







目录
③pip install 和conda install的区别
一、安装Anaconda3
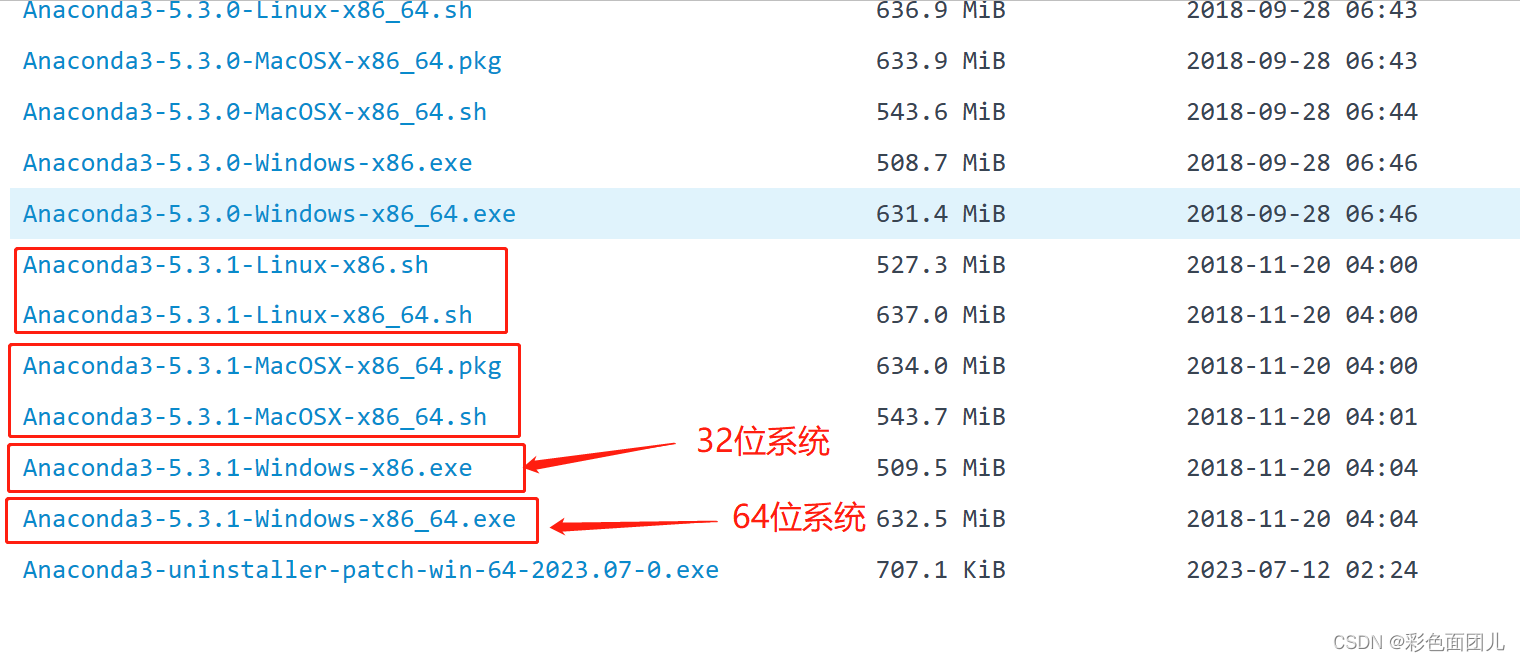
1、下载
到官网:
Index of /anaconda/archive/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
2、安装
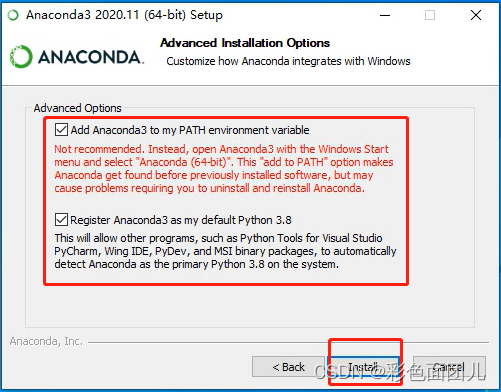
双击exe——Next——I Argee——just me ——选择路径(建议自定义,不要安装到c盘,且安装路径不要出现中文)——两个勾都勾上,不然配置环境很麻烦——Install——接下来页面两个勾不选——fnish完成安装。

3、验证
开始去找到这个
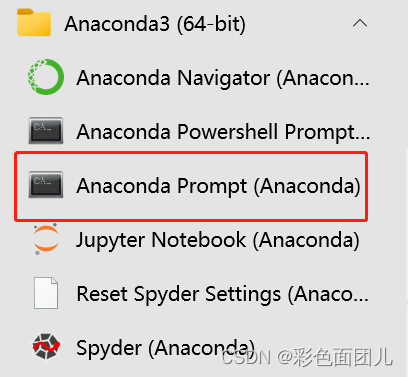
点开能进入命令框,输入python,可以看到python版本。print(“hi”)
二、搭建windows上yolov8环境
1、cuda+pytorch+python版本选择
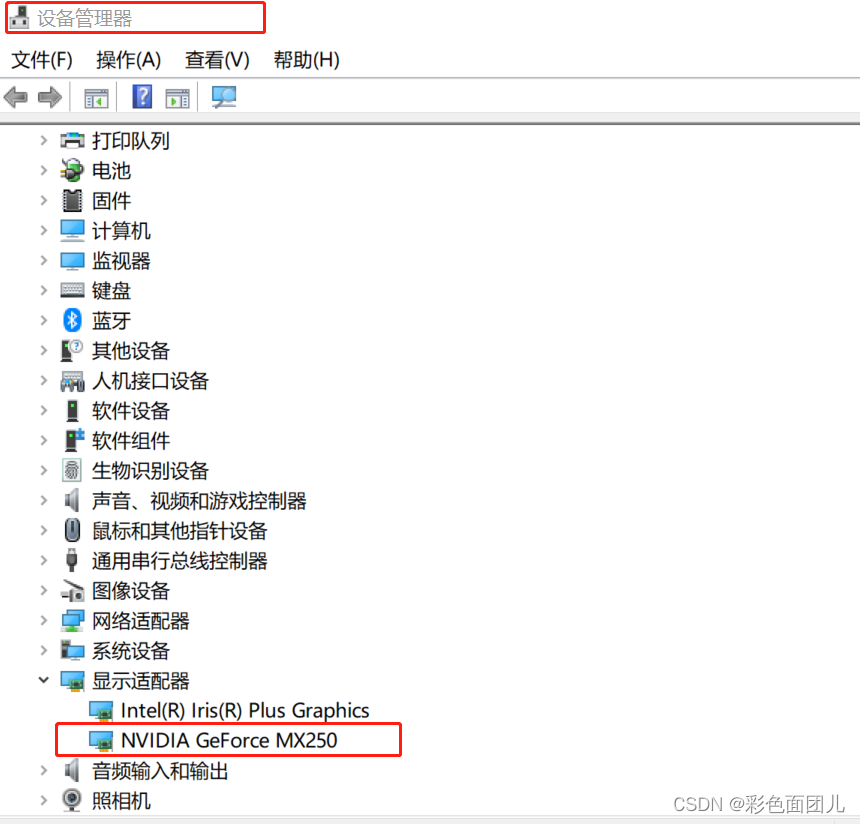
①查看自己电脑的cuda型号
首先搜索栏找到设备管理器——显示适配器——NVIDIA(有这个才可以,说明电脑有GPU独显,否则就是只有集成显卡Intel,如图所以,很多比如联想台式电脑就没有独显,那么跑深度学习就得有服务器)
在电脑上按键win+r——输入cmd——输入nvidia-smi
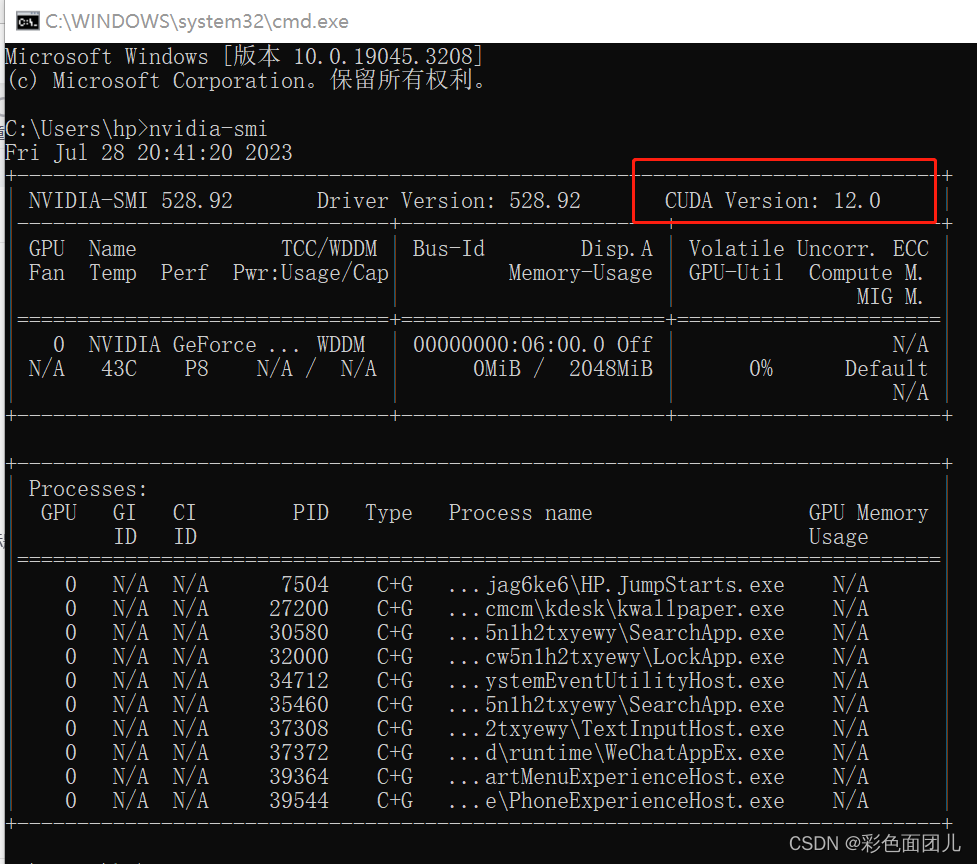
②显卡驱动版本对应选择
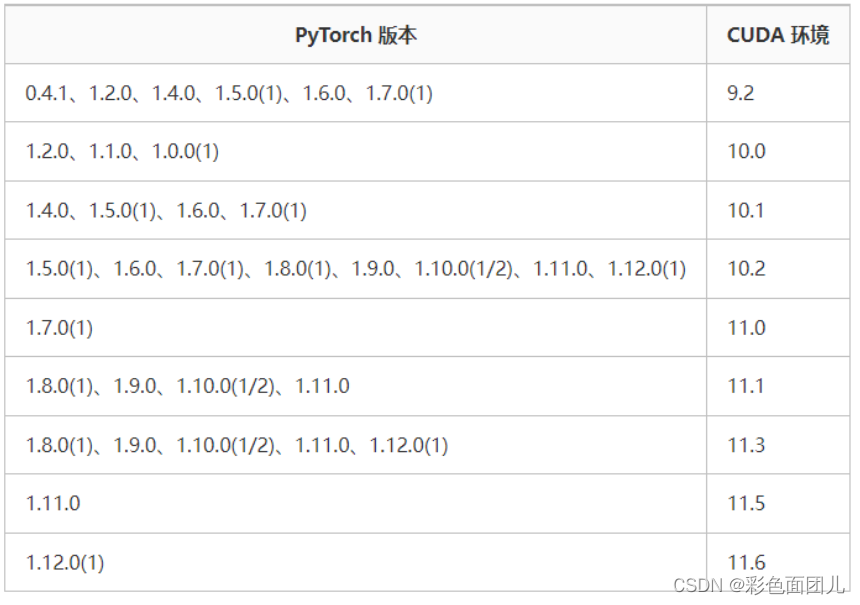
(1)理论上显卡越新越好,但是有的新的会不稳定,显示花屏等异常出现,所以不能一味追求新。而且太新了可能还没来得及出来对应的pytorch版本,就没法匹配。
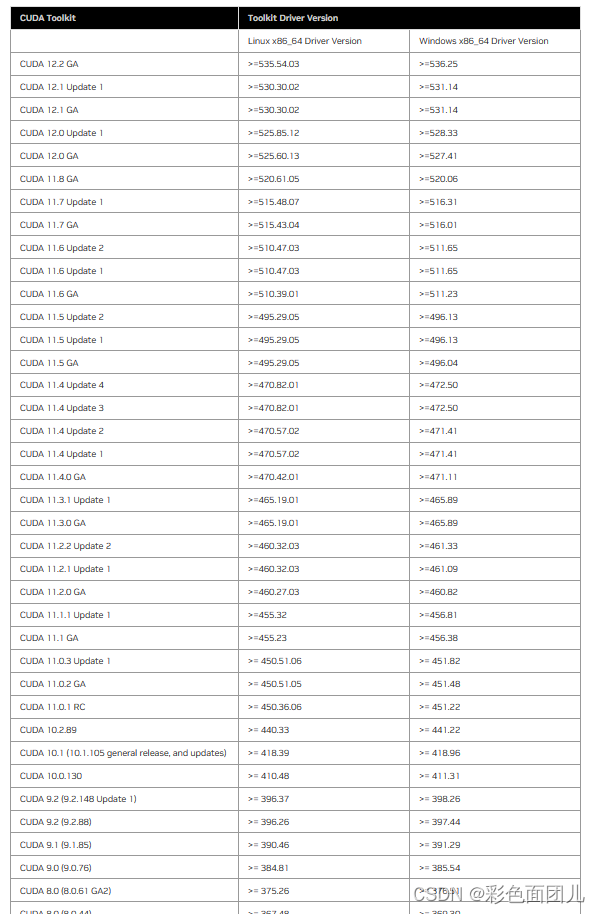
(2)安装的驱动版本<=电脑上显示的(支持最高cuda版本号),如本台电脑是12.0,那么安装的必须<=12.0,不能大于它。
(3)如果显卡<=PTX2080,推荐安装cuda10.2+cudnn7.6.5,或者其他版本;
如果显卡>=PTX3050,则必须安装cuda>=11.0。
| torch | torchvision | Python |
| main/nightly | main/nightly | >=3.8,<=3.11 |
| 2.0 | 0.15 | >=3.8,<=3.11 |
| 1.13 | 0.14 | >=3.7.2,<=3.10 |
| 1.12 | 0.13 | >=3.7,<=3.10 |
| 1.11 | 0.12 | >=3.7,<=3.10 |
| 1.10 | 0.11 | >=3.6,<=3.9 |
| 1.9 | 0.10 | >=3.6,<=3.9 |
| 1.8 | 0.9 | >=3.6,<=3.9 |
| 1.7 | 0.8 | >=3.6,<=3.9 |
| 1.6 | 0.7 | >=3.6,<=3.8 |
| 1.5 | 0.6 | >=3.5,<=3.8 |
| 1.4 | 0.5 | >=3.8,<=3.11 |
| 1.3 | 0.4.2/0.4.3 | ==2.7,>=3.5,<=3.8 |
| 1.2 | 0.4.1 | ==2.7,>=3.5,<=3.7 |
| 1.1 | 0.3 | ==2.7,>=3.5,<=3.7 |
| <=1.0 | 0.2 | ==2.7,>=3.5,<=3.7 |
2、创建虚拟环境
conda create -n 自己起名字 python==
如:conda create -n yolov8 python==3.8.0
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2326
2326











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











