







一.背景:
经常碰到我们的客户朋友反馈:BI如何做到自主分析?SQL Server 有没有好的解决方案,这个时候我们一般上就会想到使用PowerBI 进行。但紧接着就会面临一下几个问题:
1.PowerBI 的数据源从哪里来?数据源又怎么控制到行列权限,确保数据的安全。
2.自主分析:我们需要结合线下的数据,如何做到自主。
针对第一个问题,或许有很多朋友会将:我们的方案是通过PowerBI 连接表格模型(Tableuar)在表格模型上进行行列权限的控制。站在BI方案的角度,这的确是一个比较好的解决方案和思路。但紧接着就会引出第二个问题表格模型无法解决。
PowerBI 在连接表格模型之后:
1.如果用的是导入模式,需要导入很多表,表之间的关系也需要梳理清楚,导入的数据量也是偏大;
2.如果用的是直连模式,那简直是一点自主都谈不上了。假如我需要引入一个新的数据源:不行。假如我需要更改一些计算逻辑:不行。假如我需要增加一个计算列:不行。以上这些操作统统都需要IT 技术人员来帮你完成。
于是,我们在探寻一种新的方式来解决用户的困扰,众所周知;宽表用来一时爽;应运而生的,我们在数仓中抽象出一层为业务部门提供数据服务的层次(DWS);这样整个BI的架构往往会调整为:

用户通过PowerBI 访问DWS 层的宽表视图获取数据,然后结合自己的业务和线下数据做自主分析。我们技术人员帮助业务部门提供准确标准DWS 层数据服务。
那么有关表或者视图级的行列安全问题应运而生;接下来,我么一起探讨通过一些技术手段和方案来实现相关的行列安全限制;
二.技术手段:
- SQL Server 行级安全(RLS)

作为SQL Server 2016的新特性,RLS 技术为我们提供了解决表或者索引视图的行级安全的可能,行级安全的设置在SQL Server中主要通过三步完成:
1>.创建谓词函数:
首先需要明白什么是谓词:举个例子:猫是动物,3大于2。其中是,大于我们可以理解为谓词;他是连接两个客体之间关系的词。
那么明白了谓词,我们就比较容易理解什么是谓词函数:定义表中某一行数据满足用户权限之间关系的函数,即为谓词函数。
接下来,我们定义谓词函数。在微软的官方文档中,强烈建议我们单独建立相关的Schema(我们一般建议名字为:Security)。在该Schema下创建谓词函数。
CREATE FUNCTION Security.tvf_securitypredicateByRole(@TableViewName nvarchar(500),@ColumnName nvarchar(500) , @FilterValue AS nvarchar(50))
RETURNS table
WITH SCHEMABINDING
AS
RETURN (
SELECT 1 AS RESULT
FROM Security.UserSecurity U
join Security.UserRole C ON U.RoleName=C.RoleName
where
C.UserName=USER_NAME() AND
ISNULL(U.ColumnName,'')=CASE WHEN ISNULL(U.ColumnName,'')='' THEN ISNULL(U.ColumnName,'') ELSE @ColumnName END
AND ISNULL(U.FilterValue,'')=CASE WHEN ISNULL(U.FilterValue,'')='' THEN ISNULL(U.FilterValue,'') ELSE @FilterValue END --缺省值为所有
AND ISNULL(U.TableViewName,'')=CASE WHEN ISNULL(U.TableViewName,'')='' THEN ISNULL(U.TableViewName,'') ELSE @TableViewName END
)如上代码段,是一个谓词函数的定义的举例:通过以上一个例子:我们发现其实谓词函数本质是上一个表值函数,在该函数中,我们通过定义表名称,表列名,列字段的方式,实现将表和我们的权限控制表(Security.UserSecurity表,这张表可以定义要控制的表的列,过滤条件等。如下图:)之间建立起连接关系。通过函数传递相关信息,在函数中和权限表进行比对,有权限则返回true,否则返回false。
| 字段 | 类型 | 描述 |
| ID | INT | 主键 |
| UserName | nvarchar(50) | 用户名 |
| TableViewName | nvarchar(500) | 表或者视图名称 |
| ColumnName | nvarchar(500) | 需要控制的过滤的列名 |
| FilterValue | nvarchar(4000) | 过滤值 |
| RoleName | nvarchar(500) | 角色名称 |
2>创建安全策略:
以上函数定义完成之后,那么怎么让表去调用呢?SQL Server 提供了Security Policy (安全策略)的设置。
CREATE SECURITY POLICY FactFinanceFilter
ADD FILTER PREDICATE Security.tvf_securitypredicate('FactFinance','DepartmentGroupKey',DepartmentGroupKey)
ON [dbo].[FactFinance]
WITH (STATE = ON);
GO通过以上脚本,既可以为表FactFinance 表开通有关DepartmentGroupKey 相关字段的行级过滤权限。
3>开通权限
通过以上两步已经完成了行级安全的设置,接下来,我们就需要对表和函数开通相关访问权限即可,完成相关测试工作。
4>注意事项:
- 如果使用视图,必须使用索引视图(视图创建脚本前必须加上 WITH SCHEMABINDING )。
- 可以在安全策略的表或者上创建视图,但最好不要创建索引视图,索引视图会绕过安全策略。
2.SQL Server 列权限控制

SQL Server的列级权限控制,设置起来相对简单;并且也不存在版本限制,我们只需要在用户或者数据库角色配置表或者视图的访问权限时,勾选访问列即可,如下图。

虽然列级权限配置简单,但是需要我们注意的是,用起来就相对麻烦了:必须指定列名访问;也就是说Select * 的写法因为权限问题将永远无法返回数据,更为可惜的是我们用Excel或者PowerBI 连接表或者视图更加困难;如下图:

当然也可以通过高级模式,指定列名访问,不过这个大大增加了业务部门的使用难度。如下图:

综上所述,行级安全和列级安全,尽管SQL Server 都有一些技术方案用来解决,但是我们在真正实施落地的时候还是需要综合考虑提出适合大家的相关技术方案。
3.SQL Server 动态数据屏蔽

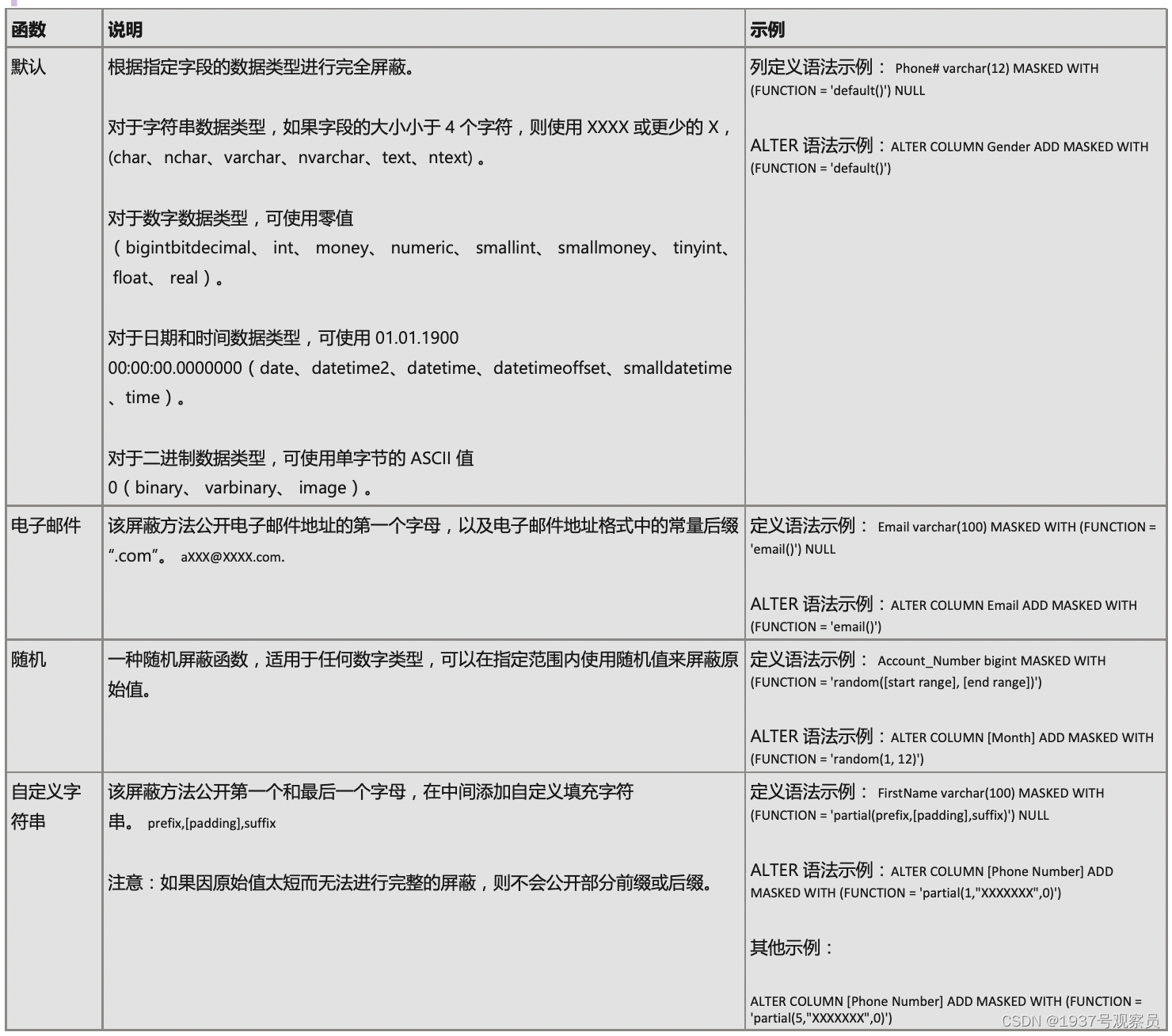
动态数据掩码 (DDM) 通过对非特权用户屏蔽敏感数据来限制敏感数据的公开。 它可以用于显著简化应用程序中安全性的设计和编码。
掩码函数:
掩码使用到列上:
-- table with masked columns
CREATE TABLE Data.Membership
(
MemberID int IDENTITY(1,1) NOT NULL PRIMARY KEY CLUSTERED,
FirstName varchar(100) MASKED WITH (FUNCTION = 'partial(1, "xxxxx", 1)') NULL,
LastName varchar(100) NOT NULL, Phone varchar(12) MASKED WITH (FUNCTION = 'default()') NULL,
Email varchar(100) MASKED WITH (FUNCTION = 'email()') NOT NULL,
DiscountCode smallint MASKED WITH (FUNCTION = 'random(1, 100)') NULL
);
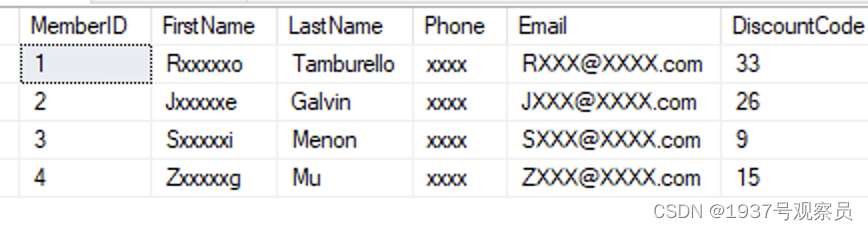
插入数据,并授权用户访问:
GRANT UNMASK TO MaskingTestUser;
如下图:实现了动态屏蔽。
如果需要查看未经屏蔽的数据,则通过以下语句实现授权。
GRANT UNMASK TO MaskingTestUser;
三.推荐方案:

如上图:
1.我们通过在DW中创建Security 的架构:在该架构下我们创建相关的谓词函数和用户权限控制表。同时我们创建权限索引视图;该视图使用上文讲到到行级安全和列级安全权限控制。
3.我们在DW中创建DWS的架构;该Schema下的所有视图最终都将为用户提供访问需求。在该层的视图,我们通过访问Security下的权限视图,并完成逻辑编写,形成宽表视图给到终端用户访问。(这里分为两类视图,一类是包含所有列的Owner视图,一类是根据不同的列权限开发的用户视图)。















 790
790











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









