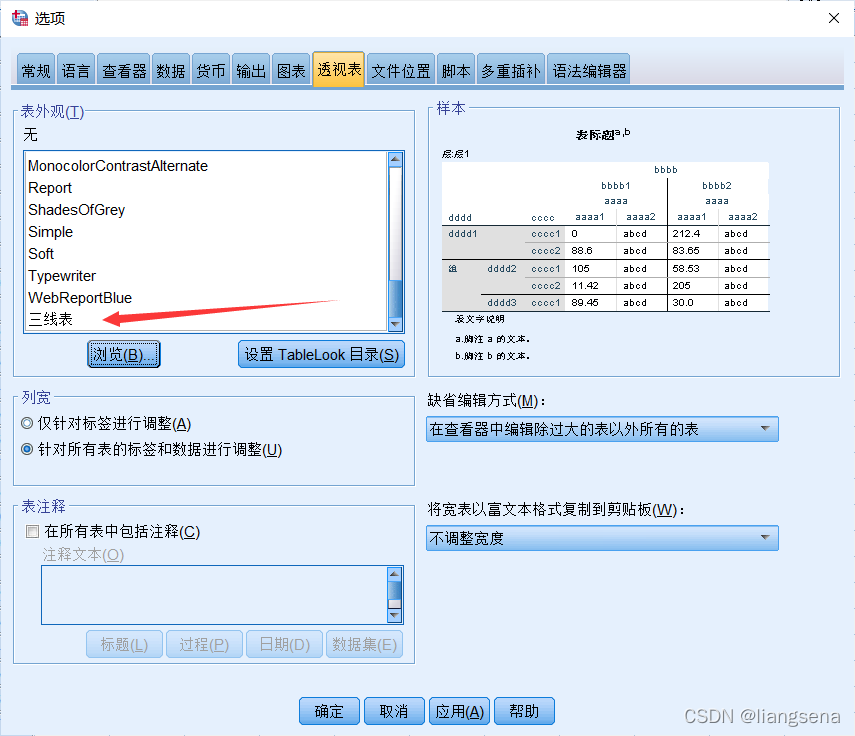
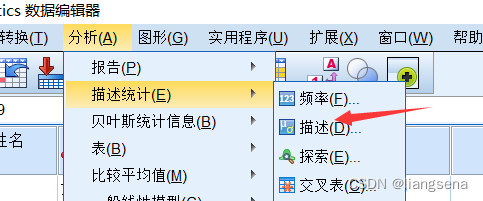
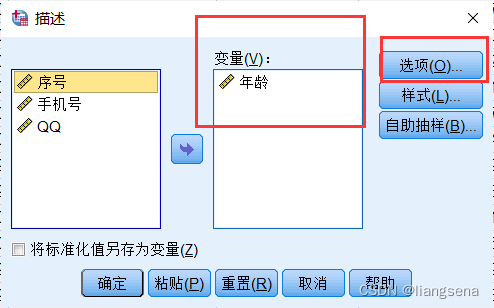
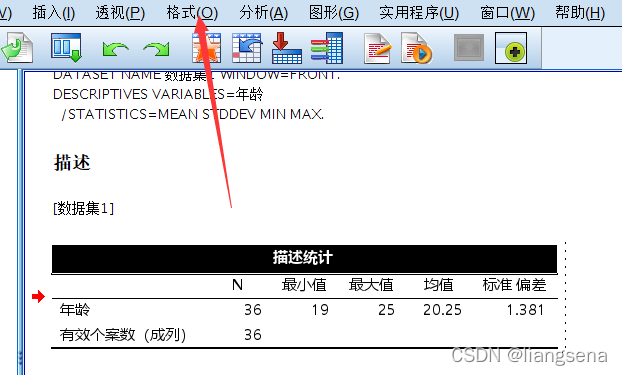
目录 一、文件下载二、配置三、应用 一、文件下载 链接:https://pan.baidu.com/s/1YJd4lH2VI3sZRCKG_VWqIA 提取码:6ezo 二、配置 下好后放入Looks,即可 就看得到我们刚刚加进来的三线表了 三、应用 选择三线表,点击应用 对导入的数据进行分析 自己调整表格格式,双击生成的表格 最终效果如下 大功告成!











 这篇博客介绍了如何下载和配置三线表资源,将其应用于数据展示。通过双击生成的表格并调整格式,可以实现专业且美观的数据分析报告。最终效果显著,适合需要提升报告质量的读者。
这篇博客介绍了如何下载和配置三线表资源,将其应用于数据展示。通过双击生成的表格并调整格式,可以实现专业且美观的数据分析报告。最终效果显著,适合需要提升报告质量的读者。





















 12万+
12万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言








