









炼丹炉部署(如果想直接使用,可以跳过)
下面从部署到炼丹,一步一步来
git clone https://github.com/lrzjason/T2ITrainer.git
cd T2ITrainer
#环境准备
python -m venv venv
call venv\Scripts\activate
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
# nf4模型下载
huggingface-cli download "lrzjason/flux-fill-nf4" --local-dir flux_models/fill/
# 启动炼丹炉
python ui_flux_fill.py

运行后,打开对应网址即可看到可视化界面
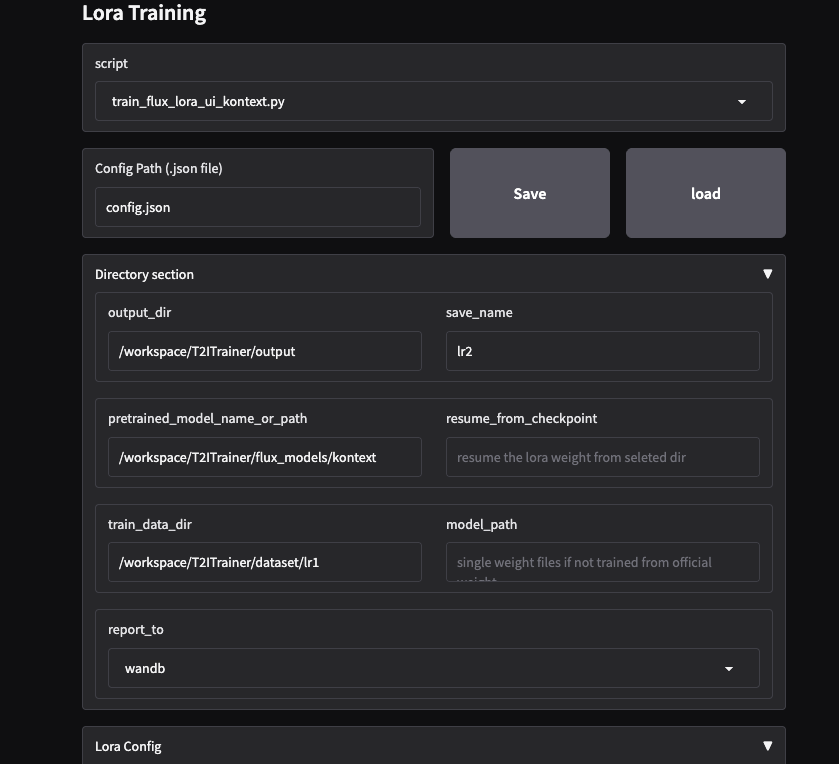
素材准备
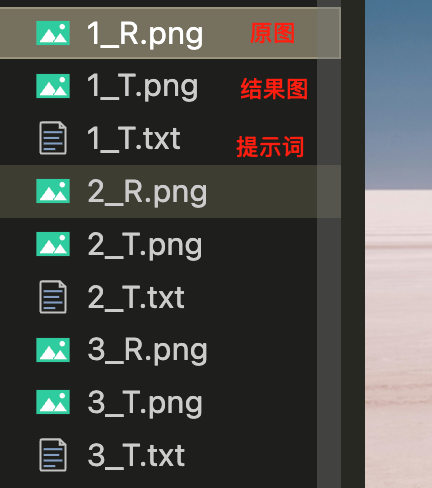
按照上图所示,准备素材,提示词部分,采用 flux-kontext风格的提示词,如
Remove red SUV with luggage on roof rack. Vast, flat, white salt flat landscape under a clear blue sky with distant mountains on the horizon.
并且如果显存是16gb,则图片分辨率推荐为:512,否则会爆显存
主要/常用参数说明

- script
训练脚本名称,一般不用改,训练kontext时不要改。
示例:"script": "train_flux_lora_ui_kontext.py"

- output_dir
输出模型保存路径,建议根据实际情况修改。
示例:"output_dir": "/workspace/T2ITrainer/output"

- save_name
保存模型的文件名。
示例:"save_name": "lr2"

- train_batch_size
每次训练的batch大小。
示例:"train_batch_size": 1
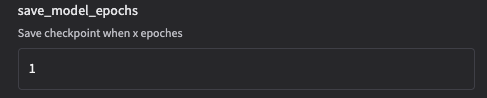
- save_model_epochs
每隔多少轮保存一次模型。
示例:"save_model_epochs": 2

- pretrained_model_name_or_path
kontext模型路径。
示例:"pretrained_model_name_or_path": "/workspace/T2ITrainer/flux_models/kontext"
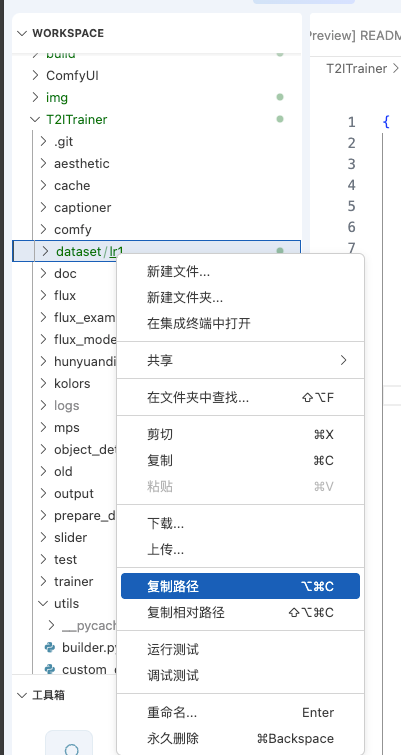
- train_data_dir
训练数据集路径,换数据集时要改。
示例:"train_data_dir": "/workspace/T2ITrainer/dataset/lr1"
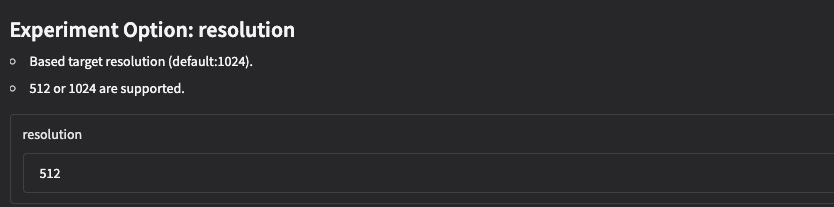
- resolution
训练图片分辨率。16GB显存推荐512,否则可能爆显存。
示例:"resolution": "512"
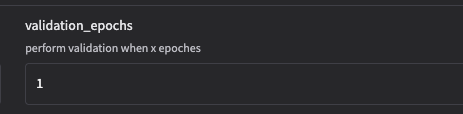
- validation_epochs
每隔多少轮做一次验证。
示例:"validation_epochs": 2
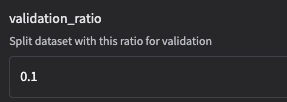
- validation_ratio
验证集比例。
示例:"validation_ratio": 0.1
点击run后

可以在终端看到训练进度

免费使用说明:
点击链接
点击复刻

到自己空间后,左小角即可选择 GPU

当前绑定腾讯云账户会自动赠送 50 机时。
租用更大显存的 GPU 能够开启更大的 batch size 更快的训练,不需要的时候关闭即可

















 488
488

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









