







目录
题目来源:计算机二级Python半个月抱佛脚大法(内呈上真题版) - 知乎
存档一下复习进度
1.基本题
1.1 基本题1
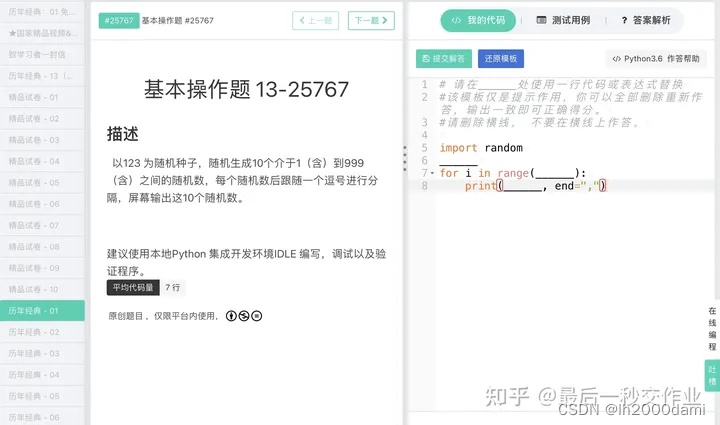
randint(a,b) 返回随机整数N满足 a<=N<=b,是包含b在内的
import random
random.seed(123)
for i in range(10):
print(random.randint(1,999),end=",")1.2 基本题2
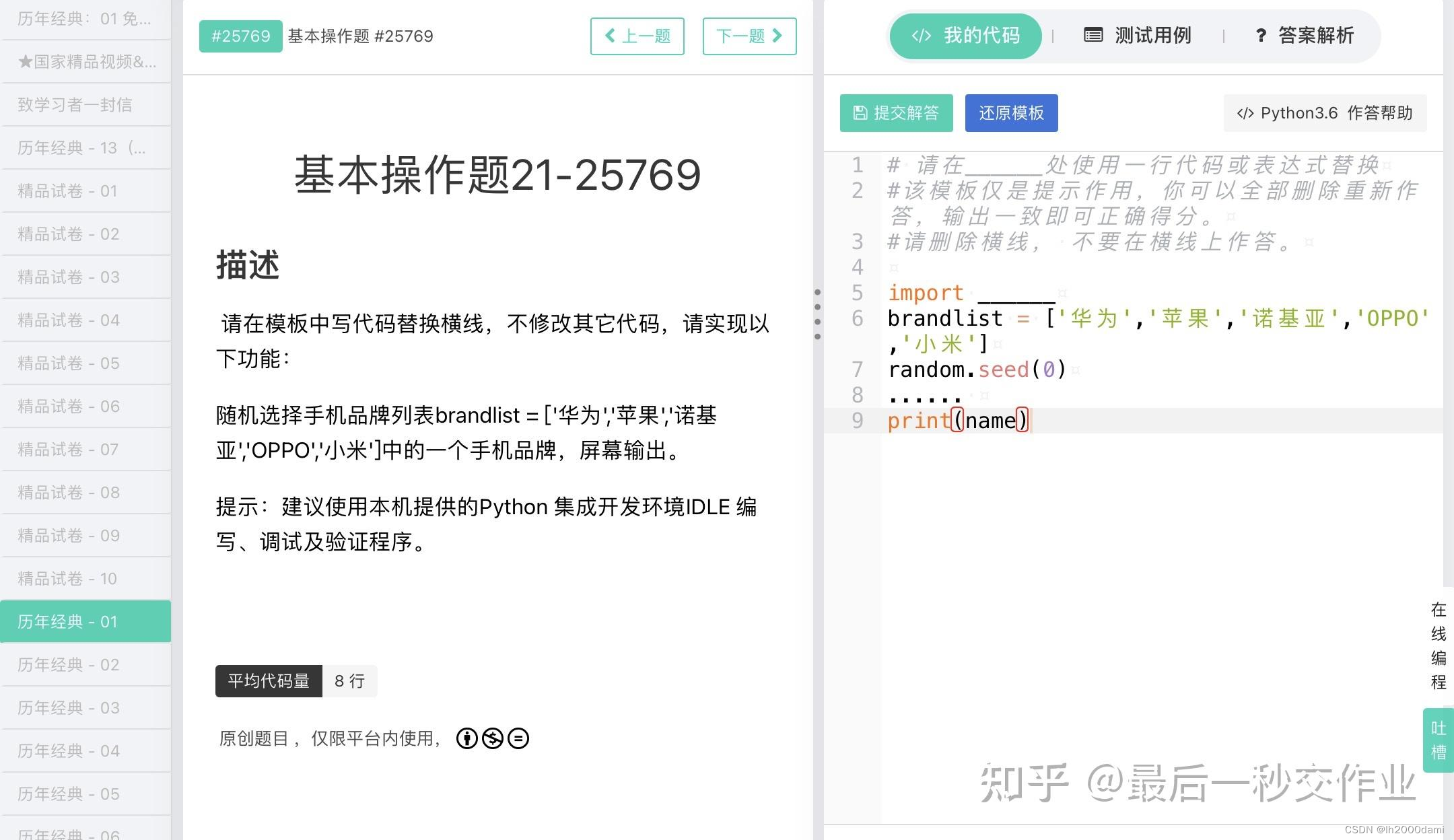
import random
brandlist=['华为','苹果','诺基亚','OPPO','小米']
random.seed(0)
name=random.choice(brandlist)
print(name)import random
brandlist=['华为','苹果','诺基亚','OPPO','小米']
random.seed(0)
i=random.randint(0,4)
name=brandlist[i]
print(name)1.3 基本题3
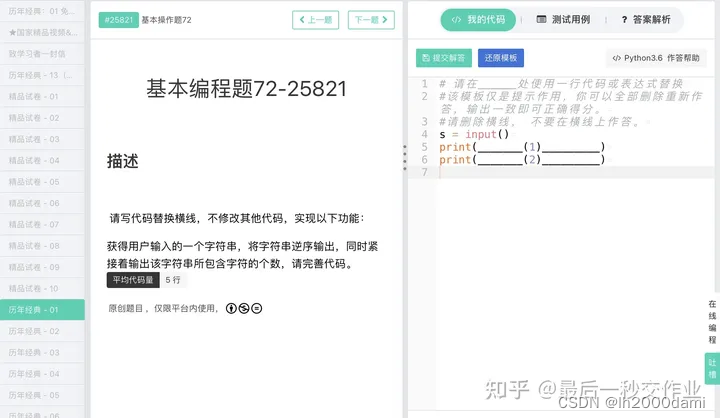
s=input()
print(s[::-1],end="")
print(len(s))2. 简单应用题或turtle绘图题

import turtle
turtle.pensize(2)
for i in range(4):
turtle.fd(200)
turtle.left(90)
turtle.left(-45)
turtle.circle(100*pow(2,0.5))3. 大题
3.1 大题1
第一问:
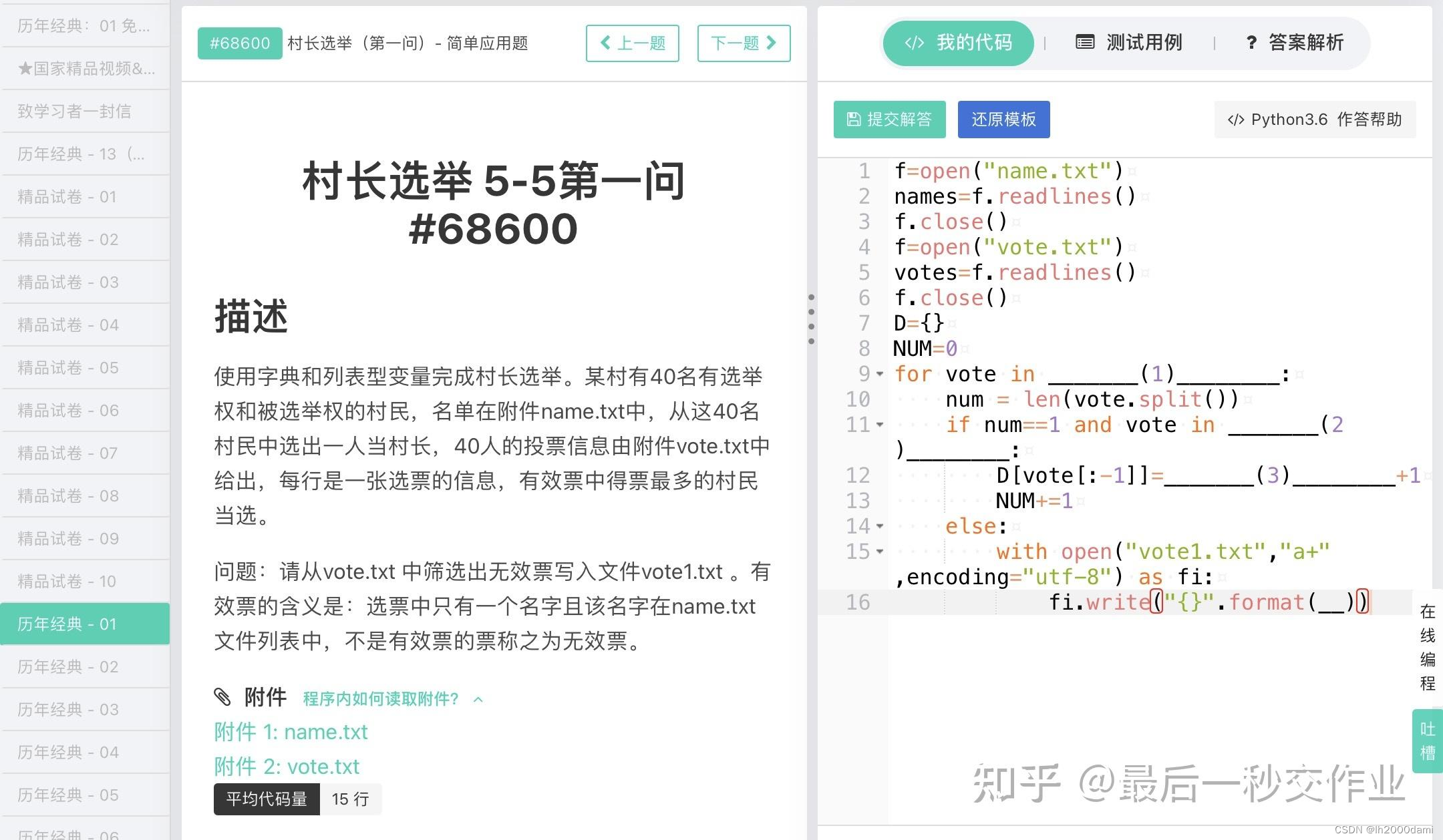
f=open("name.txt",encoding="utf-8")
names=f.readlines() #读入文件所有行,以每行为元素形成列表
f.close()
f=open("vote.txt",encoding="utf-8")
votes=f.readlines()#读入文件所有行,以每行为元素形成列表
f.close()
D={} #建立空字典
NUM=0
for vote in votes:
num=len(vote.split())
if num==1 and vote in names: #分解成列表,并求列表长度(元素个数)
D[vote[:-1]]=D.get(vote[:-1],0)+1
NUM+=1
else:
with open("vote1.txt","a+",encoding="utf-8") as fi:
fi.write("{}".format(vote))第二问:

f=open("name.txt",encoding="utf-8")
names=f.readlines() #读入文件所有行,以每行为元素形成列表
f.close()
f=open("vote.txt",encoding="utf-8")
votes=f.readlines()#读入文件所有行,以每行为元素形成列表
f.close()
D={} #建立空字典
NUM=0
for vote in votes:
num=len(vote.split())
if num==1 and vote in names: #分解成列表,并求列表长度(元素个数)
D[vote[:-1]]=D.get(vote[:-1],0)+1
NUM+=1
l=list(D.items())#将字典类型转变为列表类型
l.sort(key=lambda s:s[1],reverse=True)
name=l[0][0]
score=l[0][1]
print("有效票数为:{}当选的村民为:{},票数为:{}".format(NUM,name,score))3.2 大题2
第一问:
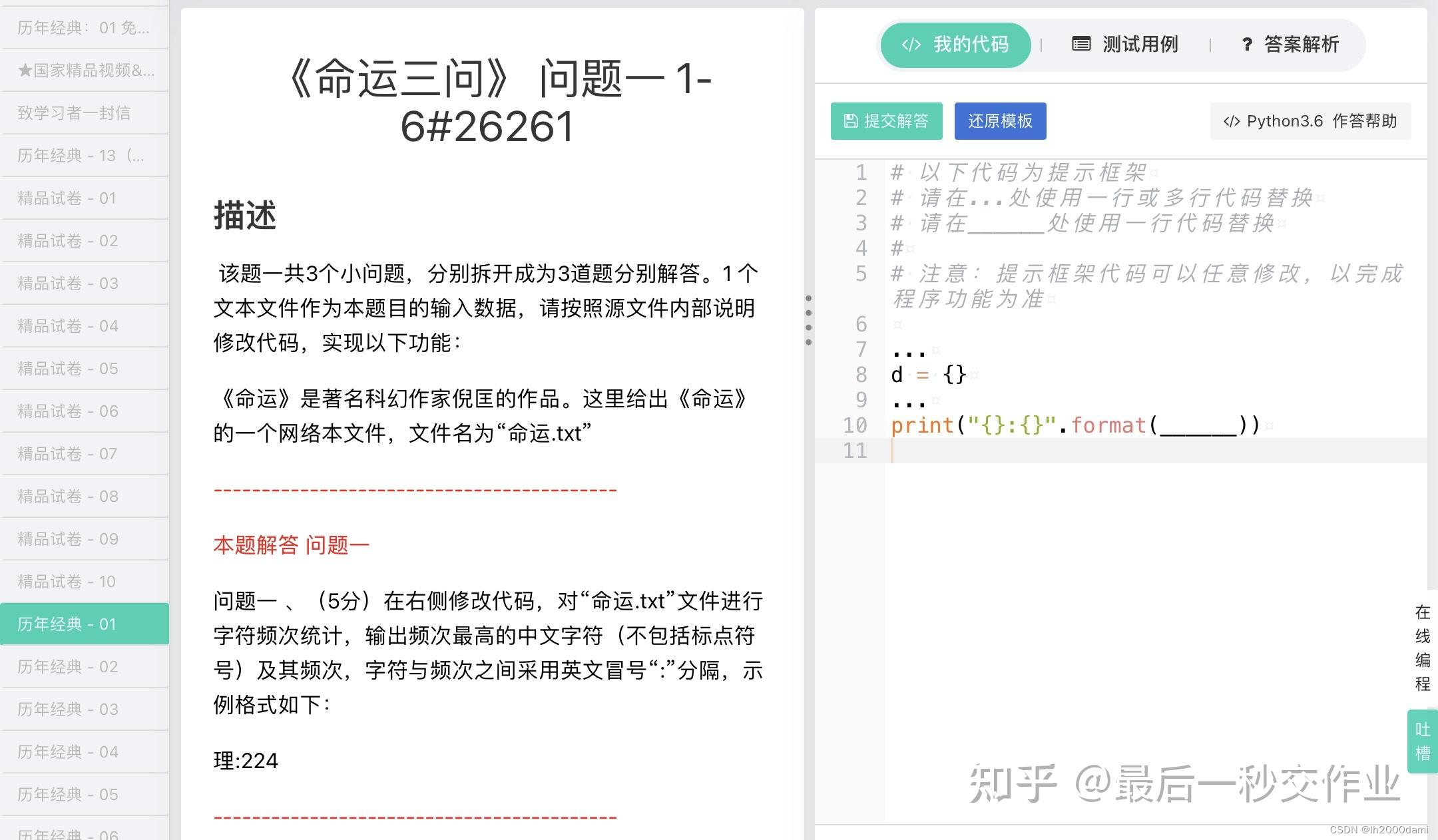
txt=open("命运.txt","r",encoding="utf-8").read()
for ch in ',。?:“《》()、!□——.':
txt=txt.replace(ch,"")
d={}
for ch in txt:
d[ch]=d.get(ch,0)+1
ls=list(d.items())
ls.sort(key=lambda x:x[1],reverse=True)
a,b=ls[0]
print("{}:{}".format(a,b))
第二问:
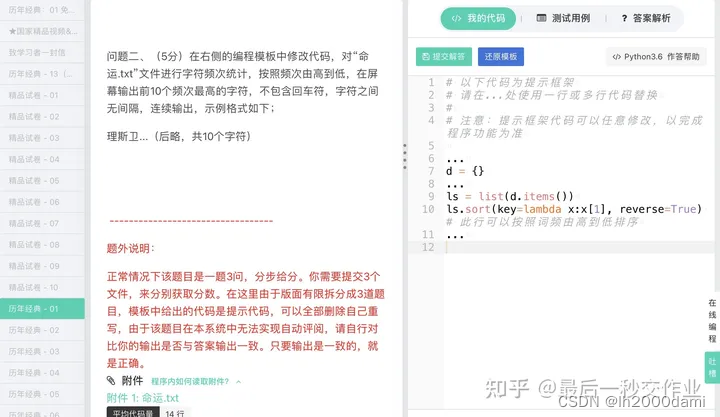
txt=open("命运.txt",'r',encoding="utf-8").read()
for ch in '\n':
txt=txt.replace(ch,"")
d={}
for word in txt:
d[word]=d.get(word,0)+1
ls=list(d.items())
ls.sort(key=lambda x:x[1],reverse=True)
for i in range(10):
print("{}".format(ls[i][0]),end="")
#或者print(str(ls[i])[2],end="")
str(ls[i])[2] 表示取出 ls[i] 元组中的第三个字符(索引为2),因为 ls[i] 是一个元组,形式为 (字符, 频率),例如 ('a', 5)。通过 str(ls[i]) 将这个元组转换为字符串后,我们使用 [2] 来取字符串的第三个字符
第三问:
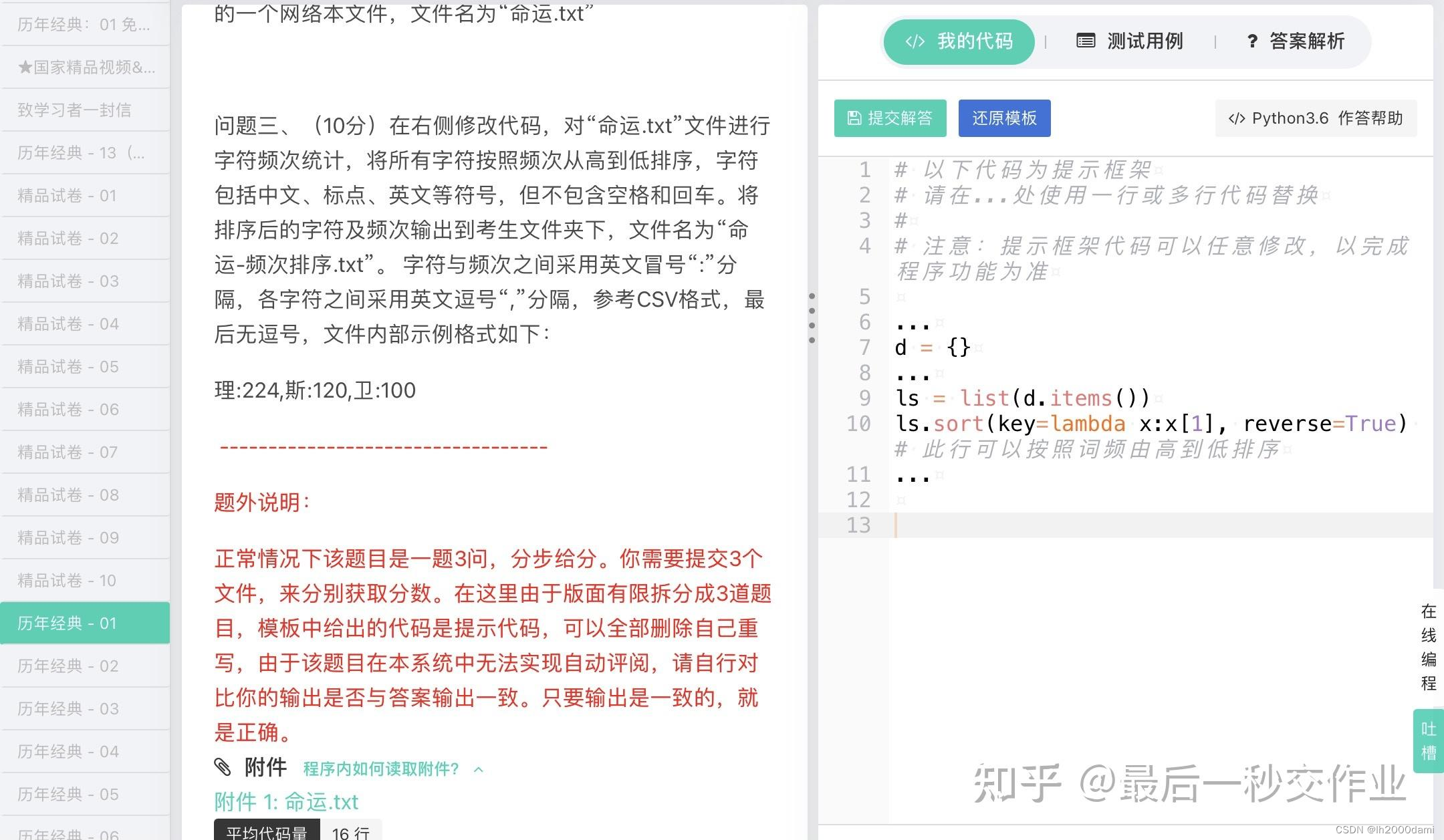
f=open("命运.txt",'r',encoding="utf-8")
txt=f.read()
for ch in " \r":
txt=txt.replace(ch,"")
d={}
for word in txt:
d[word]=d.get(word,0)+1
ls=list(d.items())
ls.sort(key=lambda x:x[1],reverse=True)
string=""
for i in range(len(ls)):
s=str(ls[i]).strip("()")
if i<len(ls)-1:
string=string+s[1]+':'+s[5:]+','
else:
string=string+s[1]+':'+s[5:]
f=open("命运-频次排序.txt","w",encoding="utf-8")
f.write(string)
f.close()
s=str(ls[i]).strip("()") 的作用具体来说:
-
str(ls[i])将元组ls[i]转换为字符串。 -
.strip("()")方法去掉字符串两端的括号()。
例如,如果 ls[i] 的值是 ('a', 5),那么 str(ls[i]) 将返回字符串 ('a', 5),然后 .strip("()") 方法将去掉字符串两端的括号,最终得到 'a', 5。















 2241
2241











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









