







0、前言
前期博文提到经过两步smooth化之后,我们将一个难以收敛的函数逐步改造成了softmax交叉熵损失函数,解决了原始的目标函数难以优化的问题。Softmax 交叉熵损失函数是目前最常用的分类损失函数,本博文继续学习Softmax 交叉熵损失函数的改进,详细的理论参考论文《基于深度学习的人脸认证方法研究》,这篇论文真的太棒了,是我见过最优秀的专门针对损失函数进行深入研究的杰作。
1、Softmax 交叉熵损失函数
(1)Softmax 交叉熵损失函数表达
将样本分为 C 个类别,在使用 Softmax 交叉熵损失时,需要将神经网络的最后一层输出设置为 C。设置理想向量, Softmax 交叉熵损失函数表示如下:
其中:
Softmax 交叉熵损失函数实际上分为两步:
1)求 Softmax : 得到当前样本属于某类别的概率
2)求交叉熵损失
将1)计算所得概率与理想向量求交叉熵:
①如果理想向量为 One-hot 向量,即仅在第 y 个位置为 1,其他部分为 0,所以最终只保留了第 y 个位置的交叉熵。此时的Softmax 交叉熵损失函数表示为:
梯度为:

②如果理想分布不再是 One-hot 向量,而是一组其他概率值时,交叉熵损失函数为:
梯度为:

可以看到梯度形式非常简单 ,也更容易实现。 由于最小化Softmax 交叉熵损失会让可以Softmax 概率无限尝试逼近 1 ,这有可能会带来过拟合效应。由1中分析可知,当理想分布不再是 One-hot 向量,而是一组其他概率值时,交叉熵损失函数的梯度更简单,因此可以考虑标签柔化(Label Smoothing)即将理想分布的 One-hot 向量柔化为如下形式:

此时的理想向量并不是0、1组合,最小值小于1,最小值大于0。此外,模型蒸馏法将一个大模型输出的概率值进行柔化来作为理想分布优化小模型,这样可以使得小模型能够得到更多的信息来进行训练,而不只是简单地去学习 0和 1。
(2)Softmax 交叉熵损失函数训练得到的特征分布
下图为在 MNIST 数据集上,使用 Softmax 交叉熵损失函数训练得到的二维特征分布,这是欧氏距离下该模型判别失败的例子(图中表示三个样本的二维特征向量,可以看出基于欧式距离相似度量方法,
,即
属于一个类别可能性更高,但实际上
才同属一个簇,因此在 Softmax 交叉熵损失函数训练得到的特征空间下采用欧式距离度量有可能失败!)

下图为在 MNIST 数据集上,使用 Softmax 交叉熵损失函数训练得到的二维特征分布,这是内积相似度下该模型判别失败的例子(图中表示三个样本的二维特征向量,可以看出基于内积相似度量方法,
,即
属于一个类别可能性更高,但实际上
才同属一个簇,因此在 Softmax 交叉熵损失函数训练得到的特征空间下采用内积度量有可能失败!)
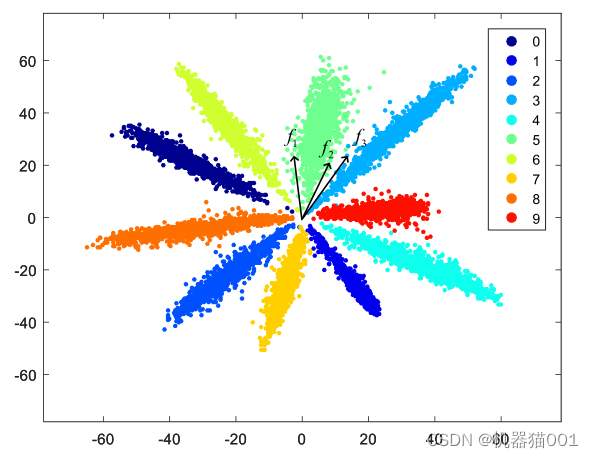
从上面两个图可以看出:Softmax 交叉熵损失函数训练出来的特征呈辐射状分布,在这种分布下,特征向量的长度(模的大小)改变将不影响该特征的类别判定,而不同类之间的区别主要由角度来决定,因此内积、欧氏距离这些与幅度相关的相似性度量的效果就不如余弦这种与幅度无关的相似性度量。至于 Softmax 交叉熵损失函数训练出的特征分布为什么呈辐射型,是因为如果将特征幅度(模的大小)放大或缩小,那样本特征向量与各类别权重之间的内积相似度也会同时放大或缩小,这时最大的相似度仍旧还是最大的,不会对该特征被归到的类别产生影响。
上述分析可以看出,传统的 Softmax 交叉熵损失函数并不是很适合人脸认证这一度量学习任务,需要进行改进。因此论文《基于深度学习的人脸认证方法研究》在深入分析传统的 Softmax 交叉熵损失函数用在人脸认证这样的度量学习上的一些特性基础上,对Softmax 交叉熵损失函数进行改进。
2、人脸认证损失函数存在的不足
深度神经网络在多项计算机视觉任务,尤其是图像分类上取得了令人瞩目的成绩。对于人脸认证任务,基于深度学习的方法也已经在多个数据集上超过了人类,然而之前的大多数方法采用的损失函数仍然存在着一些缺陷。当今的人脸认证损失函数分为两大类:基于分类的损失函数和基于度量学习的损失函数,基于分类的损失函数在训练与测试过程中的不匹配问题,基于度量学习的损失函数又存在着难以找到合适的采样方法的问题,这些问题在以往的工作中往往被一笔带过,没有做过详细的分析,不过这也给后面的研究者留下了很多研究的空间。
(1)基于分类的损失函数在训练与测试过程中的不匹配问题
一个典型的基于分类的方法在训练和测试中的流程图下图所示:

这一类的方法通常在训练时使用内积相似度,而在测试时使用余弦相似度来比对两张人脸图像的特征,这就产生了训练与测试之间不匹配的问题。
内积相似度与余弦相似度之间的区别在于余弦相似度多了一步特征归一化的操作,不加这个归一化操作,模型的识别率会有显著的下降。
既然在测试时加和不加特征归一化的区别这么明显,那如果在训练的时候也加入特征归一化操作,使得训练与测试时使用的相似度相吻合,相信也能使模型的性能得到提升。这种使训练与测试匹配的策略在深度学习领域叫作端到端学习,让神经网络直接对测试时的指标进行优化,往往能得到更好的结果。
论文《基于深度学习的人脸认证方法研究》分析了传统的 Softmax 交叉熵损失函数用在度量学习上的一些特性以及产生的一系列问题(博客第1节内容),可以看到,传统的 Softmax 交叉熵损失函数并不是很适合人脸认证这一度量学习任务,因此论文使用 Softmax 交叉熵损失函数优化余弦相似度,提出了余弦 Softmax 交叉损失函数,使得其适用于人脸认证这一度量学习任务.
余弦 Softmax 交叉损失函数:

(2)基于度量学习的损失函数难以找到合适的采样方法的问题
深度度量学习,通常需要输入一对或者一组样本,在经过一系列的特征变换后输出这些样本之间的距离,使得同样类别的样本之间的距离较小而不同类样本之间的距离较大。相比于基于分类的损失函数,度量学习的损失函数看起来更加适合人脸认证任务,因为人脸认证在测试时也是输入两张图像输出其相似度,这与度量学习的目标函数一致。
然而在实际的训练过程中,度量学习的损失函数普遍存在难调参、难收敛的情况,这其中一部分原因是度量学习损失只关心局部,而丢弃掉了全局监督信号;另一部分原因是训练度量学习损失模型通常需要采样样本对或样本组来训练,而目前人脸识别的数据规模较大,通常达到百万到上亿量级。度量学习损失往往无法采样完全,比如说如果使用 Contrastive 损失则需要采样 个样本组合,使用 Triplet损失则需要采样
个样本组合,这在目前的大型数据库下几乎是不可能实现的任务,这样庞大的样本组合内其实也有大量的样本组是已经满足了度量学习要求的,不需要再次进行训练。所以研究者们提出要使用难例挖掘的办法来进行采样,而这一过程往往需要引入一些超参数也需要很多技巧。
而基于分类的损失函数只需要不断地将样本输入进网络即可,其样本复杂度只有 O(N),而且一般也不需要难例挖掘。论文《基于深度学习的人脸认证方法研究》直接提出将度量学习的损失函数改造成为分类损失函数,以降低其对样本采样的要求。论文提出了“类代理”的概念,通过给每个类别分配一个类代理,就可以将多样本之间距离度量的学习转换为一个样本对多个类代理之间
距离度量的学习,从而避免了样本采样带来的问题。
最常用的深度度量学习方法有 Contrastive 损失:
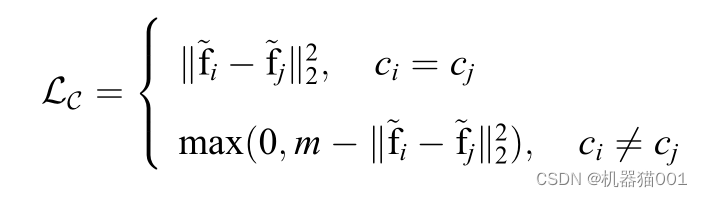
和 Triplet 损失:

其中这两个 m 都表示类间间隔。这两个方法都是在优化归一化后的两个特征向量的欧氏距离,注意到归一化后的欧氏距离与余弦距离之间有如下关系:

利用这个公式,将前文的余弦 Softmax 损失函数改写为优化归一化后的欧氏距离的形式:
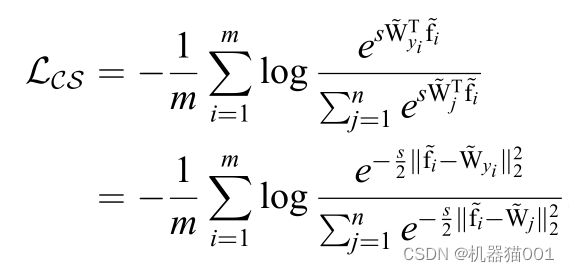
在使用了类代理(用一个类似于权重的向量,来代替各类样本)之后,就可以得到分类版本的Contrastive 损失( C-Contrastive 损失):
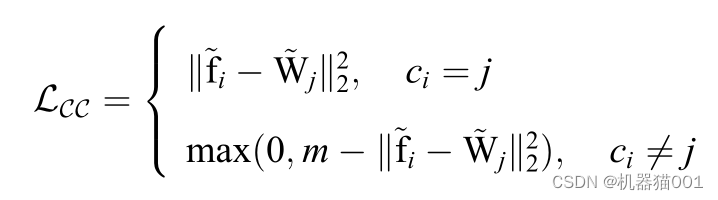
和 分类版本的Triplet 损失( C-Triplet 损失):
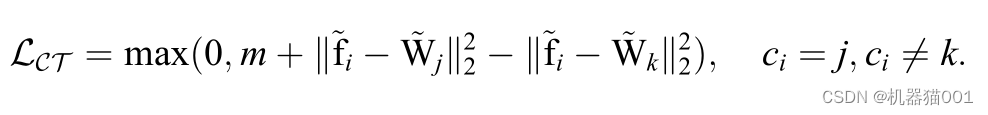
C-Contrastive 损失函数在两类、三维球面情况下,类代理与类中心之间关系的示意图如下:
(a) m = 0 时的情况;(b)m = 1 时的情况(可变类间间隔 m)















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









