







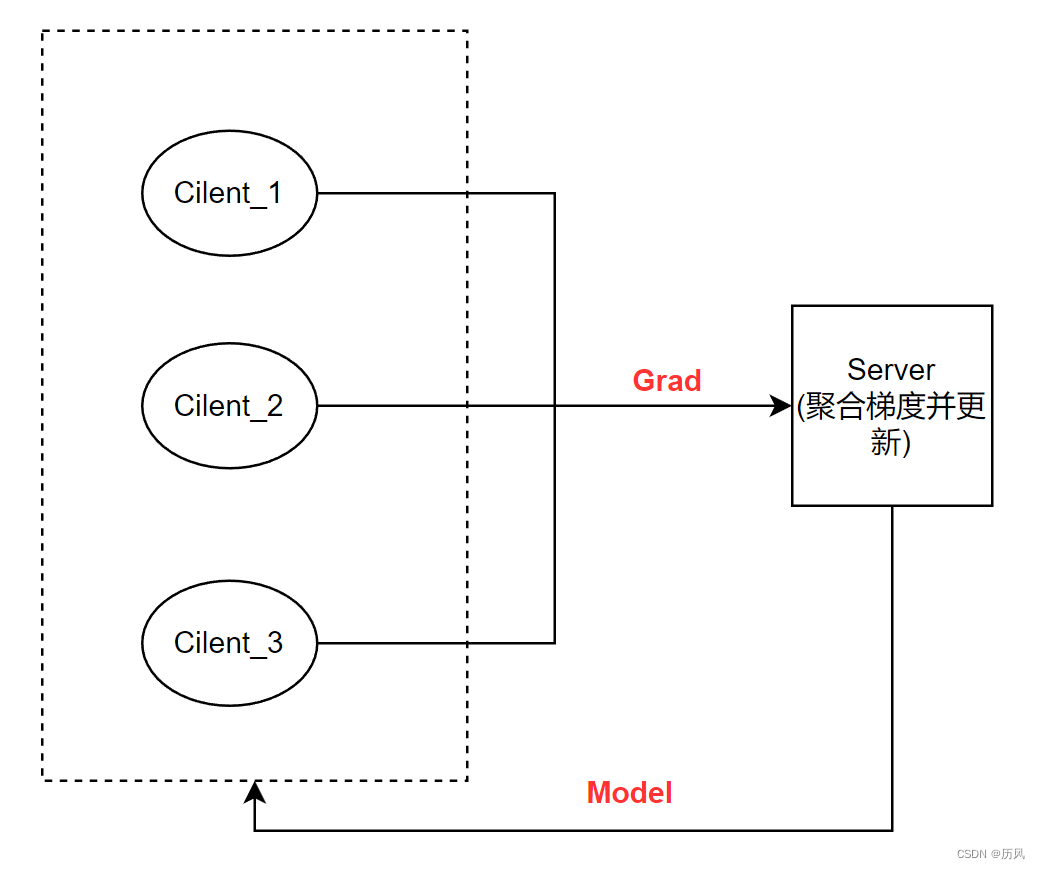
联邦学习系统提出是为了在数据不聚合的情况下实现分布式的机器学习,每个客户端持有自己的数据,向中心服务器请求下载中心模型,向中心服务器发送梯度或者模型,中心服务器进行聚合。
尽管理论上很简单,但是需要发送大量的梯度,单机实现多个客户端,也有数据划分问题,显存问题,同步和异步的问题。
起初的设想
我设想存在一个数据池,数据池自己实现了数据的划分,只需要按照客户端的请求分配一个Batch的数据。
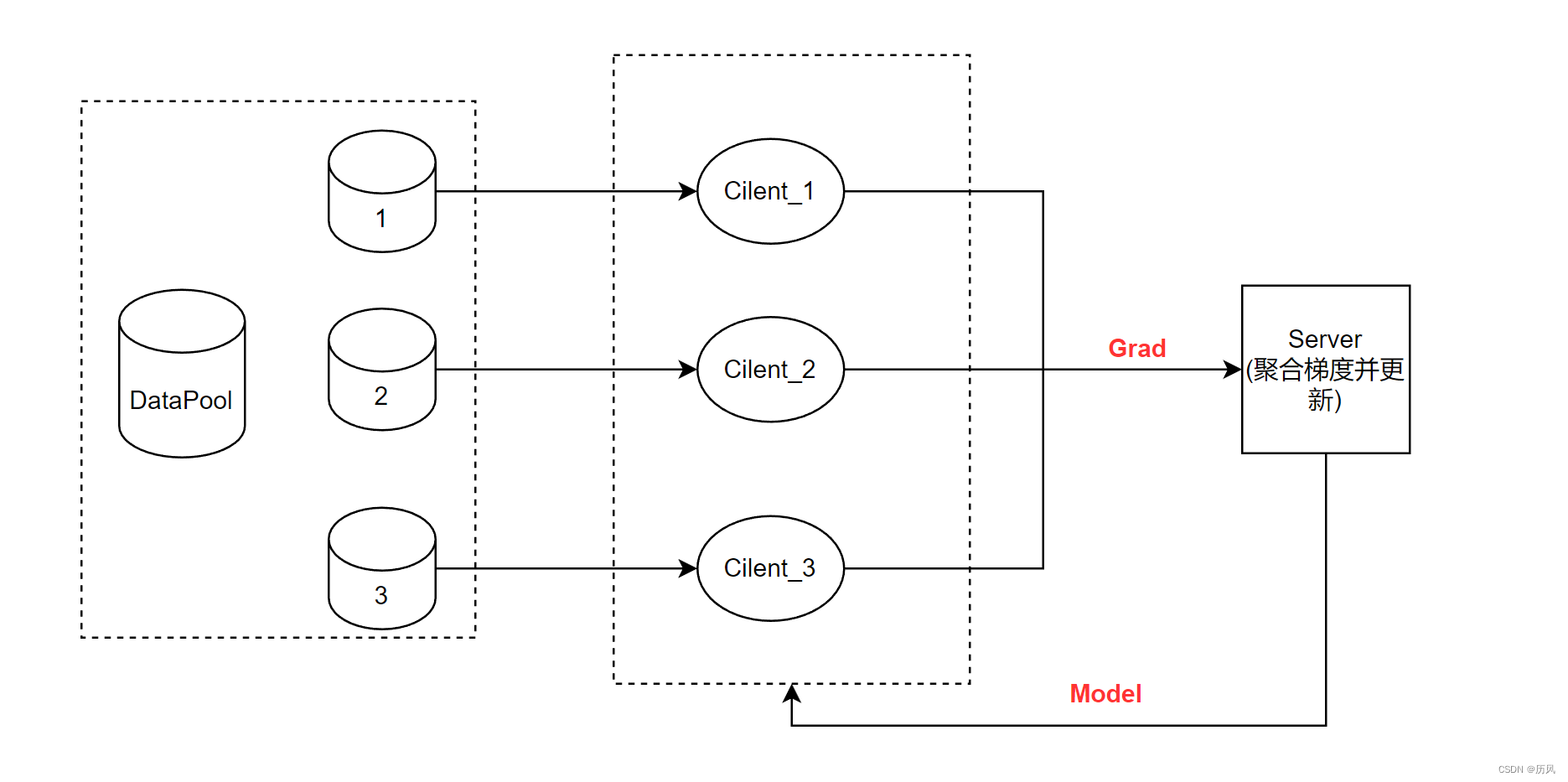
全程采用TCP协议进行传输,基于Socket编程TCP传输结构如下:
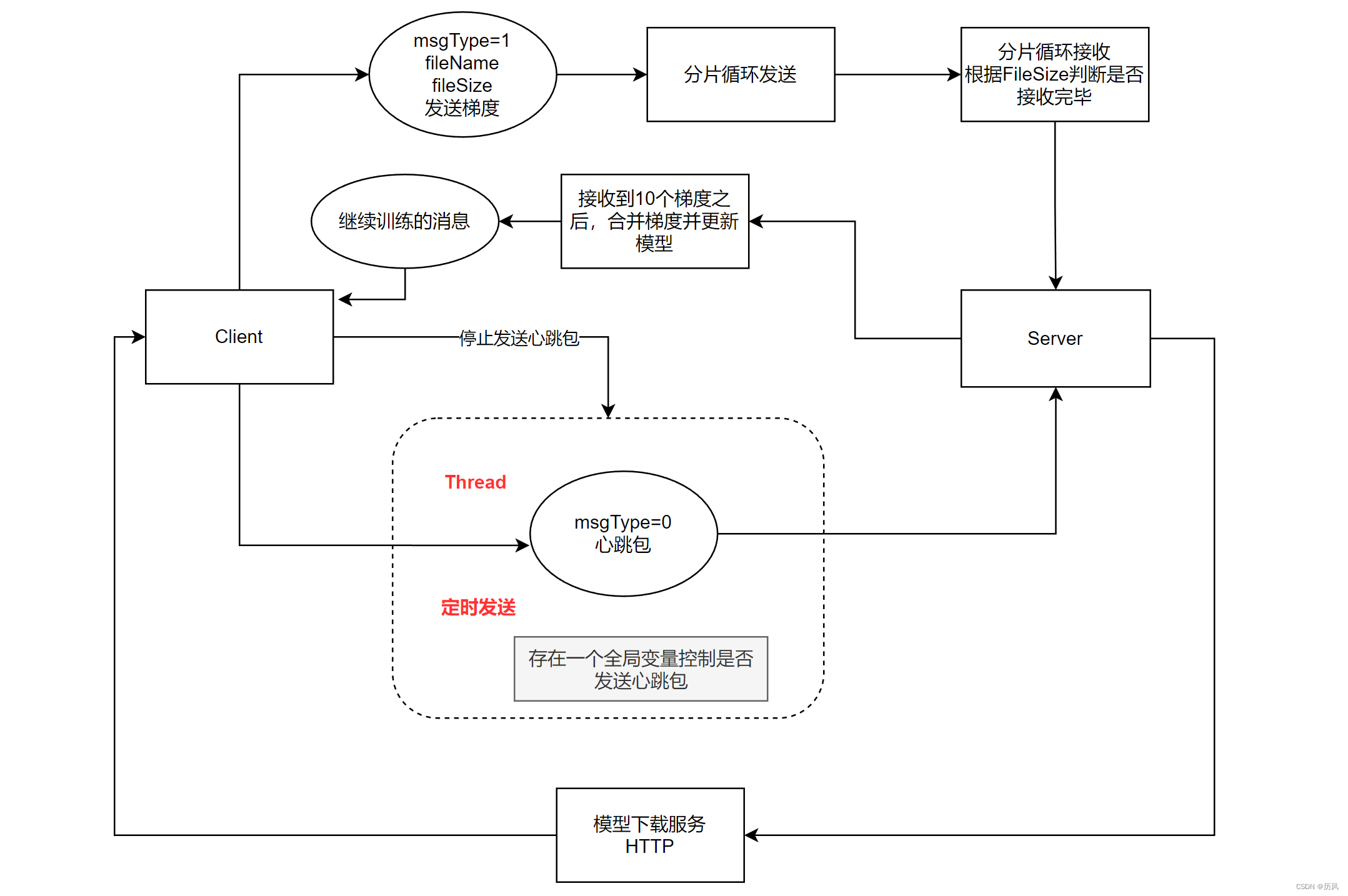
花了一天实现之后,发现训练的速度很慢,首先是发送文件需要先写到硬盘,IO限制了速度,另外是TCP需要延时,否则包会卡着发不出去。
模拟替代法
这个系统重要的是联邦学习,通讯是不重要的,所以思考单一程序的替代方法。
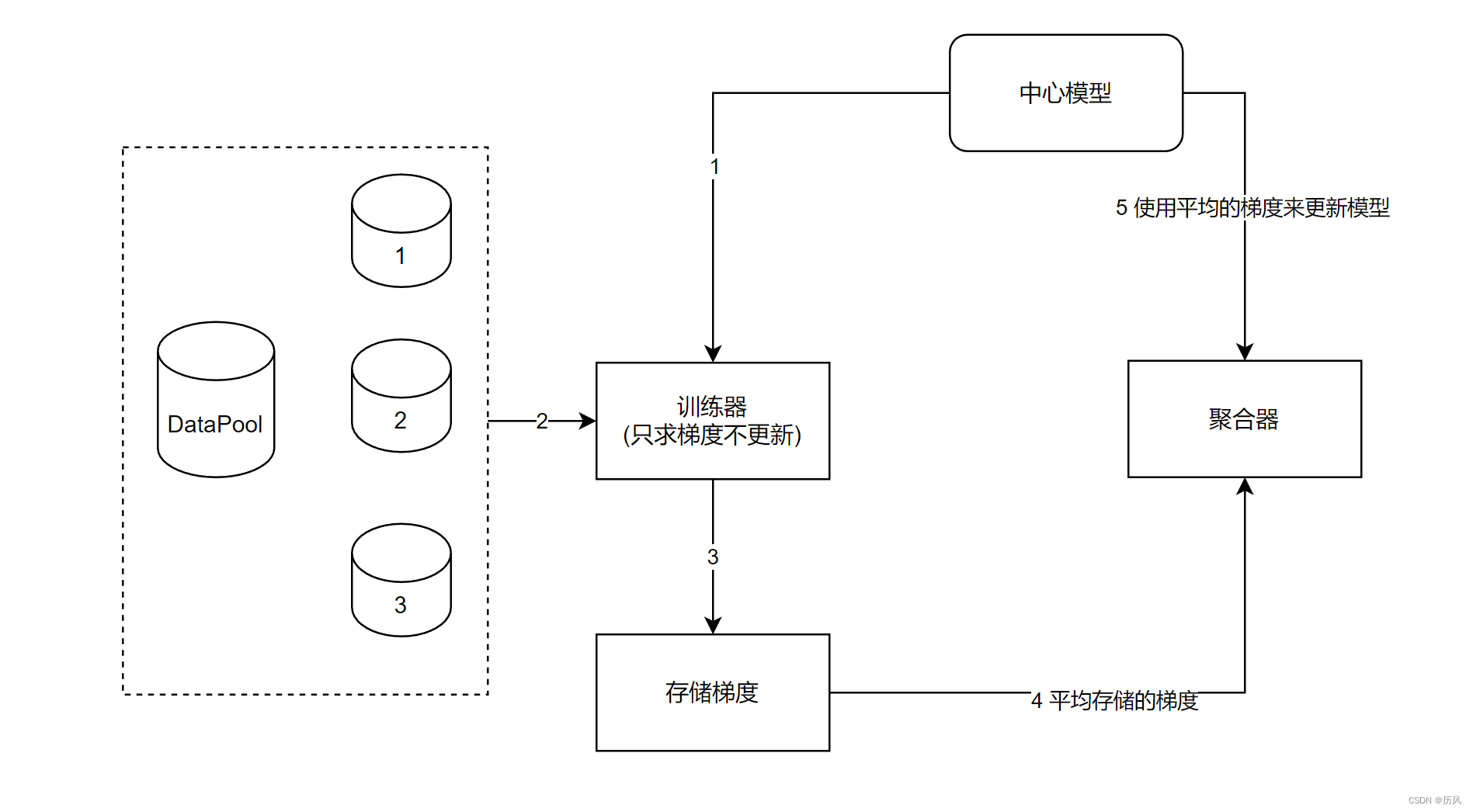
将数据打乱然后切分为N份,训练器依次使用中心模型和指定的数据求梯度并存储,存下,每一份数据都求了之后,将存储的梯度平均给聚合器更新中心模型,然后访问下一轮数据,重复。
import tensorflow as tf
import requests
from sklearn.model_selection import KFold
import numpy as np
import os
import copy
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "3"
# gpus = tf.config.experimental.list_physical_devices('GPU')
# tf.config.experimental.set_memory_growth(gpus[0], True)
minst=tf.keras.datasets.mnist
(x_train,y_train),(x_test,y_test)=minst.load_data()
np.random.seed(200)
np.random.shuffle(x_train)
np.random.seed(200)
np.random.shuffle(y_train)
centerModel=tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=[28,28]),
tf.keras.layers.Dense(128,activation='relu'),
tf.keras.layers.Dense(1280,activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10,activation='softmax')
])
model=centerModel
client_num=100
batch_size=32
class_num=10
max_epoch=100
each_client_data_num=int(x_train.shape[0]/client_num)
#初始化
ans=0
epoch=0
optimizer=tf.keras.optimizers.Adam(learning_rate=0.0001)
cce=tf.keras.losses.CategoricalCrossentropy()
while True:
grad_list=[]
for index in range(client_num):
start= int(index* x_train.shape[0]/client_num)
start+=ans
x=x_train[start:start+batch_size]
y=y_train[start:start+batch_size]
with tf.GradientTape() as tape:
y_pre=model(x)
y=tf.keras.utils.to_categorical(y,class_num)
losses=cce(y,y_pre)
grads = tape.gradient(losses,model.trainable_weights)
grad_list.append(grads)
## 中心聚合,更新中心模型
grads=grad_list[0]
for index in range(1,client_num):
for i in range(len(grads)):
grads[i]+=grad_list[index][i]
for i in range(len(grads)):
grads[i]/=client_num
optimizer.apply_gradients(zip(grads,model.trainable_weights))
#-----------
ans+=batch_size
if ans>=each_client_data_num:
ans=0
# 检验
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.evaluate(x_test,y_test)
# -------
epoch+=1
if epoch>max_epoch:
break














 845
845











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









