






层次潜在狄利克雷分配hLDA核心思想
1. 狄利克雷过程DP
狄利克雷借助折棒[21]构造使r维参数向量中的r值可趋于无穷。折棒方法可以将单位长度的棍棒折成无穷多段,折下的部分作为嵌套中国餐馆中主题的先概率。
2.嵌套中国餐馆过程
这个先验可以建模主题层次,嵌套中国餐馆过程能够表达可能的L层树的不确定性,即当L层主题树结构路径数不确定时,嵌套中国餐馆过程也可以用于先验分布。
在hLDA主题模型中个,每篇文档对应了一个无穷分支树的一个子树,每个句子对应一条主题路径,每个词语都会落在一个节点中,即为层次主题结构。
3. 概率后验推理
得到hLDA模型后,为了估计文档集的潜在主题,需要进行概率后验推理过程,利用可观察变量推理出隐含变量。使用一种特殊的MCMC[22]方法对hLDA的后验概率分布进行估计。MCMC方法把迭代抽样过程视为马尔科夫[23]过程,由抽样样本序列形成马尔科夫链。当迭代次数足够大时,可以使误差较小。Gibbs抽样明确构造马尔科夫链的过程。Gibbs抽样接收所有样本,并且在抽样时只考虑单个变量,视其他变量为定量。因此可以用它来对hLDA模型产生的联合分布进行估计。
为了学习数据的主题层次信息,Blei等人在潜在狄利克雷分配的基础上提出了层次潜在狄利克雷分配[8][9]。该模型使用贝叶斯方法,利用嵌套中国餐馆过程生成一个合适的先验,允许任意大的分支结构而且可以适应数据集增长。该模型为数据建立层次树形结构,层次中的每个节点对应一个主题,而主题又是词语的一种分布。由于本系统是在句子层面建立主题层次模型,因此每个句子在最终生成的树形层次结构中都有属于自己的唯一路径,句子中的词分布在其路径所覆盖的节点上。一条路径经过一个主题节点则代表其包含了一定程度的该主题内容,我们称该结构中的路径为主题路径。同一条主题路径上的句子共享该路径所经过的主题,因此,hLDA主题模型起到了聚集相似句子(即聚类)的作用。在hLDA主题模型中,节点是词语分布,路径是共享相同节点的句子的汇集,二者都是主题聚类的重要表现因素
文档的生成过程分为三步:第一步是选择一条从根节点到叶子的路径;第二步是重复地沿着该路径抽样主题;第三步从选择的主题中抽样词语。该模型为数据建立层次结构,方便学习数据的主题层次信息,进而能够挖掘出潜在的主题信息,为文本处理、信息挖掘等领域又点亮了一盏明灯。
hLDA建模步骤如下:
1) 生成主题先验分布:利用βk~Dirichlet(η)得到主题先验分布;
2) 针对每个句子进行逐一循环处理,d∈{1,2,…,D};
a) 生成句子d的主题路径:利用嵌套中国餐馆过程Cd~nCRP(γ)为句子d生成一条深度为L的主题路径;
b) 生成句子d的层次主题概率分布:针对句子d的L层主题向量,取得一个概率分布,θd~GEM(m,π);
c) 选择主题:利用Zd,n|θ~Mult(θd)从句子d的L层主题中选择主题;
d) 为主题生成词语:主题由词语按照概率分布混合而成,因此在选定主题后,利用主题和词语的关系Wd,n|{Zd,n, Cd, β}生成词语。
3) 利用Gibbs抽样器,对Cd和Zd,n进行迭代抽样,进而得到潜在变量的近似分布估计。
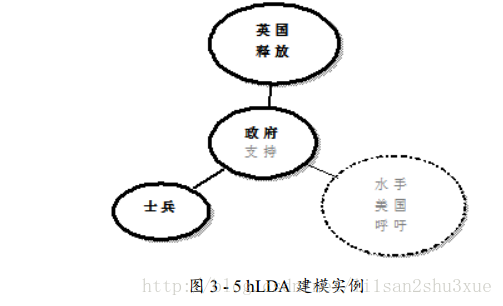
取例句“英国政府要求释放士兵”进行处理,从分词到建模结束,其所经历具体步骤如下:
1) 输入句子“英国政府要求释放士兵。”
2) 分词后结果为:英国 政府 要求 释放 士兵 。
3) 去停用词后结果为:英国 政府 释放 士兵
4) hLDA建模输入格式为:4 5:1 3:1 4:1 8:1
5) 为该句子生成了主题路径Cd
6) 句子中的词分散到不同的主题层次Zd,n上
7) 经过步骤5) 和6) ,建立Cd和Zd,n的联合分布
8) 利用Gibbs抽样器,对Cd和Zd,n进行迭代抽样
9) 该句最终在树形层次结构中呈现状态如图3-5所示。















 672
672

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









