






LaMa: 基于傅立叶卷积的分辨率鲁棒的大掩模修复
WACV 2022论文
原论文:https://arxiv.org/abs/2109.07161
源代码(用于图像修复的代码):https://github.com/saic-mdal/lama
引言:
问题描述:目前的图像修复算法在大块缺失区域、复杂几何结构以及高分辨率图像上的修复效果差强人意。
原因分析:在修复网络和损失函数都缺少有效的感受野。
解决方案: large mask inpainting(lama)
1)使用 fast Fourier convolutions(FFCs)以获取更大(wide)的感受野;
2)使用一个更大(high)感受野的 perceptual loss(感知损失);
3)训练的时候采用更大(large)的 mask 来验证前 2 步改进的效果。
实验结果:超过了以往的 SOTA 模型,鲁棒性更好(即使在比训练的分辨率 256x256 更高的图像上也有很好的效果),参数量和时间也更少。
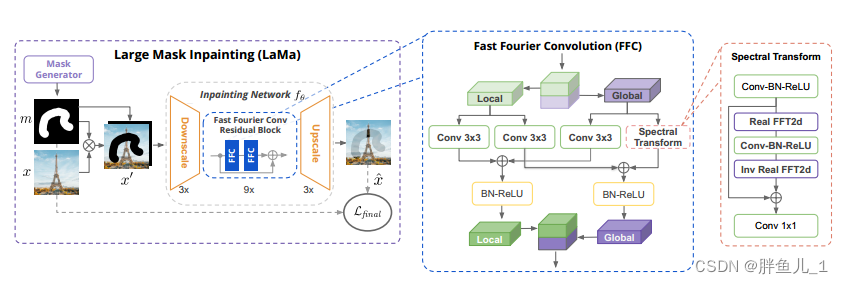
模型的主要架构:
原始彩色图片(3通道),mask图片(1通道),先将mask取反和彩色图片相乘,得到带有mask的彩色图片。然后将其和mask图片基于通道进行叠加,得到一个4通道的图片。
网络会首先进行下采样操作,然后经过快速傅立叶卷积处理,最后再上采样输出修复后的图像。
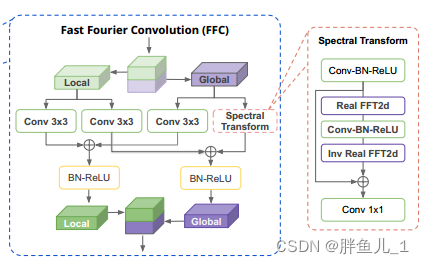
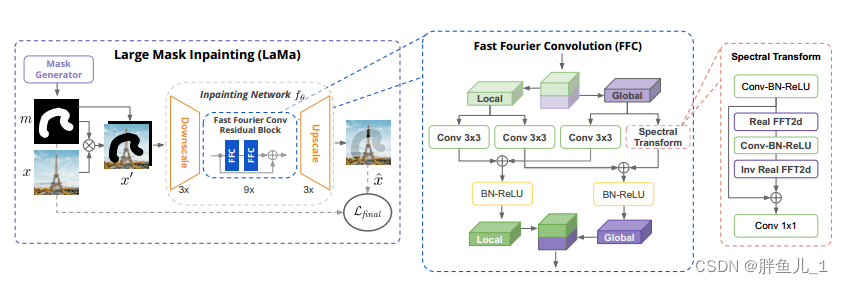
其中,在FFC的处理过程中,会将输入tensor基于通道分为2部分分别走2个不同的分支。一个分支负责提取局部信息,另一个分支负责提取全局信息。在global分支中会使用FFC提取全局特征。最后将局部信息和全局信息进行交叉融合,再基于通道进行拼接,得到最终的输出结果。
损失函数:
原始的监督损失要求生成器尽可能地去还原 Ground Truth。但是当遮挡区域很大时,已有的可见区域的信息不足以还原,因此模型会做出很多模棱两可的判断,从而导致模糊。
本文提出了 high receptive field perceptual loss(HRF PL)--高感受野感知损失,利用一个基本的预训练模型来评估预测图和目标图之间的距离。因为针对 large mask 的修复问题的重点是理解图像的全局结构,因此不需要精确的还原,允许有一定的变化。
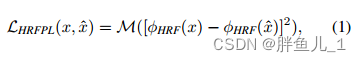
其中[·−·]2是逐元素运算,其中 M 是层内均值和层间均值的2stage均值运算,ϕHRF(·)则可以用傅里叶或空洞卷积来实现。
基于局部patch的生成器,判别器的损失:
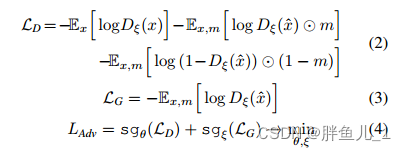
式中: x为数据集样本,m为综合生成的掩膜,xˆ = fθ(x') i为x'= stack( x⊙m,m)的修复结果,sgvar停止梯度, L Adv为联合损失进行优化。
判别器的梯度惩罚:
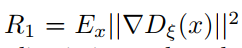
最终的损失函数是对 HRF PL 和其他几个损失函数(包括对抗损失)的融合:

训练集中的 mask 生成:
训练模型时采用了一种激进的 large mask 生成策略,随机生成遮挡面积较大的 wide 或 box 遮挡.

来自不同训练 mask 生成策略的样例。作者认为 mask 生成方式会极大地影响最终的修复效果。
实验结果表明,使用 large mask 策略会提高模型的性能,无论是在 narrow 亦或是 wide mask 上进行评估.
评估:
优于绝大多数的模型,指标好的没lama算法的参数量少,参数量少的没lama算法指标好.
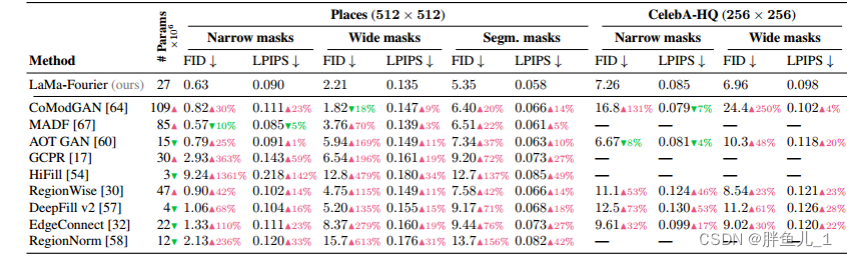
研究人员在Places,CelebA-HQ数据集上的图像修复进行了实验,采用可学习感知图像斑块相似性(LPIP)和FID作为定量评估指标。与LaMa傅立叶模型相比,几乎所有的模型的性能都更弱(红色上箭头)。表中还包括了不同的测试掩码生成的不同策略的度量,即窄掩码(narrow)、宽掩码(wide)和分段掩码(segmentation),LaMa傅里叶的性能仍然更强,表明了实验方法更有效地利用了可训练参数。
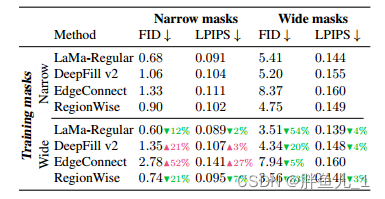
该表显示了使用窄掩模或宽掩模训练不同修复方法的性能指标。这个▲ 表示劣化,以及▼ 表示由对应方法的宽掩模训练引起的分数的提高。LaMa和RegionWise修复显然受益于使用宽口罩的训练。这是一个经验证据,表明积极的掩模生成可能对修复系统有益。
模型效果:


将修复模型迁移到更高分辨率的图像上。随着分辨率的提高,基于传统卷积的模型开始产生致命的伪影,而基于 FFC 的模型继续生成精细的语义一致的图像。
作者还提出了Big Lama
Big lama傅立叶与拉lama傅立叶在三个方面不同:生成器的深度;训练数据集;以及批次的大小。它有18个残差块,全部基于FFC,产生51M个参数。该模型是在Places Challenge数据集中450万张图像的子集上进行训练的。正如lama的标准基础模型一样,Big LaMa仅在约512×512图像的低分辨率256×256作物上进行训练。Big LaMa使用的批量更大,为120(而不是我们其他型号的30)。尽管我们认为这个模型相对较大,但它仍然小于一些基线。它在八个NVidia V100 GPU上进行了大约240小时的训练。Big LaMa模型的修复示例如图1和图5所示。
















 529
529











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









