







一、基本概念
给你一张图片如下,左边是犰狳,右边是穿山甲,然后给你一张Query让判断是犰狳还是穿山甲。大多数人分辨不出,但是如果你给人看图片,则正常人都能正确分类,那么计算机可以像人一样作出正确分类吗?如果每一类只有一两张个样本,那么计算机可以像人一样作出正确分类吗?
对于下图的例子,有两类,每一类有两个样本,仅有四张照片,不可能训练一个深度神经网络。因此,对于小样本问题,不能用传统方法分类。
注:Support set很小

小样本学习和传统监督学习不同,它的目标不是让你识别训练集中的目标,并泛化到测试集中。它的目标是自己学会学习。即学习的目的是学习事物之间的异同。
比如下图中训练集没有松鼠,但是模型可以发现事物的异同,来进行判断两张图片是不是同一种东西。


如下图,有一张Query图片,问神经网络这是什么东西,但是训练集中没有,所以神经网络无法给出判断。假如多给神经网络一些信息,support set,此时神经网络拿Query图片与support set中的六张图片依次对比,找出最相似的。
注意:support set和training set的区别:training set很大,每一类下面都有很多图片,足够大可以用来训练深度神经网络。support set很小,每一类下面只有少数图片,不足以训练一个大的神经网络,只能在做预测的时候提高一些额外信息。

用足够大的训练集训练一个大模型,如深度神经网络,训练的目的不是识别训练集中的事物类别,而是让模型知道事物之间的异同现在靠support set中的一点信息,可以判断出Query是什么东西,尽管训练集中没有这个东西。
Meta Learning:learn to learn
如下图,小朋友没有见过这种动物,但是小朋友有区分能力,你给他一些动物卡片,小朋友既不认识图上的动物,也不认识卡片上的动物,但是他把卡片翻一遍,就能知道看到的是什么动物,判断的依据是两种动物长得很像。培养小盆友自主学习,就是Meta Learning。

传统监督学习和小样本学习的比较
传统监督学习——首先用训练集训练模型,训练好之后用模型来对测试图片进行预测,这张图片虽然没有出现在训练集里面,但是类别(哈士奇)包含在训练集中,并且里面有上百张哈士奇的图片,所以模型很容易判断出这张图片是哈士奇。

小样本学习——模型不仅没有见过这张图片,而且训练集中没有兔子这个类别。所以要给模型提供更多信息support set,通过比较Query和support set中图片的相似度来判断是什么。

常用术语:k-way:the suppport set has k classes n-shot:every class has n samples
比如:
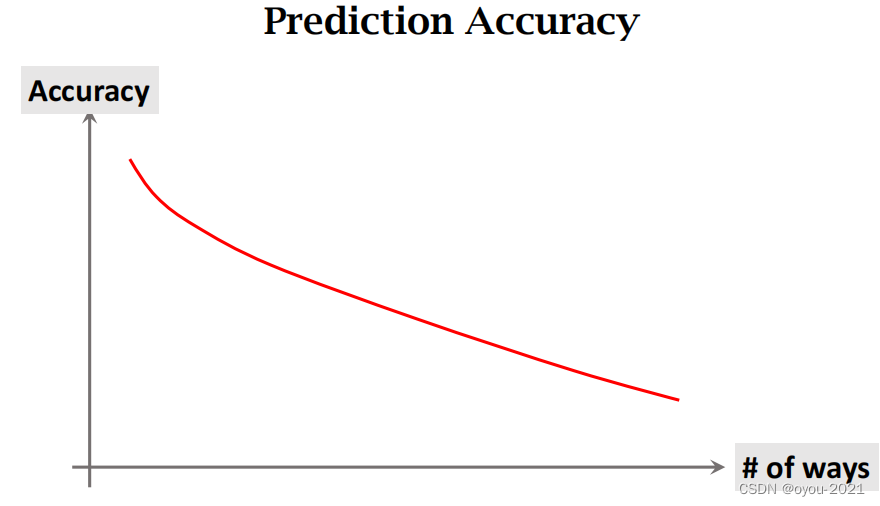
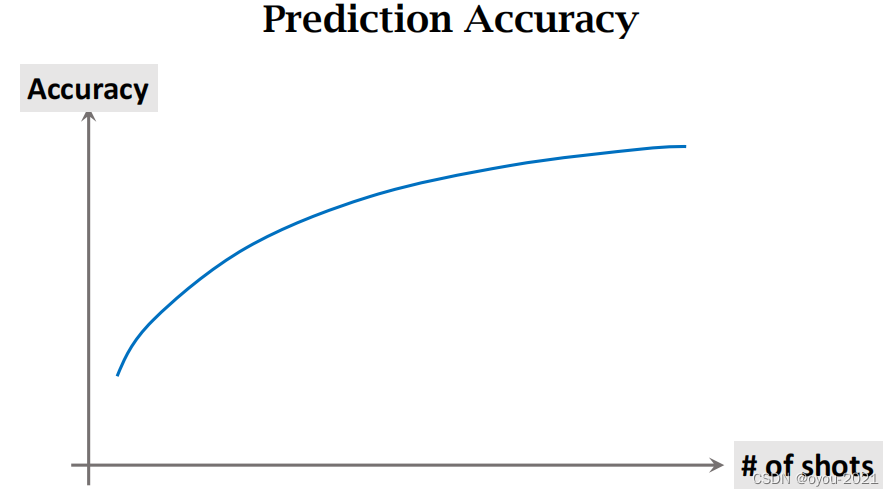
看一下sho和way变化和accuracy的关系
很显然,小朋友从三个类别里判断比从七个类别里判断容易。从多样本里判断比从少样本里容易
Idea:learn a similarity function
相似度,sim(x1,x2)=1相同类别,sim(x1,x3)=0不同类别

怎么实现
1、从一个很大的训练集上学习一个相似度函数,可以判断相似度有多高
2、训练结束之后,用学到的相似度函数进行预测,相似度最高的作为预测结果

常用数据集


二、Siamese Network(孪生网络)
介绍训练Siamese Network两种方法,都是先在一个大的训练集上训练孪生网络,让孪生网络知道学习事物之间的异同,训练结束后,那孪生网络做few-shot learning预测。
第一种: 每次取两个样本,比较它们的相似度。
需要有一个大的有标注的分类数据训练集,然后构造正样本和负样本。
正样本:告诉什么东西是同一类 。每次从训练集中随机抽取一张图片,然后在同一类别下抽取另一张图片,相似度为1,代表类别相同。
负样本:告诉事物之间的区别。每次从训练集中随机抽取一张图片,然后在除了这个类别从数据集随机抽取另一张图片,相似度为0,代表类别不同。

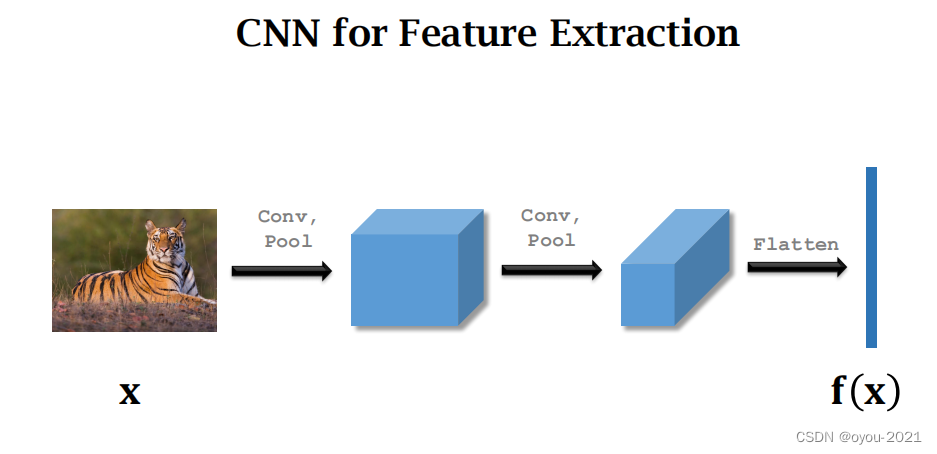
搭一个卷积神经网络来提取特征
输入是一张图片,输出是一个特征向量
开始训练,输入是类别相同的两张图片,即标签为1
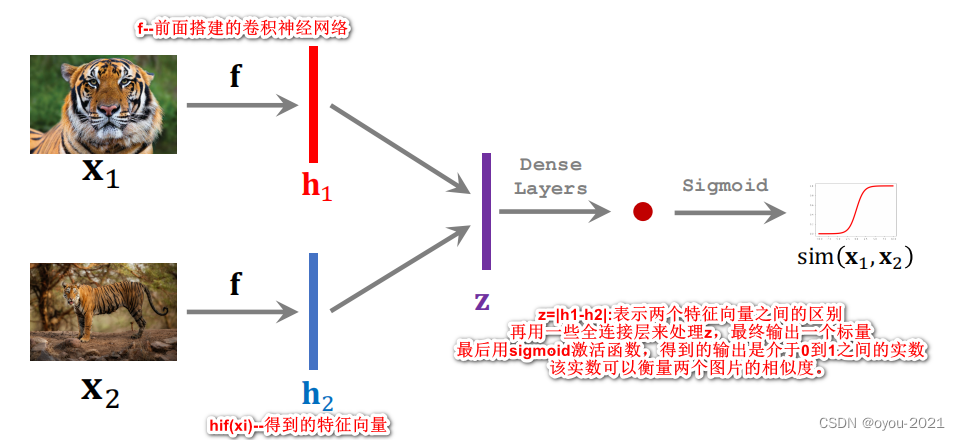
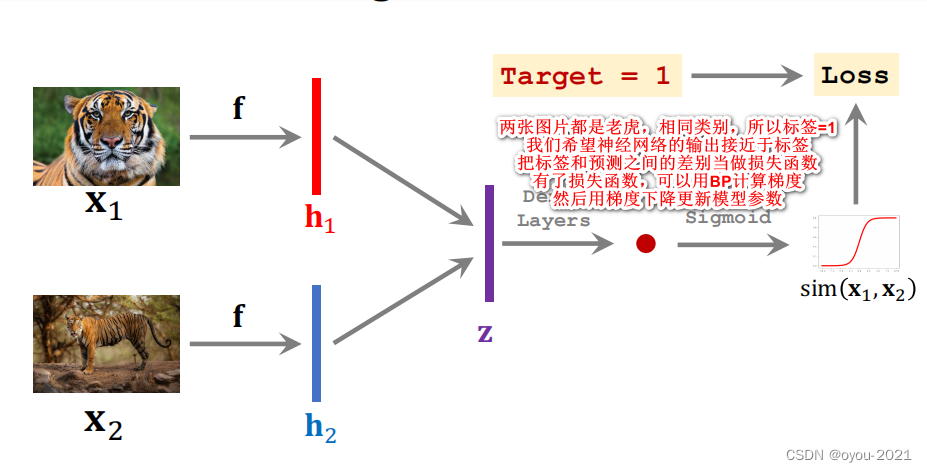
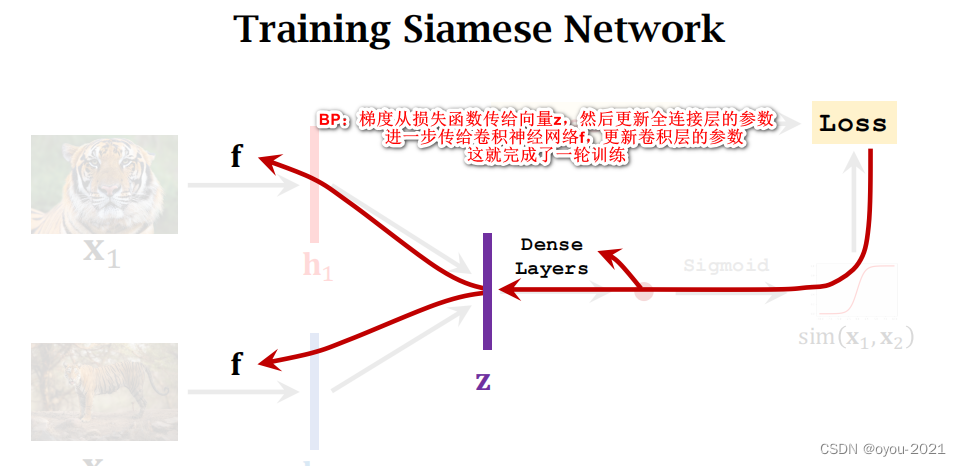
注意:训练过程中,要准备同样数量的正样本和负样本
训练好模型之后可以用来做one-shot prediction

第二种:Triplet Loss
每次从训练集中选择三张图片做一轮训练,首先从训练集中随机选取一张图片,比如下图中的老虎,把它作为anchor,记录下这个锚点,然后从相同类别中选取一张图片作为正样本并记录下,再排除这个类别,随机从数据库中选取一张图片作为负样本。

接下来将上面所得到的三张图片,输入到卷积神经网络提取特征,得到三个特征向量,计算正样本(负样本)与锚点在特征空间上的距离 。我们希望训练出来的神经网络中,相同类别的特征向量聚在一起,不同类别的特征向量分开,所以d+应很小,d-应很大。
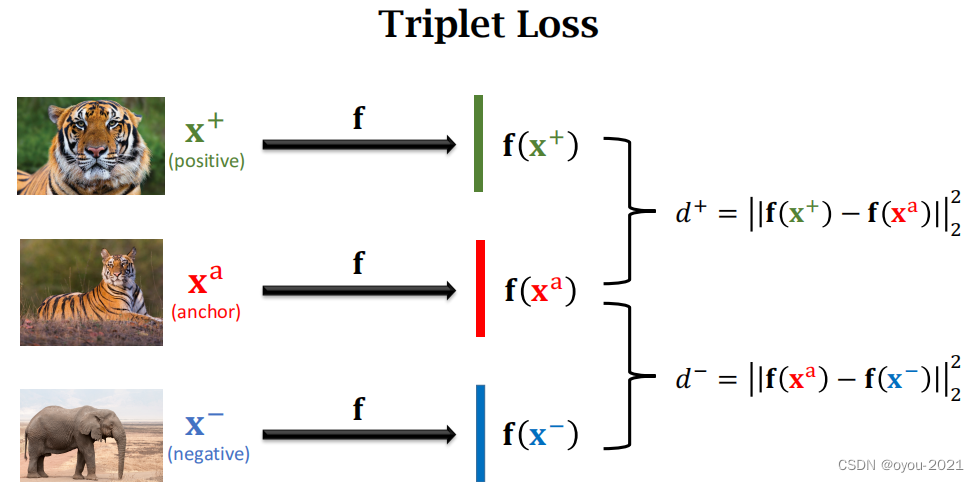
注意:下图中的坐标系是特征空间,卷积神经网络可以将图片映射到特征空间中
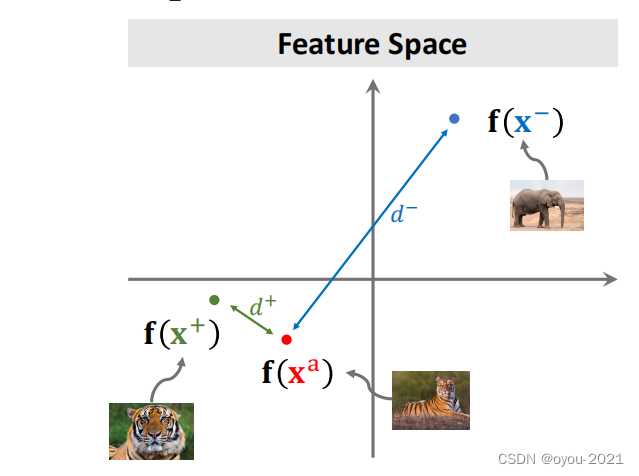
接下来,我们来分析损失函数

例子
 三、Pretraining and Fine Tuning
三、Pretraining and Fine Tuning
基本思想:大规模数据集上预训练模型,然后在小规模数据集上微调。
先介绍一些数学知识
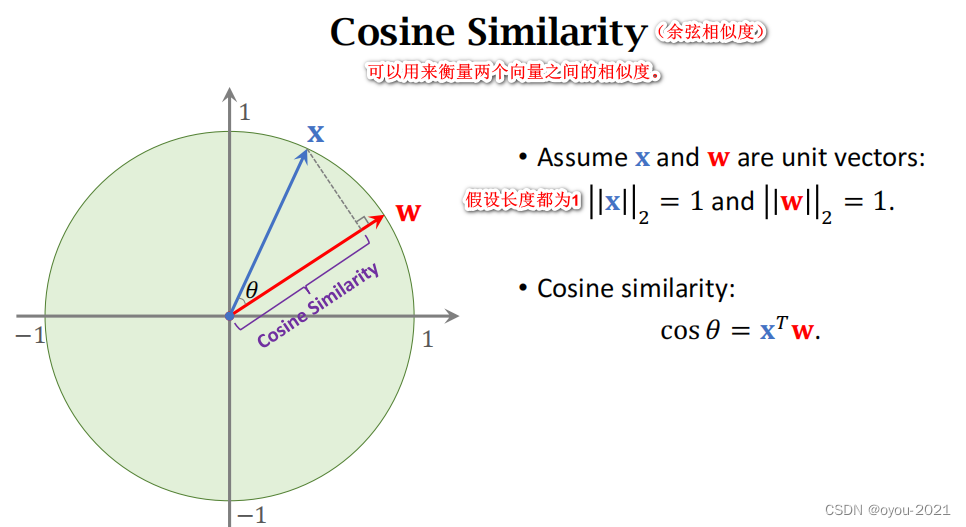
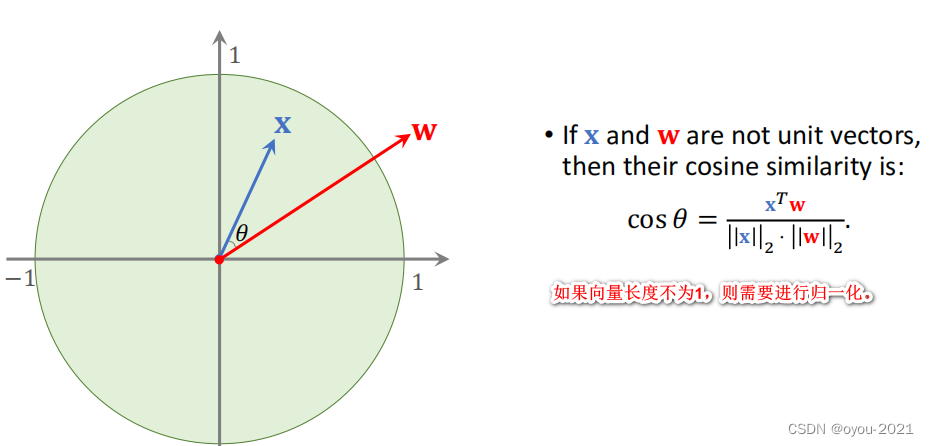
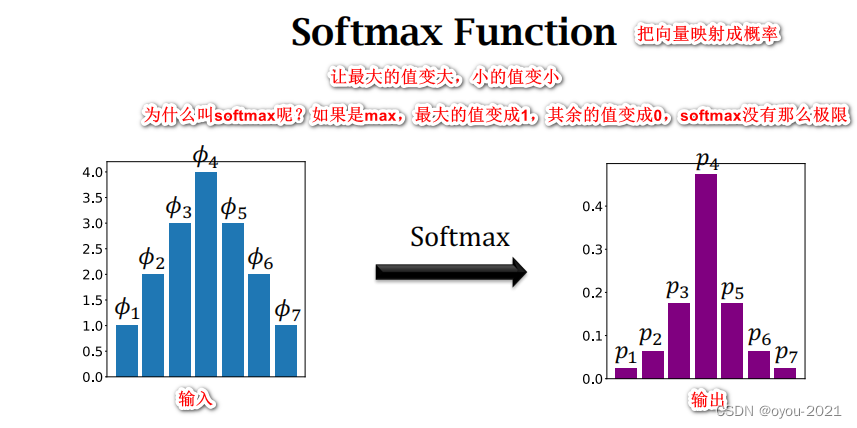
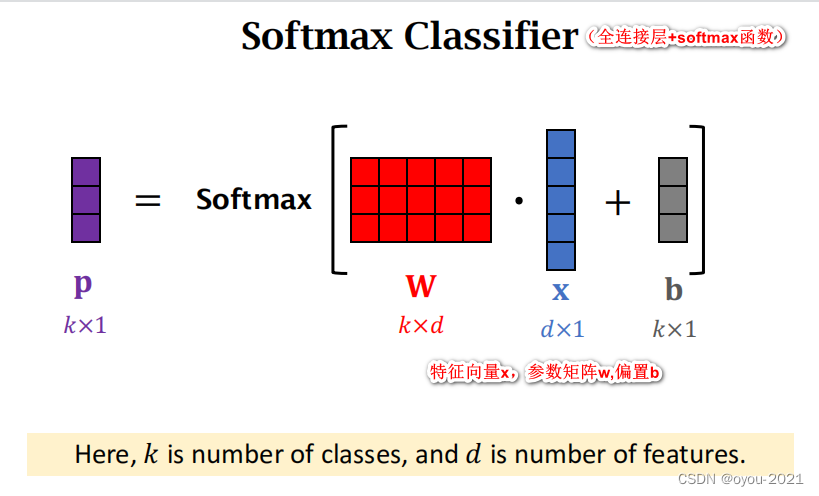
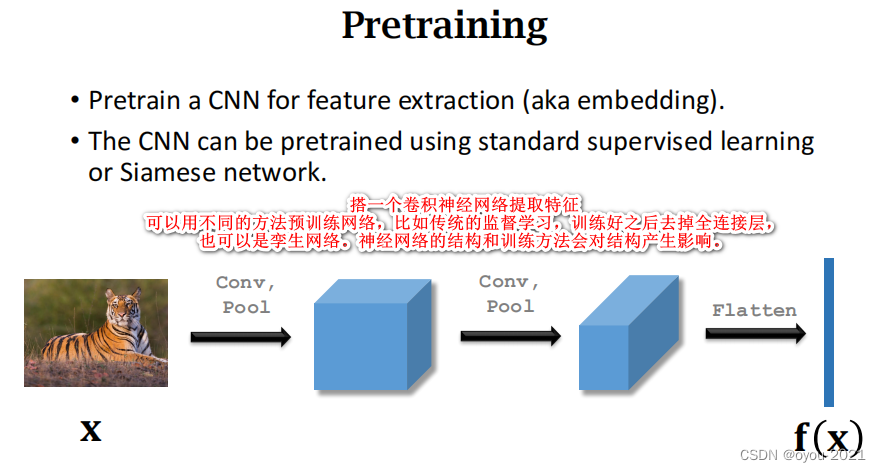
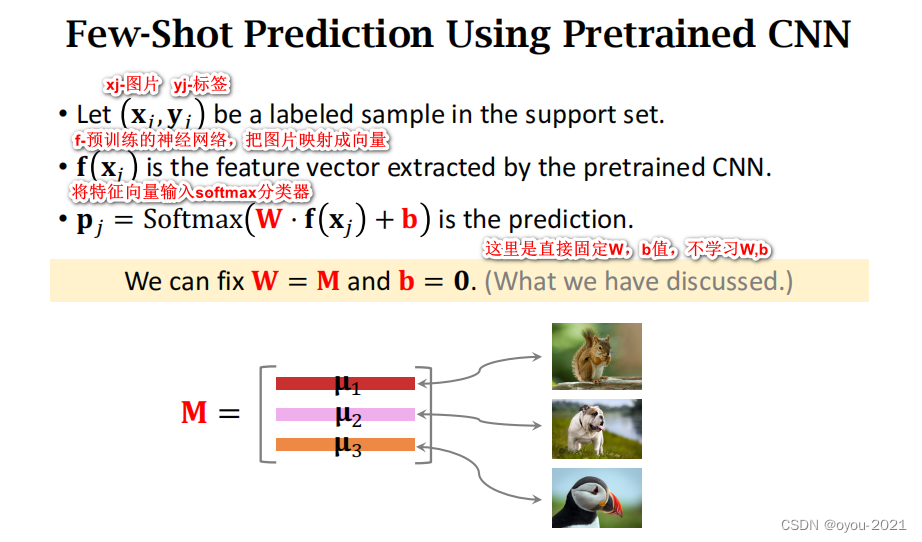
Few-Shot Prediction Using Pretrained CNN
Pretraining
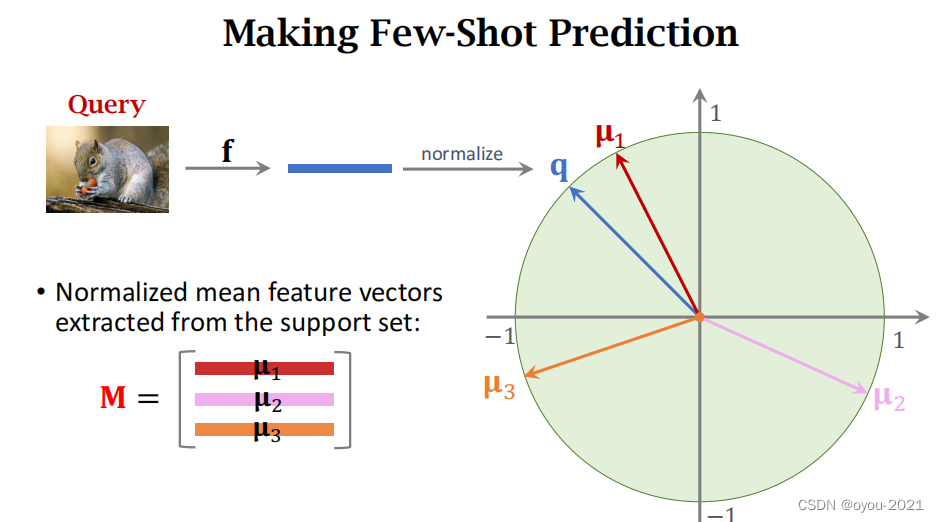
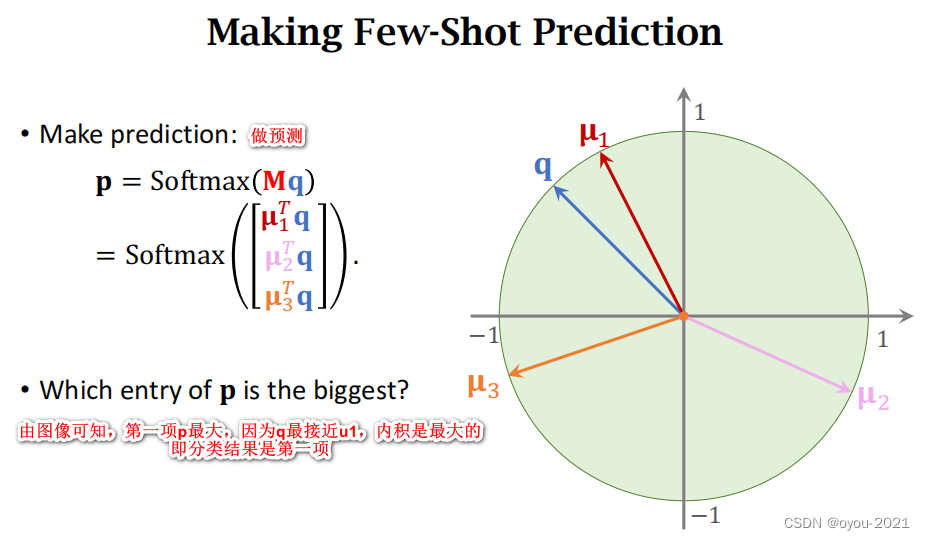
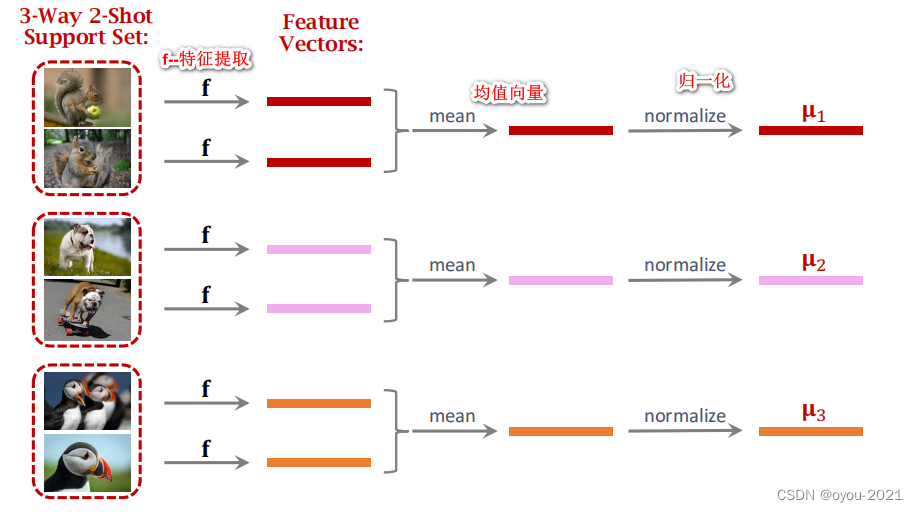 对Query进行预测
对Query进行预测
Fine-Tuning
做完预训练之后可以做微调,能够进一步提高预测准确率。
未加入微调预测小样本步骤
加入微调的小样本预测

一些技巧
1、一个好的初始化
初始化很重要,support set的样本很少,如果随机初始化学习的参数效果并不好,可以将W=M b=0作为初始化,因为如果不做训练,也可以有一定的效果。

2、加入正则化防止过拟合

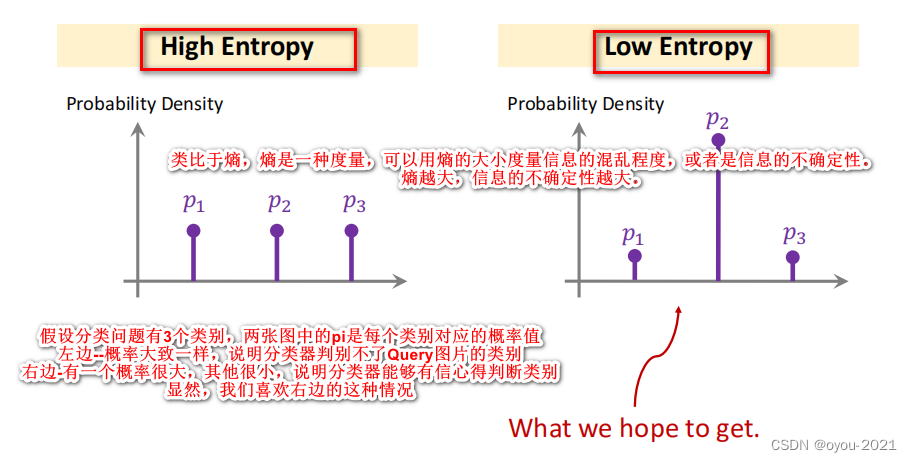
3、结合余弦相似度和分类器(可以显著提高准确度)
 总结
总结
解决小样本分类问题最简单的方法就是预训练一个神经网络,然后用它提取特征,比较相似度,作出分类

可以往中间增加一个微调,使准确度得到提高
















 9万+
9万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









