






数据标注是人工智能和机器学习领域中不可或缺的一环,它直接影响到模型的性能和准确性。本文将深入探讨数据标注的不同方法、最佳实践以及如何有效实施这些策略。
一、数据标注方法:选择适合的路径
1. 手动标注:精确无比
手动标注是最传统且最精确的数据标注方法,由人类专家对数据进行细致的标注。适用于需要高精度和复杂规则判断的任务,但成本较高且耗时长。
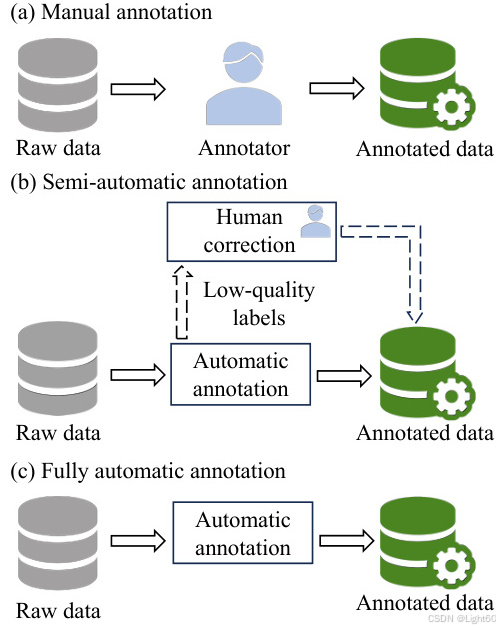
2. 半自动标注:效率与质量的结合
半自动标注结合了人工和自动化工具的力量,首先使用自动化工具进行初步标注,然后由人工检查和修正。这种方法可以显著提高标注效率,同时保持较高的标注质量。
3. 全自动标注:快速处理大规模数据
全自动标注完全依赖于机器学习模型,通过深度学习等技术直接生成标注结果。适用于大规模数据集,但其准确性通常依赖于训练数据的质量和模型的性能。
4. 专家标注:专业性保障
在某些情况下,选择特定领域的专家进行标注,以确保数据的准确性和专业性。这种方法特别适用于需要高度专业化的数据集。
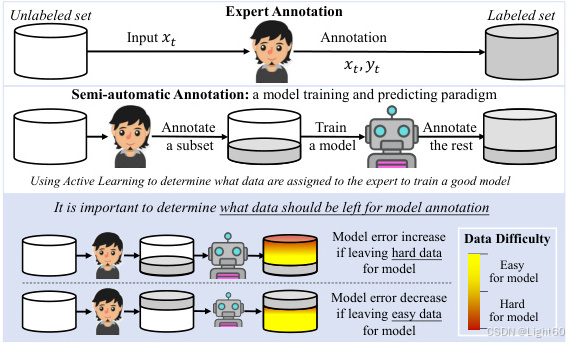
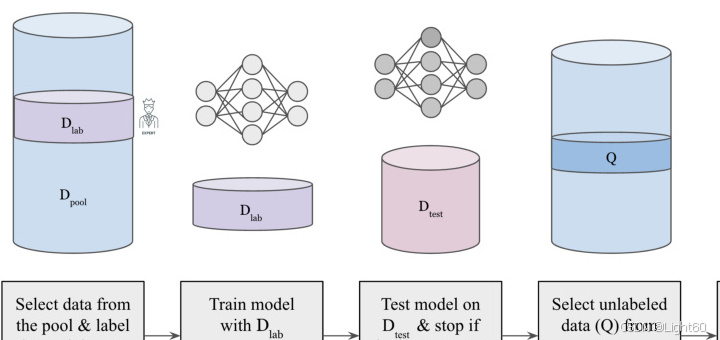
5. 主动学习:智能化的选择
主动学习是一种迭代过程,通过模型预测未标注数据的标签,并选择最具信息量的数据供专家标注。这种方法可以有效减少标注成本,同时提高模型性能。
二、数据标注的最佳实践
1. 明确标注项目
在开始标注之前,首先需要明确标注任务的具体需求和目标,包括数据集的范围、标注的标准和流程。
2. 制定详细的标注指南
制定清晰、详细的标注指南,确保所有标注人员遵循统一的标准,以减少因主观差异导致的标注不一致问题。
3. 选择合适的标注工具
根据项目需求选择合适的标注工具和技术。例如,对于图像数据,可以选择支持多标签标注的工具;对于文本数据,则可以选择支持自然语言处理功能的工具。
4. 培训标注团队
对参与标注工作的人员进行充分的培训,确保他们理解标注任务的要求和标准,并提供持续的支持和反馈,以提高标注质量。
5. 监控和管理标注进度
实时监控标注进度,并定期检查标注质量。可以通过随机抽样检查或使用质量控制团队来确保标注的一致性和准确性。
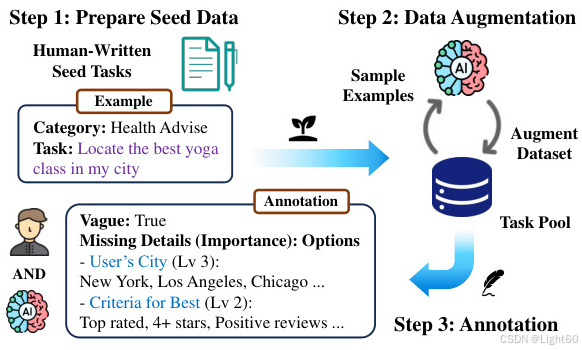
6. 数据增强与注释
使用数据增强技术生成更多样化的数据样本,并结合AI生成的注释来提高数据质量和多样性。这有助于提升模型的泛化能力和鲁棒性。
7. 优化标注流程
结合半自动和全自动方法,可以有效降低人工成本并提高效率。例如,使用自动化工具进行初步标注,再由人工进行精细调整。
8. 持续改进和优化
根据模型的表现和实际应用效果,不断调整和优化标注策略。例如,通过主动学习方法动态选择最具信息量的数据进行标注,从而提高模型性能。
三、实用工具与行动建议
工具推荐
-
手动标注工具:Labelbox、Doccano
-
半自动标注工具:Prodigy、Snorkel
-
全自动标注工具:Amazon SageMaker、Google Cloud AutoML
行动建议
-
评估项目需求:明确数据类型和标注目标。
-
选择合适工具:根据需求选择合适的标注工具。
-
制定标注计划:设定明确的时间表和质量目标。
-
开始小规模试点:验证流程和方法的可行性。
-
逐步扩大规模:根据反馈调整并优化。
通过遵循这些最佳实践和工具推荐,您将能够建立一个高效、准确的数据标注流程,为AI模型训练提供高质量的数据支持。例如,在一个实际项目中,团队使用推荐的工具优化了标注文档管理流程,不仅显著提高了标注效率,还通过高质量的数据提升了模型的预测准确率。此外,另一个案例展示了持续改进实践在适应技术升级时如何帮助维持效率。这些案例表明,数据标注是一个持续优化的过程,需要不断调整和改进,以适应不断变化的需求和技术。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









