








图一
论文地址:https://arxiv.org/pdf/2203.11947.pdf
项目页面:https://github.com/htzheng/CM-GAN-Inpainting
摘要:
最近的图像修复方法已经取得了很大的进步,但在处理复杂图像中的大洞时,往往难以生成合理的图像结构。这在一定程度上是由于缺乏能够捕捉图像的长期依赖性和高级语义的有效网络结构。我们提出了级联调制GAN(CM-GAN),这是一种新的网络设计,由一个具有傅立叶卷积块的编码器和一个在每个尺度级别具有新的级联全局空间调制块的双流解码器组成,傅立叶卷积块从带孔的输入图像中提取多尺度特征表示。在每个解码器块中,首先应用全局调制来执行粗略的和语义感知的结构合成,然后是空间调制来以空间自适应的方式进一步调整特征图。此外,我们设计了一种对象感知训练方案,以防止网络对洞里的新对象产生幻觉,满足现实世界场景中对象移除任务的需求。大量实验表明,我们的方法在定量和定性评估方面都显著优于现有方法。请参阅项目页面:https://github.com/htzheng/CM-GAN-Inpainting.
主要贡献:
- 级联调制GAN,一种新的修复网络架构,由具有傅立叶卷积块的掩码图像编码器和级联的基于全局空间调制的解码器形成。
- 一种对象感知遮罩生成方案,防止模型在孔内生成新对象并模仿逼真的修复用例。
- 掩蔽R1正则化损失,以稳定修复任务的对抗性训练。
Places2数据集上各种类型口罩的最新结果。
模型:
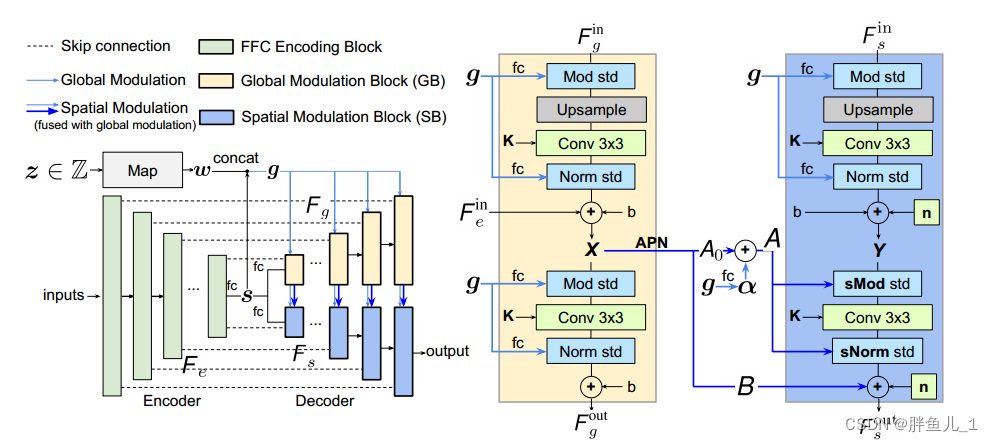
图2:左图:CM-GAN架构,由一个带有FFC块的编码器和一个带有全局调制块(GB)和后续空间调制块(SB)级联的双流解码器组成。这种级联调制方案从全局调制的特征图(而不是从先前工作中使用的编码器特征图)中提取空间样式代码,以使空间调制对修复更有效。右图:每个刻度的级联调制。GB和SB分别将F in g和F in s作为输入,并产生上采样特征F out g和F out s。具体而言,我们应用联合全球空间调制来确保全球和局部尺度上的生成一致性。
方法:
为了更好地对图像完成的全局上下文进行建模[54,55,57,56,52,59,44],我们提出了一种新的机制,将全局编码调制与空间编码调制级联,以促进部分无效特征的处理,同时更好地将全局上下文注入空间区域。它产生了一种新的架构,称为级联调制GAN(CM-GAN),它可以很好地合成整体结构和局部细节,如图1所示
编码器:如图2(左)所示,CM-GAN基于一个编码器分支和两个并行级联的解码器分支来生成视觉输出。具体来说,它从一个编码器开始,该编码器将部分图像和掩码作为输入,以生成多尺度特征图F(1)e;··;F(L)e在每个尺度1≤i≤L(L是空间大小最小的最高级别)。与大多数编码器-解码器方法不同,为了便于完成整体结构,我们从具有完全连接层的最高级别特征F(L)e中提取全局风格代码s,然后进行L2归一化。
此外,基于MLP的映射网络[21]用于从噪声中生成样式代码w,模拟图像生成的随机性。将代码w与s结合以产生用于随后的解码步骤的全局代码g=[s;w]。
全局-空间级联调制:
为了在解码阶段更好地桥接全局上下文,我们提出了全局空间级联调制(CM)。如图2(右)所示,解码阶段基于全局调制块(GB)和空间调制块(SB)的两个分支,分别并行上采样全局特征F g和局部特征F s。与现有方法[55,57,47,44,59]不同,CM设计引入了一种将全局上下文注入空穴区域的新方法。在概念层面上,它由每个尺度的特征之间的全局和空间调制级联组成,并自然地集成了用于全局上下文建模的三种补偿机制:1)特征上采样允许GB和SB利用由两个先前块生成的低分辨率特征的全局上下文;2) 全局调制(图2的青色箭头)允许GB和SB利用全局码g来生成更好的全局结构;和3)空间调制(图2的蓝色箭头)利用空间码(GB的中间特征输出)来进一步向SB注入细粒度的视觉细节。
更具体地说,如图2(右)所示,解码器各级的CM由通过空间调制桥接的并行GB块(黄色)和SB块(蓝色)组成。
这样的并行块将F in g和F in s作为输入和输出F out g和F out s。特别地,GB利用卷积层之后的初始上采样层来分别生成中间特征X和全局输出F out g。这两个层都由全局代码g[21]进行调制,以捕获全局上下文。
由于全局代码g表示二维场景的表达能力有限,以及修补孔内有噪声的无效特征[55,27],单独的全局调制会产生与上下文不一致的失真特征,如图所示。3并导致视觉伪影,如图7所示的大色块和不正确的结构。为了解决这个关键问题,我们将GB与SB级联,以纠正无效特征,同时进一步注入空间细节。SB还采用全局代码g来合成局部细节,同时尊重全局上下文。具体而言,以s中的空间特征F为输入,SB首先产生具有由全局码g调制的上采样层的初始上采样特征Y。接下来,Y由X和g按照调制卷积解调原理[21]以空间自适应的方式联合调制:
- 全局空间特征调制。通过2层卷积仿射参数网络(APN)从特征X产生空间张量A0=APN(X)。同时,全局向量α=fc(g)由全局代码g产生,具有完全连接层(fc)以合并全局上下文。最后,融合的空间张量a=A0+α利用分别从g和X提取的全局和空间信息,用逐元素乘积缩放中间特征Y:

- Convolution,然后将调制张量Y与3×3可学习内核K卷积,得到Y^
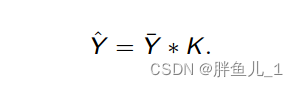
- 空间感知解调。与现有的空间调制方法[35,22,1]不同,我们放弃实例或批量归一化以避免已知的“水滴”伪影[21],并提出了一个空间感知解调步骤来产生归一化输出Ye。具体而言,我们假设输入特征Y是具有单位方差的独立随机变量,并且在调制后,输出的预期方差不会改变,即Ey2Ye[Var(Y)]=1。该假设给出了解调计算:
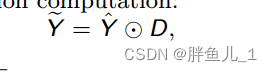
其中D=1=p K 2 Ea2A[a2]是解调系数。等式(3)是用补充材料中详细阐述的标准张量运算来实现的。
- 添加空间偏移和广播噪声。为了从特征X引入进一步的空间变化,将归一化特征Ye与广播噪声n一起添加到由另一仿射参数网络从特征X产生的移位张量B=APN(X),以产生新的局部特征Fout s:
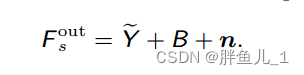
如图3的第4列所示,级联SB块有助于生成细粒度的视觉细节,并提高孔内外特征值的一致性。
在早期阶段扩大接受域。
全卷积模型的有效感受野增长缓慢[28],尤其是在网络的早期阶段。因此,基于跨步卷积的编码器通常在空穴区域内生成无效特征,这使得解码阶段的特征校正更具挑战性。最近的一项工作[44]表明,快速傅立叶卷积(FFC)[8]可以帮助早期层实现覆盖整个图像的大感受野。然而,工作[44]将FFC堆叠在瓶颈层,并且在计算上要求很高。
此外,与许多其他工作[55]一样,由于瓶颈层较浅,[44]无法有效地捕获全局语义,从而限制了其处理大漏洞的能力。我们建议用FFC代替CNN编码器的每个卷积块。通过在所有尺度水平上采用FFC,我们使编码器能够在早期阶段传播特征,从而解决在孔内产生无效特征的问题,有助于改善结果,如表2中消融研究所示。
对象感知训练
生成训练掩码的算法至关重要。本质上,采样的遮罩应该与现实用例中绘制的遮罩相似。此外,遮罩应避免覆盖整个对象或任何新对象的大部分,以阻止模型生成类似对象的图案。先前的工作生成具有正方形掩模的掩模[37,18]或使用随机笔划[27]或两者的混合物[55,59]进行训练。
过于简单化的掩模方案可能会导致偶然的伪影,例如可疑物体或色块。
为了更好地支持逼真的对象移除用例,同时防止模型试图合成孔内的新对象,我们提出了一种对象感知训练方案,该方案在训练过程中生成更逼真的遮罩,如图4所示。

图4:与真实修复请求(左)和CoModGAN[59]生成的掩码(中)相比,我们为训练生成的对象感知掩码的示例(右)。请注意,我们的掩码与真实用户的请求更加一致。
具体而言,我们首先将训练图像传递给PanopticFCN[26],以生成高度准确的实例级分割注释。接下来,我们对自由形式孔[59]和对象孔的混合物进行采样,作为初始遮罩。最后,我们从图像中计算一个洞和每个实例之间的重叠率。如果重叠比率大于阈值,则我们将前景实例从洞中排除。否则,孔将保持不变以模拟对象完成。我们将阈值设置为0.5。我们随机放大和平移对象遮罩,以避免过度拟合。我们还扩大了实例分割边界上的孔洞,以避免孔洞附近的背景像素泄漏到修复区域。
训练目标和掩蔽-R1正则化
我们的模型是用对抗性损失[59]和基于分割的感知损失[44]的组合来训练的。实验表明,当纯粹使用对抗性损失时,我们的方法也可以获得良好的结果,但添加感知损失可以进一步提高性能。此外,我们提出了一种掩码-R1正则化,用于稳定修复任务的对抗性训练。与天真地应用R1正则化[29]的[59,44]不同,我们利用掩码m来避免计算掩码外的梯度惩罚,特别是:
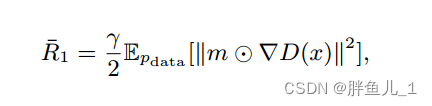
其中m是表示空穴区域的掩模,γ是平衡重量。新的损失消除了计算梯度对真实像素的潜在有害影响,从而稳定了训练。
评估:
我们将网络的信道号设置为具有与CoModGAN和LaMa类似的模型容量,如表4所示。
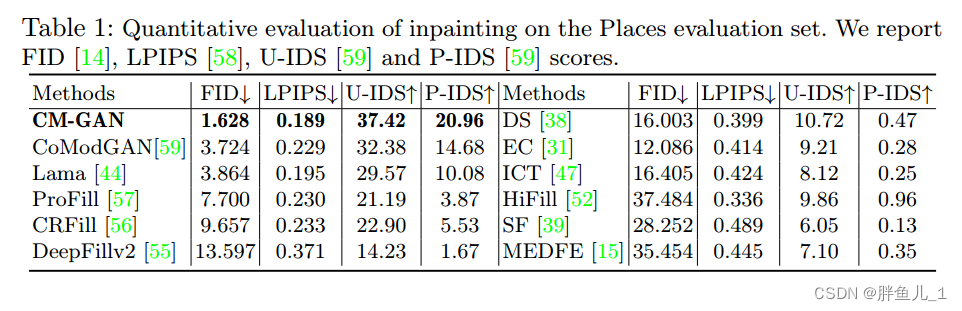
定量评估。表1显示了我们的方法与最近使用我们的掩码的一些方法的比较。结果表明,我们的方法在FID、LPIPS、U-IDS和P-IDS方面显著优于所有其他方法。我们注意到,在感知损失的帮助下,LaMa[44]和我们的CM-GAN获得了比CoModGAN和其他方法明显更好的LPIPS分数,这归因于预训练的感知模型提供的额外语义指导。与LaMa相比,我们的CM-GAN将FID降低了50%以上,从3.864降低到1.628,这可以用LaMa与我们的结果相比通常模糊的结果来解释,后者往往更清晰。
我们评估了CM-GAN对其他类型掩码的推广,包括宽掩码[44]和CoModGAN[59]的掩码。我们还用[44]和[59]的掩码(用CM-GAN=表示)微调CM-GAN,并报告结果。如表3所示,我们的模型在进行微调和不进行微调的情况下都获得了明显的性能增益,并展示了其泛化能力。值得注意的是,在我们的对象感知掩码上训练的CM-GAN在CoModGAN掩码上优于CoModGAN,这证实了CM-GAN更好的生成能力。CM-GAN强大的容量在微调后带来了进一步的性能提升。

图5:Places2与我们合成的掩模的视觉比较,包括大的随机掩模(左)和干扰物去除场景的掩模(右)。我们展示了输入图像以及ProFill[57]、Lama[44]、CoModGAN[59]和CM-GAN(我们的)的结果。通过放大屏幕查看效果最佳。















 2311
2311











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









