






1.下载安装yolov8
- 在github中下载yolov8的文档(ultralytics/ultralytics: NEW - YOLOv8 🚀 in PyTorch > ONNX > OpenVINO > CoreML > TFLite (github.com)),并将其解压到自己想要的地方。
- 通过conda终端进行虚拟环境搭建:conda create -n name pythpn=x.x(例如:conda create -n hello python=3.10)
- 在VSCODE中选择建立好的虚拟环境,在VSCODE终端(即虚拟环境下)输入:pip Install -e . 对yolo进行安装。/或者在conda的终端激活 hello 虚拟虚拟环境,在输入pip Install -e .
2.下载安装pytorch
2.1下载安装CPU版本
CPU版本先进入到上面所创建的虚拟环境中,然后直接通过pip进行安装即可
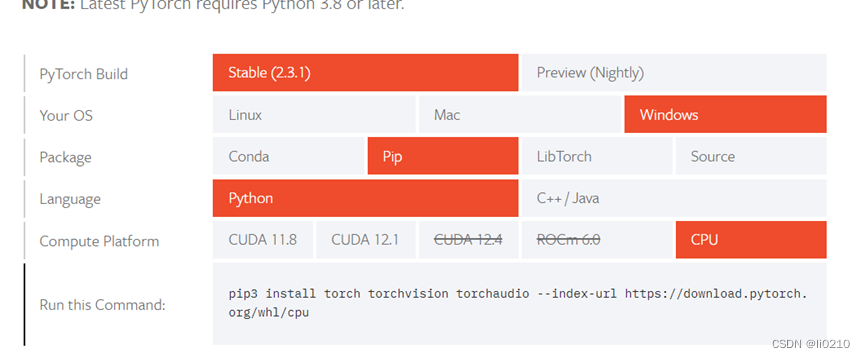
2.2下载安装GPU版本
2.2.1 安装cuda
根据自己电脑GPU,安装对应的cuda和cudnn版本
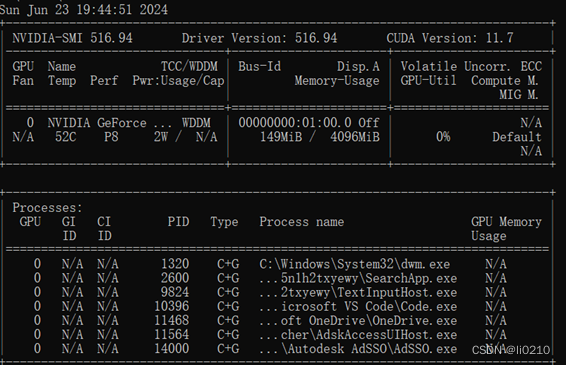
使用命令行输入 nvidia-smi ,可以看到我的为11.7(具体可见:CUDA学习(一)——如何查看自己CUDA版本?_cuda version-CSDN博客)
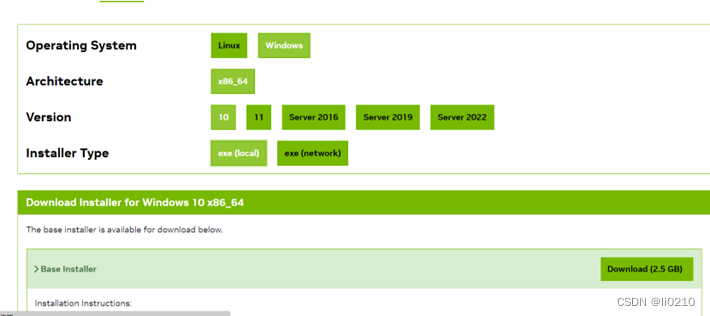
CUDA Toolkit Archive | NVIDIA Developer 通过上述网站找到属于自己的版本号,例如:cuda11.7。下载好后直接进行安装。
2.2.2 安装cudnn
https://developer.nvidia.com/rdp/cudnn-archive
扎到cuda11.7对应版本的cudnn,进行下载,下载完成后将其解压并将里面的内容复制放置到v11.7的路径下面(即之前cuda安装路径)。

2.2.3 安装torch-gpu
也是先进入自己所创建的虚拟环境中,在通过pip安装
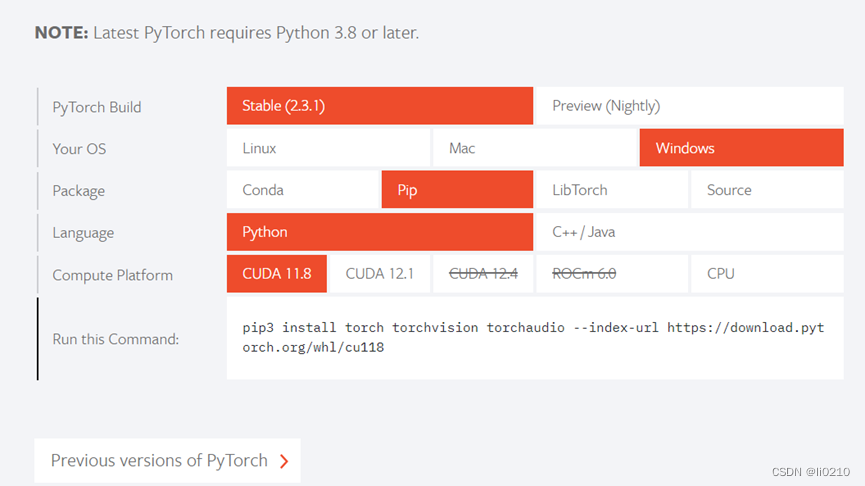
下方可以安装以前的版本的torch,我这里是11.7,python版本为3.9
pip install torch==1.13.1+cu117 torchvision==0.14.1+cu117 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu117 通过上述命令安装

2.2.4测试torch是否安装成功
import torch
# 检查torch是否有CUDA支持,即是否能用GPU
print(torch.cuda.is_available())
# 如果CUDA可用,它还会打印出当前默认的CUDA设备(通常是第一个GPU)
if torch.cuda.is_available():
print(torch.cuda.get_device_name(0))
print(torch.version.cuda)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)

若出现以上信息,出现自己的显卡信息,则安装成功。
3.下载安装标注工具labelImg
pip install labelimg (注意这里python版本不能过大,最要<=3.9)
通过终端输入 labelimg 启动标注工具,并切换到yolo数据集格式
选择好你要保存的labels路径(最好新建一个文件夹,这里我新建的为Annotation),并选择自动保存功能

标记图片后会自动生成每张图片对应的labels信息,为txt文件。

4.编辑yolov8训练集格式
在上次解压的yolov8文档下面新建一个datasets的文件夹,在datasets文件夹下建立images和labels文件夹

在images文件夹下建立train和val文件夹,放置图片,train为训练集,val为验证集。
在labels文件夹下建立train和val文件夹,放置图片所对应的labels信息。将之前标注好的文件拉过来即可,但是注意这里进行了分类,所以需要手动调整。cache文件是自动生成的,无需自己操作。
5.配置yaml文件
先在虚拟环境下的终端 输入 yolo copy-cfg ,将yaml文件复制一份到根目录下(ultralytics-main),此时会出现一个yaml文件,点开进行以下格式配置。
(注:这里我将复制出来的yaml文件名称改为了yolov8_classroom)
path:数据集的路径,即images和labels的目录
names:标签名字,即标注时自己选择的名字,可以有多个。

6.模型训练
from ultralytics import YOLO
# 加载模型
model = YOLO("yolov8n.pt") # initialize model
# 训练模型
model.train(data="./yolov8_classroom.yaml",workers=0,epochs=100,batch=4,device=[0],amp=False)
yolov8n.pt:自己选择yolo的模型,默认为自动下载,也可通过网站手动下载(其他模型请看:ultralytics/ultralytics: NEW - YOLOv8 🚀 in PyTorch > ONNX > OpenVINO > CoreML > TFLite (github.com) )
data:选择自己配置好的yaml文件;
workers:windows系统需要选择为0,否则会报错。
epochs:数据集训练轮次,例如:100,则为所有数据集训练一百轮,每一轮可以有很多次,而次数则由batch决定。
batch:每次训练数据个数,例如:4,每次训练4张图片,若数据集有100张图片,则每一轮需要训练25次。
device=[0]:选择自己的GPU训练,若为CPU,则将该项删除即可。
amp=False:训练时有些数据可能不会显示,会出现nan,设置好amp=False便可以解决。
具体其他参数可看:YOLOv8训练参数详解(全面详细、重点突出、大白话阐述小白也能看懂)-CSDN博客
点击运行,它会先下载所需要的模型:yolov8n,或者你手动下载。
训练结束后会见所有的数据储存到run的文件夹下面,weights为训练好后的模型,若想要继续训练,则可以选取best或者last替换掉之前的yolov8n模型,则可继续训练。(最好将想要训练的best或者last文件复制到根目录下,即之前yolov8n的同路径)















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









