






本文来源机器之心 作者:王浩帆、王奇勋
本文从实际存在的问题出发,对代码框架不兼容、模型加载受限等问题率先提出了自研解决方案,快速帮助开发者更容易地开发。
在 ChatGPT 出圈不久,ControlNet 的横空出世很快在英文和中文互联网收获了众多开发者和普通用户,甚至有用户宣传 ControlNet 的出现将 AI 创作带入了直立行走的时代。不夸张地说,包括 ControlNet 在内,同期的 T2I-Adapter、Composer, 以及 LoRA 训练技巧,可控生成作为 AI 创作最后一道高墙,极有可能在可预见的时间内有进一步突破,从而极大地降低用户的创作成本,提高创作的可玩性。距离 ControlNet 开源仅仅过去两周,其官方 Star 就已经超过 1 万,这种热度无疑是空前的。
与此同时,开源社区也极大地降低了用户的使用门槛,如 Hugging Face 平台提供了基础模型权重以及通用的模型训练框架 diffusers,stable-diffusion-webui 开发了完善的一套 Demo 平台,Civitai 贡献了海量风格化 LoRA 权重。

尽管 webui 作为目前最受欢迎的可视化工具,已经快速地支持了近期推出的各种生成模型,并且支持众多选项供用户设置。由于其重点考虑了前端界面的易用性,背后代码结构其实十分复杂,对于开发者而言不够友好。比如 webui 尽管支持了多种类型的加载和推理,但却无法支持不同框架下的转换,也无法支持模型的灵活训练。我们在社区讨论中发现了许多现有开源代码暂未解决的痛点。
首先,代码框架不兼容,目前热门的模型,如 ControlNet、T2I-Adapter,与主流的 Stable Diffusion 训练库 diffusers 不兼容,ControlNet 预训练的模型无法直接在 diffusers 框架中被使用。
其次,模型加载受限,目前模型保存格式多样,如.bin、.ckpt、.pth、.satetensors 等,除了 webui 外,目前 diffusers 框架对于这些模型格式的支持还有限,考虑到 LoRA 大部分模型以 safetensors 保存为主,用户很难直接将 LoRA 的模型加载到已有的基于 diffusers 框架训练的模型中。
第三,基础模型受限,目前 ControlNet、T2I-Adapter 均基于 Stable-Diffusion-1.5 进行训练,且仅开源了 SD1.5 下的模型权重,考虑到特定场景,已经存在诸如 anything-v4、ChilloutMix 等优质动漫模型,即使引入了可控信息,最终生成结果仍然受限于 SD1.5 中 UNet 的能力。
最后,模型训练受限,目前 LoRA 已经被广泛验证是风格迁移、保持特定形象 IP 最有效的方法之一,但 diffusers 框架目前仅支持 UNet 的 LoRA 嵌入,无法支持 text encoder 的嵌入,会限制 LoRA 的训练。
我们和开源社区讨论后,了解到 diffusers 框架作为通用代码库,正计划同时适配近期不断推出的生成模型;由于涉及较多底层接口重写,仍然需要一段时间更新。为此,我们从以上实际存在的问题出发,率先提出了对于每一个问题的自研解决方案,快速帮助开发者更容易地开发。
LoRA、ControlNet、T2I-Adapter 到 diffusers 的全适配方案
LoRA for diffusers
本方案是为了在 diffusers 框架,即基于 diffusers 训练保存的模型中,灵活嵌入各种格式的 LoRA 权重。由于 LoRA 的训练通常冻结 base model,因此可以作为可插拔模块轻松嵌入已有模型,作为风格或 IP 条件约束。LoRA 本身是一种通用的训练技巧,它的基本原理是,通过低秩分解,可以极大地减少模块的参数量,目前在图像生成中,一般用于训练独立于 base model 外的可插拔模块,实际使用是以残差形式与 base model 的输出合并。
首先是 LoRA 权重的嵌入,目前 Civitai 平台上提供的权重主要以 ckpt 或 safetensors 格式存储,分以下两种情况。
(1)Full model(base model + LoRA 模块)
如果 full model 是 safetensors 格式,可以通过以下 diffusers 脚本转换
python ./scripts/convert_original_stable_diffusion_to_diffusers.py --checkpoint_path xxx.safetensors --dump_path save_dir --from_safetensors如果 full model 是 ckpt 格式,可以通过以下 diffusers 脚本转换
python ./scripts/convert_original_stable_diffusion_to_diffusers.py --checkpoint_path xxx.ckpt --dump_path save_dir转换完成后,可直接利用 diffusers 的 API 进行模型加载
from diffusers import StableDiffusionPipeline
pipeline = StableDiffusionPipeline.from_pretrained (save_dir,torch_dtype=torch.float32)(2)LoRA only (仅包含 LoRA 模块)
目前 diffusers 官方无法支持仅加载 LoRA 权重,而开源平台上的 LoRA 权重基本以这种形式存储。本质上是完成 LoRA 权重中 key-value 的重新映射,使其适配到 diffusers 模型中。为此,我们自行支持这个功能,提供了转换脚本。
pipeline = StableDiffusionPipeline.from_pretrained (model_id,torch_dtype=torch.float32)
model_path = "onePieceWanoSagaStyle_v2Offset.safetensors"
state_dict = load_file (model_path)只需要指定 diffusers 格式的模型,以及存储为 safetensors 格式的 LoRA 权重。我们提供了一个转换示例。
# the default mergering ratio is 0.75, you can manually set it
python convert_lora_safetensor_to_diffusers.py此外,LoRA 本身由于其轻量化,可以在小数据情况下快速完成训练,并能够嵌入到其他网络中。为了不局限于已有 LoRA 权重,我们在 diffusers 框架中支持了 LoRA 的多模块(UNet+text encoder)训练,并已经在官方代码库提交 PR(https://github.com/huggingface/diffusers/pull/2479),并支持了 ColossalAI 中训练 LoRA。
代码开源在:https://github.com/haofanwang/Lora-for-Diffusers
ControlNet for diffusers
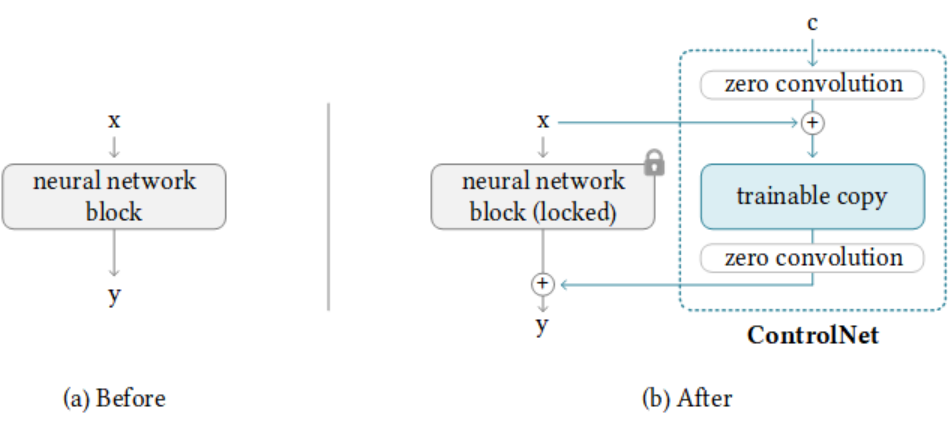
本方案是为了支持在 diffusers 框架中,使用 ControlNet。基于开源社区的部分尝试,我们提供了完整的 ControlNet+Anything-V3 使用用例,支持将 base model 从原本 SD1.5 的替换到 anything-v3 模型,使 ControlNet 具备较好动漫生成的能力。
此外,我们也支持 ControlNet+Inpainting,并提供了适配 diffusers 的 pipeline,
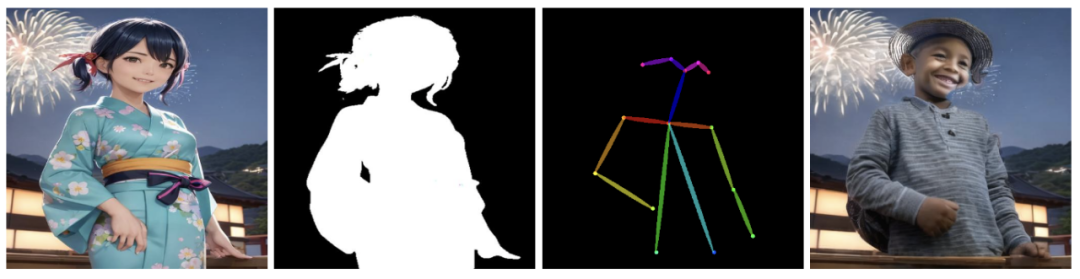

以及多条件控制的 Multi-ControlNet。

代码开源在:https://github.com/haofanwang/ControlNet-for-Diffusers
T2I-Adapter for diffusers
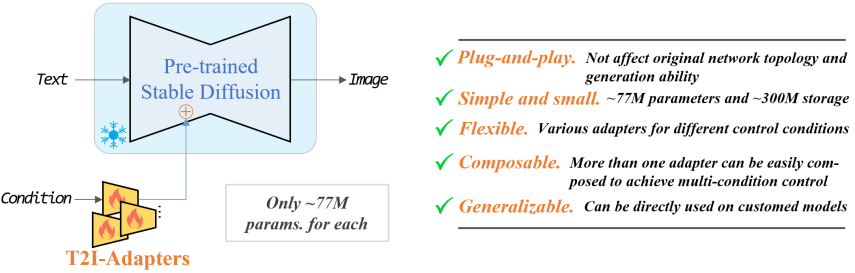
与 ControlNet 相似,我们也同时支持了同期开源的 T2I-Adapter 到 diffusers 的适配。
代码开源在:https://github.com/haofanwang/T2I-Adapter-for-Diffusers
目前以上三种适配方案均已经向社区开源,并在 ControlNet、T2I-Adapter 中被官方分别致谢,也收到了来自 stable-diffusion-webui-colab 作者的感谢。我们正在与 diffusers 官方保持讨论,会在近期完成以上方案向官方代码库的集成工作。也欢迎大家提前尝试我们的工作,有任何问题均可以直接提 issue,我们会尽快回复。
猜您喜欢:
深入浅出stable diffusion:AI作画技术背后的潜在扩散模型论文解读

最新最全100篇汇总!生成扩散模型Diffusion Models
附下载 |《TensorFlow 2.0 深度学习算法实战》
《礼记·学记》有云:独学而无友,则孤陋而寡闻
欢迎加入 GAN/扩散模型 —交流微信群 !
扫描下面二维码,添加运营小妹好友,拉你进群。发送申请时,请备注,格式为:研究方向+地区+学校/公司+姓名。如 扩散模型+北京+北航+吴彦祖

请备注格式:研究方向+地区+学校/公司+姓名
点击 一顿午饭外卖,成为CV视觉的前沿弄潮儿!,领取优惠券,加入 AI生成创作与计算机视觉 知识星球!















 823
823











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









