







最近在看推荐系统相关的资料,发现一篇很棒的概述文章,于是整理出了这篇个人笔记【转载、引用请注明出处】。原文在这里:推荐引擎初探
1、概念:相对于“搜索引擎”而存在的另外一种信息发现技术。搜索引擎,用户借助于网络通过输入关键词获取自己感兴趣的信息。但是,诚如乔布斯所言,大多数用户并不知道自己想要什么,直到你把它摆在他或她的面前,于是推荐引擎就产生了。这当然是优雅的说法,推荐引擎的产生原因还包括信息发现难度增大(对用户而言)、商家利润驱动、技术发展必然趋势等。
2、推荐系统简单框架图:
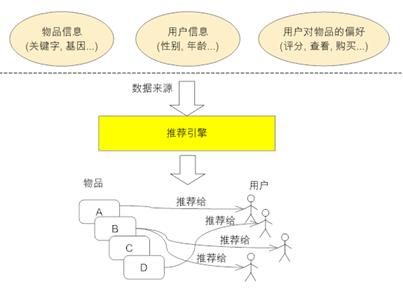
3、推荐引擎的分类
- 简单分类:大众推荐和个性化推荐
- 根据数据来源:基于内容的推荐(content-based)、基于人口统计学的推荐(demographic-based)和基于协同过滤的推荐(collaborative-based)
——基于人口统计学的推荐:甲和乙的年龄、性别等特征类似,那么甲购买过得商品就可以推荐给乙

好处是简单,领域独立,没有冷启动问题;缺点是粗暴,用户的敏感信息不易获取(比如年龄)
——基于内容的推荐:某人喜欢甲商品,乙商品与甲商品很相似,因此可以把乙商品也推荐给甲
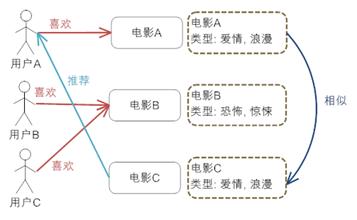
好处是:结合用户口味精确推荐;缺点是对物品特征和建模要求高、没有考虑人对物品的喜好、有冷启动问题(对冷启动问题表示怀疑,应该没有这个问题,就算有也没跟用户没关系)
——基于协同过滤的推荐:用的比较多的、比较成熟的方法,分为三个子类:基于用户的(user-based)、基于项目的(item-based)以及基于模型的(model-based)。
(1)基于用户的协同过滤推荐:根据用户与商品的历史信息,发现用户的品味;发现与用户品味类似的邻居(K-邻居);把邻居喜欢的商品推荐给当前用户。
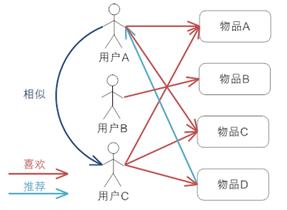
图解:根据用户A和用户C的历史信息得到二者品味相似的结论,A成为C的邻居。C喜欢D商品,而A对D商品没有记录,因此可以把D商品推荐给A。
注意:这里的基于用户的协同过滤推荐与基于人口统计学的推荐看起来很相似,但是在计算用户相似度、寻找K-近邻的方法不一样,基于人口统计学的推荐纯粹考虑用
户本身的特征,而这里的基于用户的推荐则通过用户“品味”衡量用户相似度,更可靠。
(2)基于项目的协同过滤推荐:喜欢A物品的用户都喜欢C,A用户也喜欢物品A,故可以把物品C推荐给用户A。
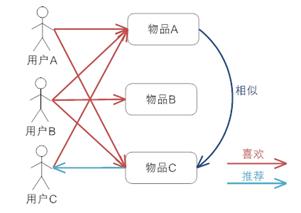
注意:看起来与基于内容的推荐类似,都是基于物品相似度进行推荐,实际上它们的相似度计算方法不同。这里的方法是基于用户与物品之间连接关系的,而基于内容
的推荐纯粹基于物品本身的相似度。
(3)基于模型的协同过滤推荐:利用用户的历史信息专门训练出一个个性化推荐模型,根据用户喜好进行实时预测、推荐。
基于协同过滤的推荐是当今使用最广泛的推荐机制,它的好处是:1)共用用户历史信息,深度挖掘用户的喜好;2)非严格建模,领域无关。缺点:1)基于用户历
史数据,有冷启动问题;2)依赖于用户历史数据的多少和准确性;3)数据稀疏,对噪声敏感;4)难于在线学习,不够灵活。
- 根据推荐模型的建立方式:基于物品和用户本身的推荐、基于关联规则的推荐(rule-based)以及基于模型的推荐(model-based)
4.混合机制:现有推荐机制多采用混合推荐机制,根据实际情况灵活使用推荐机制。
- 加权的混合
- 切换的混合
- 分区的混合
- 分层的混合
5.推荐引擎的应用
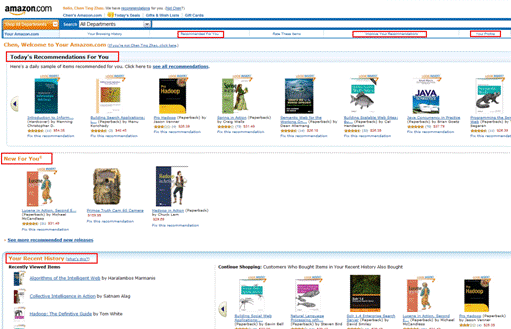
- 在电子商务领域的应用——亚马逊(分区混合机制)
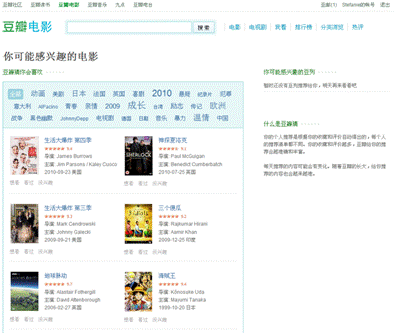
- 在社交网络领域的应用——豆瓣(基于社会化的协同过滤)
















 904
904











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









