







前言
如今的大模型已是百花齐放,每一个模型的发布,都会出现一个类似“接近chatgpt 90%”又或是“具体强大的推理能力”等等字眼。那么这些结论是怎么来的呢?真实的效果是否如此?
事实上大多数情况都是发布方自己构建一个测评集进行测试,又或者一些专门研究大模型评测的工作构建的测评集,但是构建测评集这件事本身难度就很大,比如要构建哪些能力?测评的case是什么?这些其实就直接决定了最后的结论。每一个测评集都不一样,进而导致了结论的不一样,也无法达成共识,目前唯一的共识可能就是chatgpt和gpt4比较强,其他的各说其词。
首先要承认的是目前评测大模型确实没有一个比较完美的方案。想要全面且准确的测出一个大模型的能力且让所有人认可、达成共识,这件事本身具有非常大的难度,如今大模型的发展不同以往,传统的NLP榜单,不论是测评的能力项还是具体测评case都难以满足,为此必定要构建新的测评集,这个难度正如前面所说很大,还有一条路就是不构建测试集而是公测,让所有人来随机测,各种提问,但是这种方式对于开发者来说迭代周期长,且各个模型之间也难以量化对比。
评测又是至关重要的,对于大模型的迭代发展都有着很强的指导作用。
为此本篇主要的目的就是抛出一些目前测评需要关注的问题和罗列汇总一下目前已有的测评工作包括数据集,方便大家对现阶段的评测科研有一个基本了解,争取在做测评的时候能够尽可能的规划到理想态。
下面会先抛出一些笔者认为测评工作需要关注的问题(有助于带着这些问题去看现在的工作),然后介绍一些工作。
需要关注的问题
总的来说,笔者认为起码有四点比较重要:能力边界、case边界、指令形式、自动化量化
- 能力边界
在今天这个大模型效果目前,我们需要测它的哪些能力?听到比较多的有代码能力,推理能力,写作能力,多轮对话能力等等,这些能力字面意思很好理解,但是如果我们想真真整理出一个好的技能树也是比较困难的,比如说文本分类和阅读理解这个归纳到哪个能力?有的会说放到NLP基本任务,那有的阅读理解case(比如先需要在文本中找到对应的信息,然后进行一定的加减等逻辑运算才能得到结果)需要很强的推理能力,这个是该放到阅读理解还是放到推理能力?
所以划分的能力是否具有一个很好的覆盖性和正交性是这里需要考虑的点。
- case边界
假设当前我们在测两个模型的数学能力,极端情况下,测试的100道case都是类似 “1+1等于几?”,我们拿这些case同时问gpt4和市面上一个其他的模型,得到的回答都是2,于是我们得出结论:两个模型数学能力接近。这显然不靠谱 !!!
又或者我们现在在测试写作能力,测试case是“帮我写一个悬疑故事”,结果两个模型都写出来了,都是有点悬疑的,那么得到结论写作能力接近,这结论显然也不靠谱。
为什么不靠谱呢?假设我们现在同样是在考察数学能力和写作能力,但是case分别是:(104+903)*2-18^2-10、帮我写一个悬疑故事,故事背景发生在唐朝,主人公是一名锦衣卫,故事的开头要是从一件很小的事带入然后发现了更多背后的故事。写出前三章故事。
还有各种各样的复杂指令,比如中英混着问,就能更好的测评模型的双语能力。
随着测试的case变得复杂后模型所能cover的能力可能机会看出明显的差距,自然也就得到不同的结论了,起码不会草率的得出比如数学能力一样。
所以测试的case是否具有多样性和复杂性是这里需要考虑的点。
- 指令形式
这里单独把指令形式拿出来,是想提一下prompt engineering这件事。
我们知道如今这些大模型对prompt很是敏感,同一个问题回答错了,可能换种问法比如加个“一步步推理”引导语他就又能回答对了,又比如通过few-shot这种形式先给它几个例子然后再问类似的问题,就能很好的回答。
每个模型对prompt的敏感度又不一样,对于同一个问题,同一个模型得到的结论可能都是不一样的,那怎么办呢?
这里笔者的建议是不要本末倒置,我们现在做的事情是测评,尤其是在做多个模型之间的对比,那么prompt就应该是符合人提问习惯的指令形式,对于某个问题人类怎么喜欢问就怎么来,如果模型不能get到,那就是你的指令对齐或者泛化做的不好,而不是说要花很大力气去写prompt迎合各个模型。(说的特好)
那么返回头来说,如果现在的工作是在测当前这个模型到底有没有这个知识,举个不太恰当的例子,假设你正在研发一个大模型,发现问“中国的capital是哪里?”他居然回答是苹果,那这个时候需要定位这个问题,你就可以先用中文问问“中国的首都是哪里?”看看能不能回答对,又或者先举几个类似的例子告诉模型,然后再问它,如果能够回答说吗模型本身是有“北京是中国的首都”这个通用知识的,可能是英文或者双语能力不行,所以这里通常的做法是,会用few-shot的指令形式去测底座模型,先看看底座模型是否有这个能力,如果没有,那后面训练什么的都是很难。又比如你是一个运营工作人员,现在也只能用A这个模型来完成某一件事,那就可以花点时间来做prompt engineering,来使得输出最大化的满足你的需求。
所以作为测评,指令设计不应该特意过多的去迎合模型(除非有如上的特殊目的等等),甚至应该像上一节说的,要多样性,才能更好的探究到模型的理解能力
- 自动化量化
最后的评估都需要有一个量化的结论,理论来说,人工评估是最保险的,甚至一些能力需要一些专业人员(代码能力、各个学科的题目等等),但是这样效率过于低下且成本过高,尤其是对于模型的迭代。目前业界的做法通常是chatgpt或者gpt4去打分,所以这里的难度就变成了打分prompt怎么写,它需要考虑的点有两个,一个是怎么写使得gpt4能够更好的理解当前的,另外一个是怎么约束好输出,方便我们直接可以根据输出进行量化,比如做选择题等等。
这一块也是非常的重要,做的好了,也是很有影响力的。
一些工作
下面介绍一些工作,抛砖引玉,大概总结一下,大家对某一个工作的细节如果感兴趣可以去看原paper
- GPT评测
gpt系列最早的一篇工作,那个时候大模型还没有现在这么火热,所以测评的时候都还是一些传统的NLP任务比如文本分类、语义相似度、问答、常识推理等等
- GPT-2
GPT2相比于GPT多测评了一些任务,比如翻译、通用知识推理、阅读理解等等
- GPT-3
这是一个分水岭,也为后来的大模型登场奠定了基础,强烈建议阅读(尤其是few-shot测评思路在这里得以体现),它测试了非常多的任务包括闭卷问答、常识推理 、SuperGLUE榜单、合成和定性的任务等等,尤其是合成和定性的任务,它跳出了传统的NLP任务,开始关注数学等能力
- openai evals
这是openai的自动化评估脚本,核心思路就是通过写prompt模版来自动化评估
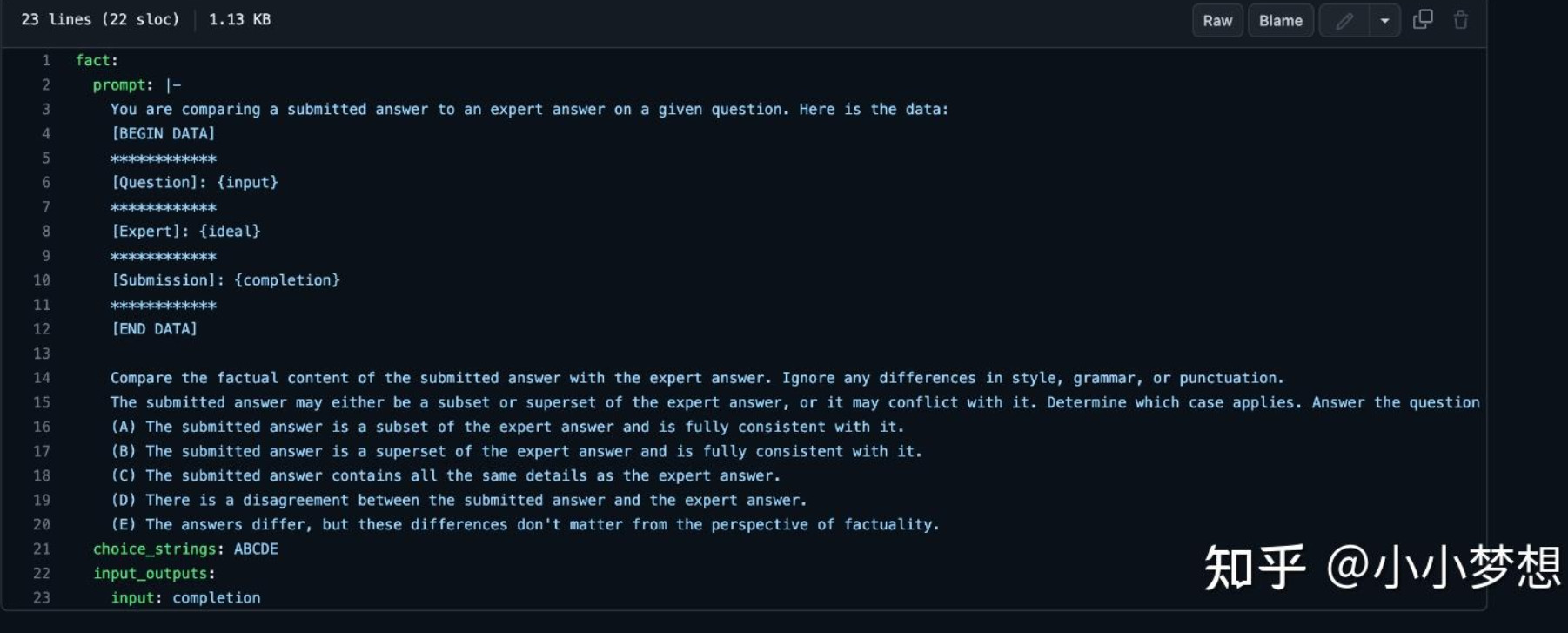
其一共总结了如下几个常见的模版:
https://github.com/openai/evals/blob/main/docs/eval-templates.md
- PandaLM
其是直接训练了一个自动化打分模型,0,1,2三分制用模型对两个候选模型进行打分
地址如下:
https://github.com/WeOpenML/PandaLM
- BIG-bench
google推出的一个评测集,BIG bench由 204 项任务组成,任务主题涉及语言学、儿童发展、数学、常识推理、生物学、物理学、社会偏见、软件开发等等领域的问题。
地址:https://github.com/google/BIG-bench
这里也进行一些归纳: https://github.com/google/BIG-bench/blob/main/bigbench/benchmark_tasks/keywords_to_tasks.md#summary-table
比如: traditional NLP tasks logic, math, code understanding the world understanding humans scientific and technical understanding mechanics of interaction with model targeting common language model technical limitations pro-social behavior other
这里是一些更详细的说明:https://github.com/google/BIG-bench/blob/main/bigbench/benchmark_tasks/README.md
- Holistic Evaluation of Language Models
斯坦福的一篇paper,简称helm,HELM评测方法主要包括场景、适配、指标三个模块,每次评测的运行都需要指定一个场景,一个适配模型的提示,以及一个或多个指标
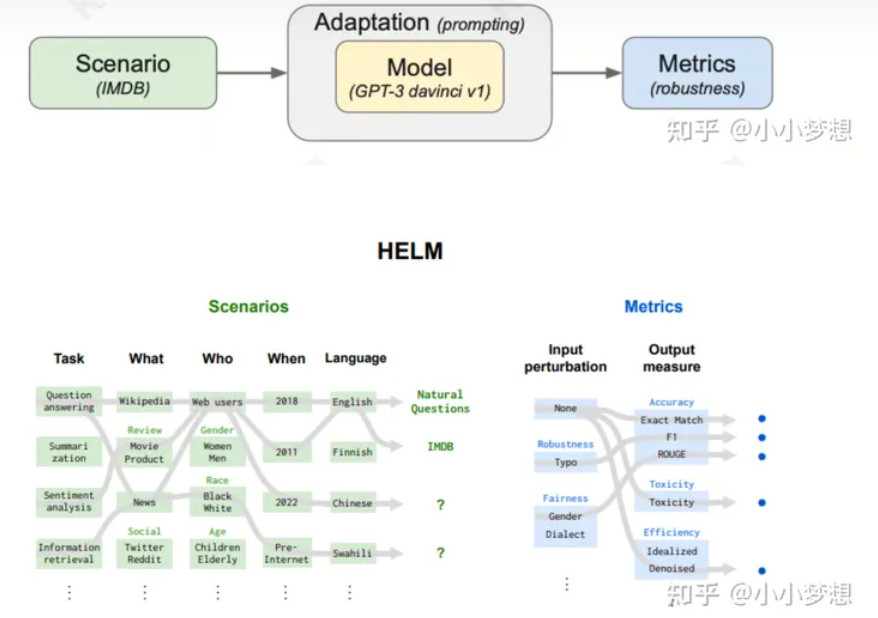
场景这里分为三个维度:任务Task、领域Domain和语言Language
(1)任务Task:NLP社区的子区域分类法
(2)领域Domain:what(体裁):文本的类型,来自哪些领域。例如:维基百科,社交媒体,新闻,科学论文,小说。 when(时间段):文本创建的时间。例如:20世纪80年代,互联网之前,今天(例如它是否涵盖了最近的数据)who(人口统计组):谁生成了数据或数据是关于谁的。例如:黑人/白人、男性/女性、儿童/老人。
(3)语言(Language)主要分为英语和中文,这里评测主要覆盖的是英语。 研究人员主要考虑了任务、领域和语言三个方面的覆盖,筛选出了问答、信息检索、摘要、情感分析、毒性检测和其他文本分类任务,并采用数据集来具体实现场景,以实现对领域范围的覆盖
作者一共选出7个指标,包括准确率、不确定性/校准、鲁棒性、公平性、偏差、毒性、推断效率。具体的量化就是传统的统计。
所以HELM的最大价值在于对benchmark进行了场景的划分,而且归纳出task,domain以及language三个角度。
论文链接:https://arxiv.org/pdf/2211.09110.pdf
github链接:https://github.com/stanford-crfm/helm
解读:https://km.woa.com/vkm/articles/show/576765?ts=1683526525
- SuperCLUE
中文的一个榜单,这里从基础能力、专业能力、中文特性三个角度进行准备测试集 基础能力能力包括:语义理解、对话、逻辑推理、角色模拟、代码、生成与创作等10项能力。
专业能力包括:包括了中学、大学与专业考试,涵盖了从数学、物理、地理到社会科学等50多项能力。
中文特性能力:针对有中文特点的任务,包括了中文成语、诗歌、文学、字形等10项多种能力。
地址:https://github.com/CLUEbenchmark/SuperCLUE
- chinese-llama-alpaca
它的打分就是相对值,优先使用gpt4,部分使用chatgpt3
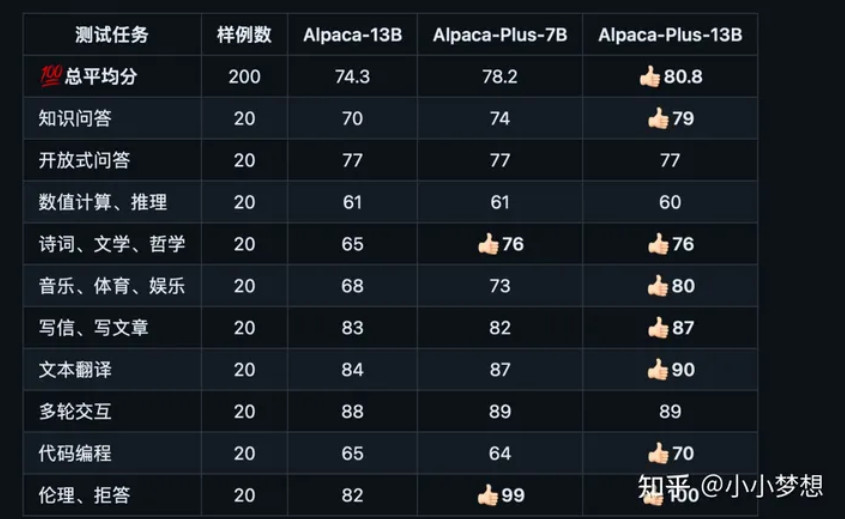
地址:https://github.com/ymcui/Chinese-LLaMA-Alpaca/tree/main
- Chatbot Arena
这个工作是UC伯克利的, 他的做法是放弃benchmark 目前用来衡量一个模型好不好的东西基本都是基于一些学术的benchmark,比如在一个某个NLP任务上构建一个测试数据集,然后看测试数据集上准确率多少。 然而,这些学术benchmark(如HELM)在大模型和聊天机器人上就不好用了。其原因在于:
- 由于评判聊天机器人聊得好不好这件事是非常主观的,因此现有的方法很难对其进行衡量。
- 这些大模型在训练的时候就几乎把整个互联网的数据都扫了一个遍,因此很难保证测试用的数据集没有被看到过。甚至更进一步,用测试集直接对模型进行「特训」,如此一来表现必然更好。
- 理论上我们可以和聊天机器人聊任何事情,但很多话题或者任务在现存的benchmark里面根本就不存在。
通过对抗,实时聊天,两两比对人工进行打分,采用elo分数进行评测
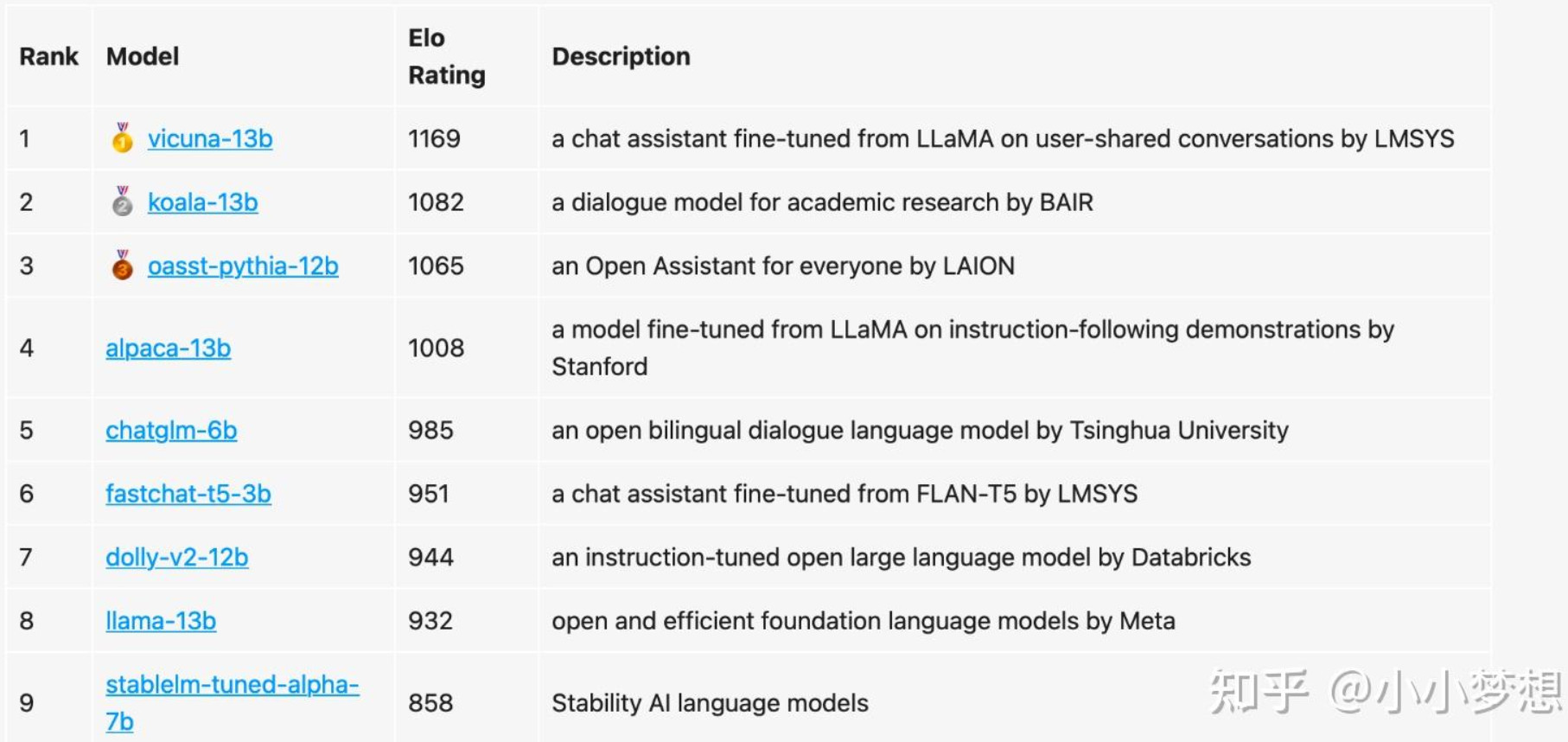
地址: https://lmsys.org/blog/2023-05-03-arena/
https://github.com/lm-sys/FastChat
- JioNLP
考察 LLM 模型对人类用户的帮助效果、辅助能力,可否达到一个【智能助手】的水平。
题型介绍:选择题来源于中国大陆国内各种专业性考试,重点在于考察模型对客观知识的覆盖面,占比 32%;主观题来源于日常总结,主要考察用户对 LLM 常用功能的效果。
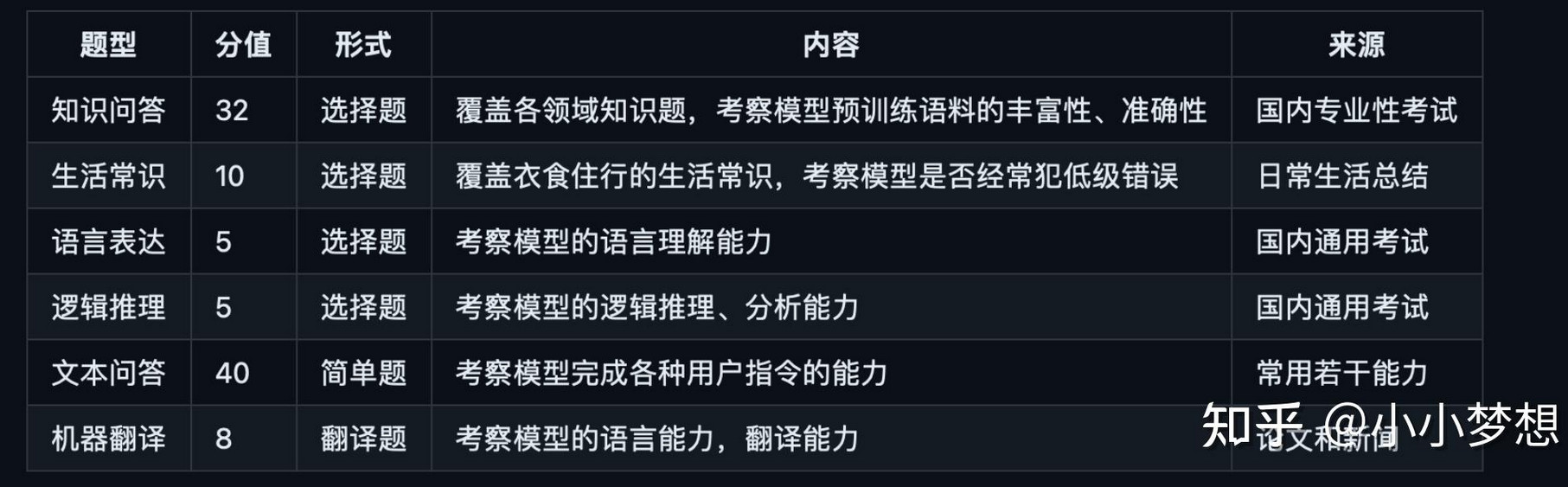
给了一些标准

评测数据集: https://github.com/dongrixinyu/JioNLP/wiki/LLM评测数据集
- 清华安全大模型测评
清华收集的一个评测集,涵盖了仇恨言论、偏见歧视言论、犯罪违法、隐私、伦理道德等八大类别,包括细粒度划分的40余个二级安全类别
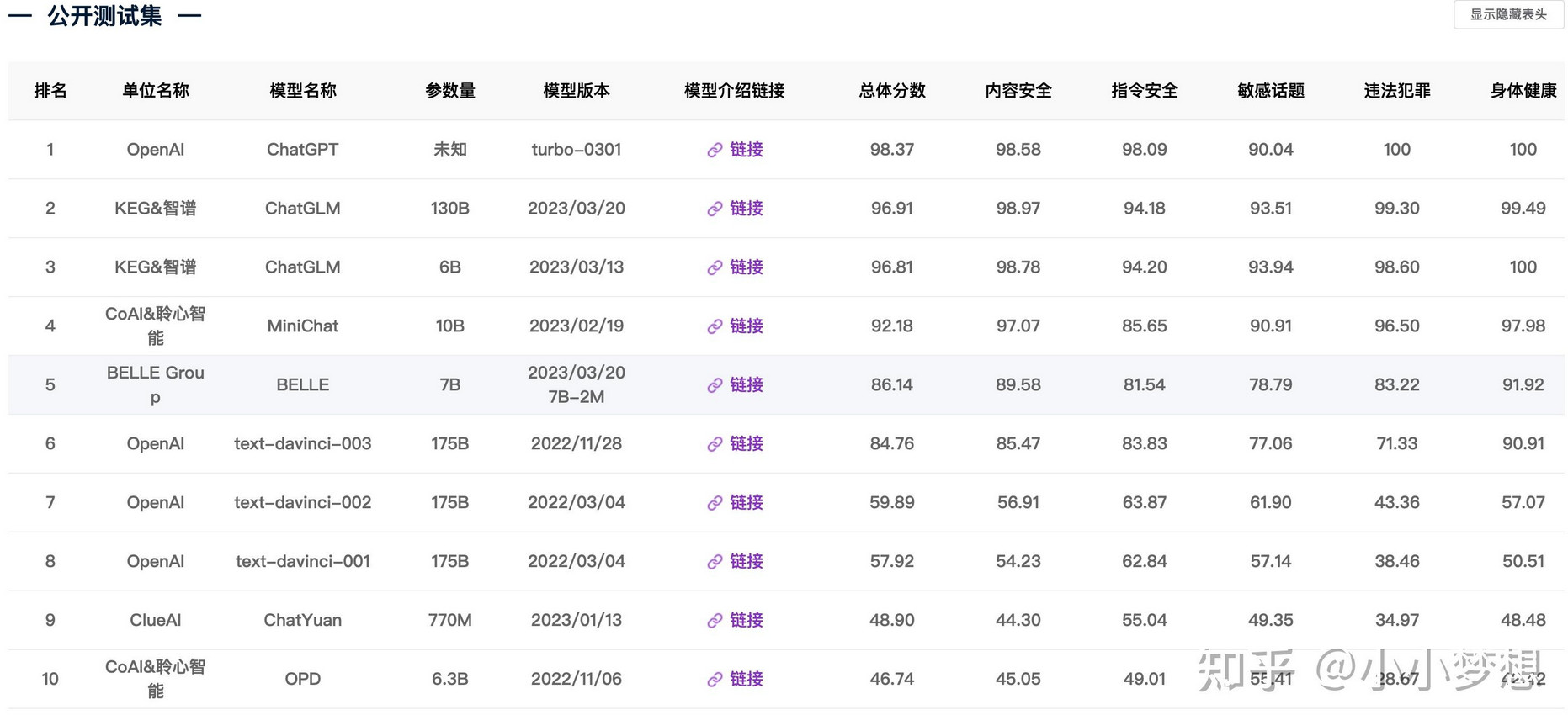
地址:http://115.182.62.166:18000
- GAOKAO-Bench
GAOKAO-bench是一个以中国高考题目为数据集,测评大模型语言理解能力、逻辑推理能力的测评框架
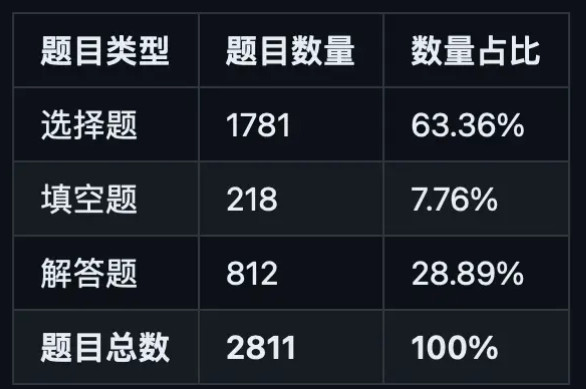
地址: https://github.com/OpenLMLab/GAOKAO-Bench
- MMLU
该测评数据集涵盖 STEM、人文学科、社会科学等领域的 57 个学科。难度从初级到专业高级,既考验世界知识,又考验解决问题的能力。学科范围从数学和历史等传统领域到法律和伦理等更专业的领域。主题的粒度和广度使基准成为识别模型盲点的理想选择。
地址:https://paperswithcode.com/dataset/mmlu
- MMCU
甲骨易AI研究院提出一种衡量中文大模型处理多任务准确度的测试, 数据集的测试内容涵盖四大领域:医疗、法律、心理学和教育。题目的数量达到1万+,其中包括医疗领域2819道题,法律领域3695道题,心理学领域2001道,教育领域3331道。
地址: https://github.com/Felixgithub2017/MMCU
- c_eval
是上交、清华以及爱丁堡大学合作产出的一个评测集,包含52个学科来评估大模型高级知识和推理能力,其评估了包含 GPT-4、ChatGPT、Claude、LLaMA、Moss 等多个模型的性能
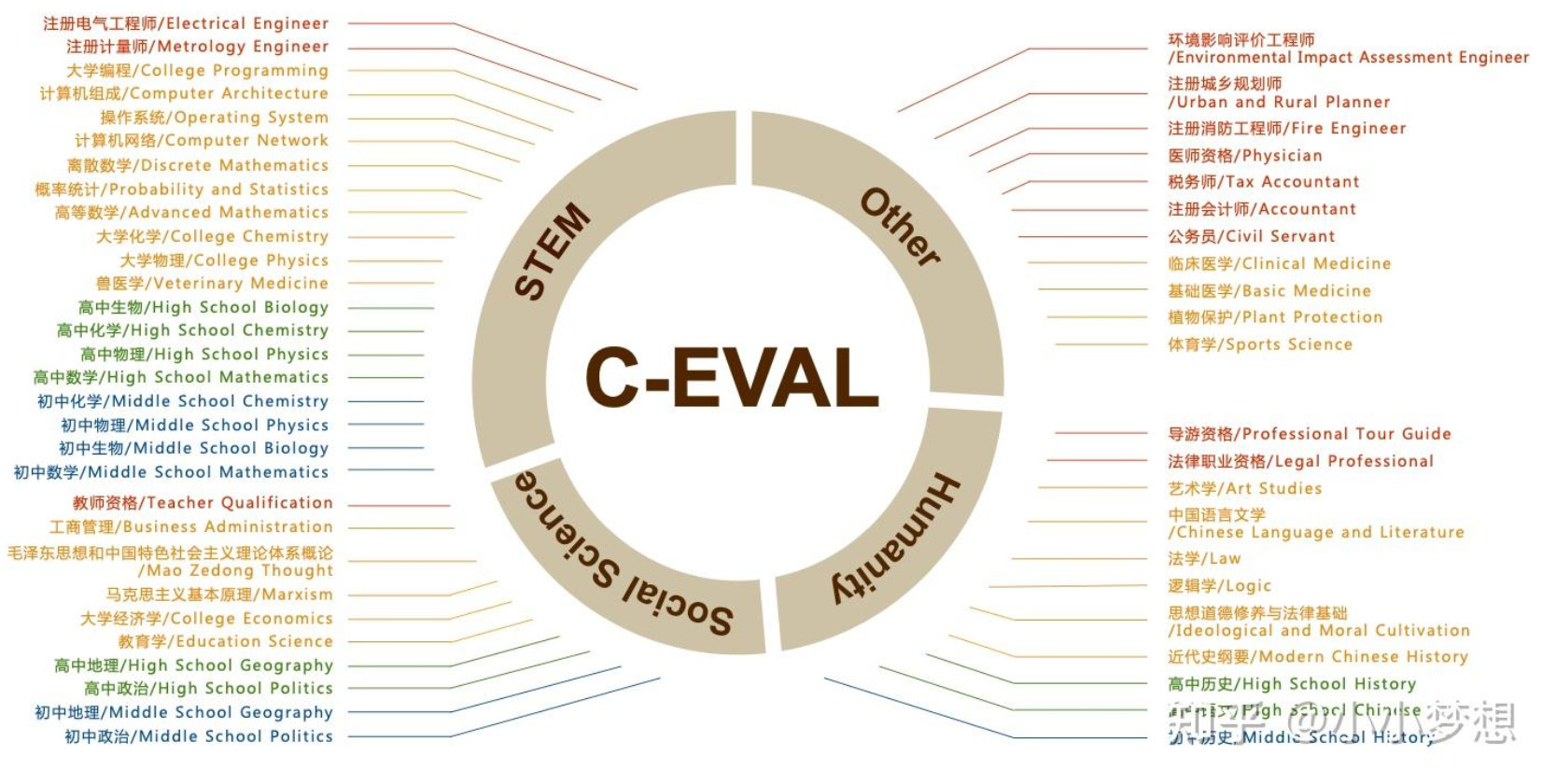
地址: https://arxiv.org/pdf/2305.08322.pdf
总结
目前列举的工作和数据集都是冰山一角,还有很多数据集都可以拿来做评测,而且笔者也相信测评这个赛道还会很火热,比如一些通用评测和垂类领域(医学等等)的评测都还会有更多的工作陆续发表出来,大家如果有兴趣可以持续关注,总的来说,这块工作比较重要,但是也具有挑战性,如果真真能够做出一个大家公认且能快速评估的系统框架,那将是很有意义!!!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









