







前言:
百度一下“C++读取BMP位图”的文章一大堆,想省事的话大可以复制粘贴一份就行了。
我就是贱啊,非要自己写一份,不管实用性如何,兼容性如何,就是想要拥有自己的一份独一无二的代码,即使只有核心功能。实用性和兼容性还有鲁棒性这种东西可以慢慢来嘛···········其实早在大一用MFC写绘图程序时就已经接触过BMP的读写问题了,当时由于不知道有CImage这个类,所以傻傻地啃了网上的代码。现在已经很久不用MFC了(大概忘得差不多),但是BMP的读写我却不想忘记,大概是dream以及这学期要上“数字图像处理”课的缘故吧。于是近来几天重拾朝花
。
自己给自己随便记录记录好了··········
BMP文件结构:
传说中,BMP位图有1、4、8、16、24、32位的,前面几种我一般不怎么用,所以只考虑了24和32位(其实是一想到调色板就觉得难受>_<)。不管有多少位,要读取BMP位图首先要了解其数据的组织方式。
BMP位图的结构可以这样表示:

从文件开头到文件末尾,一次保存着 BITMAPFILEHEADER(位图文件头)、BITMAPINFOHEADER(位图信息头)、RGBQUADS调色板、像素数据。其中,调色板数据在24、32位的BMP位图中是没有的,因为调色板的作用主要是为了节省图像保存空间而存在的,24位以上的像素能表示的颜色已经够多了,调色板的存在已经失去了意义。下面分别记录下前面两个结构。
位图文件头:
微软的位图文件头的声明如下:
#pragma pack(push,2)
typedef struct tagBITMAPFILEHEADER {
WORD bfType;
DWORD bfSize;
WORD bfReserved1;
WORD bfReserved2;
DWORD bfOffBits;
} BITMAPFILEHEADER,*LPBITMAPFILEHEADER,*PBITMAPFILEHEADER;
#pragma pack(pop)
bfType:文件的类型标识,必须是“BM”,即十六进制的0x4D42,不能是其他。
bfSize:文件的大小,包括当前结构体的大小。
bfReserved1、
bfReserved2:都是保留字,不用管,填0就是了。
bfOffBits:从文件开始处到实际图像数据的偏移量,单位为字节。
位图的信息头:
位图的信息头声明如下:
typedef struct tagBITMAPINFOHEADER{
DWORD biSize;
LONG biWidth;
LONG biHeight;
WORD biPlanes;
WORD biBitCount;
DWORD biCompression;
DWORD biSizeImage;
LONG biXPelsPerMeter;
LONG biYPelsPerMeter;
DWORD biClrUsed;
DWORD biClrImportant;
} BITMAPINFOHEADER,*LPBITMAPINFOHEADER,*PBITMAPINFOHEADER;
biSize:当前结构体的大小。仅仅是 sizeof(
BITMAPINFOHEADER
)。
biWidth、biHeight:图像的长和宽,单位为像素。
biPlanes:微软说
The number of planes for the target device. This value must be set to 1.
还能有什么疑问呢·········
bBitCount:每个像素需要的位数。可以是
1、2、4、8、16、24、32之中的一个。
对于我只需要24和32就好了啦。
biCompression:图像的压缩方式,一般是 BI_RGB 即不压缩,实际上这个数字被 #define 成 0。还可以是其他的 BI_RLE8、BI_RLE4,这些都是压缩的格式,我暂时就不考虑了。
biSizeImage:图像数据的大小,不包括两个头信息和调色板大小。这里要注意一个字节对齐问题。微软要求BMP图像每行的像素所需字节数必须是4的倍数,不够的填补空字节。所以,对于真彩色的位图来说,像素数据大小应该为:(biWidth*biBitCount/8+3)/4*4*biHeight。太多乘除法?优化一下,(
(((biWidth*biBitCount>>3)+3)>>2)<<2)*biHeight。还可以:
int bytePerRow = biWidth*biBitCount>>3;
if(bytePerRow & 0x11) bytePerRow = (bytePerRow & 0xFFFFFFFC)+4;
biSizeImage = bytePerRow * biHeight;
乱七八糟的,效率应该都差不多哈。传说当压缩类型是BI_RGB时,该值可能为0。我亲测该值确实变成0了,我之前没考虑,搞得一大堆BUG啊。
biXPelsPerMeter、
biYPelsPerMeter:设备的水平、垂直分辨率。一般都填0就得了。
biClrUsed:已经使用的颜色数,要是24位以上的填0就行了。
biClrImportant:重要的颜色数,
要是24位以上也是填0就行了。
调色板:
接下来就是调色板信息了,如果biBitCount = 1或4或8时,调色板就分别为2、16、256项。对于16、24、32位的位图请直接忽略调色板信息。这里记录一下调色板数组项的声明好了:
typedef struct tagRGBQUAD {
BYTE rgbBlue; //蓝色分量
BYTE rgbGreen; //绿色分量
BYTE rgbRed; //红色分量
BYTE rgbReserved; //保留位
} RGBQUAD,*LPRGBQUAD;
奇葩的像素组织:
差点忘了记录一个很重要的信息。微软的BMP位图的颜色分量存放顺序是BGR或BGRA(假如有alpha分量的话),由上面的结构体就可以看出,或者花点心思用WinHex文本编辑器查看其二进制的十六进制表示也可以看出,不如干脆自个实现程序后一眼就能看出,哈哈。而且,BMP像素数据的存储顺序也挺奇葩的,紧接信息头或者调色板的竟然是最后一行像素,然后是倒数第二行、倒数第三行··········最后到第一行。所以程序实现后,也许会发现图像显示是倒过来的,这时千万不要惊呆,自己有意识地将行像素调整一下就行了哈。前面说到的颜色分量顺序也自个调整调整就行了哈。
BMP读取与保存:
明白了BMP位图的数据结构后,接下来要做的就只是打开文件、读取数据到适当位置就行了,不管你用C还是C++还是别的··········下面是最简单的不考虑鲁棒性的C渣渣代码:
int LDBitmap::Load(const std::string& strFileName)
{
std::ifstream inFile(strFileName.c_str());
inFile.read((char*)&m_BFH,sizeof(m_BFH));
inFile.read((char*)&m_BIH,sizeof(m_BIH));
m_bytePerRow = (((m_BIH.biWidth * m_BIH.biBitCount>>3) + 3)>>2)<<2; //保证是4的倍数
if(m_BIH.biCompression == 0)
{
/*若压缩类型为BI_RGB即0,则该项可能为0,此处手动计算无压缩大小。*/
m_BIH.biSizeImage = m_bytePerRow*m_BIH.biHeight;
}
LD_SAFE_DELETE_ARRAY(m_pData);
m_pData = new GLubyte[m_BIH.biSizeImage];
inFile.read((char*)&m_pData[0],m_BIH.biSizeImage); //大家可以自己尝试逐行读取上下翻转图像
ChangeFormat(BF_RGB_OR_RGBA); //调整红蓝分量的位置,因为我在OpenGL里用GL_RGB方式显示
//大家可以省略这步,自己弄点别的有意思的东西,即图像处理了哈
inFile.close();
return LD_OK;
}
其中 strFileName 是位图的文件名,m_BFH是位图文件头结构,m_BIH是位图信息头结构,m_pData指向像素缓冲。下面是木有鲁棒性的保存代码:
int LDBitmap::SaveAs(const std::string strFileName)
{
std::ofstream outFile(strFileName.c_str());
/*确保蓝色分量在前,红色分量在后*/
ChangeFormat(BF_BGR_OR_BGRA);
outFile.write((const char*)&m_BFH,sizeof(m_BFH));
outFile.write((const char*)&m_BIH,sizeof(m_BIH));
outFile.write((char*)&m_pData[0],m_BIH.biSizeImage);
outFile.close();
return LD_OK;
}
关于字节对齐引发的问题:
最后还想记录一个让我程序崩溃N次的bug。注意在位图文件头的声明前后有点奇怪的东西混了进来:
#pragma pack(push,2)
//省略中间部分
#pragma pack(pop)
这个是告诉编译器在编译中间部分代码时将字节对齐数改为2的意思。仔细点你会发现,sizeof(
BITMAPFILEHEADER
)竟然等于14,而自己写了一个拥有同样数据结构的结构体 sizeof() 的结果却是16。因为我就是用自己写的结构体来存放位图的两个头信息,所以才引发了一些奇奇怪怪的bug(我是不是好贱— —!)。为什么是这样呢?
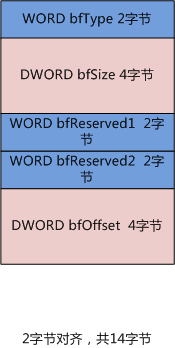
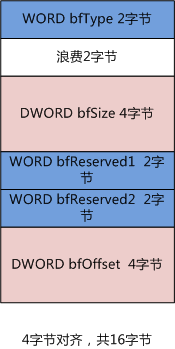
字节对齐是啥?字节对齐是为了提高机器存取效率而存在的一种数据存储方式。为什么字节对齐会对存取效率有影响?这就跟硬件有关了。某些机器要读取某些类型必须在特定位置上读取,比如读取int型就只能在大小为4的倍数的地址上读取,且一个时钟周期就能读出来;但如果允许不按字节对齐的方式来存放数据,那么若int型数据存放在奇数地址处,则CPU必须取两次大小为4的倍数的地址处的数据(上半截和下半截数据),而且数据取出来后还要拼凑,这时要花的时间就是原来的两倍以上了。所以字节对齐是一种典型的以空间换时间的做法。由于编译帮我们在底层做了字节对齐的工作,所以我们猿类不用太过操心。但也因为如此,才引发了一些问题。(补充:字节对齐数是可调的)
经过默认的字节对齐之后,结构体占用的空间大于等于原来的大小且为占用字节最多的成员的最小倍数。就如上面右侧的图片,可以看出
成员
最大占用字节数是4个字节,所以该结构体大小必须要是4的倍数,数据实际占用14字节,不够4的倍数,补两个字节,共占用16个字节。而左边的图片是经过预编译指令 #pragma pack 强制指定字节对齐数是2之后的内存布局,由于数据实际占用14字节,是2的倍数,所以就不用再补充字节了。
在仔细看看我读取BMP信息头的代码,是用read方法成块读取二进制信息的,那么,本来应该放到像左边那样的内存布局中的,而实际上我却提供了右边的内存布局,导致通过用成员映射到的地址来读取数据时比实际数据往后偏移了两个字节,于是得到的数据大多数时候就变成了天文数字了,进而引发各种奇奇怪怪的bug···········
后记:
最后说说为什么我想要用自己写的数据结构来存放位图头信息,因为WORD、DWORD等定义是微软平台上才有的,去到别的平台也许不识别,而且我的代码要与OpenGL一起工作,OpenGL可以跨平台,我不想因为一两个定义就丢弃了跨平台的特性,所以我就将他们换回了最真实的一面,然后就遇上这问题了。幸亏小白我不是很白,只是有点迟钝,花上大半天就可以解决了问题了,经一事长一智,呵呵。自己鼓励自己············
参考文章:















 907
907

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









