






选自arXiv
作者:AXEL SAUER 机器之心编译 编辑:蛋酱
StyleGAN-XL 首次在 ImageNet 上实现了 1024^2 分辨率图像合成。
近年来,计算机图形学领域的研究者一直致力于生成高分辨率的仿真图像,并经历了一波以数据为中心的真实可控内容创作浪潮。其中英伟达的 StyleGAN 在图像质量和可控性方面为生成模型树立了新的标杆。
但是,当用 ImageNet 这样的大型非结构化数据集进行训练时,StyleGAN 还不能取得令人满意的结果。另一个存在的问题是,当需要更大的模型时,或扩展到更高的分辨率时,这些方法的成本会高得令人望而却步。
比如,英伟达的 StyleGAN3 项目消耗了令人难以想象的资源和电力。研究者在论文中表示,整个项目在 NVIDIA V100 内部集群上消耗了 92 个 GPU year(即单个 GPU 一年的计算)和 225 兆瓦时(Mwh)的电力。有人说,这相当于整个核反应堆运行大约 15 分钟。
最初,StyleGAN 的提出是为了明确区分变量因素,实现更好的控制和插值质量。但它的体系架构比标准的生成器网络更具限制性,这些限制似乎会在诸如 ImageNet 这种复杂和多样化的数据集上训练时带来相应代价。
此前有研究者尝试将 StyleGAN 和 StyleGAN2 扩展到 ImageNet [Grigoryev et al. 2022; Gwern 2020],导致结果欠佳。这让人们更加相信,对于高度多样化的数据集来说,StyleGAN 可能会从根本上受到限制。
受益于更大的 batch 和模型尺寸,BigGAN [Brock et al. 2019] 是 ImageNet 上的图像合成 SOTA 模型。最近,BigGAN 的性能表现正在被扩散模型 [Dhariwal and Nichol 2021] 超越。也有研究发现,扩散模型能比 GAN 实现更多样化的图像合成,但是在推理过程中速度明显减慢,以前的基于 GAN 的编辑工作不能直接应用。
此前在扩展 StyleGAN 上的失败尝试引出了这样一个问题:架构约束是否从根本上限制了基于 Style 的生成器,或者 missing piece 是否是正确的训练策略。最近的一项工作 [Sauer et al. 2021] 引入了 Projected GAN,将生成和实际的样本投射到一个固定的、预训练的特征空间。重组 GAN 设置这种方式显著改进了训练稳定性、训练时间和数据效率。然而,Projected GAN 的优势只是部分地延伸到了这项研究的单模态数据集上的 StyleGAN。
为了解决上述种种问题,英伟达的研究者近日提出了一种新的架构变化,并根据最新的 StyleGAN3 设计了渐进式生长的策略。研究者将改进后的模型称为 StyleGAN-XL,该研究目前已经入选了 SIGGRAPH 2022。

论文地址:https://arxiv.org/pdf/2202.00273.pdf
代码地址:https://github.com/autonomousvision/stylegan_xl
这些变化结合了 Projected GAN 方法,超越了此前在 ImageNet 上训练 StyleGAN 的表现。为了进一步改进结果,研究者分析了 Projected GAN 的预训练特征网络,发现当计算机视觉的两种标准神经结构 CNN 和 ViT [ Dosovitskiy et al. 2021] 联合使用时,性能显著提高。最后,研究者利用了分类器引导这种最初为扩散模型引入的技术,用以注入额外的类信息。
总体来说,这篇论文的贡献在于推动模型性能超越现有的 GAN 和扩散模型,实现了大规模图像合成 SOTA。论文展示了 ImageNet 类的反演和编辑,发现了一个强大的新反演范式 Pivotal Tuning Inversion (PTI)[ Roich et al. 2021] ,这一范式能够与模型很好地结合,甚至平滑地嵌入域外图像到学习到的潜在空间。高效的训练策略使得标准 StyleGAN3 的参数能够增加三倍,同时仅用一小部分训练时间就达到扩散模型的 SOTA 性能。
这使得 StyleGAN-XL 能够成为第一个在 ImageNet-scale 上演示 1024^2 分辨率图像合成的模型。
将 StyleGAN 扩展到 ImageNet

实验表明,即使是最新的 StyleGAN3 也不能很好地扩展到 ImageNet 上,如图 1 所示。特别是在高分辨率时,训练会变得不稳定。因此,研究者的第一个目标是在 ImageNet 上成功地训练一个 StyleGAN3 生成器。成功的定义取决于主要通过初始评分 (IS)[Salimans et al. 2016] 衡量的样本质量和 Fréchet 初始距离 (FID)[Heusel et al. 2017] 衡量的多样性。
在论文中,研究者也介绍了 StyleGAN3 baseline 进行的改动,所带来的提升如下表 1 所示:
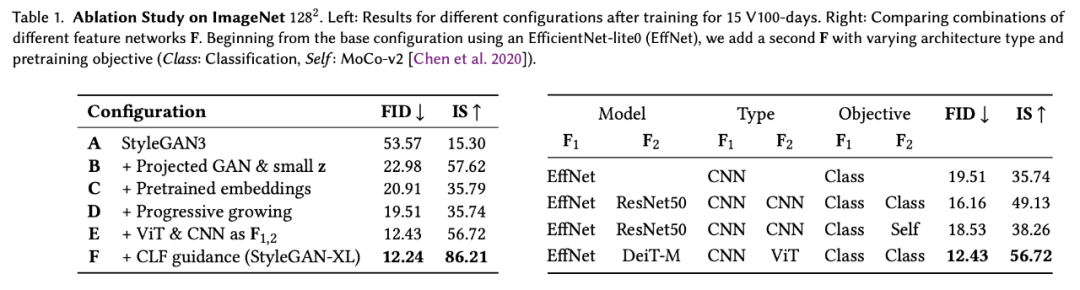
研究者首先修改了生成器及其正则化损失,调整了潜在空间以适应 Projected GAN (Config-B) 和类条件设置 (Config-C);然后重新讨论了渐进式增长,以提高训练速度和性能 (Config-D);接下来研究了用于 Projected GAN 训练的特征网络,以找到一个非常适合的配置 (Config-E);最后,研究者提出了分类器引导,以便 GAN 通过一个预训练的分类器 (Config-F) 提供类信息。
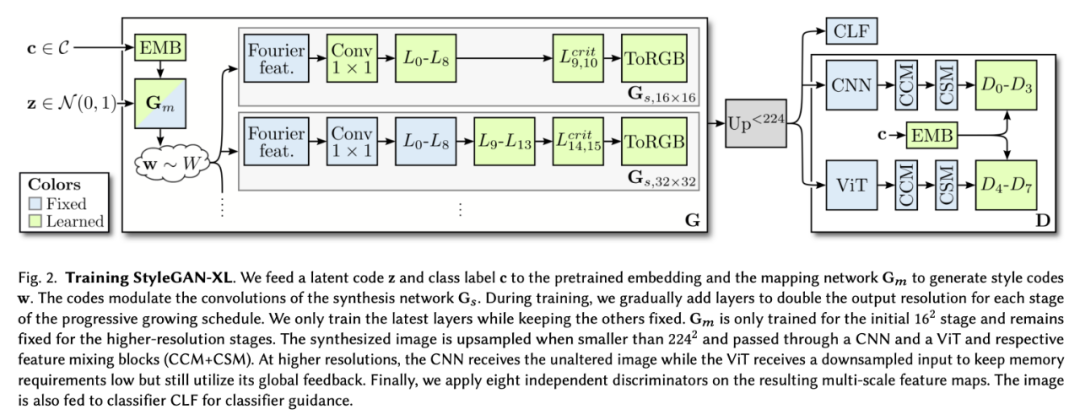
这样一来,就能够训练一个比以前大得多的模型,同时需要比现有技术更少的计算量。StyleGAN-XL 在深度和参数计数方面比标准的 StyleGAN3 大三倍。然而,为了在 512^2 像素的分辨率下匹配 ADM [Dhariwal and Nichol 2021] 先进的性能,在一台 NVIDIA Tesla V100 上训练模型需要 400 天,而以前需要 1914 天。(图 2)。
实验结果
在实验中,研究者首先将 StyleGAN-XL 与 ImageNet 上的 SOTA 图像合成方法进行比较。然后对 StyleGAN-XL 的反演和编辑性能进行了评价。研究者将模型扩展到了 1024^2 像素的分辨率,这是之前在 ImageNet 上没有尝试过的。在 ImageNet 中,大多数图像的分辨率较低,因此研究者用超分辨率网络 [Liang et al. 2021] 对数据进行了预处理。
图像合成
如表 2 所示,研究者在 ImageNet 上对比了 StyleGAN-XL 和现有最强大的 GAN 模型及扩散模型的图像合成性能。
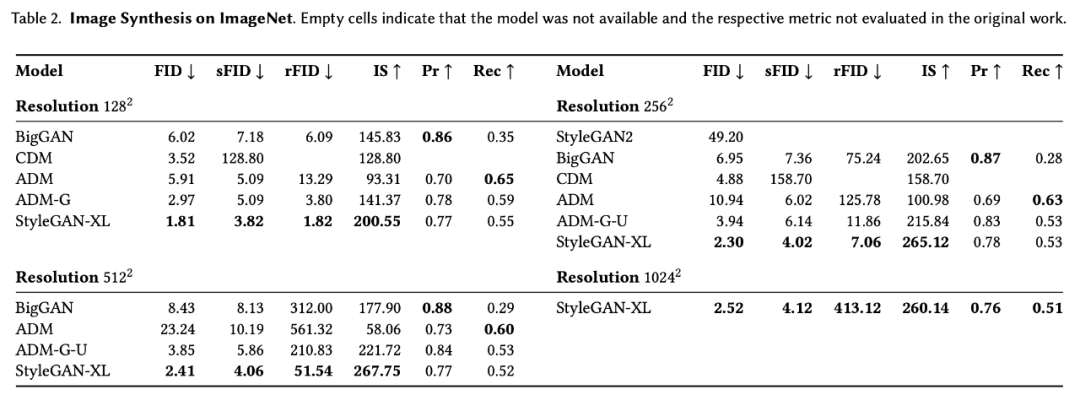
有趣的是,StyleGAN-XL 在所有分辨率下都实现了高度的多样性,这可以归功于渐进式生长策略。此外,这种策略使扩大到百万像素分辨率的合成变成可能。
在 1024^2 这一分辨率下,StyleGAN-XL 没有与 baseline 进行比较,因为受到资源限制,且它们的训练成本高得令人望而却步。
图 3 展示了分辨率提高后的生成样本可视化结果。

逆映射和可控编辑
同时,还可以进一步细化所得到的重构结果。将 PTI [Roich et al. 2021] 和 StyleGAN-XL 相结合,几乎可以精确地反演域内 (ImageNet 验证集) 和域外图像。同时生成器的输出保持平滑,如下图 4 所示。

图 5、图 6 展示了 StyleGAN-XL 在图像操纵方面的性能:


更多细节可参考原论文。
猜您喜欢:

附下载 |《TensorFlow 2.0 深度学习算法实战》
















 459
459











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









