







目标网站:https://careers.tencent.com/search.html?pcid=40001
目标数据:爬取前10页招聘信息中的岗位名称、工作职责、工作要求
准备工作:先看下目标数据的获取方式,是从页面的HTML中获取还是从接口中直接获取。
通过对网站的分析,发现需要的数据是来自接口。如下图所示:
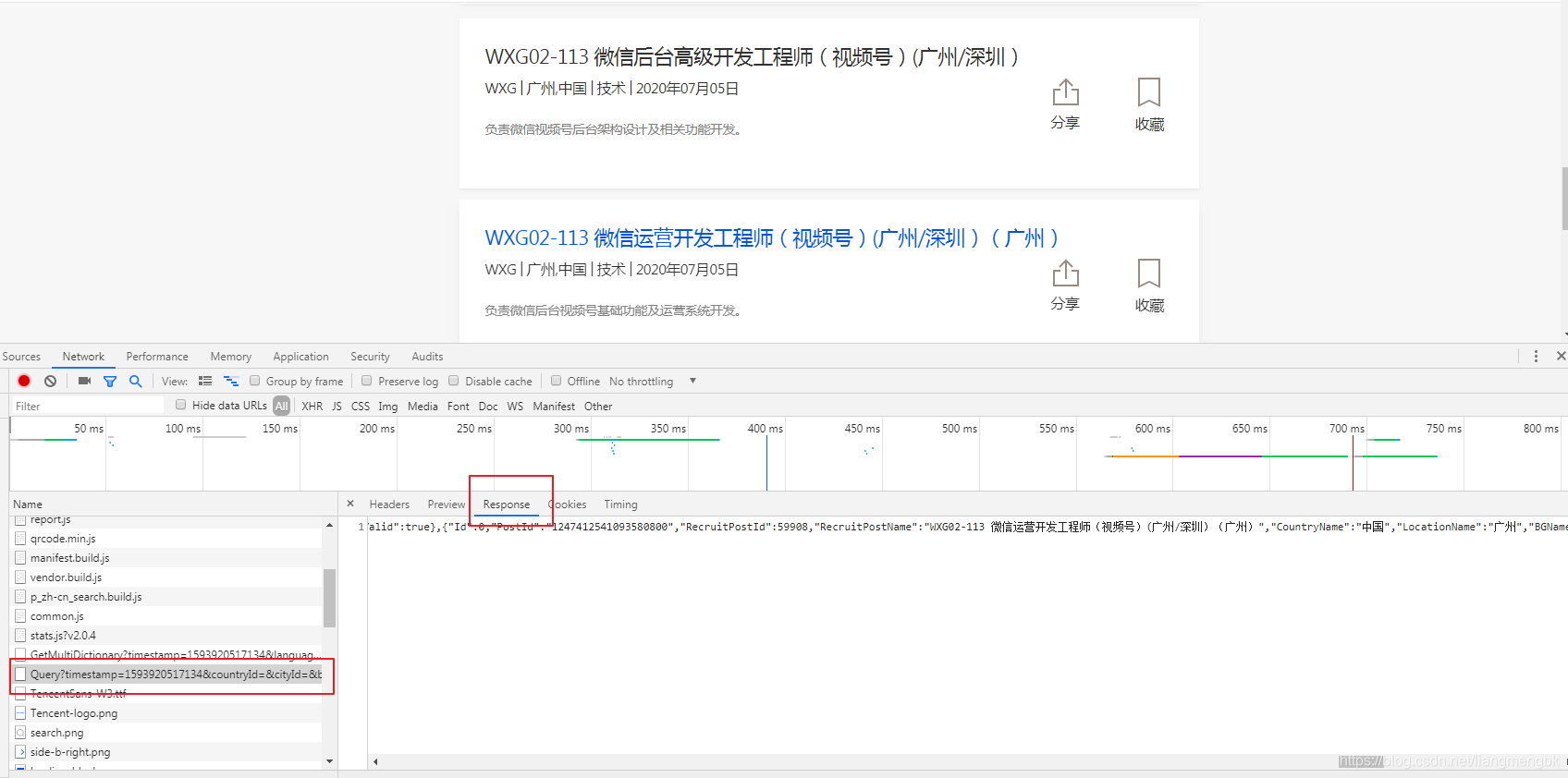
话不多说,直接上代码:
import requests
import json
headers={
"user-agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.108 Safari/537.36"
}
def main(url):
response=requests.get(url,headers=headers)
#将json字符串转字典
jsonDic=json.loads(response.text)
result=jsonDic["Data"]["Posts"]
for x in result:
postID=x["PostId"]
postUrl="https://careers.tencent.com/tencentcareer/api/post/ByPostId?postId="+postID #构造详情页url
resDetail=requests.get(postUrl,headers=headers)
jsonDicDetail=json.loads(resDetail.text) #将json字符串转字典
# 获取需要的信息
RecruitPostName=jsonDicDetail["Data"]["RecruitPostName"] #岗位名称
Responsibility=jsonDicDetail["Data"]["Responsibility"] #工作职责
Requirement=jsonDicDetail["Data"]["Requirement"] #工作要求
print("岗位名称: "+RecruitPostName+"\n")
print("工作职责: "+Responsibility+"\n")
print("工作要求: "+Requirement+"\n")
print("------------------------------------------------------------------")
if __name__ == '__main__':
# 构造请求url
url="https://careers.tencent.com/tencentcareer/api/post/Query?pageIndex="
for i in range(1,11):
main(url+str(i)+"&pageSize=10")
执行结果:

这样就获取到了目标信息。
声明:以上数据仅作为爬虫学习,不做任何其他用途。

















 400
400

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









