






点击上方“机器学习与生成对抗网络”,关注星标
获取有趣、好玩的前沿干货!
知乎作者受限玻尔兹曼机
https://zhuanlan.zhihu.com/p/396593319
编辑|人工智能前沿讲习
最近想搞一搞Few shot leanring,于是在B站上听了王老师的课,感觉深受启发,写一写课程笔记,也希望分享给想入门的朋友。笔记中增加了一些我个人的理解,希望各位大佬指导。
王老师的课程:
https://www.bilibili.com/video/BV1V44y1r7cx
01
小样本学习要解决什么问题?
举一个例子,假如有如图的两类动物,左边一类是犰狳,右边一类是穿山甲,现在请你仔细区分一下它们。但是我并不告诉你到底什么是犰狳,什么是穿山甲。现在,我新给你一个图像,请你判断是犰狳还是穿山甲。

它显然是穿山甲。这是人的能力,仅仅从一个很小的甚至为1的样本量就可以进行同类或异类的区分。我们希望机器也能够具有这样仅仅根据很小的样本量就可以区分同类和异类的能力。但是这样小的样本不可能用来训练一个深度神经网络,那该怎么办呢?
我们首先回顾一下传统的强监督分类问题。简化来说,我们有一个训练集,训练集中包含很多类别,每个类别下有很多同类样本。现在来了一个测试图片,注意这个测试图片本身是训练集没有见过的,但是!他的类别一定在训练集中有。比如下图所示:测试图片是一个哈士奇,但是在训练集中是有哈士奇这一类,所以网络已经见过很多的哈士奇了。

对于小样本问题,我们还是有训练集,这个训练集和之前传统的强监督的差不多。但是现在这个测试图像(FSL中叫做Query)训练集既没见过,他的类别训练集中也没有!比如下图,训练集中有哈士奇,大象,虎哥,鹦鹉和车五类,测试图片却是一个兔子。但是呢,我们有一些数量很少的卡片,叫做Support Set,它里面包含几个类别(标注),每个类别下有很少量的图片。已知Query一定来自Support Set中的一类。但是Support Set本身又无法支持网络的训练。现在我们想要让机器和人一样只根据数量很少的样本就能够判断Query是Support Set中的哪一类。这就是小样本学习要解决的问题。


02
小样本学习的几个概念
小样本学习的数据集包含三个,一个是Training Set,一个是Support Set,另一个是Query。我刚学到这里时,对Training Set非常疑惑,既然Query的类别Training Set中都没有,那么为什么我们还需要Training Set?其实我们需要在Training Set上训练网络能够区分同类和异类的能力,这种能力的训练是需要大量样本的。后面就知道啦。
现在我们来看Support Set,Support Set中有k类样本,每类中有n个样本,我们将类别数叫做k-way,将每类中的样本数叫做n-shot。如图中这个就是4-way,2-shot。显然,当way越多n越少的时候,就越困难。注意,当每类下就一个样本时,叫做one-shot,这个是最困难的,也是目前比较火的。


03
怎么解决?
那我们怎么来解决这个问题呢?最主要的思路也很简单,那就是看Query和Support Set中的哪一类更像呗!用学术语言来说,就是Learn a similarity function。那就得先让网络知道什么是像!但是Support Set中就那么几个,网络学不会啊。这个时候之前说的Training Set就派上用场了。原来我们不是用它来训练一个分类器来分哪一个是虎哥,哪一个是大象,我们是要用它来让网络学习什么是像,什么是不像!具体来看就是学习下面的这个sim函数,当两张图像是同一类时,sim=1,是不同类的时候sim=0。学会了像以后,就让网络来看Query和Support Set中的哪一个最像,那么Query就属于Support Set中的哪一类。这个问题就解决啦。



04
让网络学习什么是像,什么是不像
让网络学会什么是像,什么是不像,这是最基本的想法也是最重要的一环。以下简单介绍几种经典的方法。
Learning Pairwise Similarity Scores
这个思想比较简单,既然Training Set中有很多类,每类中也有很多样本,那么就来构造正负样本对来让网络学习哪些是像的,哪些是不像的。如图所示,训练集中包含五类,我们使用类中的样本构造正样本,即他们是相似的;用类间的样本构造负样本,即他们是不相似的。我们给正样本给予标签1,负样本给予标签0。可以看到,这样构造的话,我们的映射关系,就是输入是一个图像对,标签是0或者1。我们如何设计网络结构呢?


答案是使用孪生网络Siamese Network,它的输入是两个图像,并按照完全相同(共享)的权重将两幅图像映射到embedding中。然后我们将这两个图像在特征空间的embedding求一个距离,或者做差之后通过全连接层进一步映射,最后通过sigmoid函数和我们的标签结合起来。这样网络就可以端到端的来学习什么是像啦。
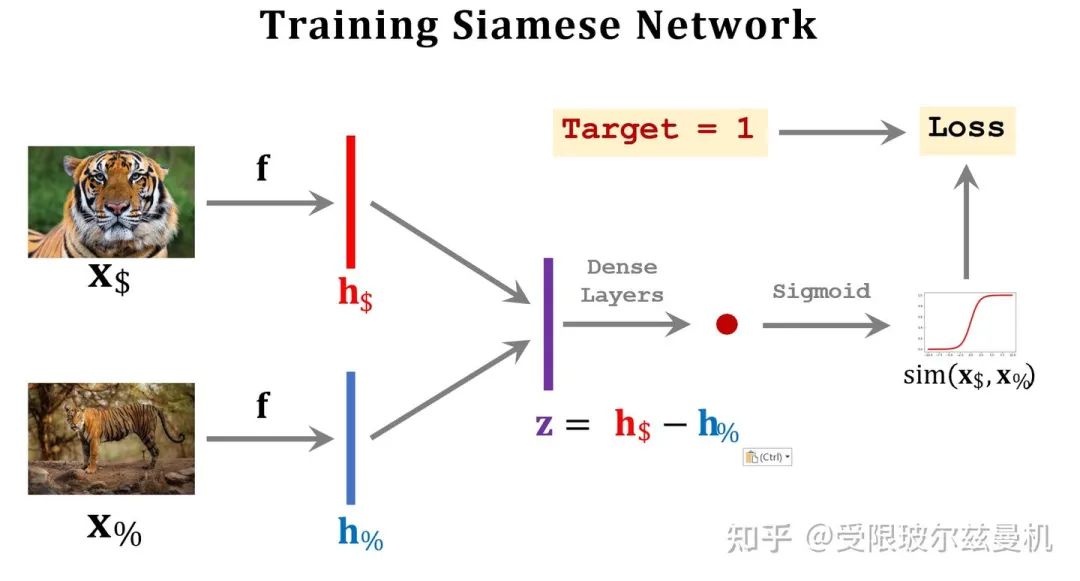
然后呢,我们将Quary与Support Set中的每一个样本均进行以上测试,最后sigmoid输出的sim值越接近1,就说明Quary和这个样本越像,最后找到那个最像的就可以啦!

Triplet Loss
之前我们构造样本对每次都是一个正样本对一个负样本对这样来构造,这样其实并不能很明显的进行对比。于是三个样本的构造方法就出现了。首先我们在测试集中的某一类中选择一个锚点样本,比如那个虎哥。然后我们在虎哥所在的这一类中,再选一个虎弟作为正样本;然后不在虎这一类里面选了,再到其他类里面选一个作为负样本。这样我们就选好了三个样本。



然后我们依然使用孪生网络来进行特征提取,只不过现在在一次训练的过程中,我们计算两个正样本之间的特征距离和两个负样本之间的特征距离,接下来就是定义损失函数了。对于正样本们,我们当然希望它们在特征空间的距离尽可能地靠近,近成0了那最好;对于负样本对,我们尽可能地希望它们在特征空间的距离尽可能远离,那么多远就算远了呢,我们需要给定一个条件。因此我们定义一个α,当两个负样本之间的距离比正样本之间的距离远到α的时候,我们就认为足够了,loss=0,这样正样本之间的距离太远了不行,负样本之间的距离太近了也不行。所以这种思想是一种对比的思想,将相似的样本在特征空间拉近,而将不相似的样本在特征空间推远。


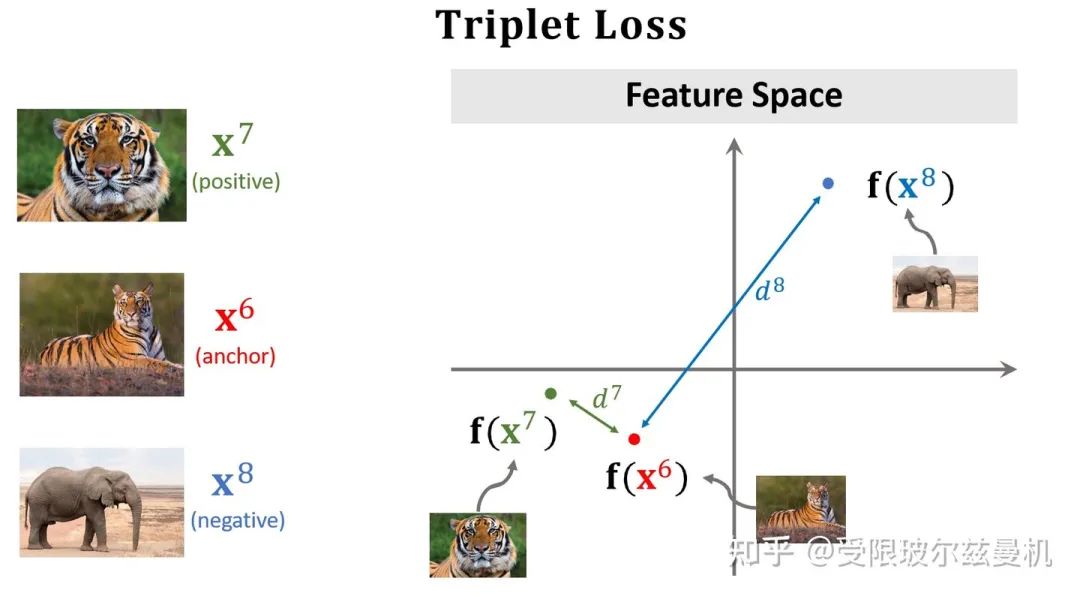
之后我们来进行预测,我们分别计算Quary和每个样本之间的距离,选距离最小的那个作为最终的决策类。

Pretraining and Finetuning
我们之前的思路是在训练集上让网络学会什么是像,然后直接测试Quary和Support Set。其实Support Set在训练集中也没有,甚至连类别都没有见过,网络可能会有点害怕。那么能不能让网络也见见Support Set呢,答案是可以的!而且能涨好多点!
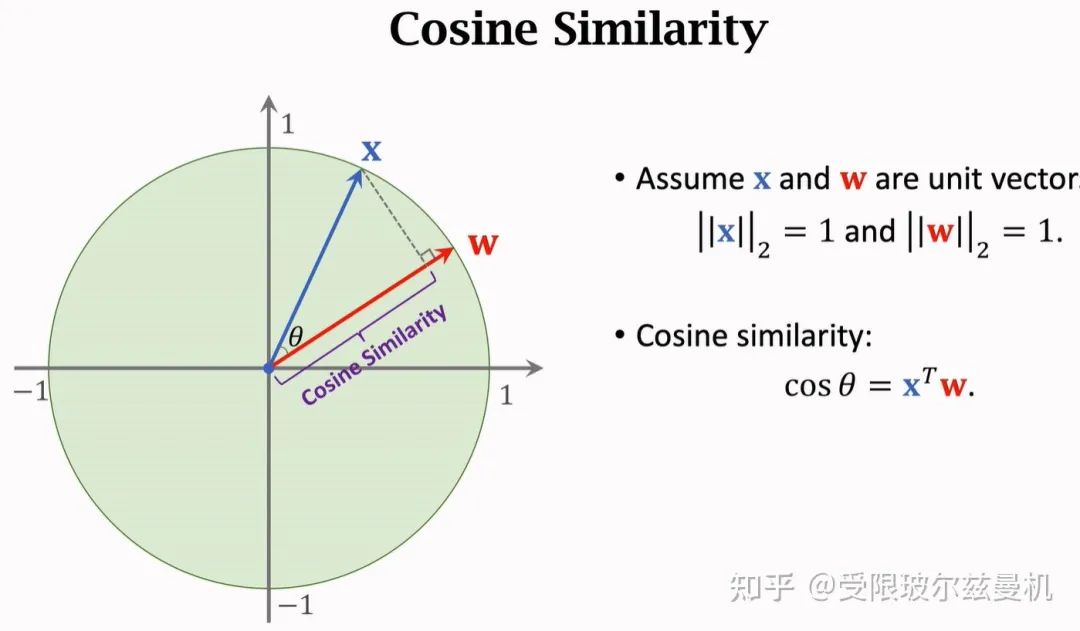
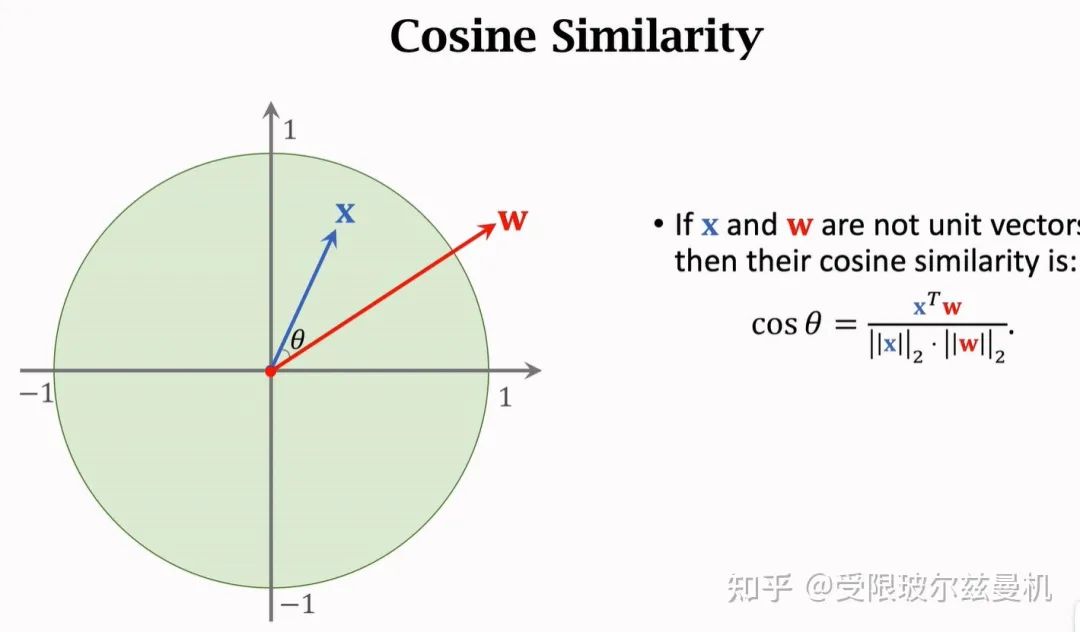
首先我们从余弦相似度说起,已知两个单位向量,它们之间的余弦相似度就是它们的内积,当夹角越小的时候,两个向量更像。因此余弦相似度可以表示两个向量的相似程度,常常用在特征空间。当两个向量不是单位向量时,需要先对其进行归一化,然后再求内积。
我们再来说Softmax函数。Softmax函数可以将一组数转化为每个数对应的概率值,概率和为1。当然,这样转化会使本来大的数更大,但是却比直接max要温和。那么所谓的softmax分类器,无非就是将一个d1的输入向量左乘一个kd的权重矩阵,再加一个偏置,得到对应k类的概率值。这个权重是根据loss计算的。

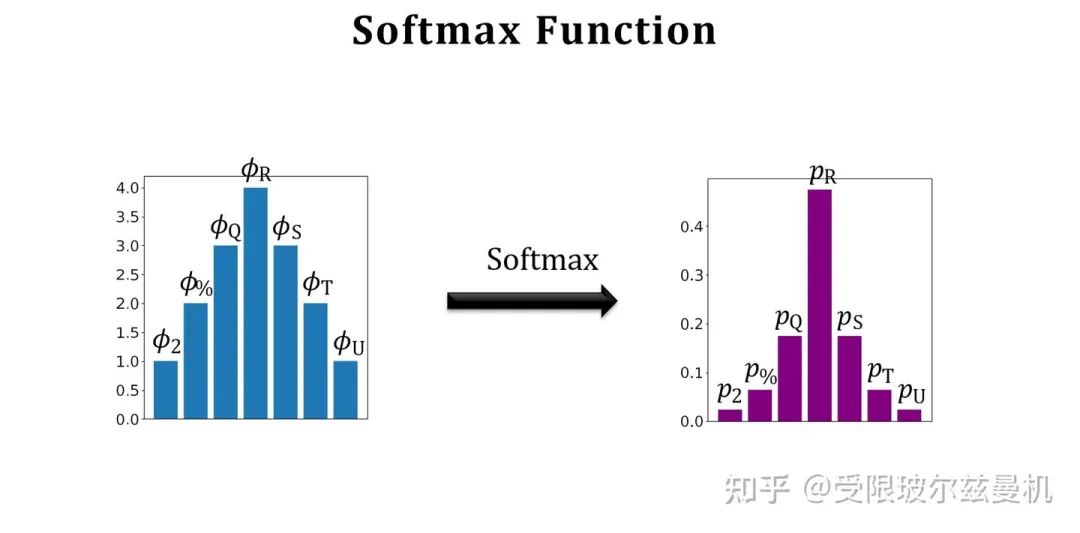
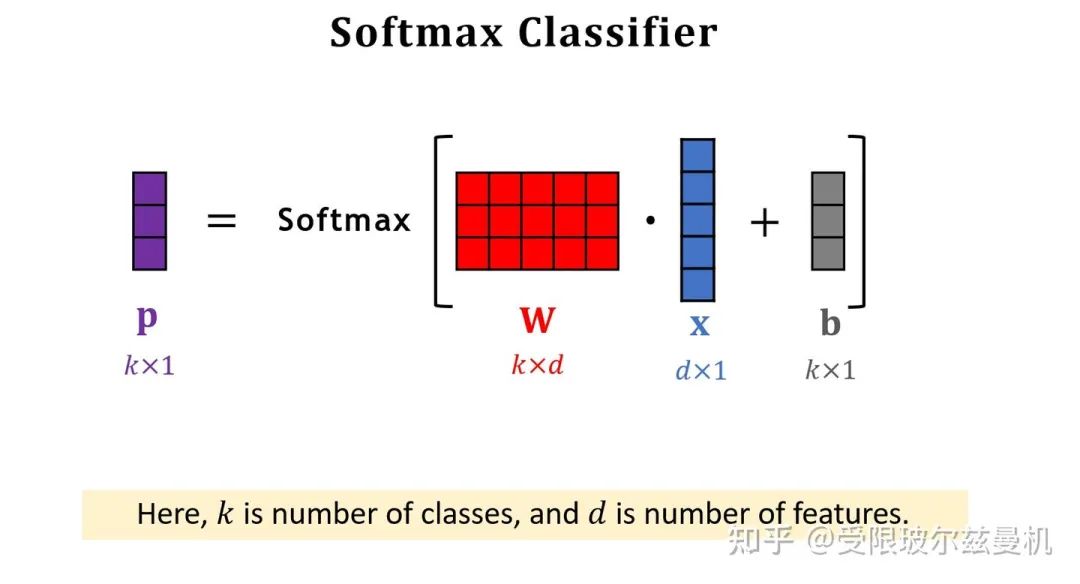
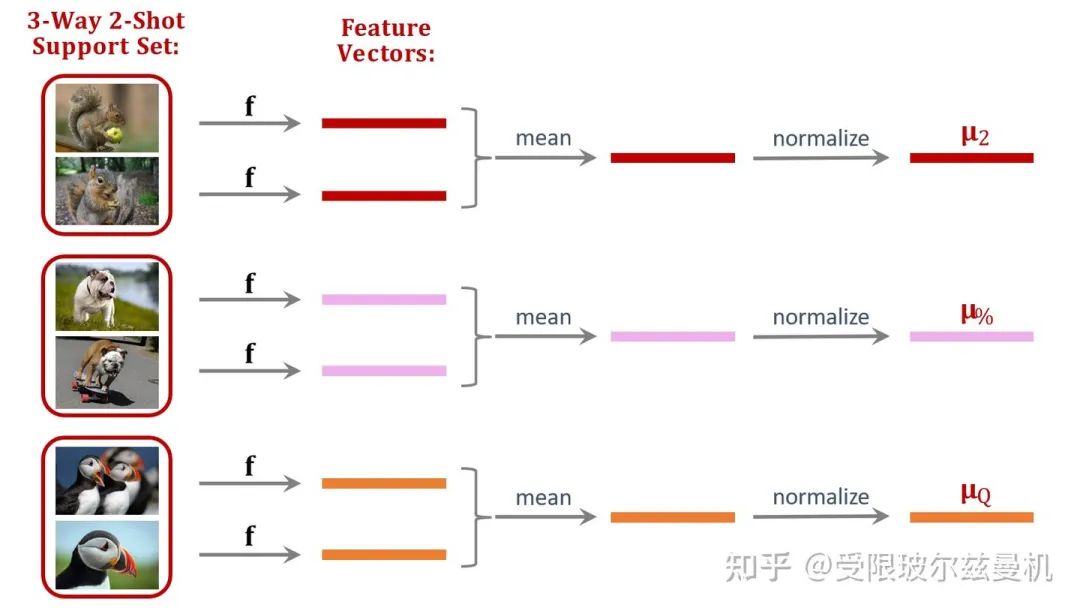
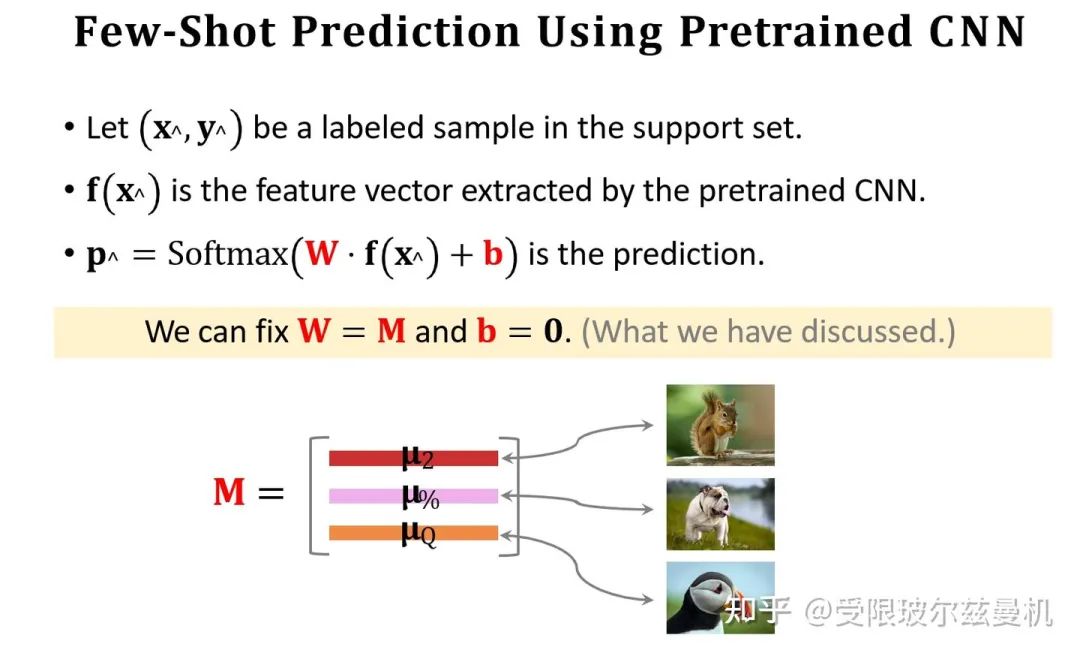
好啦,下面我们开始具体说。我们还是在大型的训练集上训练我们的网络。只不过不直接在Support Set上进行测试。我们将Support Set中的每一类样本使用训练好的网络进行特征提取,如果每一类中有一些样本,那么我们对他们的embedding进行平均。之后我们进行归一化,这是为了后面更好的计算余弦相似度。这样一来我们得到了Support Set中这些类的平均归一化embedding。
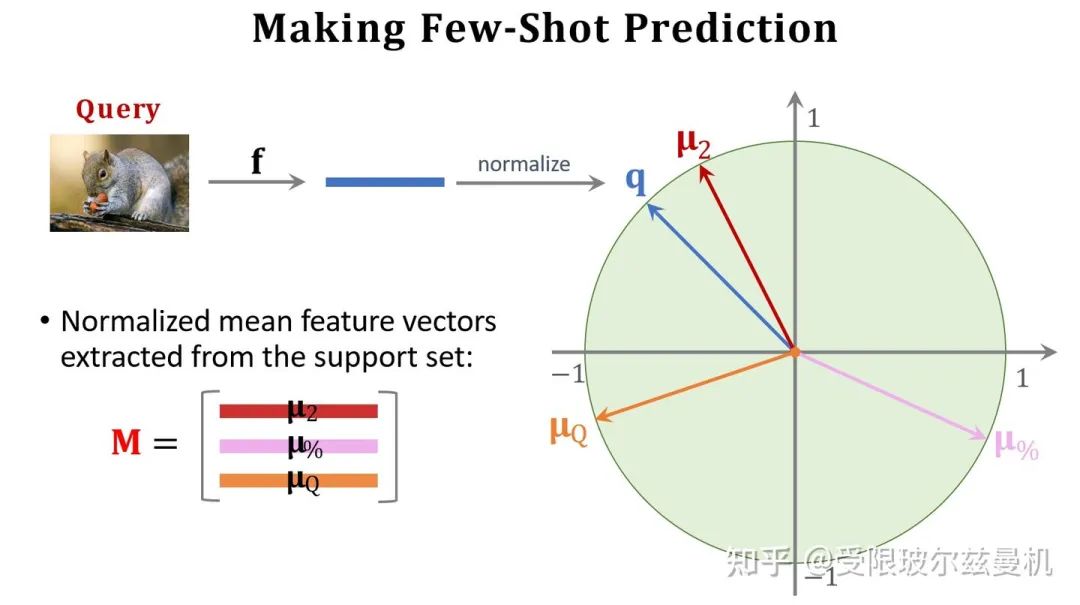
接下来我们也对Query提取embedding,并使用之前Support Set提取的embedding初始化权重矩阵M。我们可以看出M中的每一行其实都代表Support Set中每一类的特征。接下来我们使用Support Set中的样本根据softmax分类器进行fintuning。我们使用M来直接初始化softmax的权重矩阵W,这是因为Support Set中的样本数量太少了,如果随机初始化参数,则效果并不好。其实不难发现,我们直接求Q与M的内积再接softmax就可以得到Q属于M中的哪一类的概率,由于没有进行fintuning,它的结果还是差一些。
我们使用M作为初始化权重矩阵,之后使用交叉熵函数对Support Set中的所有样本进行fintuning。

Trick
在fintuning的过程中,我们有三个非常好用的Trick。
第一个是我们刚才说过的,在finetuning的时候使用Support Set中每类样本的特征组成的矩阵M进行初始化待训练权重W,这是因为Support Set中的样本数量太少了,如果随机初始化参数,则效果可能不佳。

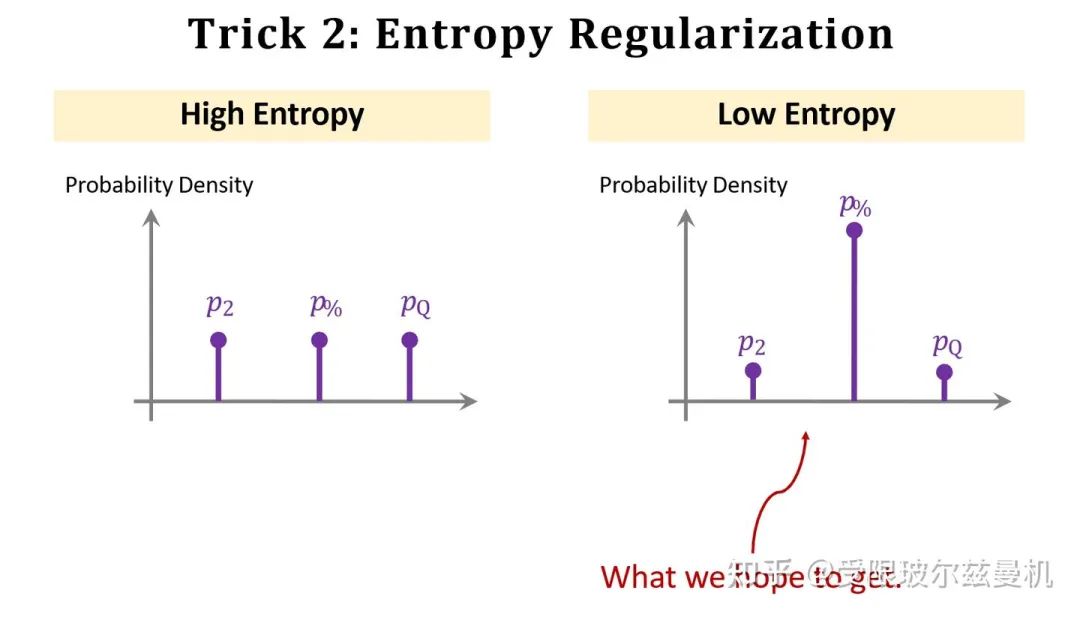
第二个是使用熵进行正则化。我们知道对于softmax,如果他输出每一类的概率都差不多,那么说明分类器没有学好,基本是在瞎猜的状态,此时它的熵就会很大;但是如果有一类输出的概率特别大,其他预测概率都很小,那么说明神经网络此时很有把握,这时它的熵就会很小。我们希望fintuning中神经网络能给出更有把握的结果,因此加入熵正则化,可以明显提高性能。

第三个是使用余弦相似度与softmax分类器的组合。我们知道softmax分类器中是权重W与Q相乘来运算的,而我们这里将这个W替换为余弦相似度的计算,也可以提高性能。

猜您喜欢:
CVPR 2021 | GAN的说话人驱动、3D人脸论文汇总
附下载 |《TensorFlow 2.0 深度学习算法实战》
附下载 | 超100篇!CVPR 2020最全GAN论文梳理汇总!
















 863
863











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









