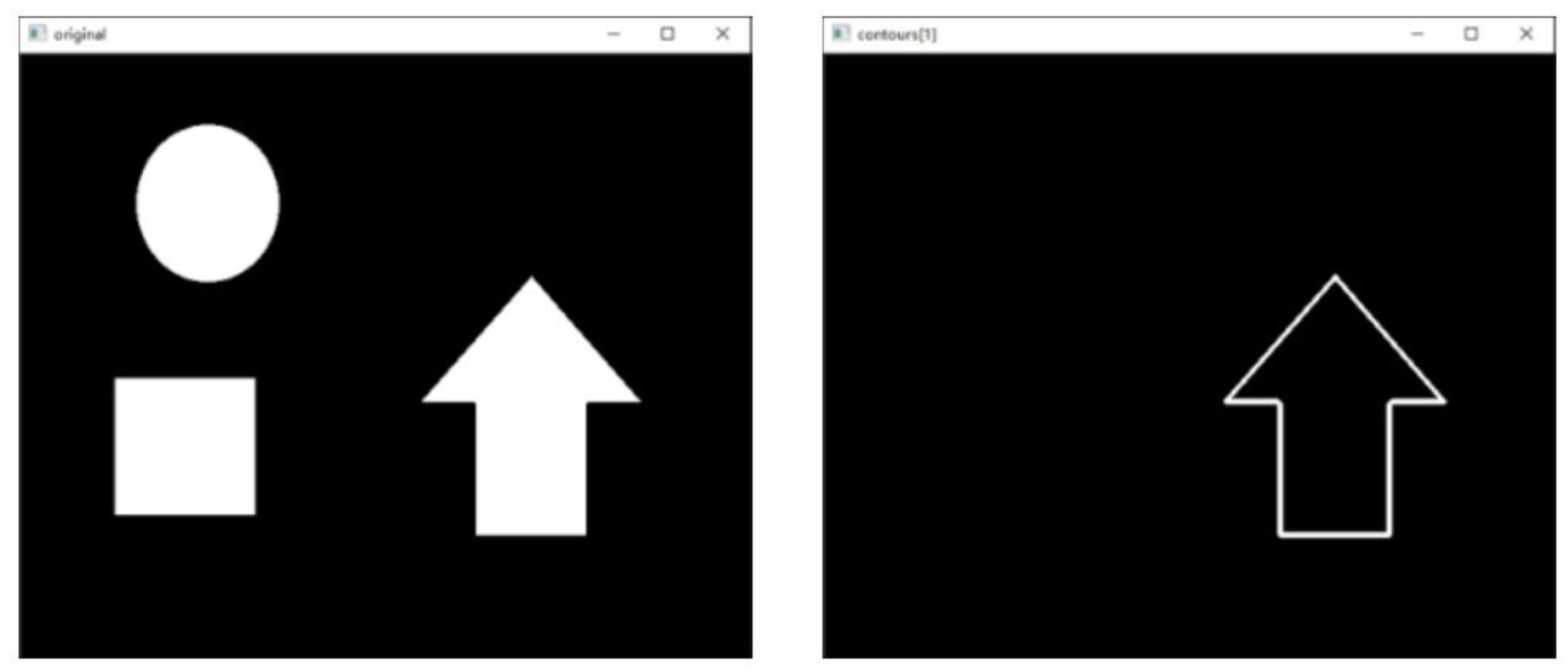
例:逐个显示轮廓
逐个显示一幅图像内的边缘信息。
如果要绘制图像内的某个具体轮廓,需要将函数cv2.drawContours()的参数contourIdx设置为具体的索引值。本例通过循环语句逐一绘制轮廓。
import cv2
import numpy as np
# 读取图片
o = cv2.imread('contours.bmp')
cv2.imshow("original", o)
# 转换为灰度图
gray = cv2.cvtColor(o, cv2.COLOR_BGR2GRAY)
# 应用二值化
ret, binary = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
# 寻找轮廓
contours, hierarchy = cv2.findContours(binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
n = len(contours)
contoursImg = []
for i in range(n):
# 创建一个与原图相同尺寸的黑色图像
temp = np.zeros(o.shape, np.uint8)
# 在相应的图像上绘制每个轮廓
contoursImg.append(cv2.drawContours(temp, contours, i, (255, 255, 255), 5))
# 显示每个轮廓图像
cv2.imshow("contours[" + str(i) + "]", contoursImg[i])
# 等待按键后销毁所有窗口
cv2.waitKey()
cv2.destroyAllWindows()

例:提取前景对象
使用轮廓绘制功能,提取前景对象。具体步骤为:
- 将函数cv2.drawContours()的参数
thickness的值设置为-1,可以绘制前景对象的实心轮廓。 - 将该实心轮廓与原始图像进行
按位与操作,即可将前景对象从原始图像中提取出来。
import cv2
import numpy as np
# 读取图片
o = cv2.imread('loc3.jpg')
cv2.imshow("original", o)
# 转换为灰度图
gray = cv2.cvtColor(o, cv2.COLOR_BGR2GRAY)
# 应用二值化
ret, binary = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
# 寻找轮廓
contours, hierarchy = cv2.findContours(binary, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
# 创建一个遮罩
mask = np.zeros(o.shape, np.uint8)
# 绘制轮廓
mask = cv2.drawContours(mask, contours, -1, (255, 255, 255), -1)
# 显示遮罩
cv2.imshow("mask", mask)
# 应用遮罩
loc = cv2.bitwise_and(o, mask)
# 显示结果
cv2.imshow("location", loc)
# 等待按键后关闭所有窗口
cv2.waitKey()
cv2.destroyAllWindows()

12.2 矩特征
基础概念
矩特征的理论基础来源于数学中的矩概念,它在图像处理和计算机视觉中被广泛应用。矩是一种描述图像特定属性的统计量,可以用来表征图像的形状、大小、方向等信息。以下是矩特征的几个关键概念和理论基础:
-
几何矩(Geometric Moments):
- 定义:几何矩是图像像素强度的加权和。对于二维图像 I ( x , y ) I(x, y) I(x,y),其 p + q p+q p+q阶矩定义为 M p q = ∑ x ∑ y x p y q I ( x , y ) M_{pq} = \sum_x \sum_y x^p y^q I(x, y) Mpq=∑x∑yxpyqI(x,y)。
- 零阶矩 M 00 M_{00} M00 描述了图像的“质量”,可以视为图像的面积或总亮度。
- 一阶矩 M 10 M_{10} M10 和 M 01 M_{01} M01 与图像的质心或重心位置有关。
-
中心矩(Central Moments):
- 定义:中心矩是相对于图像质心的矩,定义为 μ p q = ∑ x ∑ y ( x − x ˉ ) p ( y − y ˉ ) q I ( x , y ) \mu_{pq} = \sum_x \sum_y (x - \bar{x})^p (y - \bar{y})^q I(x, y) μpq=∑x∑y(x−xˉ)p(y−yˉ)qI(x,y),其中 x ˉ = M 10 M 00 \bar{x} = \frac{M_{10}}{M_{00}} xˉ=M00M10 和 y ˉ = M 01 M 00 \bar{y} = \frac{M_{01}}{M_{00}} yˉ=M00M01 是图像的质心坐标。
- 中心矩对图像的平移具有不变性,即当图像平移时,中心矩的值不变。
-
归一化中心矩(Normalized Central Moments):
- 定义:归一化中心矩是对中心矩的进一步处理,定义为 η p q = μ p q μ 00 ( 1 + p + q 2 ) \eta_{pq} = \frac{\mu_{pq}}{\mu_{00}^{(1 + \frac{p+q}{2})}} ηpq=μ00(1+2p+q)μpq。
- 归一化中心矩对图像的尺度变化具有不变性。
-
Hu矩(Hu Moments):
- 定义:Hu矩是由归一化中心矩组合而成的一组矩,它们具有平移、尺度和旋转不变性。
- 应用:Hu矩常用于图像匹配和识别,因为它们可以唯一地表示图像的某些基本特征。
-
数学性质:
- 矩特征在数学上具有多种性质,如加法性、尺度不变性、旋转不变性等,这使得它们在图像分析和模式识别中非常有用。
- 不同阶数和类型的矩揭示了图像的不同特性,例如形状、大小、方向等。
moments函数原型
cv2.moments() 函数在 OpenCV 中用于计算图像的矩(Moments),其函数原型如下:
M = cv2.moments(array, binaryImage=False)
参数说明:
-
array:这是一个二维数组或图像矩阵,通常是一个灰度图像或二值图像。在实际应用中,
array通常是通过图像处理方法(如阈值处理、边缘检测等)得到的。 -
binaryImage(可选):这是一个布尔值,用于指示传入的
array是否应被视为二值图像。如果设置为True,则所有非零像素值都被视为1,这对处理二值图像特别有用。默认值是False。
返回值:
cv2.moments() 返回一个字典,包含了计算得到的各种矩。这些矩包括:
- 几何矩,如
m00,m01,m10,m20,m11,m02,m30,m21,m12,m03。 - 中心矩,如
mu20,mu11,mu02,mu30,mu21,mu12,mu03。 - 归一化中心矩,如
nu20,nu11,nu02,nu30,nu21,nu12,nu03。
这些矩可以用于进一步的图像分析和处理,例如计算图像的质心、面积、方向等。
moments使用步骤
- 读取图像:首先,加载要处理的图像。
- 预处理:通常包括将图像转换为灰度图,然后应用阈值处理或边缘检测。
- 找到轮廓:使用
cv2.findContours()找到图像的轮廓。 - 计算矩:对每个轮廓使用
cv2.moments()来计算矩。 - 使用矩:可以根据矩来计算质心、面积等特性。
求坐标和质心计算
m00是图像的面积(或总像素值)。- 质心的 xx 坐标可以用
cx = M['m10']/M['m00']计算。 - 质心的 yy 坐标可以用
cy = M['m01']/M['m00']计算。
moments注意事项
- 如果
m00(零阶矩,代表图像区域的总像素值或面积)为零,这意味着图像中没有非零像素,可能导致在计算质心时除以零的错误。因此,在使用m00进行除法运算前,应检查其值是否为零。 - 对于彩色图像,通常先将其转换为灰度图像或处理一个特定的颜色通道。
cv2.moments()函数通常应用于二值图像,因为在二值图像上计算矩更加直观和有效。
例:求面积和质心并标记
import cv2
import numpy as np
# 读取图像(以灰度模式)
image = cv2.imread('path_to_your_image.jpg', cv2.IMREAD_GRAYSCALE)
# 对图像进行二值化处理
_, binary_image = cv2.threshold(image, 127, 255, cv2.THRESH_BINARY)
# 计算矩
M = cv2.moments(binary_image)
# 使用几何矩计算面积
area = M['m00']
# 使用一阶矩计算质心
cx = int(M['m10'] / M['m00']) if M['m00'] != 0 else 0
cy = int(M['m01'] / M['m00']) if M['m00'] != 0 else 0
# 打印结果
print("面积: ", area)
print("质心: (", cx, ",", cy, ")")
# 在图像上标记质心
marked_image = cv2.cvtColor(binary_image, cv2.COLOR_GRAY2BGR)
cv2.circle(marked_image, (cx, cy), 5, (0, 0, 255), -1)
# 显示图像
cv2.imshow('Marked Image', marked_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
contourArea函数原型
cv2.contourArea() 是 OpenCV 中的一个函数,用于计算轮廓的面积。在计算机视觉和图像处理中,这个函数经常用于确定图像中对象的大小。
area = cv2.contourArea(contour, oriented=False)
参数说明:
- contour:这是一个代表图像中单个轮廓的 NumPy 数组。通常,这个数组是通过
cv2.findContours()函数获得的。轮廓是由点的序列组成的,这些点形成了对象或图像部分的边界。 - oriented(可选):这是一个布尔值,用于指定计算的面积是否应该是有向面积。默认值为
False,这意味着计算的面积总是正值。如果设置为True,面积的符号将根据轮廓的方向确定(顺时针或逆时针)。
返回值:
- 函数返回一个单个浮点数,代表了轮廓的面积。
例:计算各个轮廓的面积
使用函数cv2.contourArea()计算各个轮廓的面积
import cv2
import numpy as np
# 读取图像
o = cv2.imread('contours.bmp') # 替换为你的图像路径
# 将图像转换为灰度图
gray = cv2.cvtColor(o, cv2.COLOR_BGR2GRAY)
# 应用二值化处理
ret, binary = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
# 查找轮廓
contours, hierarchy = cv2.findContours(binary, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
# 显示原始图像
cv2.imshow("original", o)
# 获取轮廓数量
n = len(contours)
# 初始化一个列表来存储每个轮廓的图像
contoursImg = []
for i in range(n):
# 打印每个轮廓的面积
print("contours[" + str(i) + "]面积 =", cv2.contourArea(contours[i]))
# 创建一个与原始图像大小相同的黑色图像
temp = np.zeros(o.shape, np.uint8)
# 将当前轮廓画在黑色图像上
contoursImg.append(temp)
contoursImg[i] = cv2.drawContours(contoursImg[i], contours, i, (255, 255, 255), 3)
# 显示当前轮廓的图像
cv2.imshow("contours[" + str(i) + "]", contoursImg[i])
# 等待按键操作
cv2.waitKey()
# 关闭所有OpenCV窗口
cv2.destroyAllWindows()
输出为:
contours[0]面积= 13108.0
contours[1]面积= 19535.0
contours[2]面积= 12058.0

例:将面积大于15000的轮廓筛选出来
import cv2
import numpy as np
# 读取图像
o = cv2.imread('contours.bmp') # 替换为你的图像路径
cv2.imshow("original", o) # 显示原始图像
# 将图像转换为灰度图
gray = cv2.cvtColor(o, cv2.COLOR_BGR2GRAY)
# 应用二值化处理
ret, binary = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
# 查找轮廓
contours, hierarchy = cv2.findContours(binary, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
# 获取轮廓数量
n = len(contours)
# 初始化一个列表来存储每个轮廓的图像
contoursImg = []
for i in range(n):
# 创建一个与原始图像大小相同的黑色图像
temp = np.zeros(o.shape, np.uint8)
# 将当前轮廓画在黑色图像上
contoursImg.append(temp)
contoursImg[i] = cv2.drawContours(contoursImg[i], contours, i, (255, 255, 255), 3)
# 检查当前轮廓的面积是否大于 15000 个像素单位
if cv2.contourArea(contours[i]) > 15000:
# 如果是,显示该轮廓的图像
cv2.imshow("contours[" + str(i) + "]", contoursImg[i])
# 等待按键操作
cv2.waitKey()
# 关闭所有OpenCV窗口
cv2.destroyAllWindows()
arcLength函数原型
arcLength 函数是 OpenCV 中用于计算轮廓或曲线的周长(或弧长)的函数。它的函数原型如下:
length = cv2.arcLength(curve, closed)
参数说明:
- curve:这是一个代表轮廓或曲线的 NumPy 数组。通常情况下,这个数组是通过
cv2.findContours()函数获得的,表示一个轮廓的所有点。 - closed:这是一个布尔值,指示轮廓是否闭合。如果轮廓是闭合的(如圆形、矩形等),则设置为
True;如果轮廓是非闭合的(如一段曲线),则设置为False。
返回值:
- 函数返回一个浮点数,表示轮廓或曲线的总长度。
例:长度大于平均值的轮廓显示出来
import cv2
import numpy as np
# 读取并显示原始图像
o = cv2.imread('contours0.bmp') # 替换为你的图像路径
cv2.imshow("original", o)
# 将图像转换为灰度图并进行二值化处理
gray = cv2.cvtColor(o, cv2.COLOR_BGR2GRAY)
ret, binary = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
# 查找二值图像中的轮廓
contours, hierarchy = cv2.findContours(binary, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
# 计算并打印每个轮廓的长度,存储长度值
n = len(contours) # 轮廓的数量
cntLen = [] # 存储各轮廓的长度
for i in range(n):
length = cv2.arcLength(contours[i], True)
cntLen.append(length)
print("第" + str(i) + "个轮廓的长度:%d" % length)
# 计算轮廓长度的总和和平均长度
cntLenSum = np.sum(cntLen) # 轮廓长度的总和
cntLenAvr = cntLenSum / n # 轮廓长度的平均值
print("轮廓的总长度为:%d" % cntLenSum)
print("轮廓的平均长度为:%d" % cntLenAvr)
# 初始化一个列表,用于存储每个轮廓的图像
contoursImg = []
# 遍历所有找到的轮廓
for i in range(n):
# 创建一个与原图大小相同的黑色图像(用于绘制轮廓)
temp = np.zeros(o.shape, np.uint8)
# 将创建的黑色图像添加到列表中
contoursImg.append(temp)
# 在黑色图像上绘制当前轮廓(轮廓用白色线条宽度为3绘制)
contoursImg[i] = cv2.drawContours(contoursImg[i], contours, i, (255, 255, 255), 3)
# 判断当前轮廓的长度是否大于平均长度
if cv2.arcLength(contours[i], True) > cntLenAvr:
# 如果是,则显示该轮廓的图像
cv2.imshow("contours[" + str(i) + "]", contoursImg[i])
# 等待按键操作
cv2.waitKey()
# 关闭所有OpenCV窗口
cv2.destroyAllWindows()
cv2.arcLength(contours[i], True)用于计算每个闭合轮廓的长度。
输出为:
第0个轮廓的长度:145
第1个轮廓的长度:147
第2个轮廓的长度:398
第3个轮廓的长度:681
第4个轮廓的长度:1004
第5个轮廓的长度:398
第6个轮廓的长度:681
第7个轮廓的长度:1004
第8个轮廓的长度:2225
第9个轮廓的长度:2794
轮廓的总长度为:9480
轮廓的平均长度为:948

12.3 Hu矩
12.4 轮廓拟合
在计算轮廓时,可能并不需要实际的轮廓,而仅需要一个接近于轮廓的近似多边形。OpenCV提供了多种计算轮廓近似多边形的方法。
boundingRect(矩形包围框)函数原型
cv2.boundingRect() 函数在 OpenCV 中用于计算给定轮廓的最小矩形边界框。这个边界框是一个没有旋转的矩形,完全覆盖轮廓。函数的返回值是一个包含四个元素的元组,这些元素代表矩形边界框的位置和大小。
函数原型:
x, y, w, h = cv2.boundingRect(contour)
参数说明:
- contour:代表单个轮廓的 NumPy 数组。这个数组通常是通过
cv2.findContours()函数获得的。
返回值:
- x:边界框左上角的 x 坐标。
- y:边界框左上角的 y 坐标。
- w:边界框的宽度。
- h:边界框的高度。
例:返回矩形框顶点长宽和元组
import cv2
# 读取并显示原始图像
o = cv2.imread('cc.bmp') # 确保这里的路径指向你的图像文件
# 如果需要显示图像,可以取消下面一行的注释
# cv2.imshow("original", o)
# 将图像转换为灰度图
gray = cv2.cvtColor(o, cv2.COLOR_BGR2GRAY)
# 应用二值化处理
ret, binary = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
# 查找二值图像中的轮廓
contours, hierarchy = cv2.findContours(binary, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
# 计算第一个轮廓的矩形边界,并返回顶点及边长
x, y, w, h = cv2.boundingRect(contours[0])
print("顶点及长宽的点形式:")
print("x=", x)
print("y=", y)
print("w=", w)
print("h=", h)
# 以单个返回值的形式获取矩形边界的信息
rect = cv2.boundingRect(contours[0])
print("\n顶点及长宽的元组(tuple)形式:")
print("rect=", rect)
# 如果之前显示了图像,这两行将等待并关闭窗口
# cv2.waitKey()
# cv2.destroyAllWindows()
输出为:
顶点及长宽的点形式:
x= 202
y= 107
w= 157
h= 73
顶点及长宽的元组(tuple)形式:
rect= (202, 107, 157, 73)
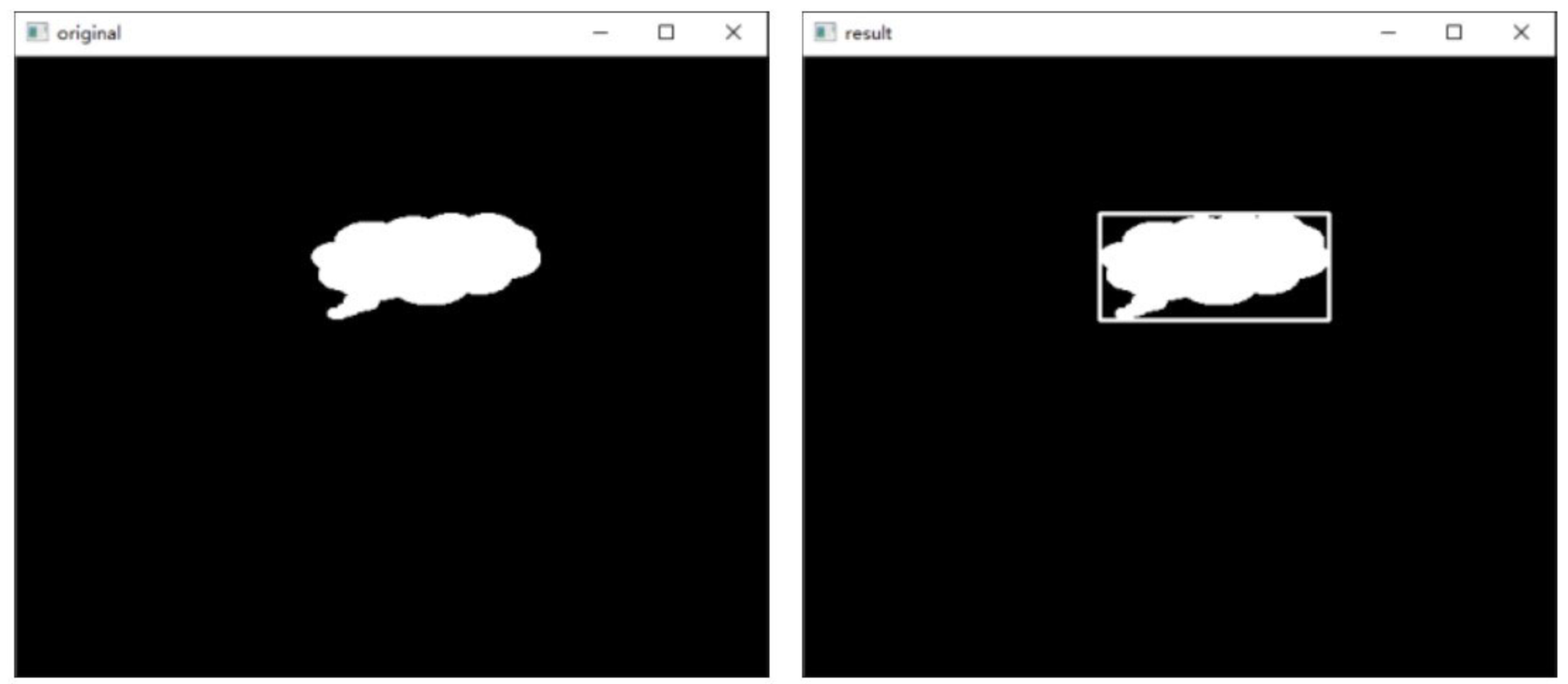
例:绘制矩形包围框
import cv2
import numpy as np
# 读取并显示原始图像
o = cv2.imread('cc.bmp') # 确保这里的路径指向你的图像文件
cv2.imshow("original", o)
# 将图像转换为灰度图
gray = cv2.cvtColor(o, cv2.COLOR_BGR2GRAY)
# 应用二值化处理
ret, binary = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
# 查找二值图像中的轮廓
contours, hierarchy = cv2.findContours(binary, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
# 计算第一个轮廓的矩形边界
x, y, w, h = cv2.boundingRect(contours[0])
# 构造矩形边界的四个顶点
brcnt = np.array([[[x, y]], [[x + w, y]], [[x + w, y + h]], [[x, y + h]]])
# 在原始图像上绘制矩形边界
cv2.drawContours(o, [brcnt], -1, (255, 255, 255), 2)
# 显示带有矩形边界的图像
cv2.imshow("result", o)
# 等待按键操作
cv2.waitKey()
# 关闭所有OpenCV窗口
cv2.destroyAllWindows()
minAreaRect( 最小包围矩形框)函数原型
cv2.minAreaRect() 函数是 OpenCV 中用于计算给定轮廓的最小面积边界旋转矩形的函数。不同于 cv2.boundingRect(),这个函数计算的矩形可能是旋转的,以便它可以包含给定轮廓的最小面积。
函数原型:
rect = cv2.minAreaRect(points)
参数说明:
- points:代表轮廓的点集。这通常是一个 NumPy 数组,包含轮廓上的点。这个数组通常是通过
cv2.findContours()函数获得的。
返回值:
- rect:一个包含三个元素的元组,表示最小面积旋转矩形。元组包含:
- 矩形的中心点坐标 (x, y)
- 矩形的宽度和高度 (width, height)
- 矩形的旋转角度 angle
注意:返回值retval的结构不符合函数cv2.drawContours()的参数结构要求。因此,必须将其转换为符合要求的结构,才能使用。函数cv2.boxPoints()能够将上述返回值retval转换为符合要求的结构。函数cv2.boxPoints()的语法格式是:
points = cv2.boxPoints(rect)
- 参数:
rect:由cv2.minAreaRect()返回的旋转矩形。
- 返回值:
points:矩形的四个角点,通常为一个包含四个点的数组。
例:计算并显示图像的最小包围矩形框
import cv2
import numpy as np
# 读取图像
o = cv2.imread('cc.bmp') # 确保这里的路径指向你的图像文件
cv2.imshow("original", o) # 显示原始图像
# 将图像转换为灰度图
gray = cv2.cvtColor(o, cv2.COLOR_BGR2GRAY)
# 应用二值化处理
ret, binary = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
# 查找二值图像中的轮廓
contours, hierarchy = cv2.findContours(binary, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
# 计算第一个轮廓的最小面积旋转矩形
rect = cv2.minAreaRect(contours[0])
print("返回值rect:\n", rect) # 打印旋转矩形的中心点、尺寸和旋转角度
# 将旋转矩形转换为矩形的四个角点
points = cv2.boxPoints(rect)
print("\n转换后的points:\n", points) # 打印矩形的四个角点
# 将浮点数坐标转换为整数
points = np.int0(points)
# 在原始图像上绘制最小面积旋转矩形
image = cv2.drawContours(o, [points], 0, (255, 255, 255), 2)
# 显示绘制了旋转矩形的图像
cv2.imshow("result", o)
# 等待按键操作
cv2.waitKey()
# 关闭所有OpenCV窗口
cv2.destroyAllWindows()
- 使用
cv2.minAreaRect()计算第一个找到的轮廓的最小面积旋转矩形。 - 使用
cv2.boxPoints()将旋转矩形转换为四个角点。
输出为:
返回值rect:
((280.3699951171875, 138.58999633789062), (154.99778747558594,63.78103256225586), -8.130102157592773)
转换后的points:
[[208.16002 181.12 ]
[199.14 117.979996]
[352.57996 96.06 ]
[361.59998 159.2 ]]

minEnclosingCircle(最小包围圆形)函数原型
cv2.minEnclosingCircle() 是 OpenCV 中的一个函数,用于找到完全覆盖指定轮廓的最小圆形边界。这个函数对于封装给定轮廓的最小圆是非常有用的,特别是在形状分析和对象检测中。
函数原型:
(center, radius) = cv2.minEnclosingCircle(points)
参数说明:
- points:代表轮廓的点集。这通常是一个 NumPy 数组,包含轮廓上的点。这个数组通常是通过
cv2.findContours()函数获得的。
返回值:
- center:圆心的坐标,表示为
(x, y)形式的元组。 - radius:圆的半径。
例:构造图像的最小包围圆形
import cv2
# 读取图像
o = cv2.imread('cc.bmp') # 确保这里的路径指向你的图像文件
cv2.imshow("original", o) # 显示原始图像
# 将图像转换为灰度图
gray = cv2.cvtColor(o, cv2.COLOR_BGR2GRAY)
# 应用二值化处理
ret, binary = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
# 查找二值图像中的轮廓
contours, hierarchy = cv2.findContours(binary, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
# 计算第一个轮廓的最小封闭圆
(x, y), radius = cv2.minEnclosingCircle(contours[0])
# 将圆心坐标和半径转换为整数
center = (int(x), int(y))
radius = int(radius)
# 在原始图像上绘制最小封闭圆
cv2.circle(o, center, radius, (255, 255, 255), 2)
# 显示绘制了最小封闭圆的图像
cv2.imshow("result", o)
# 等待按键操作
cv2.waitKey()
# 关闭所有OpenCV窗口
cv2.destroyAllWindows()

fitEllipse(最优拟合椭圆)函数原型
cv2.fitEllipse() 是 OpenCV 中的一个函数,用于找到给定轮廓的最小面积的拟合椭圆。这个函数在形状分析和对象检测中非常有用,特别是当处理的对象近似为椭圆形时。
函数原型:
ellipse = cv2.fitEllipse(points)
参数说明:
- points:代表轮廓的点集。这通常是一个 NumPy 数组,包含轮廓上的点。这个数组通常是通过
cv2.findContours()函数获得的。
返回值:
- ellipse:一个表示椭圆的元组,包含以下内容:
- 椭圆中心的坐标 (x, y)
- 椭圆的尺寸 (长轴长度, 短轴长度)
- 椭圆的旋转角度
例:构造最优拟合椭圆
import cv2
# 读取图像
o = cv2.imread('cc.bmp') # 确保这里的路径指向你的图像文件
# 将图像转换为灰度图
gray = cv2.cvtColor(o, cv2.COLOR_BGR2GRAY)
# 应用二值化处理
ret, binary = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
# 查找二值图像中的轮廓
contours, hierarchy = cv2.findContours(binary, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
# 显示原始图像
cv2.imshow("original", o)
# 计算第一个轮廓的最小面积拟合椭圆
ellipse = cv2.fitEllipse(contours[0])
print("ellipse=", ellipse) # 打印椭圆的参数
# 在原始图像上绘制拟合椭圆
cv2.ellipse(o, ellipse, (0, 255, 0), 3) # 使用绿色线条绘制椭圆
# 显示绘制了拟合椭圆的图像
cv2.imshow("result", o)
# 等待按键操作
cv2.waitKey()
# 关闭所有OpenCV窗口
cv2.destroyAllWindows()
输出为:
ellipse= ((276.2112731933594, 139.6067352294922), (63.01350021362305,
166.72308349609375), 82.60102844238281)
-
(276.2112731933594, 139.6067352294922)是椭圆的中心点。
-
(63.01350021362305, 166.72308349609375)是椭圆的轴长度。
-
82.60102844238281是椭圆的旋转角度。

fitLine(最优拟合直线)函数原型
cv2.fitLine() 是 OpenCV 中的一个函数,用于根据指定的算法拟合一个直线。该函数适用于一组点,并找到最佳拟合线。
函数原型:
line = cv2.fitLine(points, distType, param, reps, aeps)
参数说明:
-
points:这是一个包含二维点或三维点的 NumPy 数组。这些点可以是轮廓的点,也可以是任何需要拟合线的点集。这个数组通常是通过
cv2.findContours()函数获得的。 -
distType:距离类型。这是一个表示点到拟合线的距离度量方式的参数。常用的距离类型包括:
cv2.DIST_L2:普通的最小二乘法拟合。cv2.DIST_L1:绝对值的和最小。cv2.DIST_L12:L1-L2混合的距离。cv2.DIST_FAIR、cv2.DIST_WELSCH等:其他更复杂的类型。
-
param:对于某些距离类型,这是一个额外的参数。当此参数被设置为0时,该函数会自动选择最优值。
-
reps 和 aeps:这些参数分别是坐标和轴的精度,通常可以设置为小数(如 0.01 或 0.001)。
返回值:
- line:一个包含直线参数的数组。对于二维直线,返回值是一个包含四个元素
[vx, vy, x0, y0]的向量,其中(vx, vy)是直线的方向向量,(x0, y0)是直线上的一个点。
用途:
cv2.fitLine() 在图像处理和计算机视觉中广泛应用,特别是在需要从一组散乱点中找到最佳拟合线的场景中,如边缘检测、轮廓分析、立体视觉等。
例:构造最优拟合直线
import cv2
# 读取图像
o = cv2.imread('cc.bmp') # 确保这里的路径指向你的图像文件
cv2.imshow("original", o) # 显示原始图像
# 将图像转换为灰度图
gray = cv2.cvtColor(o, cv2.COLOR_BGR2GRAY)
# 应用二值化处理
ret, binary = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
# 查找二值图像中的轮廓
contours, hierarchy = cv2.findContours(binary, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
# 获取图像的行数和列数
rows, cols = o.shape[:2]
# 使用cv2.fitLine()函数找到轮廓的最佳拟合直线
[vx, vy, x, y] = cv2.fitLine(contours[0], cv2.DIST_L2, 0, 0.01, 0.01)
# 计算直线的两个端点
lefty = int((-x * vy / vx) + y)
righty = int(((cols - x) * vy / vx) + y)
# 在图像上绘制最佳拟合直线
cv2.line(o, (cols - 1, righty), (0, lefty), (0, 255, 0), 2)
# 显示绘制了拟合直线的图像
cv2.imshow("result", o)
# 等待按键操作
cv2.waitKey()
# 关闭所有OpenCV窗口
cv2.destroyAllWindows()

minEnclosingTriangle(最小外包三角形)函数原型
截至我的最后更新数据(2023年4月),OpenCV Python库中确实包含了一个 cv2.minEnclosingTriangle() 函数。这个函数用于计算给定点集的最小封闭三角形。请注意,这个函数可能不在所有版本的OpenCV中都可用,它在较新版本的OpenCV中被引入。
函数原型:
retval, triangle = cv2.minEnclosingTriangle(points)
参数说明:
- points:这是一个二维点集,通常是一个NumPy数组,其中包含了需要计算最小封闭三角形的点。这个数组通常是通过
cv2.findContours()函数获得的。
返回值:
-
retval:三角形的面积。
-
triangle:一个表示最小封闭三角形的三个顶点的数组。这个数组是一个形状为 (3, 1, 2) 的NumPy数组,其中每个顶点是一个形式为
[x, y]的数组,如下所示:[[[x1, y1]], [[x2, y2]], [[x3, y3]]]
请注意,这个函数在一些特定条件下可能无法正确工作(例如,当点集中的所有点都位于同一直线上时),因此使用时需要小心处理异常情况。
例:构造最小外包三角形
import cv2
import numpy as np
# 读取图片
o = cv2.imread('cc.bmp')
cv2.imshow("original", o)
# 转换为灰度图
gray = cv2.cvtColor(o, cv2.COLOR_BGR2GRAY)
# 应用二值化
ret, binary = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
# 寻找轮廓
contours, hierarchy = cv2.findContours(binary, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
# 计算最小包围三角形及其面积
area, trgl = cv2.minEnclosingTriangle(contours[0])
print("面积 =", area)
print("三角形顶点:", trgl)
# 检查三角形顶点的格式,并进行必要的调整
if trgl is not None and len(trgl) == 3:
trgl = np.int32(trgl) # 确保顶点坐标为整数
# 绘制三角形
for i in range(3):
pt1 = tuple(trgl[i][0])
pt2 = tuple(trgl[(i + 1) % 3][0])
cv2.line(o, pt1, pt2, (255, 255, 255), 2)
else:
print("未找到有效的三角形顶点")
# 显示结果
cv2.imshow("result", o)
# 等待按键后关闭所有窗口
cv2.waitKey()
cv2.destroyAllWindows()
- 注意:要把
minEnclosingTriangle返回的trgl转成整数,否则会报错 pt1 = tuple(trgl[i][0]):trgl[i][0]:这部分从trgl数组中选取第i个顶点的坐标。trgl是一个形状为(3, 1, 2)的数组,代表三个顶点。每个顶点的坐标以[x, y]的形式存储。因此,trgl[i]是形状为(1, 2)的数组,表示第i个顶点的坐标。tuple(...):将顶点坐标从数组形式转换为元组(x, y)。这是因为cv2.line函数需要点坐标以(x, y)元组的形式。
pt2 = tuple(trgl[(i + 1) % 3][0]):trgl[(i + 1) % 3][0]:这里使用了模运算(i + 1) % 3来循环访问三角形的顶点。例如,当i = 0时,它将选取第二个顶点 (i + 1 = 1);当i = 2(最后一个顶点)时,i + 1会变成3,但由于模运算3 % 3,它将回到第一个顶点 (0)。tuple(...):与上面相同,将顶点坐标转换为元组形式。
输出为:
面积 = 12904.00390625
三角形顶点: [[[441.41028 107. ]]
[[193.25641 107. ]]
[[222.58974 211. ]]]

approxPolyDP(逼近多边形)函数原型
cv2.approxPolyDP() 是 OpenCV 中的一个函数,用于将轮廓近似为另一个具有较少顶点的轮廓,这通常用于简化轮廓或获得几何形状的多边形近似表示。
函数原型:
approx = cv2.approxPolyDP(curve, epsilon, closed)
参数说明:
-
curve:这是要近似的轮廓,通常是一个NumPy数组,包含轮廓上的点。这个数组通常是通过
cv2.findContours()函数获得的。 -
epsilon:这是近似精度的参数。它是原始轮廓到其近似轮廓的最大距离。通常,它可以设置为轮廓周长的一个小百分比。
-
closed:该值为
True时,逼近多边形是封闭的;否则,逼近多边形是不封闭的。
返回值:
- approx:一个NumPy数组,表示近似后的轮廓。这个数组的形状和原始轮廓数组类似,但通常包含更少的顶点。
用途:
cv2.approxPolyDP() 函数在图像处理和计算机视觉中广泛应用,尤其是在轮廓分析、形状识别和几何建模等领域。通过减少轮廓中的点数,它可以帮助简化形状的表示,有助于识别和分类几何图形。
例:构造不同精度的逼近多边形
import cv2
# 读取并显示原始图像
o = cv2.imread('cc.bmp') # 确保这里的路径指向你的图像文件
cv2.imshow("original", o)
# 将图像转换为灰度图
gray = cv2.cvtColor(o, cv2.COLOR_BGR2GRAY)
# 应用二值化处理
ret, binary = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
# 查找二值图像中的轮廓
contours, hierarchy = cv2.findContours(binary, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
# 使用不同的epsilon值进行轮廓近似,并显示结果
# epsilon是轮廓近似的精度,是轮廓周长的一个百分比
for eps_factor in [0.1, 0.09, 0.055, 0.05, 0.02]:
# 复制原始图像以便绘制
adp = o.copy()
# 计算epsilon值(轮廓周长的一个百分比)
epsilon = eps_factor * cv2.arcLength(contours[0], True)
# 进行轮廓近似
approx = cv2.approxPolyDP(contours[0], epsilon, True)
# 在图像上绘制近似后的轮廓
adp = cv2.drawContours(adp, [approx], 0, (0, 0, 255), 2)
# 显示结果
cv2.imshow("result" + str(eps_factor), adp)
# 等待按键操作
cv2.waitKey()
# 关闭所有OpenCV窗口
cv2.destroyAllWindows()

-
(a)图是图像o。
-
(b)图显示了
epsilon=0.1周长的逼近多边形(实际上,在第1次的查找过程中仅仅找到了一条直线)。 -
©图显示了
epsilon=0.09周长的逼近多边形。 -
(d)图显示了
epsilon=0.055周长的逼近多边形。 -
(e)图显示了
epsilon=0.05周长的逼近多边形。 -
(f)图显示了
epsilon=0.02周长的逼近多边形。
12.5 凸包
12.6 利用形状场景算法比较轮廓
12.7 轮廓的特征值
第十三章 直方图处理
13.1 直方图的含义
13.2 绘制直方图
13.3 直方图均衡化
13.4 pyplot模块介绍
第十四章 傅里叶变换
14.1 理论基础
14.2 Numpy实现傅里叶变换
14.3 OpenCV实现傅里叶变换
14.4 滤波处理
第十五章 模板匹配
模板匹配是指在当前图像A内寻找与图像B最相似的部分,一般将图像A称为输入图像,将图像B称为模板图像。模板匹配的操作方法是将模板图像B在图像A上滑动,遍历所有像素以完成匹配。
例如,在下图中,希望在图中的大图像“lena”内寻找左上角的“眼睛”图像。此时,大图像“lena”是输入图像,“眼睛”图像是模板图像。查找的方式是,将模板图像在输入图像内从左上角开始滑动,逐个像素遍历整幅输入图像,以查找与其最匹配的部分。

15.1 模板匹配基础
matchTemplate(模板匹配)函数原型
cv2.matchTemplate() 函数用于在更大的源图像中查找模板图像的匹配区域。此函数在源图像上滑动模板图像,并在每个位置计算模板与该区域的匹配度。匹配度的计算方式取决于所选的方法。
函数原型:
result = cv2.matchTemplate(image, templ, method, mask=None)
参数详解:
-
image:待搜索的源图像。它必须是灰度图或彩色图像,但应与模板图像的通道数匹配。
-
templ:模板图像,它的大小和类型(如灰度、彩色)应与源图像一致。模板的大小应小于源图像的大小。
-
method:指定比较方法的标志。OpenCV 提供了多种匹配方法,包括:
cv2.TM_SQDIFF和cv2.TM_SQDIFF_NORMED:这些方法计算模板与图像区域之间的平方差。最佳匹配是最小值。cv2.TM_CCORR和cv2.TM_CCORR_NORMED:相关性匹配方法。最佳匹配是最大值。cv2.TM_CCOEFF和cv2.TM_CCOEFF_NORMED:相关系数匹配方法。最佳匹配是最大值。这些方法考虑了模板和图像区域的平均强度。
-
mask(可选):模板的掩码,是一个与模板大小相同的二值图像。掩码指定了在模板中哪些区域应被考虑在内。
返回值:
- result:一个二维浮点数组,每个元素值表示模板与图像在对应位置的匹配度。数组的大小由源图像和模板图像的大小决定。
匹配位置的确定:
- 根据选定的比较方法,可以通过查找
result数组中的最小值或最大值来确定模板在源图像中的最佳匹配位置。 - 对于
cv2.TM_SQDIFF和cv2.TM_SQDIFF_NORMED方法,最佳匹配位置是result数组中的最小值位置。 - 对于其他方法,最佳匹配位置是
result数组中的最大值位置。 - 通常使用
cv2.minMaxLoc()函数来找到这个最小值或最大值位置。
minMaxLoc函数原型
cv2.minMaxLoc() 是 OpenCV 中用于查找数组(通常是图像或结果矩阵)中的最小值和最大值及其位置的函数。这个函数在图像处理中经常用于从结果矩阵中检索信息,如在模板匹配或特征检测后确定关键点的位置。
函数原型:
minVal, maxVal, minLoc, maxLoc = cv2.minMaxLoc(src, mask=None)
参数详解:
-
src:输入的单通道数组,通常是图像或图像处理操作(如边缘检测、模板匹配等)的结果。
-
mask(可选):一个可选的掩码,用于指定需要考虑的数组部分。如果提供掩码,函数将只在掩码的非零区域内查找最小和最大值。
返回值:
- minVal:数组中的最小值。
- maxVal:数组中的最大值。
- minLoc:最小值的位置,表示为
(x, y)坐标。 - maxLoc:最大值的位置,表示为
(x, y)坐标。
这四个返回值分别表示在给定数组(或掩码指定的数组区域)中找到的最小值、最大值及其对应的位置。
如何搭配使用
cv2.matchTemplate() 函数在进行模板匹配时提供了多种方法(method),每种方法对匹配结果的解释不同。根据选择的匹配方法,使用 cv2.minMaxLoc() 函数来找到最佳匹配位置的方式也会有所不同。
不同的匹配方法
-
平方差匹配 (
cv2.TM_SQDIFF和cv2.TM_SQDIFF_NORMED):- 最佳匹配的位置是在结果矩阵中的最小值位置。
- 使用
minLoc(minMaxLoc返回的最小值位置)作为最佳匹配的坐标。
-
相关性匹配 (
cv2.TM_CCORR和cv2.TM_CCORR_NORMED):- 最佳匹配的位置是在结果矩阵中的最大值位置。
- 使用
maxLoc(minMaxLoc返回的最大值位置)作为最佳匹配的坐标。
-
相关系数匹配 (
cv2.TM_CCOEFF和cv2.TM_CCOEFF_NORMED):- 最佳匹配的位置同样是在结果矩阵中的最大值位置。
- 使用
maxLoc作为最佳匹配的坐标。
使用 cv2.minMaxLoc()
无论选择哪种匹配方法,都使用 cv2.minMaxLoc() 来查找结果矩阵中的最小值和最大值及其位置:
minVal, maxVal, minLoc, maxLoc = cv2.minMaxLoc(result)
根据方法选择匹配位置
-
对于
cv2.TM_SQDIFF和cv2.TM_SQDIFF_NORMED,使用minLoc:if method in [cv2.TM_SQDIFF, cv2.TM_SQDIFF_NORMED]: bestMatch = minLoc # bestMatch 现在包含最佳匹配位置的坐标 -
对于其他方法,使用
maxLoc:else: bestMatch = maxLoc # bestMatch 现在包含最佳匹配位置的坐标
rectangle函数原型
cv2.rectangle() 是 OpenCV 中用于在图像上绘制矩形的函数。这个函数常用于在图像处理和计算机视觉任务中标记感兴趣的区域或对象。
函数原型:
cv2.rectangle(img, pt1, pt2, color, thickness=None, lineType=None, shift=None)
参数详解:
-
img:要绘制矩形的图像,它是一个NumPy数组。
-
pt1:矩形左上角的坐标,表示为
(x, y)的元组或列表。 -
pt2:矩形右下角的坐标,同样表示为
(x, y)的元组或列表。 -
color:矩形的颜色。在彩色图像中,它是
(B, G, R)格式的颜色值;在灰度图像中,它是灰度值。 -
thickness(可选):线条的粗细。如果是正数,表示线条的粗细;如果是负数(如
-1),表示填充整个矩形。 -
lineType(可选):线条的类型,例如
cv2.LINE_8或cv2.LINE_AA。cv2.LINE_8是8-connected line,cv2.LINE_AA是抗锯齿线条。 -
shift(可选):点坐标中小数点后的位数。这是用于子像素精度绘图的高级特性。
例:使用TM_SQDIFF进行匹配
使用函数cv2.matchTemplate()进行模板匹配。要求参数method的值设置为cv2.TM_SQDIFF,显示函数的返回结果及匹配结果。
import cv2
import matplotlib
from matplotlib import pyplot as plt
# 设置 Matplotlib 使用中文字符
matplotlib.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体
matplotlib.rcParams['axes.unicode_minus'] = False # 正确显示负号
# 读取原始图像和模板图像
img = cv2.imread('lena512g.bmp', 0)
img2 = img.copy()
template = cv2.imread('temp.bmp', 0)
# 获取模板的宽高
th, tw = template.shape[::]
# 进行模板匹配
img = img2.copy()
rv = cv2.matchTemplate(img, template, cv2.TM_SQDIFF)
minVal, maxVal, minLoc, maxLoc = cv2.minMaxLoc(rv)
# 标记匹配区域
topLeft = minLoc
bottomRight = (topLeft[0] + tw, topLeft[1] + th)
cv2.rectangle(img, topLeft, bottomRight, 255, 2)
# 在新的子图中显示模板图像
plt.subplot(131), plt.imshow(template, cmap='gray')
plt.title('模板'), plt.xticks([]), plt.yticks([])
# 显示原图像
plt.subplot(133), plt.imshow(img, cmap='gray')
plt.title('原图像展示匹配结果'), plt.xticks([]), plt.yticks([])
# 显示的是匹配结果的热力图
plt.subplot(132), plt.imshow(rv, cmap='gray')
plt.title('匹配结果热力图'), plt.xticks([]), plt.yticks([])
plt.show()

注意:
- 匹配结果热力图的灰度图像中,每个像素的值表示相应位置上模板与搜索图像的匹配程度。当使用
cv2.TM_SQDIFF作为匹配方法时,较低的像素值表示更好的匹配。因此,在匹配结果的灰度图中,较暗的区域表示模板与该位置的图像更相似。 th, tw = template.shape[::]:使用shape属性获取 NumPy 数组(在这种情况下是 OpenCV 图像)的形状是很常见的。对于一个图像,这个属性返回一个包含行数和列数的元组,通常以(行数, 列数)的形式表示。对于灰度图像(代码中的模板图像),行数代表图像的高度(Height),列数代表图像的宽度(Width)。
例:使用TM_CCOEFF进行匹配
使用cv2.matchTemplate()函数进行模板匹配。要求参数method的值设置为cv2.TM_CCOEFF,显示函数的返回结果及匹配结果。
import matplotlib
import matplotlib.pyplot as plt
import cv2
# 设置 Matplotlib 使用中文字符
matplotlib.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体
matplotlib.rcParams['axes.unicode_minus'] = False # 正确显示负号
# 读取图像和模板
img = cv2.imread('lena512g.bmp', 0)
template = cv2.imread('temp.bmp', 0)
tw, th = template.shape[::-1]
# 模板匹配
rv = cv2.matchTemplate(img, template, cv2.TM_CCOEFF)
minVal, maxVal, minLoc, maxLoc = cv2.minMaxLoc(rv)
topLeft = maxLoc
bottomRight = (topLeft[0] + tw, topLeft[1] + th)
cv2.rectangle(img, topLeft, bottomRight, 255, 2)
# 显示图像
plt.subplot(131), plt.imshow(template, cmap='gray')
plt.title('模板'), plt.xticks([]), plt.yticks([])
plt.subplot(133), plt.imshow(img, cmap='gray')
plt.title('原图像展示匹配结果'), plt.xticks([]), plt.yticks([])
plt.subplot(132), plt.imshow(rv, cmap='gray')
plt.title('匹配结果热力图'), plt.xticks([]), plt.yticks([])
plt.show()

- 当使用
cv2.TM_CCOEFF作为匹配方法时,较高的像素值表示更好的匹配。因此,在匹配结果的灰度图中,较亮的区域表示模板与该位置的图像更相似。















 322
322











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









