







今天来看一下一些爬虫过程的小技巧或者说是一些注意或者是坑的地方,因为博主也是刚入门,所以也是把一些学到的对象进行分享,那么第一个坑:在浏览网页的时候我们经常会看到这样的东西:
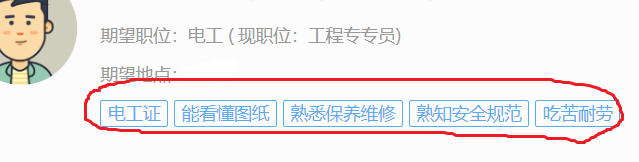
也就是所谓的多标签,我们再来看看它对应的HTML结构,打开F12(如果你按了F12什么也没发生,可以去看看博主第一篇文章)
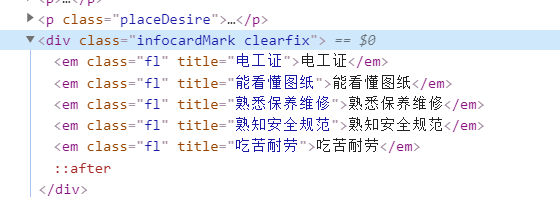
可以发现,这些信息都是嵌套于某一HTML下的,图中信息是位于 <div class = "infocardMark clearfix"></div>标签中,那么我们怎么去获取这些信息呢,这时我们可以在获取数据的时候只分析到 div.infocardMark.clearfix 这一层(用浏览器的 Copy selector方法可以获取),对了这里说一下,博主用的是Google浏览器,当然,你们也可以使用火狐浏览器什么的,都有对应的F12界面,然后使用stripped_strings方法,其说明是这样的:
stripped_strings:用来获取目标路径下所有的子孙非标签字符串,会自动去掉空白字符串,返回的是一个生成器
然后针对该案例具体的使用可以是这样的:
date = soup.select('div.infocardMark.clearfix')
for info in zip(date):
print(list(info.stripped_strings))
如果遇到:AttributeError: 'tuple' object has no attribute 'stripped_strings',需要先分析元组的结构,然后取到具体的元素上在使用
stripped_strings方法,比如上述代码中发生所说的错误就可以尝试用list(info[0].stripped_strings)来一试,当然这是在分析了错误和数据的基础上进行的代码修改。
那么第二个要说的问题是,有时候我们会因为种种原因,比如:网页的数据是通过js控制传递的,那么这个时候要去分析js是相对麻烦的,那么我们就可以尝试下谷歌浏览器的黑科技(p≧w≦q),在F12之后我们可以模拟手机的方式进行网页查看,因为适配的原因,有时候采取手机页面的方式进行信息获取是一种相对简单的方法,具体怎么做呢?这里首先要简单讲一下,发起请求的一些东西(其实博主也不是很懂,但会粗暴的讲一下),在我们发起服务请求的时候处理URL之外,其实还应该在加上一些报文头(请求头)的信息,可是我们之前都没加上报文头都能正常访问网络啊,具体的你们可以自己下去查一下资料,这里简单说一下报文头应该如何去查看,并且应该怎么用。首先,肯定得F12了:然后切换到Network,选择XHR,选择第一个请求项,点击Headers,然后传送信息的报文头就在request Headers中,额...好吧就是下面这些东西:

那么知道了这些信息有什么用呢,嘿嘿,两个方面,比如说你的登录信息就可以靠这里Request Headers中的信息进行获取,然后放到链接中,这样你的请求就是具有身份信息的,嗯....怎么说呢,就是说我们之前的请求都只是以游客的形式进行的,那如果我们想以自己已经登录的状态去发起请求的话,就可以从Request Headers中去找寻蛛丝马迹,好吧,如果其实重要的是Headers中的Cookie(具体资料下去查询),它就是记录我们身份的对象..........好了,多的不说还是说会正题吧,我们该怎么去模仿手机登录呢,这时候我就需要去点击那个手机的图标,也就是这个:

点击完毕,就可以切换不同的手机型号进行访问了,是不是很兴奋(p≧w≦q)(好吧其实并不兴奋.....):

有了这些准备,这时候我们再去F12中重新查看request headers中的信息,
User-Agent:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36
User-Agent:
Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1
第一条是正常用Windows访问时的信息,第二条是模拟Iphone访问时的信息,可以放心发生了改变,有了这些信息我们就可以如下去访问网址:
在进行request请求前我们先定义header,然后在请求时指定headers即可:
header = {
'User-Agent':'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1'
}
wb_data = requests.get(url,headers = header )
如果需要加入登录信息,需要先进行一次登录,然后在去查看Headers中的Cookie,在header中指定Cookie对应的信息即可。















 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









