







一、复杂的数据类型都有哪些呢?
hive中复杂数据类型分为三种,分别是 数组array、键值对map和结构体struct
array : col array<基本类型> ,下标从0开始,越界不报错,以NULL代替 map : column map<string,string> struct: col struct
二、数组array的基本操作
1、创建一个表
create table if not exists arr1( name string, score array<string> ) row format delimited fields terminated by '\t' collection items terminated by ',';
2、将数据导入arr1表
#原始数据 注: 中间不是空格 是 \t
liqi 11,22,33,44,55,66 zhangsan 12,23,34,45,56,67 shenghuang 111,222,333,444,555,666# 导入数据
load data local inpath 'arr1.txt' into table arr;#查询数据
select * from arr1;

3、列转行操作
其实就上把一列数据转化成多行
- explode: 主要是讲 列表中的每个元素生成一行,(由列变行)
- lateral view: 侧视图的意义是配合explode,功能是将一个语句生成的单行数据拆解成多行后的数据结果集; 具体的解释为 lateral view 会将explode生成的结果放到一个虚拟表中,然后这个虚拟表会和当前表 进行 join连接,来达到数据聚合的目的。
格式为:lateral view explode(字段) 虚拟表名 as 虚拟表字段名
将列变成行:
select name,s from arr1 lateral view explode(score) score as s;

统计每个学生的总成绩:
select name,sum(s) as tatalscore from arr1 lateral view explode(score) score as s;
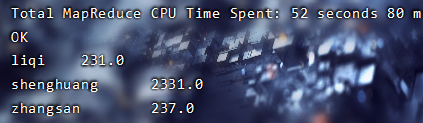
4、行转列操作
此时用到 collect_set函数
collect_set函数功能: 将分组中的某列转为一个数组再返回
准备数据: 就是 上面的 列转行的数据,再将其转列
#1、创建一个临时表 存储 由列转行的数据的表
create table temp_arr1 as select name,s from arr1 lateral view explode(score) score as s;#2、创建一个存储某列的表
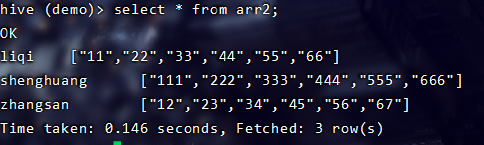
create table if not exists arr2( name string, score array<string> ) row format delimited fields terminated by ' ' collection items terminated by ','#3、然后就是将数据插入到arr2表中,期间利用collect_set函数
insert into arr2 select name,collect_set(s) from temp_arr1 group by name; #注意:一定会是字段s,因为转为行的时候起的列名为s
三、键值对map的基本操作
1、创建字段类型为map类型的表
create table if not exists map1( name string, score map<string,int> ) row format delimited fields terminated by ' ' collection items terminated by ',' map keys terminated by ':';提示:键值对map 会切两次 ,数组array只切一次,结构体struct也是切一次
2、数据准备
zhangsan chinese:90,math:87,english:63,nature:76 lisi chinese:60,math:30,english:78,nature:0 wangwu chinese:89,math:25,english:81,nature:9
3、加载数据
load data local inpath '/root/hivetest/map1.txt' into table map1;
4、键值对map类型的查询操作
#查询全部表map1的数据
select * from map1;#查询数学大于35分的学生的英语和自然成绩:
提示:最好起别名,别管为什么,总之有好处,因为别的表再访问的时候 可以根据字段名访问
select name,m.score['english'],m.score['nature'] from map1 as m where m.score['math']>35;

5、map的列转行操作
其实类似于 array的列转行操作,只要array的列转行明白,这个或者下面肯定都明白了,下面我会一点一点展示到完整。
- 利用explode展开数据
select explode(score) as (m_key,m_value) from map1;
- 利用Lateral view和split,explode等一起使用,它能够将一行数据拆成多行数据,并在此基础上 对拆分后的数据进行聚合
#列转行的操作语句:
select name,m_key,m_value from map1 lateral view explode(score) s as m_key,m_value;
5、map的行转列操作
# 数据准备: -- 使用新的数据
name7,38,75,66
name6,37,74,65
name5,36,73,64
name4,35,72,63
name3,34,71,62
name2,33,70,61
name1,32,69,60# 创建临时表,并加载数据
create table temp_map1( name string, score1 int, score2 int, score3 int ) row format delimited fields terminated by ',';# 加载数据到临时表
load data local inpath 'temp_map1.txt' into table temp_map;
# 创建要导入数据Map表
create table if not exists map2( name string, score map<string,int> ) row format delimited fields terminated by ' ' collection items terminated by ',' map keys terminated by ':';# 导入数据:
insert into map2 select name,map('chinese',score1,'math',score2,'english',score3) from temp_map1# 查询是否成功导入到表map2
select * from map2;

四、struct数据类型的基本操作
#注:其实struct 与array、map 是一样的 ,按我理解只不过过了层包装、多了几种数据类型罢了
#创建一个表:
create table if not exists str2( uname string, addr struct < province:string, city:string, xian:string, dadao:string >) row format delimited fields terminated by '\t' collection items terminated by ',';#导入数据:
load data local inpath 'struct.txt' into table str2;#查询数据:
select uname,addr.province,addr.city,addr.xian from str2;
#复杂数据类型案例
#类型介绍
uid uname belong tax addr xdd ll,lw,lg,lm wuxian:300,gongjijin:1200,shebao:300 山,济,历 lkq lg,lm,lw,ll,mm wuxian:200,gongjijin:1000,shebao:200 河,石,中#创建表
create table if not exists tax( id int, name string, belong array<string>, tax map<string,double>, addr struct<province:string,city:string,road:string> ) row format delimited fields terminated by ' ' collection items terminated by ',' map keys terminated by ':' stored as textfile;#导入数据
load data local inpath 'tax.txt' into table tax;#查询:下属个数大于4个,公积金小于1200,省份在河的数据
select id, name, belong[0], belong[1], tax['wuxian'], tax['shebao'], addr.road from tax where size(belong) > 4 and tax['gongjijin'] < 1200 and addr.province = '河';
#嵌套数据类型















 6323
6323











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









