







一、GAs遗传算法简介
在计算机人工智能领域,遗传算法算法是模拟自然选择过程的启发式搜索,这种启发式(有时也被称做元启发式)通常用于产生优化和搜索的问题有用的解。遗传算法属于更大类别进化算法的一种,这类算法使用自然进化技术如继承、变异、选择和交叉获得优化问题的解。
在机器学习上一个有用的观点是学习作为搜索问题,不同的学习方法用不同的搜索策略和潜在的需要搜索的假设空间结构进行特征化。在遗传算法中假设经常是用位字符串进行描述,具体的解释依赖于具体的应用,除此之外也可以用符合表达式甚至是计算机程序表示。从一个初始假设的种群(集合)开始搜索一个合适假设,当前种群的成员通过模拟生物进化过程包括随机突变和交叉操作产生下一代种群。在每一步,当前种群的假设根据给定的适应值进行进行评估,最适应的假设被概率性的选择作为产生下一代的种子。遗传算法已经被成功的应用到各种学习问题和其他的优化问题,例如,遗传算法已经被用于机器人控制的规则集合学习以及为人工神经网络优化拓扑结构和学习参数。
遗传算法产生后继假设是通过重复的突变和重新组合当前种群中已知的最好的假设,而非从一般——特别的假设或者从简单——复杂的假设。这个过程形成了一个假设的生产——测试的束搜索,其中不变的是当前种群中的最适应的假设是下一个最可能被考虑的。遗传算法流行的原因包括
1.对于在生物系统中适应性进化是已知成功的和鲁棒的方法;
2.遗传算法可以搜索包含复杂交互作用部分的假设空间,其中每一部分对总体假设适应值的影响可能很难模拟;
3.遗传算法很容易并行化,可以利用计算机硬件成本减少的优势。
二、本文遗传算法的4个实现版本
遗传算法的实现版本很多,本文主要介绍4个:
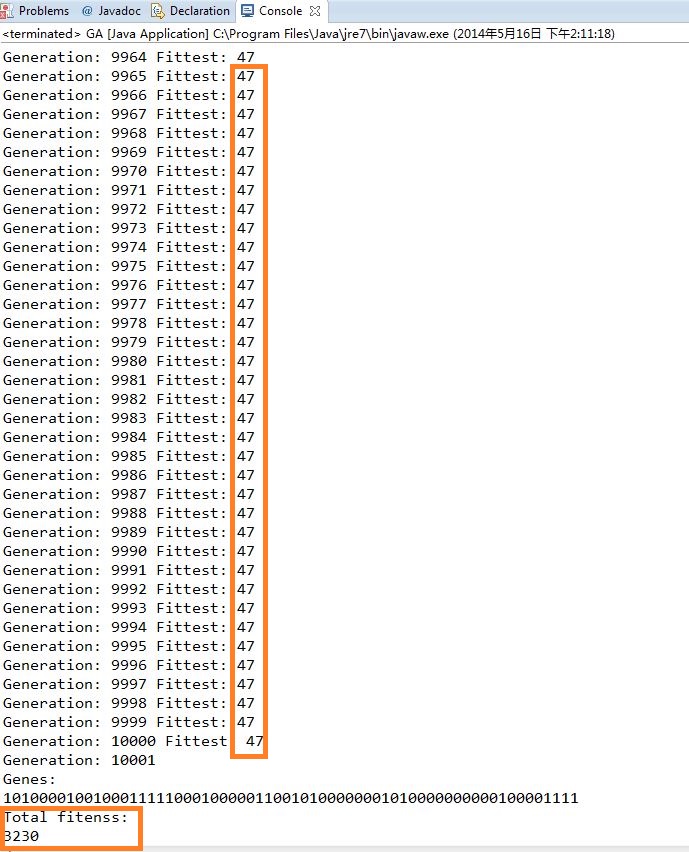
1.MichellAlgorith:《Machine Learning》一书中米切尔叙述的版本,算法首先根据设的定种群大小随机生成一个初始种群,根据预设的适应值计算方法,计算每个假设的适应值;模拟生物进化操作包括选择,交叉和变异;选择根据种群中每个假设的适应值概率性选择固定比例的假设到下一代种群中;交叉是与选择并行进行的,交叉选择的个体也是从原种群中根据假设的适应值概率性的选择,每次选择两个个体进行交叉产生两个后代,交叉的次数等于种群的大小减去选择得到的种群数量除以2,算法实现时可能要进行奇偶数处理;变异是在完成选择和交叉之后得到的新种群上进行的操作,根据米切尔的叙述使用固定比例的突变数目进行突变,这种情况适应于在突变率确定的情况下种群数量较大的情况,在本文实现时采用非固定比例的突变数,概率性的进行突变,这样在种群数量少时也保证了可以有变异操作。
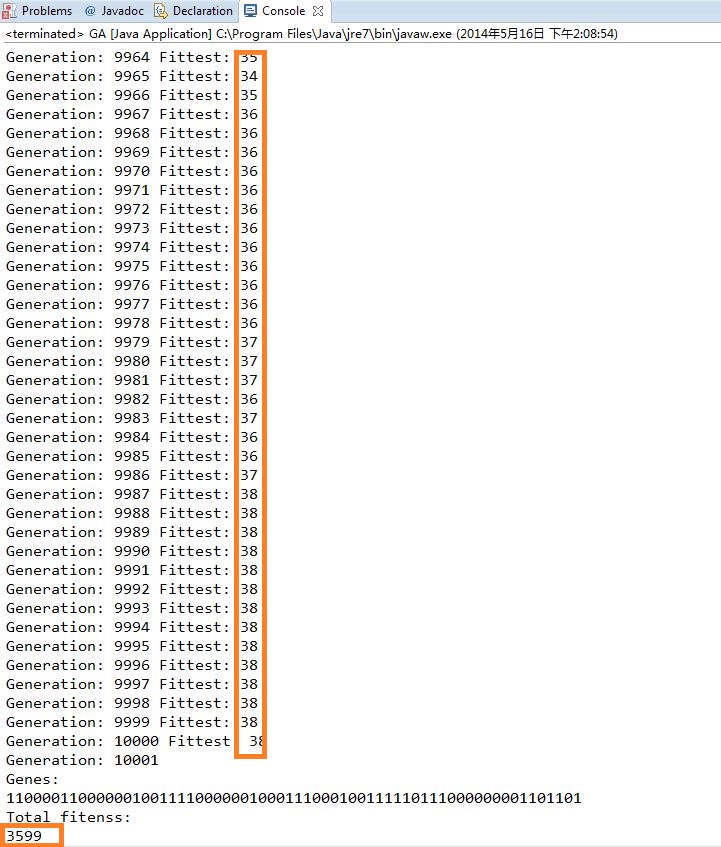
2.PlainAlgorithm:此算法是Matlab中通常被实现的版本,算法的思想主要是在进行选择时选择的数量的等于种群的数量(种群进化前后数量是固定的),之后再得到的种群上进行随机交叉操作,交叉的比例根据预先设定的交叉率;变异操与上述相同是对种群中所有的个体进行变异操作。
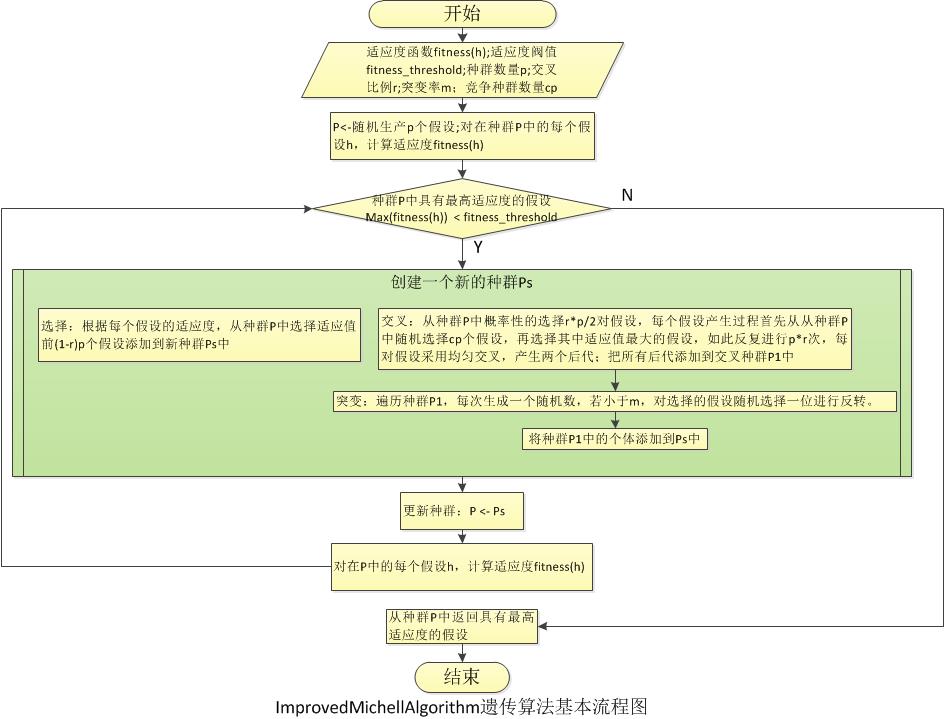
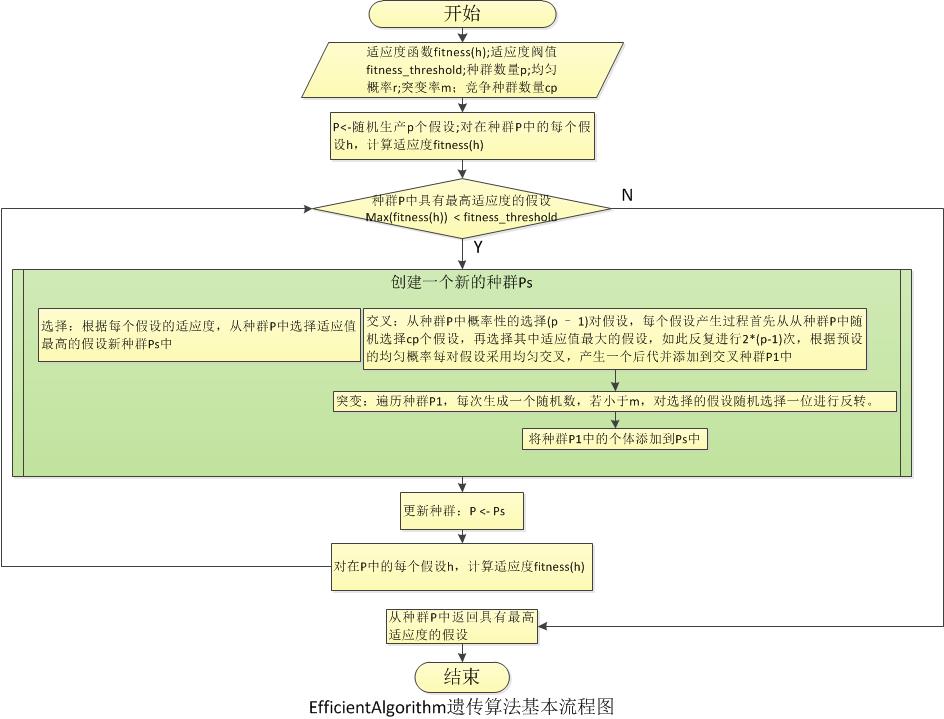
3.ImprovedMichellAlgorithm与EfficientAlgorithm:算法思想基本相同,即是交叉时使用多点均匀交叉,选择是根据预设的比例选择种群中适应值按从大到小排列前面的个体,其中EfficientAlgorithm算法是每次只选择种群中适应值最高的个体作为精英保留,所以算法在实现时简单而有效,交叉一方面是使用多点均匀交叉,另一方面交叉的个体选择是先随机从当前种群中选择指定数目的假设到竞争种群中,在从竞争种群中选择最适应的假设作为交叉的操作的父母,这里ImprovedMichellAlgorithm交叉产生两个后代,而EfficientAlgorithm交叉产生一个后代,所以交叉的次数等于种群数量-1;最后在变异时两种算法都不对保留的精英进行变异操作,这也是称做精英算法的原因,已被证明是一个非常成功的遗传算法改进版本,从本文实验结果也可以解释这一点。
三、UML图和辅助类源代码
1、UML类图
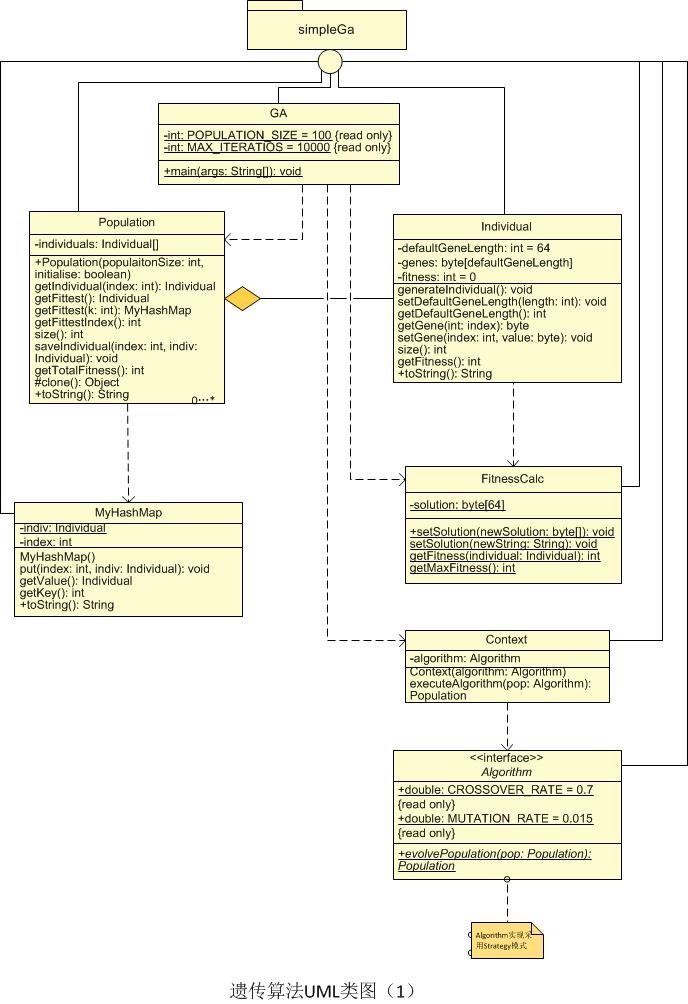
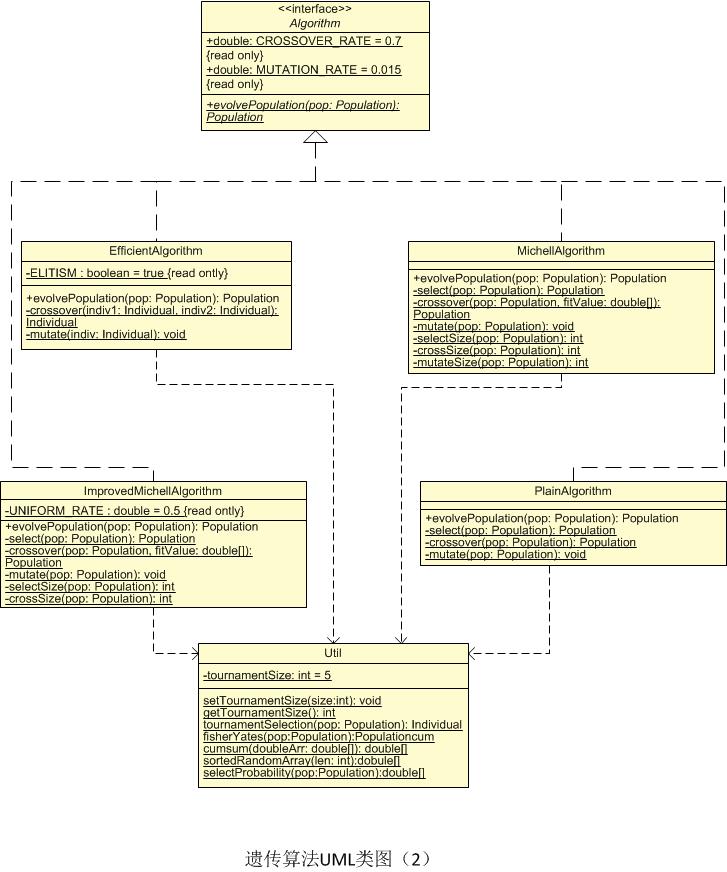
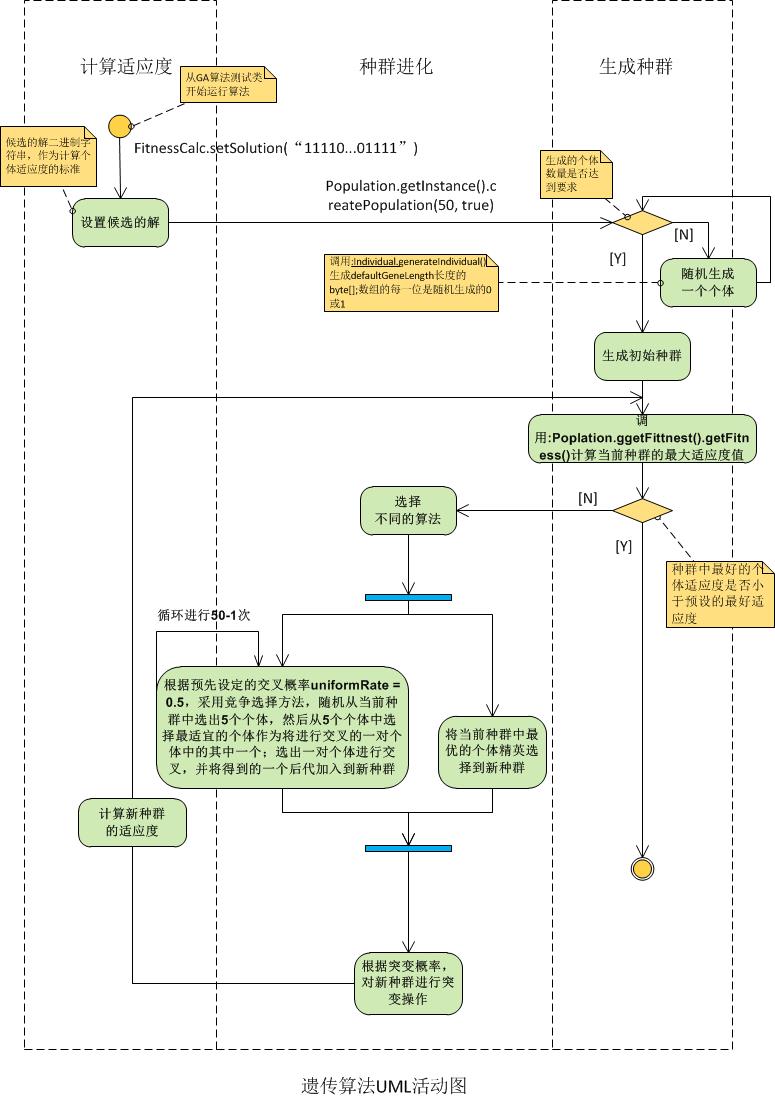
2、UML活动图
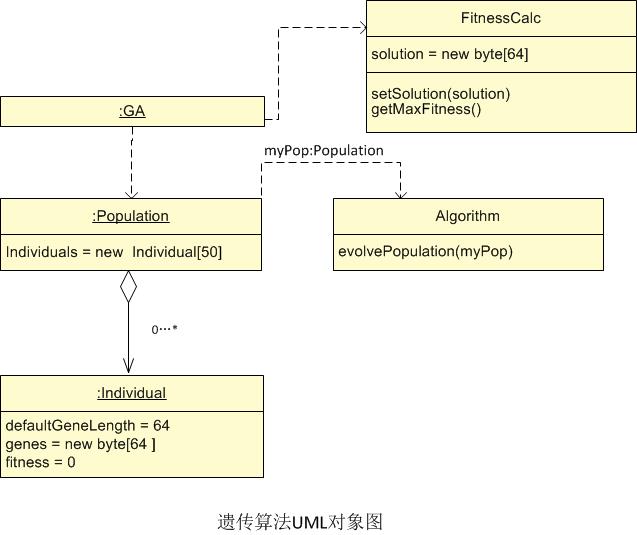
3、UML对象图
3、UML顺序图
4、UML状态图
5、UML协作图
6、UML用例图
1.定义个体的类
package simpleGa;
class Individual {
/** 在public类中使用访问方法,而非公共域 */
private int defalutGeneLength = 64;
private byte[] genes = new byte[defalutGeneLength];
private int fitness = 0;
/** 逐位调用随机发送器,生成一个伪随机二进制个体 */
void generateIndividual() {
byte gene;
for (int i = 0; i < size(); i++) {
gene = (byte)Math.round(Math.random());
genes[i] = gene;
}
}
/** 设置默认的个体基因编码长度 */
void setDefaultGeneLength(int length) {
defalutGeneLength = length;
}
/** 获取预设默认个体基因编码长度 */
int getDefaultGeneLength() {
return defalutGeneLength;
}
/** 获取个体指定位置的基因编码 */
byte getGene(int index) {
return genes[index];
}
/** 设置个体指定位置的基因编码 */
void setGene(int index, byte value) {
genes[index] = value;
}
/** 获取个体编码长度 */
int size() {
return genes.length;
}
/** 计算个体的适应值 */
int getFitness() {
if (fitness == 0)
fitness = FitnessCalc.getFitness(this);
return fitness;
}
/** 覆盖java.lang.Object.toString()方法,获得个体的字符串编码*/
public String toString() {
String geneString = "";
for (int i = 0; i < size(); i++)
geneString += getGene(i);
return geneString;
}
}
package simpleGa;
class Population implements Cloneable {
private Individual[] individuals;
/** 构造器 */
public Population(int populationSize, boolean initialise) {
individuals = new Individual[populationSize];
// 初始化种群
if (initialise) {
//循环创建种群中的所有个体
for (int i = 0; i < size(); i++) {
Individual newIndividual = new Individual();
newIndividual.generateIndividual();
saveIndividual(i, newIndividual);
}
}
}
/** 根据给定的数组索引,返回该位置的个体*/
Individual getIndividual(int index) {
return individuals[index];
}
/** 计算种群中适应值最大的个体 */
Individual getFittest() {
Individual fittest = getIndividual(0);
for (int i = 0; i < size(); i++)
if (fittest.getFitness() < getIndividual(i).getFitness())
fittest = getIndividual(i);
return fittest;
}
/**
* 得到种群中从位置k开始的适应值最高的个体;
* 连续调用此方法得到前n个适应值最大的个体是时需要保持原种群的秩序
*/
MyHashMap getFittest(int k) {
Individual fittest = getIndividual(k);
int index = k;
//生产一个MyHashMap,用于存放最大适应值的索引——个体键值对
MyHashMap myHashMap = new MyHashMap();
for (int i = k; i < size(); i++)
if (fittest.getFitness() < getIndividual(i).getFitness()) {
fittest = getIndividual(i);
index = i;
}
myHashMap.put(index, fittest);
return myHashMap;
}
/** 计算种群中最适应的个体的索引位置 */
int getFittestIndex() {
Individual fittest = getIndividual(0);
int index = 0;
for (int i = 0; i < size(); i++) {
if (fittest.getFitness() < getIndividual(i).getFitness()) {
fittest = getIndividual(i);
index = i;
}
}
return index;
}
/** 计算种群中存放个体的数组大小 */
int size() {
return individuals.length;
}
/** 保存指定的个体到指定的存放种群的数组索引位置 */
void saveIndividual(int index, Individual indiv) {
individuals[index] = indiv;
}
/** 计算种群的总适应值 */
int getTotalFitness() {
int sum = 0;
for (int i = 0; i < individuals.length; i++)
sum += getIndividual(i).getFitness();
return sum;
}
/** 覆盖Object.colone()方法 */
protected Object clone() throws CloneNotSupportedException {
Population pop = (Population)super.clone();
pop.individuals = individuals.clone();
return pop;
}
/** 《Effective Java》总是覆盖Object.toString()方法 */
public String toString() {
StringBuilder builder = new StringBuilder();
for (Individual indiv: individuals)
builder.append(indiv + "\n");
return builder.toString();
}
}
package simpleGa;
class FitnessCalc {
/** <<Effective Java>>:在public类中使用访问方法而非,公共域 */
private static byte[] solution = new byte[64];
/** 设置候选解 */
static void setSolution(byte[] newSolution) {
solution = newSolution;
}
/** 获取设置的候选解 */
byte[] getSolution() {
return solution;
}
/** 通过字符串编码设置候选的解 */
static void setSolution(String newString) {
solution = new byte[newString.length()];
for (int i = 0; i < newString.length(); i++) {
String character = newString.substring(i, i+1);
if (character.contains("0") || character.contains("1"))
solution[i] = Byte.parseByte(character);
else
solution[i] = 0;
}
}
/** 计算个体的适应值 */
static int getFitness(Individual individual) {
int fitness = 0;
for (int i = 0; i < individual.size() && i < solution.length; i++) {
if (individual.getGene(i) == solution[i])
fitness++;
}
return fitness;
}
/** 获取理论上可以进化得到的最大适应值即是预设的候选解的适应值 */
static int getMaxFitness() {
int maxFitness = solution.length;
return maxFitness;
}
}
package simpleGa;
import java.util.Arrays;
import java.util.Random;
class Util {
private static int tournamentSize = 5;
/** 设置竞争种群的大小 */
static void setTournamentSize(int size) {
tournamentSize = size;
}
/** 获取预设的竞争种群的大小 */
static int getTournamentSize() {
return tournamentSize;
}
/**
* 竞争选择个体:随机预设大小弟新种群,从新种群中返回一个适应值最大的个体;
* 在此遗传算法系统实现中,一般用在交叉操作过程的个体选择
*/
static Individual tournamentSelection(Population pop) {
Population tournament = new Population(tournamentSize, false);
for (int i = 0; i < tournamentSize; i++) {
int randomId = (int)(Math.random() * pop.size());
tournament.saveIndividual(i, pop.getIndividual(randomId));
}
Individual fittest = tournament.getFittest();
return fittest;
}
/** 费雪耶兹随机置乱算法 */
static Population fisherYates(Population pop) {
Random random = new Random();
Individual temp;
for (int i = pop.size() - 1;i > 0; i--) {
int rand = random.nextInt(i+1); //随机数范围[0...i]
temp = pop.getIndividual(i);
pop.saveIndividual(i, pop.getIndividual(rand));
pop.saveIndividual(rand, temp);
}
random = null;
temp = null;
return pop;
}
/**
* 浮点数聚集求和如fitnessValue = [1 2 3 4],
* 则cumsum(fitnessValue) = [1 3 6 10]
*/
static double[] cumsum(double[] doubleArr) {
double[] tempArr = new double[doubleArr.length];
tempArr[0] = doubleArr[0];
for (int i = 1; i < doubleArr.length; i++)
tempArr[i] = doubleArr[i] + tempArr[i-1];
return tempArr;
}
/** 生成一个指定大小,并按从小到大排序的随机浮点数组 */
static double[] sortedRandomArray(int len) {
double[] random = new double[len];
for (int i = 0; i < len; i++)
random[i] = Math.random();
//对生成的随机数组按照从小到大排列
Arrays.sort(random);
return random;
}
/** 计算种群的个体被选择的概率聚集和 */
static double[] selectProbability(Population pop) {
//求种群的适应值之和
int totalFitness = 0;
for (int i = 0; i < pop.size(); i++)
totalFitness += pop.getIndividual(i).getFitness();
//单个个体被选择的概率
double[] cumPro = new double[pop.size()];
for (int i = 0; i < pop.size(); i++)
cumPro[i] = (double)pop.getIndividual(i).getFitness() / totalFitness;
//选择概率的聚集求和
cumPro = Util.cumsum(cumPro);
return cumPro;
}
}
package simpleGa;
import java.util.Arrays;
import java.util.Random;
class Util {
private static int tournamentSize = 5;
/** 设置竞争种群的大小 */
static void setTournamentSize(int size) {
tournamentSize = size;
}
/** 获取预设的竞争种群的大小 */
static int getTournamentSize() {
return tournamentSize;
}
/**
* 竞争选择个体:随机预设大小弟新种群,从新种群中返回一个适应值最大的个体;
* 在此遗传算法系统实现中,一般用在交叉操作过程的个体选择
*/
static Individual tournamentSelection(Population pop) {
Population tournament = new Population(tournamentSize, false);
for (int i = 0; i < tournamentSize; i++) {
int randomId = (int)(Math.random() * pop.size());
tournament.saveIndividual(i, pop.getIndividual(randomId));
}
Individual fittest = tournament.getFittest();
return fittest;
}
/** 费雪耶兹随机置乱算法 */
static Population fisherYates(Population pop) {
Random random = new Random();
Individual temp;
for (int i = pop.size() - 1;i > 0; i--) {
int rand = random.nextInt(i+1); //随机数范围[0...i]
temp = pop.getIndividual(i);
pop.saveIndividual(i, pop.getIndividual(rand));
pop.saveIndividual(rand, temp);
}
random = null;
temp = null;
return pop;
}
/**
* 浮点数聚集求和如fitnessValue = [1 2 3 4],
* 则cumsum(fitnessValue) = [1 3 6 10]
*/
static double[] cumsum(double[] doubleArr) {
double[] tempArr = new double[doubleArr.length];
tempArr[0] = doubleArr[0];
for (int i = 1; i < doubleArr.length; i++)
tempArr[i] = doubleArr[i] + tempArr[i-1];
return tempArr;
}
/** 生成一个指定大小,并按从小到大排序的随机浮点数组 */
static double[] sortedRandomArray(int len) {
double[] random = new double[len];
for (int i = 0; i < len; i++)
random[i] = Math.random();
//对生成的随机数组按照从小到大排列
Arrays.sort(random);
return random;
}
/** 计算种群的个体被选择的概率聚集和 */
static double[] selectProbability(Population pop) {
//求种群的适应值之和
int totalFitness = 0;
for (int i = 0; i < pop.size(); i++)
totalFitness += pop.getIndividual(i).getFitness();
//单个个体被选择的概率
double[] cumPro = new double[pop.size()];
for (int i = 0; i < pop.size(); i++)
cumPro[i] = (double)pop.getIndividual(i).getFitness() / totalFitness;
//选择概率的聚集求和
cumPro = Util.cumsum(cumPro);
return cumPro;
}
}
package simpleGa;
class GA {
/** 定义常量(《代码大全》
* 代码中不要出现magic数) */
private static final int POPULATION_SIZE = 100;
/** 减少类之间的耦合性;《设计模式:构建可复用的代码》*/
private static final int MAX_ITERATIONS = 10000;
/** 主方法,测试遗传算法性能
* @throws CloneNotSupportedException */
public static void main(String[] args) throws CloneNotSupportedException {
//设置候选解
FitnessCalc.setSolution("11110000000000000000000000000000000"
+ "00000000000000000000000001111");
//创建一个种群,并进行初始化
Population myPop = new Population(POPULATION_SIZE, true);
//种群代数计数
int generationCount = 0;
//创建一个Context类,维护一个Algorithm接口的引用
Context contextA, contextB, contextC, contextD;
//用一个具体的算法配置Context类
contextA = new Context(new EfficientAlgorithm());
contextB = new Context(new ImprovedMichellAlgorithm());
contextC = new Context(new MichellAlgorithm());
contextD = new Context(new PlainAlgorithm());
//进化直到获得一个最优解
while (myPop.getFittest().getFitness() < FitnessCalc.getMaxFitness() &&
generationCount < MAX_ITERATIONS) {
generationCount++;
System.out.println("Generation: " + generationCount + " Fittest: " +
myPop.getFittest().getFitness());
//注释掉最初建立系统时使用非策略方式的静态调用方法
//myPop = ImprovedMichellAlgorithm.evolvePopulation(myPop);
//调用不同的算法进行实验对比
myPop = contextA.executeAlgorithm(myPop);
// myPop = contextB.executeAlgorithm(myPop);
// myPop = contextC.executeAlgorithm(myPop);
// myPop = contextD.executeAlgorithm(myPop);
}
generationCount++;
if (myPop.getFittest().getFitness() >= FitnessCalc.getMaxFitness())
System.out.println("Solution found!");
System.out.println("Generation: " + generationCount);
System.out.println("Genes:");
System.out.println(myPop.getFittest());
System.out.println("Total fitenss:");
System.out.println(myPop.getTotalFitness());
}
}四、4种算法流程图及其源代码
4种实现的算法采用了《设计模式》中的Strategy策略模式,除了实现算法的源文件包括MichellAlgorithm.java,PlainAlgorithm,java,ImprovedMichellAlgorithm.java和EfficientAlgorithm.java,还有Context.java和Algorithm接口;
Strategy模式中的Context类
package simpleGa;
/*
* 在遗传算法实现时,使用了不同的实现方式,采用策略模式Strategy,对不同等算法进行调用;
* 策略模式由三个部分组成:
* 1.策略(Algorithm)
* 声明一个支持所有算法的公共接口。环境类使用这个接口调用由具体策略定义的算法
* 2.具体策略(EfficientAlgorithm, ImprovedMichellAlgorithm, MichellAlgorithm, PlainAlgorithm)
* 使用策略接口实现算法
* 3.环境(Context)
* 由一个具体策略对象配置;维护着一个策略对象的接口;可能定义一个接口让策略访问它的数据
* Context类维护一个策略接口的引用,用一个具体的策略进行配置
*/
class Context {
private Algorithm algorithm;
/** 构造器;定义为包私有的 */
Context(Algorithm algorithm) {
this.algorithm = algorithm;
}
/** 定义一个接口让Algorithm访问Context类的数据*/
Population executeAlgorithm(Population pop) throws CloneNotSupportedException {
return this.algorithm.evolvePopulation(pop);
}
}
package simpleGa;
/*
* 《Introduction to Java Programming》:
* 接口中所有的域都是public static final int k = 1;所有的方法都是public abstract
*/
interface Algorithm {
/**
* 种群的交叉比率
* 等价于public static final double crossoverRate = 0.7
*/
static final double CROSSOVER_RATE = 0.7;
/** 种群的突变比率 */
static final double MUTATION_RATE = 0.015;
/**
* 种群进化操作,在其实现的类中供其他的类调用的方法
* 等价于public abstract Population evolvePopulation(Population pop)
* @throws CloneNotSupportedException
*/
abstract Population evolvePopulation(Population pop) throws CloneNotSupportedException;
}1.米切尔版本的遗传算法
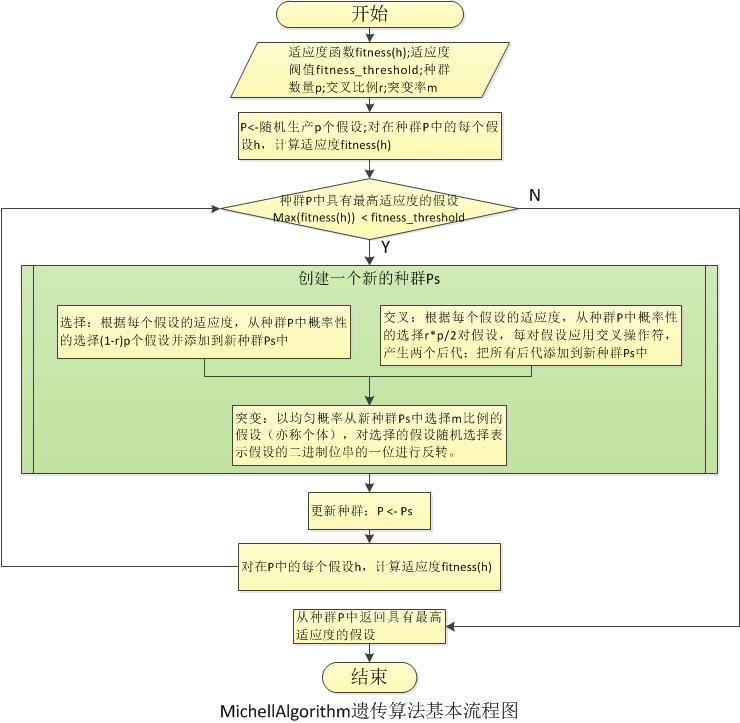
package simpleGa;
import java.util.Random;
/*
*
*/
class MichellAlgorithm implements Algorithm {
/**
* 种群进化操作,可以被其他类访问的方法
* 在机器学习创始人米切尔《Machine Learning》中选择和交叉时并行操作,这里实现时体现了这一算法思想
* @throws CloneNotSupportedException
*/
public Population evolvePopulation(Population pop) throws CloneNotSupportedException {
Population newPop = new Population(pop.size(), false);
//单个个体被选择的概率;概率之和计算并非等于1.0
double[] indivSelectPro = Util.selectProbability(pop);
//选择操作;相对《Machine Learning》原著中在选择不是根据适应值概率性的进行选择,而是选择最大的前selectionSize的个体
newPop = select(pop);
//交叉操作
Population crossPop = crossover(pop, indivSelectPro);
int j = selectSize(pop);
for (int i = 0; i < crossPop.size(); i++, j++)
newPop.saveIndividual(j, crossPop.getIndividual(i));
//<<Effective Java>>:消除废弃的对象引用
crossPop = null;
//突变操作
mutate(newPop);
return newPop;
}
/**
* 选择适应值最高的精英到新种群中
* 两种方法:1.根据预设的选择种群数量连续选择适应值最高的个体到新种群中
* 2. 按照适应值从高到低的顺序,依次选择到新种群中
* 这里实现了第2种
* @throws CloneNotSupportedException
*/
private static Population select(Population pop)
throws CloneNotSupportedException {
//计算从种群中选择保留跨世精英数量
int selectionSize = selectSize(pop);
//创建一个非初始化原种群大小的新种群
Population newPop = new Population(pop.size(), false);
//保留种群中适应值前selectSize数量的个体
Population copyPop = (Population)pop.clone();
for (int i = 0; i < selectionSize; i++) {
MyHashMap fittest = copyPop.getFittest(i);
newPop.saveIndividual(i, fittest.getValue());
//将从i到最后种群中适应值最大的个体与第i位置个体进行交换,利用冒泡排序思想,从大到小排序,i之前的总是按适应值排好的
copyPop.saveIndividual(fittest.getKey(), copyPop.getIndividual(i));
copyPop.saveIndividual(i, fittest.getValue());
}
return newPop;
}
/** 交叉操作包括单点、两点和均匀交叉;在这里实现了单点交叉 */
private static Population crossover(Population pop, double[] fitValue) {
//计算交叉种群的数量
int crossSize = crossSize(pop);
//创建一个非初始化的种群,用于存放交叉操作得到的种群
Population crossPop = new Population(crossSize, false);
//生成一个均匀分布的伪随机数组,用于随机选择交叉的个体;若交叉种群的数量为奇数时,用于确定最后一个加入到交叉种群的个体
double[] random = Util.sortedRandomArray(crossSize);
//存放根据适应值概率性选择的两个个体
Individual indiv1 = new Individual();
Individual indiv2 = new Individual();
//两个临时变量存放一对个体产生的两个交叉后代
Individual temp1 = new Individual();
Individual temp2 = new Individual();
//循环选择crossSize/2对的个体进行交叉;
int j = 0;
for (int i = 0; i < crossSize - 1; i = i + 2) {
//根据两个已经是从小到大顺序的数组(随机数数组和适应值数组),利用快速排序思想选择两个个体进行交叉
while(j < pop.size())
if (random[i] < fitValue[j]) {
indiv1 = pop.getIndividual(j);
break;//跳出循环
}
else
j++;
while (j < pop.size())
if (random[i+1] < fitValue[j]) {
indiv2 = pop.getIndividual(j);
break;//跳出循环
}
else
j++;
//计算个体的编码长度
int len = pop.getIndividual(0).size();
//随机选择交叉点位置,范围在[0...len-1]
int cpoint = (new Random()).nextInt(len);
//将选择的两个个体inidv1、indiv2的0...cpoint-1位置的基因设置分别为temp1、temp2的0...cpoint-1的基因
int k;
for (k = 0; k < cpoint; k++) {
temp1.setGene(k, indiv1.getGene(k));
temp2.setGene(k, indiv2.getGene(k));
}
//将indiv1、indiv2的cpoint...len-1位置的基因设置为temp2、temp1的cpoint...len-1位置的基因
for (; k < len; k++) {
temp1.setGene(k, indiv2.getGene(k));
temp2.setGene(k, indiv1.getGene(k));
}
//保存交叉得到的两个后代到新种群中
crossPop.saveIndividual(i, temp1);
crossPop.saveIndividual(i+1, temp2);
}
//<<Effective Java>>:消除废弃的对象引用
temp1 = temp2 = indiv1 = indiv2 = null;
//判断crossSize的奇偶性;若为奇数,则根据个体适应值概率性的选择一个个体到交叉种群中
if (crossSize % 2 == 1)
while (j < pop.size())
if (random[crossSize-1] < fitValue[j]) {
crossPop.saveIndividual(crossSize - 1, pop.getIndividual(j));
break;//跳出循环
}
else
j++;
return crossPop;
}
/**
* 突变操作;当种群数量小于一定数量时, 突变的可能性为0;所以这个实现版本只适用于种群数量较大时的遗传算法;否则
* 算法必收敛到局部最优解。改进版本的遗传算法是自适应的遗传算法,突变率随着种群进化的次数增加而增加,在确保收敛
* 稳定性的情况下,可以跳过局部最优解;尽力搜索全局最优。
* 《Mahcine Learning》原著中算法突变操作思想是上述容,这里实现时作了调整,突变的个体数量是概率性而非固定比例的
*/
private static void mutate(Population pop) {
// 对种群的中非精英个体进行突变操作;《Machine Learning》原著中是对所有个体进行突变,包括种群中的精英
// 因为在原著中算法在第一步选择时是根据个体的适应值,概率性的选择固定指定数量的个体,而非绝对选择适应值最前的个体;
// 与其的突变操作思想是一致的。
for (int i = selectSize(pop); i < pop.size(); i++) {
if (Math.random() < Algorithm.MUTATION_RATE) {
Individual indiv = pop.getIndividual(i);
//随机选择一个突变的位置
int randPos = (new Random()).nextInt(indiv.size());
//若突变的位置原始值为1则反转为0,反之亦然;(《代码大全》构建简洁的代码)
indiv.setGene(randPos, (byte)(1-indiv.getGene(randPos)));
}
}
}
/** 计算选择种群的大小 */
private static int selectSize(Population pop) {
return pop.size() - crossSize(pop);
}
/** 计算交叉种群的大小 */
private static int crossSize(Population pop) {
return (int)Math.round(Algorithm.CROSSOVER_RATE * pop.size());
}
/**
* 计算突变个体的数量:当种群数量比较小时,如果按照固定比例从种群中随机选择个体进行变异,
* 且突变的比率自身又比较低,则会种群进行突变的可能性为0.在米切尔《Machine Learning》
* 中按固定比例选择个体进行变异,在变异率确定的情况下,适应于种群数量较大情况
*/
private static int mutateSize(Population pop) {
return (int)Math.round(pop.size() * Algorithm.MUTATION_RATE);
}
}
Ecplise中运行的结果:
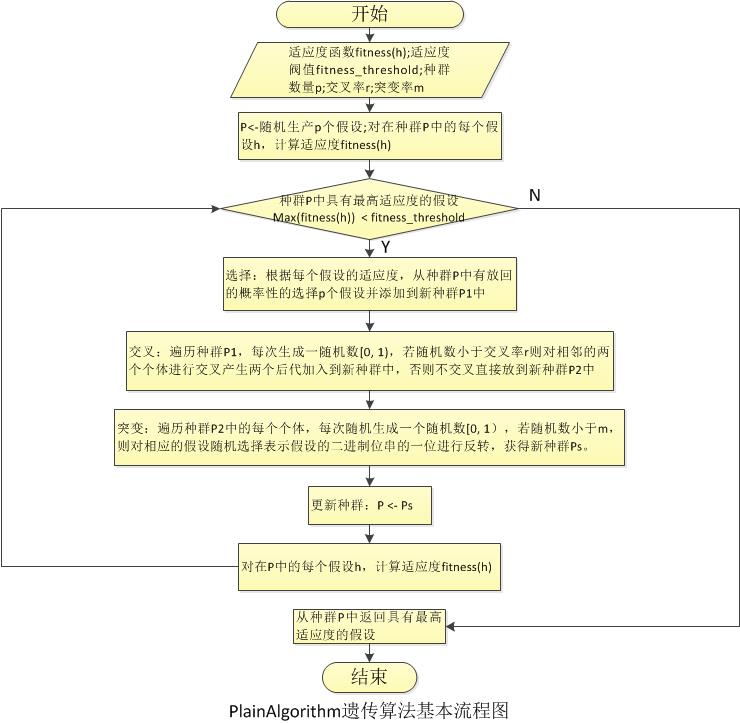
package simpleGa;
import java.util.Random;
class PlainAlgorithm implements Algorithm {
/**
* 种群进化操作,可以被其他类访问的方法
* @throws CloneNotSupportedException
*/
public Population evolvePopulation(Population pop) throws CloneNotSupportedException {
Population newPop = new Population(pop.size(), false);
//单个个体被选择的概率;概率之和计算并非等于1.0
double[] indivSelectPro = Util.selectProbability(pop);
//选择操作
newPop = select(pop, indivSelectPro);
//对选择得到的种群进行交叉操作
newPop = crossover(newPop);//《Effective Java》减少创建的对象的引用
//突变操作
mutate(newPop);
return newPop;
}
/**
* 根据个体的适应值概率性的从当前种群中,非放回可重复抽样,选择原种群数量的新种群
* @throws CloneNotSupportedException
*/
private static Population select(Population pop, double[] fitValue)
throws CloneNotSupportedException {
//创建一个非初始化原种群大小的新种群
Population newPop = new Population(pop.size(), false);
//生成一个均匀分布的伪随机数组,用于根据适应值概率性的选择个体
double[] random = Util.sortedRandomArray(pop.size());
int randIndex = 0;
int fitIndex = 0;
while (randIndex < pop.size()) {
if (random[randIndex] < fitValue[fitIndex]) {
newPop.saveIndividual(randIndex, pop.getIndividual(randIndex));
randIndex++;
}
else
fitIndex++;
}
return newPop;
}
/** 交叉操作包括单点、两点和均匀交叉;在这里实现了单点交叉 */
private static Population crossover(Population pop) {
//创建一个非初始化的种群
Population crossPop = new Population(pop.size(), false);
//存放根据适应值概率性选择的两个个体
Individual indiv1 = new Individual();
Individual indiv2 = new Individual();
//两个临时变量存放一对个体产生的两个交叉后代
Individual temp1 = new Individual();
Individual temp2 = new Individual();
//计算个体的编码长度
int len = pop.getIndividual(0).size();
//循环选择pop.size()/2对的个体进行交叉;交叉使用单点交叉
for (int i = 0; i < pop.size() - 1; i = i + 2) {
indiv1 = pop.getIndividual(i);
indiv2 = pop.getIndividual(i+1);
if (Math.random() < Algorithm.CROSSOVER_RATE) {
//随机选择交叉点位置,范围在[0...len-1]
int cpoint = (new Random()).nextInt(len);
//将选择的两个个体inidv1、indiv2的0...cpoint-1位置的基因设置分别
//为temp1、temp2的0...cpoint-1的基因
int k;
for (k = 0; k < cpoint; k++) {
temp1.setGene(k, indiv1.getGene(k));
temp2.setGene(k, indiv2.getGene(k));
}
//将indiv1、indiv2的cpoint...len-1位置的基因设置为temp2、temp1的cpoint...len-1位置的基因
for (; k < len; k++) {
temp1.setGene(k, indiv2.getGene(k));
temp2.setGene(k, indiv1.getGene(k));
}
}
else {
temp1 = indiv1;
temp2 = indiv2;
}
//保存交叉得到的两个后代到新种群中
crossPop.saveIndividual(i, temp1);
crossPop.saveIndividual(i+1, temp2);
}
//<<Effective Java>>:消除废弃的对象引用
temp1 = temp2 = indiv1 = indiv2 = null;
//判断种群的奇偶性;若为奇数,则根据个体适应值概率性的选择一个个体到交叉种群中
if (pop.size() % 2 == 1)
crossPop.saveIndividual(pop.size()-1, Util.tournamentSelection(pop));
return crossPop;
}
/**
* 突变操作:根据预设的突变率,对当前种群中的个体进行变异
*/
private static void mutate(Population pop) {
// 对种群的所有个体进行突变操作,包括非精英个体
for (int i = 0; i < pop.size(); i++) {
if (Math.random() < Algorithm.MUTATION_RATE) {
Individual indiv = pop.getIndividual(i);
//随机选择一个突变的位置
int randPos = (new Random()).nextInt(indiv.size());
//若突变的位置原始值为1则反转为0,反之亦然;(《代码大全》构建简洁的代码)
indiv.setGene(randPos, (byte)(1-indiv.getGene(randPos)));
}
}
}
}
Ecplise中运行的结果:
package simpleGa;
import java.util.Random;
class ImprovedMichellAlgorithm implements Algorithm{
/** 均匀概率 */
private static final double UNIFORM_RATE = 0.5;
/**
* 种群进化操作,可以被其他类访问的方法
* @throws CloneNotSupportedException
*/
public Population evolvePopulation(Population pop) throws CloneNotSupportedException {
Population newPop = new Population(pop.size(), false);
//单个个体被选择的概率;概率之和计算并非等于1.0
double[] indivSelectPro = Util.selectProbability(pop);
//选择操作
newPop = select(pop, indivSelectPro);
//交叉操作
Population crossPop = crossover(pop, indivSelectPro);
int j = selectSize(pop);
for (int i = 0; i < crossPop.size(); i++, j++)
newPop.saveIndividual(j, crossPop.getIndividual(i));
//<<Effective Java>>:消除废弃的对象引用
crossPop = null;
//突变操作
mutate(newPop);
return newPop;
}
/**
* 选择适应值最高的精英到新种群中
* 两种方法:1.根据预设的选择种群数量连续选择适应值最高的个体到新种群中
* 2. 按照适应值从高到低的顺序,依次选择到新种群中
* 这里实现了第2种
* @throws CloneNotSupportedException
*/
private static Population select(Population pop, double[] fitValue)
throws CloneNotSupportedException {
//计算从种群中选择保留跨世精英数量
int selectionSize = selectSize(pop);
//创建一个非初始化原种群大小的新种群
Population newPop = new Population(pop.size(), false);
//保留种群中适应值前selectSize数量的个体
Population copyPop = (Population)pop.clone();
for (int i = 0; i < selectionSize; i++) {
MyHashMap fittest = copyPop.getFittest(i);
newPop.saveIndividual(i, fittest.getValue());
//将从i到最后种群中适应值最大的个体与第i位置个体进行交换,利用冒泡排序思想,从大到小排序,i之前的总是按适应值排好的
copyPop.saveIndividual(fittest.getKey(), copyPop.getIndividual(i));
copyPop.saveIndividual(i, fittest.getValue());
}
return newPop;
}
/** 交叉操作包括单点、两点和均匀交叉;在这里实现了单点交叉 */
private static Population crossover(Population pop, double[] fitValue) {
//交叉种群的数量
int crossSize = crossSize(pop);
//创建一个非初始化的种群
Population crossPop = new Population(crossSize, false);
//设置竞争选择随机选择的种群大小
Util.setTournamentSize(10);
//存放根据适应值概率性选择的两个
Individual indiv1 = Util.tournamentSelection(pop);
Individual indiv2 = Util.tournamentSelection(pop);
//两个临时变量存放一对个体产生的两个交叉后代
Individual temp1 = new Individual();
Individual temp2 = new Individual();
//循环选择crossSize/2对的个体进行交叉;
int j = 0;
for (int i = 0; i < crossSize - 1; i = i + 2) {
//计算个体的编码长度
int len = pop.getIndividual(0).size();
//实现多点交叉
for (int m = 0; m < len; m++) {
if (Math.random() <= UNIFORM_RATE) {
temp1.setGene(m, indiv1.getGene(m));
temp2.setGene(m, indiv2.getGene(m));
}
else {
temp1.setGene(m, indiv2.getGene(m));
temp2.setGene(m, indiv1.getGene(m));
}
}
//保存交叉得到的两个后代到新种群中
crossPop.saveIndividual(i, temp1);
crossPop.saveIndividual(i+1, temp2);
}
//<<Effective Java>>:消除废弃的对象引用
temp1 = temp2 = indiv1 = indiv2 = null;
//判断crossSize的奇偶性;若为奇数,则根据个体适应值概率性的选择一个个体到交叉种群中
double rand = Math.random();
if (crossSize % 2 == 1)
while (j < pop.size())
if (rand < fitValue[j]) {
crossPop.saveIndividual(crossSize - 1, pop.getIndividual(j));
break;//跳出循环
}
else
j++;
return crossPop;
}
/**
* 突变操作;当种群数量小于一定数量时, 突变的可能性为0;所以这个实现版本只适用于种群数量较大时的遗传算法;否则
* 算法必收敛到局部最优解。改进版本的遗传算法是自适应的遗传算法,突变率随着种群进化的次数增加而增加,在确保收敛
* 稳定性的情况下,可以跳过局部最优解;尽力搜索全局最优。
*/
private static void mutate(Population pop) {
// 对种群的中非精英个体进行突变操作
for (int i = selectSize(pop); i < pop.size(); i++) {
if (Math.random() < Algorithm.MUTATION_RATE) {
Individual indiv = pop.getIndividual(i);
//随机选择一个突变的位置
int randPos = (new Random()).nextInt(indiv.size());
//若突变的位置原始值为1则反转为0,反之亦然;(《代码大全》构建简洁的代码)
indiv.setGene(randPos, (byte)(1-indiv.getGene(randPos)));
}
}
}
/** 计算选择种群的大小 */
private static int selectSize(Population pop) {
return (int)Math.round((1-Algorithm.CROSSOVER_RATE) * pop.size());
}
/** 计算交叉种群的大小 */
private static int crossSize(Population pop) {
return pop.size() - selectSize(pop);
}
}
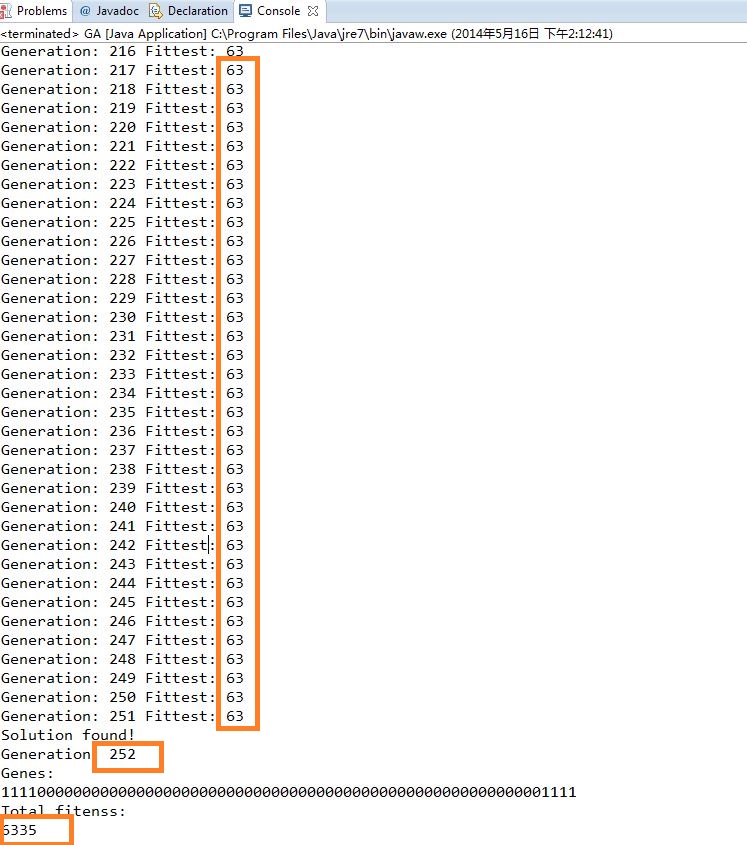
Ecplise中运行的结果:
package simpleGa;
class EfficientAlgorithm implements Algorithm{
/** 保留精英布尔常量*/
private static final boolean ELITISM = true;
/**
* 《Effective Java》对于所有的可供其他类访问的域、方法和类写注释文档
* 此算法从种群中选择一个精英个体保留到下一代;从当前种群中随机选择预设竞争种群数量的个体到竞争种群中,
* 从竞争种群中选择适应值最高的个体到作为交叉个体,每一次交叉按照这种方法选择两个个体,使用多点均匀交叉
* 产生一个后代作为下一代的种群的个体;对新种群进行变异操作,变异不包括精英。
* http://www.theprojectspot.com/tutorial-post/creating-a-genetic-algorithm-for-beginners/3
* @param pop:Poplation
* @return Population
*/
public Population evolvePopulation(Population pop) {
Population newPopulation = new Population(pop.size(), false);
int elitismoffset = 0;
//判断是否保留当前种群中具有最高适应度的个体———精英,到下一代种群中
if (ELITISM) {
newPopulation.saveIndividual(0, pop.getFittest());
elitismoffset = 1;
}
else
elitismoffset = 0;
//循环使用交叉创建新个体
Individual indiv1, indiv2, newIndiv;
for (int i = elitismoffset; i < pop.size(); i++) {
indiv1 = Util.tournamentSelection(pop);
indiv2 = Util.tournamentSelection(pop);
newIndiv = crossover(indiv1, indiv2);
newPopulation.saveIndividual(i, newIndiv);
}
//除跨世代保留的精英外,对种群中其他个体进行突变操作
for (int i = elitismoffset; i < newPopulation.size(); i++)
mutate(newPopulation.getIndividual(i));
return newPopulation;
}
/** 个体交叉,均匀交叉*/
private static Individual crossover(Individual indiv1, Individual indiv2) {
Individual newIndividual = new Individual();
for (int i = 0; i < indiv1.size(); i++) {
if (Math.random() <= Algorithm.CROSSOVER_RATE)
newIndividual.setGene(i, indiv1.getGene(i));
else
newIndividual.setGene(i, indiv2.getGene(i));
}
return newIndividual;
}
/** 突变一个个体 */
private static void mutate(Individual indiv) {
for (int i = 0; i < indiv.size(); i++) {
if (Math.random() <= Algorithm.MUTATION_RATE) {
byte gene = (byte)Math.round(Math.random());
indiv.setGene(i, gene);
}
}
}
}
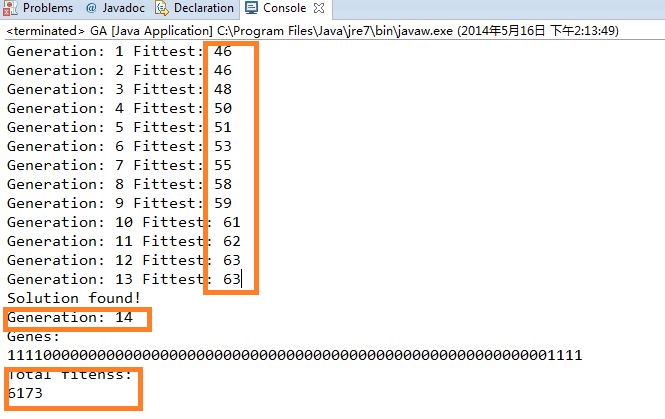

















 757
757

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









